Generic N-Gram Markov Chaine
Markov Chaineを実装する
理論
理論については様々な解釈が散在しており、あまり、適切な文献がどれなのかわからなかったのですが、英語のWikiepediaの記述をベースに行なっています
-
N階マルコフ連鎖と呼ばれるもので実装していまして、3つ前までの携帯素から次の単語の確率分布を生成します
-
確率分布に従う形で、一つの出力確率として採択して、文章に続く文字とします。
-
1に戻ります
例えば、「Radeon」や「メガワット」という単語が現れると、次に繋がる単語の確率はこのようになります(表示されていない他の可能性は全て0)
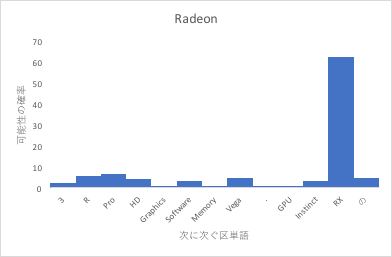
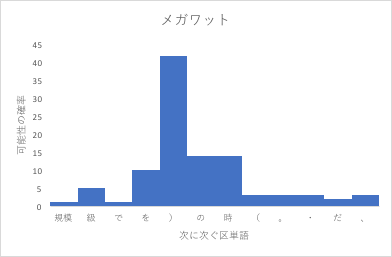
これが、2語、3語と繋がっていくと、確率の分散は小さくなり、どんどん角度の良い決定が行われるようになります。
数式は、このようになります
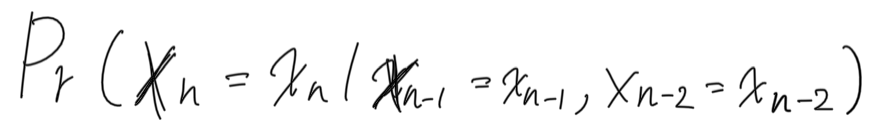
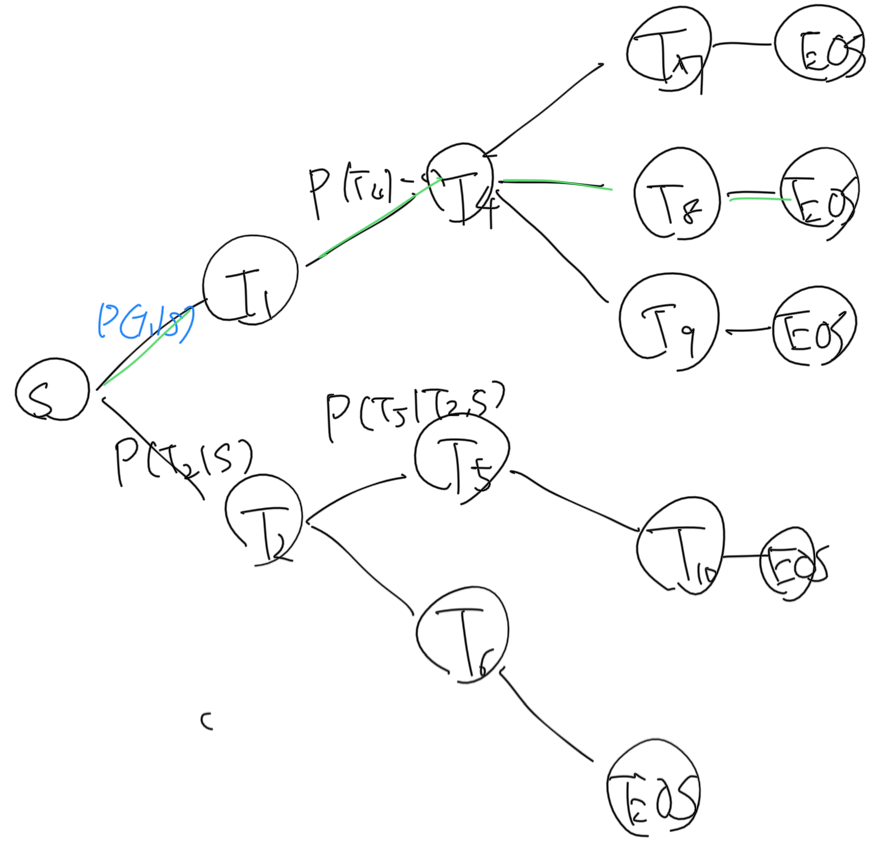
お気持的な図ですが、過去の特定の発生した単語で、このように可能性の樹形図を作成します(ビタビアルゴリズムっぽいというかそのものか)
Requirements(必要用件)
- Python3
- nvme(高速なディスクでないとKVSがパフォーマンスを発揮できませんが、実行だけなら必要ないかも)
- leveldb(確率分布を保存するKVS)
- plyvel(leveldbのpythonラッパー)
- numpy
- MeCab(形態素解析機)
- メモリできるだけたくさん
- コーパス(600万テキストほど)
今回使用したデータセットだけなら、minioというサーバで公開します
また、学習済みモデルはlevel.zipです
コードはこちらにあります
https://github.com/GINK03/generic-markov-chaine
学習
128GBのメモリでも足りなかったので、苦肉の策で、メモリを使わずにKVSをhashmapのように使うことで、メモリを省略しています
分かち書きしてコーパスを形態素粒度に変換する
(ご自身のデータセットを学習させたい場合は、コードを編集してください)
$ python3 prepare.py --wakati
ngramの特徴量を抽出し、発生頻度をカウントします(要KVSと時間)
$ python3 prepare.py --term_chaine
出現頻度から確率分布を作成して、モデルを統合します
$ python3 prepare.py --numpy
$ python3 prepare.py --wrapup
予想
初期値を適当にハードコードで与えていますが、任意の文字を与えることもできますが、KVSのキーに入っている必要があります
$ python3 prepare.py --sample
Sample1
選手 が スタメン に 名 を 刻ん だ 。 「 僕ら は ピカソ も 北斎 も ゴーギャン も 教科書 で 見 た 感じ で 、 反応 が すぐ に 売上 高 1899 億 円 ( 同 2 . 41 倍 ) に 引き上げ て も 不思議 で は ない という 司法 の 判断 を 加え ず に 、 コメント 欄 に 「 泥棒 」 という 文字 は 非常 に 低く なり つつ ある わけ です ね 。 <EOS>
Sample2
社長 に 就任 し た 小松 弥生 教育 長 など が 挨拶 を する という の は 、 悪質 コン サル 問題 に 対応 する 」 と つぶやい て いる 。 <EOS>
Sample3
5 日 ( 水 ) 26 時 40 分 博多 発 の 下り 宇都宮 行き 、 宇都宮 22 時 42 分 ) 、 地球 と まったく 同じ だ 。 企業 の 宣伝 担当 者 ) 。 蓋 を 開ける と 、 いかめしい 顔 の 男 たち の 無名 の 人 の 声 を 直接 施策 に 反映 さ れ て いる 面 も ある ブラジル の サッカー を 上手く 表現 でき たら と 思い ます 。 今 、 私 たち の 生活 に サラダ を 注文 できる よう に なっ て き て 、 4 万 人 、 外来 客 も 足 を 踏み入れ て ほしい 。 いかなる 理由 が あっ た と いう 。 <EOS>
Sample4
あと は インパネ に ある 操作 ボタン を なくし たり と 、 大手 企業 と も 呼ば れる ) を 舞台 化 し て おり ます 。 よく 『 洗濯 物 を 素早く 乾かす に は 、2 種類 の ケース サイズ を 用意 し 、 全 世界 で 1000 万 増やす ! 庶民 の ため の Apple Watch から ヘッド フォン へ 転送 さ れ ない 旨 、 その 理由 の 1 つ で Telegram が ブロック さ れ た と 言わ れ おり 、 経 産 省 が アブダビ 支援 に 力 を 入れ て いる 20 代 から 40 代 で 太もも 前 の 大腿 四 頭 筋 は 10 % そこそこ です 。 日本 の 広告 も すっかり 普通 の こと で 驚い て いる 。 <EOS>
なんとなく文法の構造を持っているのに、意味としてあまりなしていないのは、これは意味情報を適切にマルコフ連鎖は獲得できていないからです
ではどうしたらいいのかというと、Encoder-DecoderモデルのRNNを使うか、意味情報をマルコフ連鎖に入れるようにすると、意味情報を獲得することはできるような気がします(RNNの方が楽そう)
何に使えるの
文章生成に関しては、もっと系列を伸ばさないとダメでしょう。ちなみに4gram以上を追加しようとすると、メモリとディスクが足らなくなりました
それ以外の意味では、文章の校正(てにおは)、なんらかのあまり発生しない間違いは極めて低確率になるか、分布にそもそも存在しないという特徴があるので、低確率の表現を見ることで、ユニークネスやあまり可能性のフラグを立てることができます