2018年7月27日(金)に御茶ノ水のソラシティで行われたDevelopers Summit 2018 Summerに行ってきたので聴講したセッションのうち聞いて良かったと思ったものをシェアします。(記事を寝かせていたことを忘れてたので今更感がありますが^^;)
なお、Developers Summit 2018 Summer、講演関連資料まとめ に各講演の資料とTogetterまとめが集約されているのでこちらもご参照ください。
受講セッション
ソニーが提供するディープラーニングの開発環境の紹介と活用事例
僕のような年代のエンジニアにとって、ソニーといえばソニータイマー(保証期限が切れた直後に壊れる)という認識だし、機械学習界隈ではあまり著名では無いような気が。そんなソニーからどんな話が聞けるのか興味もあって朝一番のセッションとして参加。しかし、予想以上に素晴らしい話を聞けたので、お礼に ソニーのワイヤレスイヤホンWI-C300ホワイトを楽天の上新電機で買いました^^;
ソニーでは、2010年頃から本格的にDNNの研究に参画。発表者の成平さんは2014年から2015年までUCバークレイに留学しCaffeの開発にも携わったそうで、その流れの中からソニー内部で使用していた Neural Network Libraries というライブラリーやNeural Network Console という開発ツールをオープンソース化して提供するようになったとのこと。
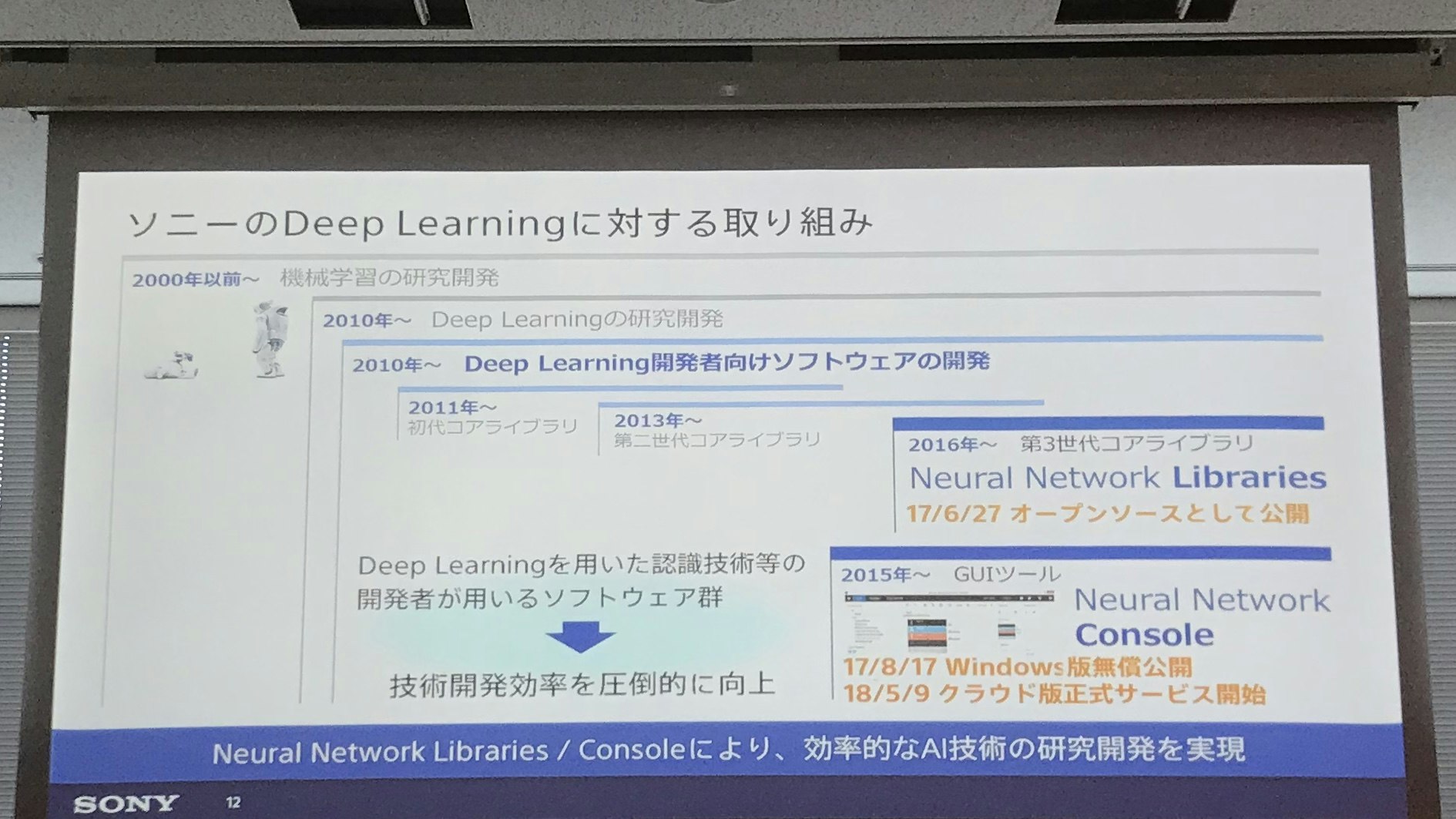
画像の認識率は2015年にはすでに人間を超えており、ディープラーニングは研究の時代から実用の時代に移っている。ソニーでも、AIBO含めて多種多様なアプリケーションに実装が進んでいて、リサーチャーや機械学習エンジニアだけでなく一般のエンジニアでも活用され始めている。おそらくいまのクラウドと同じく使えることが当たり前になる日が来るのもそう遠く無いのでは無いかとのこと。
これは僕が思うに、マイクロソフトに代わってExcelというアプリを「作れます」ではなく、Excel「使えます」が必要だという意味に解釈。Excelにデータを投入して=sum()とかやって集計取ったり、平均出したり、ちょっと自動化でマクロ組んだり。そういった業務でExcel「使えます」と同じく、出来合いのモデルからいい感じのヤツを選んで少しデータ学習させて推測したり、分類したり。そういった「使えます」が業務アプリの開発者にも必要なのではないかと。
この後、Neural Network Consoleで手書き数字を認識するモデルを構築するデモ。このツールはAzure Machine Learning Studioみたいな感じだけど、どちらかというとモデルの構築をメインに据えてるようです。Azure ML Studioはどちらかというとワークフロー的。入力層があって、ReLUを活性化関数にして畳み込み層とプーリング層を付けて、最後はシグモイド関数でと、積み木のようにモデルをグラフィカルな操作で構築していける。今まで見てきたIBMやMicrosoftなどのツールに比べて格段に使いやすそう。
そしてさらなるおすすめポイント。ここで構築したモデルはONNX形式のファイルとして出力できるので、別のフレームワークでインポートしてそちらで実行することもできる。例えば、ここで作ってエクスポートしてラズパイなどのエッジ側で実行するとか。なおソニーのNeural Network LibrariesもONNX対応なので、例えばAzure上でモデルを構築してONNX形式のファイルをインポートするとかも普通にできそう。
このモデルをさらに発展させて、手書きアルファベットという今まで見たことのない画像を3つばかり学習させて、新しく推測させる画像が学習させたデータのどのクラスタに近いかという距離から分類する Siamese Network という手法を使った少量学習データによる画像認識のデモに移る。
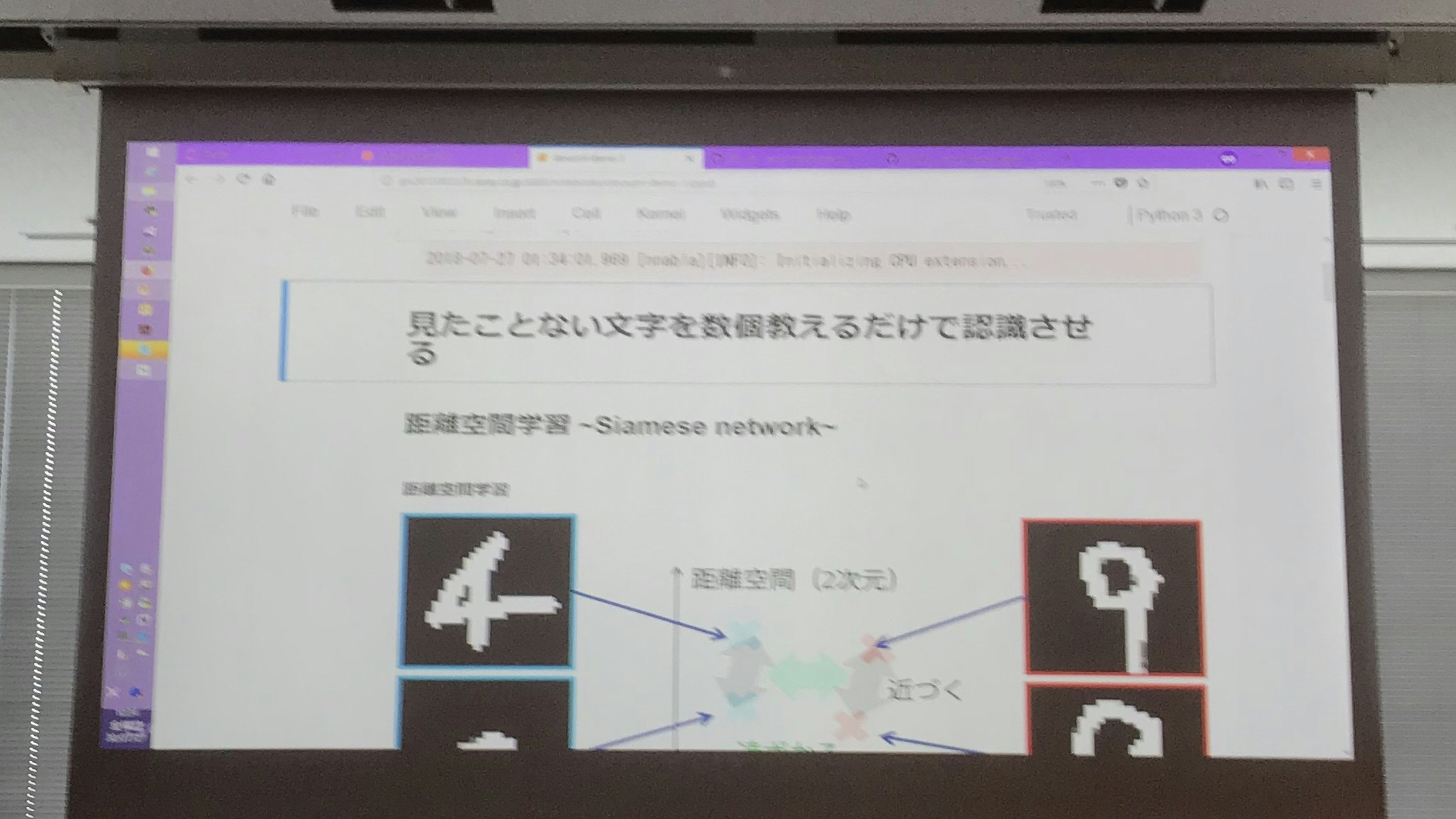
この手法について受講時点では知らなかったんだけど、この少量データで学習するという点は今一番興味を持ってる部分で、実現手法としての転移学習やデータの水増しみたいなことを色々試してみようと思っていたけれど、こういった手法があることを知っただけで今回のデブサミに参加した意義があった気がする。(注:その後Deep Learning Specializationの中で、これらの手法については学びましたし、実際にコードも書いてみました)

ちょっとソニーのこと見直したので、早速Neural Network Consoleインストールしてみよう。
AI時代におけるエンジニアの生存戦略
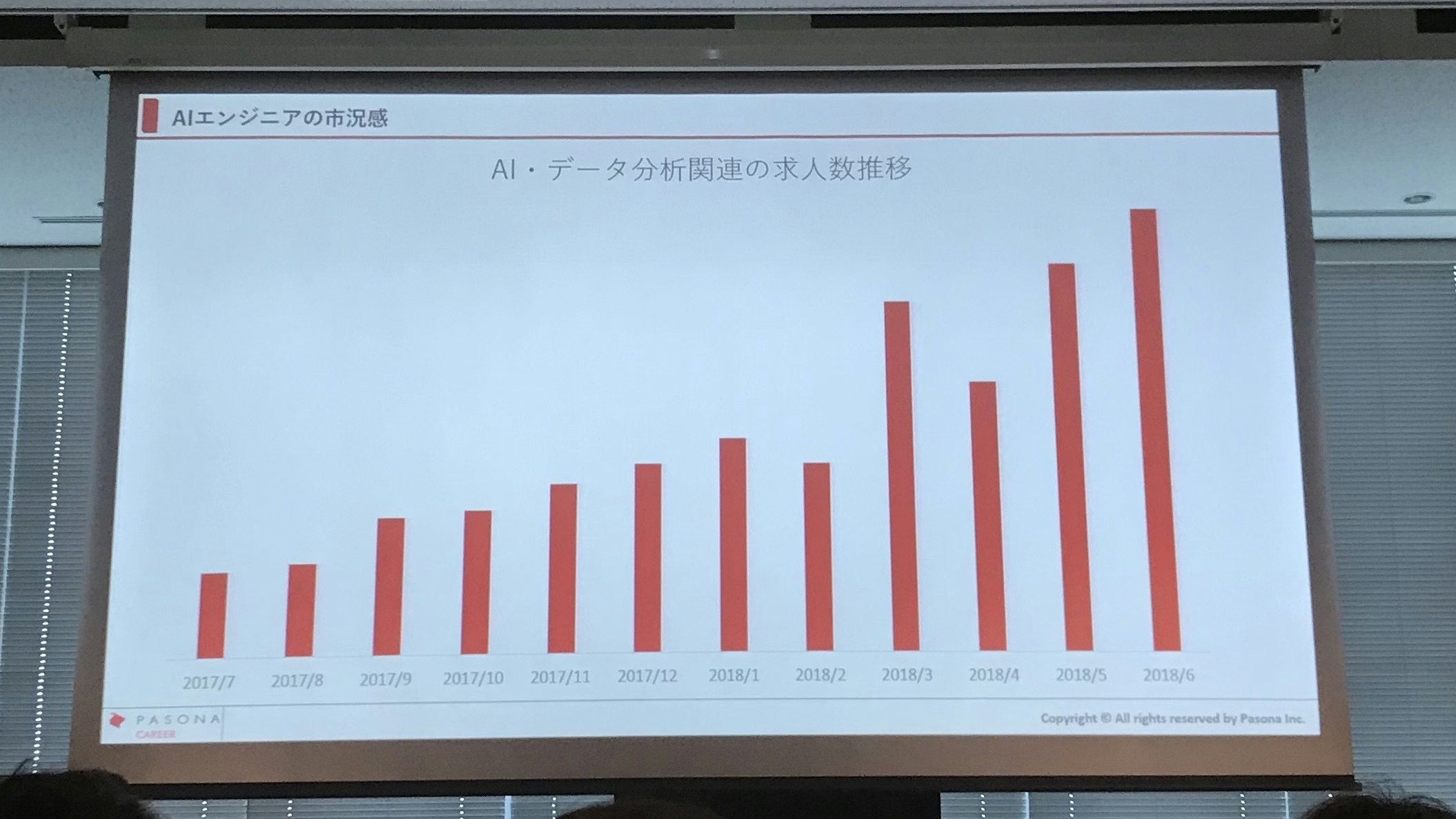
驚くべきことに立ち見が出るほどの盛況。スキルセットのひとつとしてAIがいかに人気かというのを裏付けているかもしれない。パソナの高坂さんが提示した最近の求人状況を紹介するパネルにも、ここ半年間でAI関連の求人が倍増しているなど、はっきりとAI人材に対する需要が高まっていることが表れている。
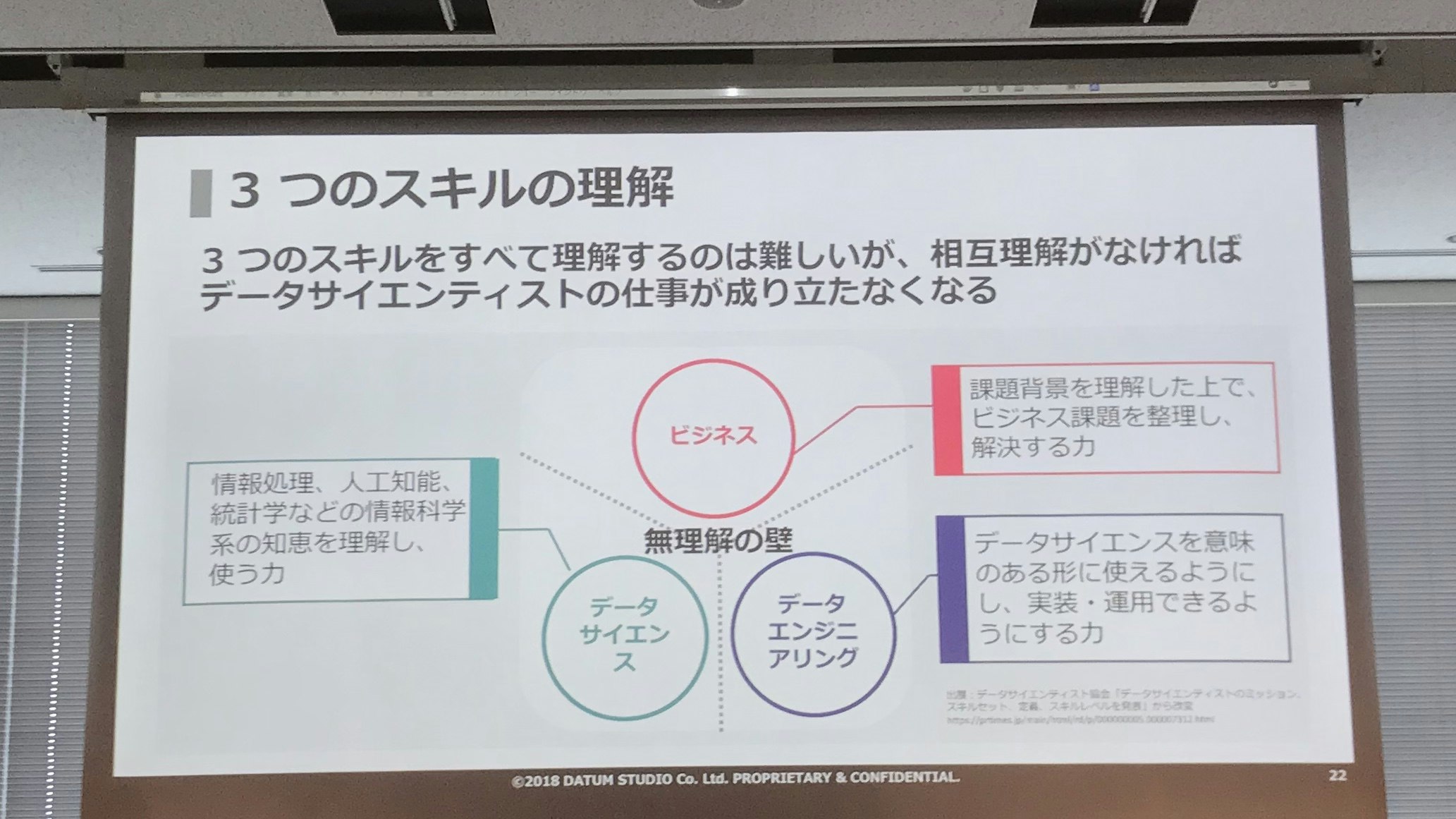
DATUM STUDIOの安部さんによると、データサイエンティストのスキルは、
- ビジネス
- データエンジニアリング
- データサイエンス
の3つに分かれるが、この全てに精通している人材などいないと思ったほうがいい。だから、上記の3つのスキルセットをチームとして備えることを考えるべきとのこと。そうは言っても、全く隣のことを理解しないというのも困るので、ある程度はビジネスを理解しつつデータエンジニアリングに軸足とか、データサイエンスに軸足はおいてるけどエンジニアリングも分かるよというオーバーラップがある方がいいとのこと。
僕が思うに、これって実は機械学習に限った話でないのでは? 一般的な日本企業は人材といったとき、全てにおいてハイレベルな角のないレーダーチャートを持つスーパーマンを夢見がち。例えばITSSだと、コミュ力、プロマネ力、ビジネススキル、技術力、リーダーシップ、交渉力など全方位に渡ってできる人を獲得、あるいはできる人材を育てねばと意気込む。
でも、10方向に満遍なくハイレベルな稀有な人材を探すより、1方向に優秀な人材を10人獲ってチームを編成する方が早くてコストパフォーマンスが良い気がしませんか? そして、そういうチームをうまく機能させられるマネージャーを育成することが必要なように思います。
その後、パソナの高坂さんの問いにDATUM STUDIOの安部さんが応答する形でトークセッションへと移行。
Q1:AI時代の到来を迎え今からエンジニアは何をすれば/どこを目指せばいい?
A1: ビジネス、エンジニアリング、サイエンスのどこに軸足をおくかを、自分自身のバックグラウンドをベースに決めたほうがいい。
Q2:CTO目線でどんな人材が欲しいか?
重なり合うグレーな領域は知りませんではなく歩み寄る姿勢を持っていることが大事。(僕の受けた印象:軸足は得意分野に置くけれどその隣接部分に対して興味を持ち、そちらの立場に立った配慮がある程度できるということかと思います)
Q3:AI人材に対する需要は続く?バブル的なものでもう終焉?
バブル的は終焉を迎え、当たり前になってきそうだけれど業界によっても異なる。製造業は腰が重かったけれど動き始めているので、ほぼすべての業種で人材の需要は高まっている。大手SIerも参画してコモディティ化が進んでいる。
最後に、今日の参加者に向けて安部さんから「興味を持ったら具体的な一歩を踏み出して欲しい」とのこと。
機械学習チームにおけるソフトウェアエンジニア〜役割、キャリア
クックパッドの伊藤さんから、機械学習プロジェクトでのソフトエンジニアの役割、機械学習分野でのキャリア形成についての講演。お話を聞いて衝撃的だったのは、ソフトエンジニアにとって基本のキといっていいリファクタリング、ユニットテスト、CIといった部分が意外にも見過ごされているということ。最近になって機械学習プロジェクトにソフトウェアエンジニアリングの視点をという話をよく聞くようになったのはそういう背景だったのかと理解できました。
伊藤さんによれば、機械学習プロジェクトには機械学習モデルというものがありそれが主役なので、コードだけでは完結しない(モデルが必要)、コードを読んでも振る舞いが分からない(モデルの理解)、品質は入力データに依存する(モデルへの投入データ)などという特徴があり、ブラックボックス的な部分が非常に多いためケアすべきところが非常に多いプロジェクトと言える。ここを何とかするために近年ソフトエンジニアリングの視点を導入しようという機運が高まっているそうです。
では具体的にソフトウェアエンジニアリングは機械学習プロジェクトにどう貢献できるのかというと、機械学習プロジェクトの3つのライフサイクルである実験→コード整理→デプロイというサイクルを速くよどみなく回すことができるようにデータサイエンティストをサポートすることであると定義できるそうです。
実験では、データを以下に効率よくデータサイエンティストのもとに自動的に届けるかということがポイントで、データが手元にないデータサイエンティストは陸サーファー(笑)みたいなものなので、その状態をできるだけ作らないようにしないといけない。また、計算機リソースをいかに適切に配分するかという点も大きなポイントで、データと計算機リソースがあればデータサイエンティストの仕事を阻害する大半の要因は排除できたことになる。
次にコード整理では、ソフトエンジニアなら当たり前と言っていい、リファクタリング、自動テスト、CIなどがきちんと回るような仕掛けづくりが必要となるそうでうです。多くの機械学習プロジェクトでは、データサイエンティストがJupyter Notebookを使って書いたモデルのソースは、必ずしもメンテナンス性が高いとも言えないのでリファクタリングが必要であるが、自動テストがないのに実験で作成されたモデルのコードをリファクタリングしても正しく動作していることを保証できない。僕が受けた印象としては、要するに一般的なアジャイル開発プロセスが実を伴って回っていないらしい。
デプロイでは、モデルの実行環境構築の手間を極力少なくするために、実験環境と実行環境の両者をDockerイメージとして用意し、そのイメージをデプロイすることで実行環境依存部分の不整合による障害を減らすようにしているとのこと。機械学習プロジェクトでは多くのライブラリを使うし、バージョン不整合によって正しく動作しないなどの問題があるため、Dockerコンテナに押し込めてしまうことで環境依存をなくすアプローチは有用だと思う。ただ、あまりパワーのないエッジ側で実行するのは辛いかも。(後日談:先日ラズパイ・ゼロでも10fpsで千クラスの一般物体検知できるデモを見たので一概にそうとはいえないかも)
最後にエンジニアのキャリア形成という面では、小さなプロジェクトにおいてはマンパワー的に分業化が難しいためエンジニア自身がマルチスタック化せざるをえず、一人一人が対応する範囲は必然的に広くなるが、機械学習アルゴリズムに深く刺さっていき、その面でのスキルを強化することは難しい。一方、大規模なプロジェクトにおいては分業化が進むため一人一人の担当する領域は必然的に小さくなり全体を俯瞰できなくなるが、その分自分の担当する分野においては専門的なスキルを積み上げることができる。
とはいうものの、機械学習に限らずどのようなプロジェクトでもこういった傾向はみられるとおもうのであまり参考にはならないかもしれないとも思います。
ソーシャルゲームを分析せよ!〜社内分析チームの立ち上げから学んだデータ分析のための組織と技術
gumiが社内でデータ分析チームを立ち上げてから1年間の悪戦苦闘の歴史を紹介するセッション。実は今回の中で一番期待していたセッションでもあります。結論からいうと期待を裏切らない素晴らしいセッションでした。セッションの最初に会場への質問で「データ分析エンジニアになりたい人?」と聞いたとき1/3程度が挙手したのを見て「分析業務… やめるなら今ですよ」と(笑)
データ分析プロジェクトは2017年に社長直々の依頼で立ち上げられた。最初はコンサルティング会社と一緒に始めたが最終的には内製を選択し試行錯誤しながらデータ分析を実施し現場のプロジェクトに結果を還元してきたとのこと。
ソーシャルゲーム市場はレッドオーシャン化が進んでおり、新規ユーザーは減っているのに既存ユーザーは離脱するという中で、プランナーやプロデューサーは様々なイベントやコンテンツの追加を仕掛けて、事態の改善を図ろうとしているが仕事を抱えすぎて疲弊している。彼らを補佐するためにデータを分析して改善ポイントを提案できるチームを設立したいということだった。
現実に回っているプロジェクトを補佐するための提案であるから、その提案は現場の意向や事情を十分にくみ取ったもので、分析として正しいのみではなく、現場が受け入れ可能で実行可能なものでなくてはならない。現場に寄り添った提案でないと実際に現場に使って効果を出してもらえない。また、分析チームがいないと分析できないとなると、今度は分析チームのキャパシティがボトルネックになってしまうので、継続的に現場で運用可能であることも大事。
最初はデータ分析の専門会社に依頼していたけれど、最終的に内製にした理由がこちら。外部専門家に依頼する場合と内製の場合を比較すると以下のような表になると、かかりつけ医と大学病院という比喩を用いて説明。非常にわかりやすい。

現場が本当に望んでいるのは高度な専門的分析なのか、それとも自分の病状に合った治療や薬を処方してくれるいつもの先生なのかという視点が重要なポイントになりそうです。逆に言えば、社内分析チームは、手に負えないという兆候をつかんだらすぐに大学病院を紹介して、精密検査を受けさせる窓口として機能することも大事ということになる。
かかりつけ医として現場のプロジェクトに関わると、いずれプロジェクトの数が増えるとともに社内分析チームのキャパシティを超え破たんに近づく。分析チームの最大効果はプロジェクト専用になったとき発揮されるが、分析チームの初期目標である「標準化」と「横展開」にそぐわないので、KPI的に指標を3つのレベルに分割し、最下層は各プロジェクト固有の指標としたことで共通的な指標をプロジェクト横断で共通的に利用することが可能になった。
また、社内分析チームへの依頼が増えてレスポンスが悪くなると現場は「データだけくれ!」とか「勝手にやるから!」とか社内分析チームを「データの取り出し屋さん」としてしか見なくなる。そうすると、現場ごとにバラバラで勝手な分析を初めてしまい比較・検証もできない状態になってしまうのでそうならないよう、確立された分析手段はできるだけ現場に卸して任せるようにし、そうでないものだけを社内分析チームで担当するようにしている。しかし、いずれ分析チームがボトルネックとなり破たんすることは自明なので、できるだけ現場が自走できる環境を用意することと、溢れないように社内分析チームが「これは、やりません」ということをきちんと決めることが大事。ぶっちゃけていうと、売れているプロジェクトを分析する必要はない。
社内分析チームにはシニアアナリスト、アナリスト、データサイエンティストがいるけれど、分析は現場のプロジェクトチーム、共通基盤のインフラチームを含めた広範囲の利害関係者を含めて巻き込む必要がある。また、シニアアナリストとは技術的にハイスキルのアナリストを指すのではなく、現場や関連部署のヒアリングをはじめとした課題発見/設定に優れた人材のことだとおっしゃってました。