モダンなサーバレスアーキテクチャのログ収集基盤を、App Engine + Pub/Sub + DataFlow + GCS or BigQueryのコンビネーションで作成が可能です。
このデザインは趣味で友達と作っているプロダクトのレコメンドと機械学習を行うためのデータ収集基盤として用いたいのと、会社の業務で関連会社のデータ分析もしているのですが、多くの場合、IT業から始まっていない会社はデータ収集基盤が整っていなく、私と数名でエンジニアリングに近いデータ収集からデータサイエンス領域の分析までEnd-to-Endで完結できる感じにしたいというときに便利です。
おまけで、GoogleのDataFlowのSDK version 1.XがEnd of Lifeなるということで、プログラムの移行時にハマった点を記します。
ローカルで開発するときにの注意点
-
- JDKはOracle JDKの1.8を使う(OpenJDKではダメ)
-
- Kotlin, Scalaなどで記述することも一部できるが、Java互換の言語が型の推論に失敗するようになるので、メインの部分はJavaで記述する必要がある
全体の設計

これは、一般的なログ収集基盤の基本的な構成になっており、最終的な出力先をBigQueryにすれば、高速なすぐ分析が開始できる基盤がサーバレスで作れますし、画像や言語のような非構造なデータであれば、CloudStrageを出力先にすることもできます。(なお、私個人の好みの問題で、いきなりSQLに投入せずに、CloudStrageに投入してあとからゆっくり、集計角度を決める方法が好みです)
ユーザの面からGoogle App Engineにデータを送る
Google Analyticsは様々なログ角度が集計できますが、一部限界があって、生ログを見たい時、特にユーザのクッキーやそれに類するIDなどの粒度で取得して、レコメンドエンジン等に活用したい際に要約値しかわかないという、問題があります。
また、データの深い部分の仮説立案と検証は、生ログに近い方が多くの場合はデータの粒度として適切です。ユーザのデータを追加したり、粒度を変更したりした際に効率よく吸収できる方法の一つは、データをログを保存するサーバに送りつけるという方法があります。
JQuery(フロントの知識が古くてすみません)などであると、このようなコードでデータを数秒ごとに送ったり、特定の動作と紐づけて動作させることで記録することができます。
$.ajax({
type: 'POST',
url: 'https://to.com/postHere.php', // URLはapp engine等を想定
crossDomain: true,
data: '{"some":"json"}', // ここにユーザデータが入るイメージ
dataType: 'json',
success: function(responseData, textStatus, jqXHR) {
var value = responseData.someKey;
},
error: function (responseData, textStatus, errorThrown) {
alert('POST failed.');
}
});
Pub/Subとは
Pub/Subはデータを効率的に他のサービスにつなぐことに使えます。
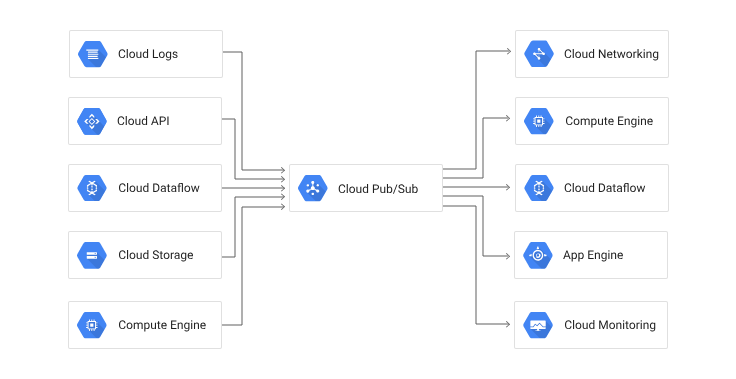
データを何らかの方法で集めて、Topicとよばれる粒度で送信し、Subscriptionに連結したサービスにつなぎます。
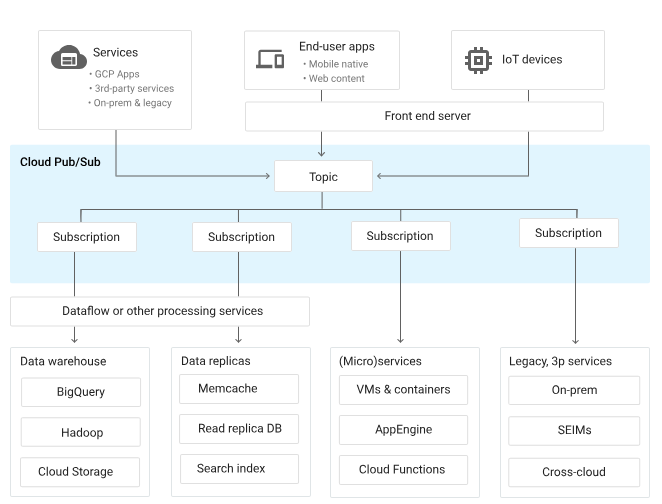
Google App EngineからPub/Subへの繋ぎ
ユーザの画面のJSから受け取ったJSONデータを一度、app engineでパースして、パースしたデータをTopicに発行することができます。
app engineに登録したコードはこのようなもを書きました。(golangとかの方が、いろいろと早いらしくいいらしいのですが、書きなれていないので、pythonのflaskを用いました)
from flask import Flask, request, jsonify
import json
from google.cloud import pubsub_v1
import google.auth
from google.oauth2 import service_account
info = json.load(open('./pubsub-publisher.json'))
credentials = service_account.Credentials.from_service_account_info(info)
app = Flask(__name__)
@app.route("/json", methods=['GET', 'POST'])
def json_path():
content = request.json
print(content)
publisher = pubsub_v1.PublisherClient(credentials=credentials)
project_id = 'YOUR_PROJECT' # project_idを入れる
topic_name = 'YOUR_TOPIC' # publish先のtopicネームを入れる
topic_path = publisher.topic_path(project_id, topic_name)
data = json.dumps(content)
future = publisher.publish(topic_path, data=data.encode('utf8')) # publishできるのはbytes型になる
return f"<h1 style='color:blue'>OK</h1>"
if __name__ == '__main__':
app.run(host='127.0.0.1', port=8080, debug=True)
app engineは以下のURLをテンプレートとして簡単に開発することが可能です。
DataFlowのstreaming処理方法
DataFlowのstreamingは実装的には、Windowと呼ばれるstreamingの取得粒度(多くは5分などの時間間隔)を設定して、データをパイプライン処理で変換で変換し、任意の出力先に出力することが可能です。
いろいろな用途が期待され、うまくスキャン間隔を設定することで、リアルタイムの異常検出などもできます(下図のstreaming + accumulationが該当するかと思われます)。

streamingのDataFlowはGCEのインスタンスが起動し、定期的に実行していることでstreamingとしているので、インスタンスが立ちっぱになるので、金額的にbatch処理より安くない要因になっているように思います。
DataFlow pipeline
DataFlowはpipelineで動作を定義することができ、jsonなどの何かの非構造化データが入力されているとすると、何かのサニタイズ処理、パース処理、変換処理を行うことができます。ここで分析角度が決定しているのであれば、BigQueryにそのまま投入すればいいはずです。
今回は、取得粒度をあとから丁寧に決定したいというモチベもあり、なんの変換もせずに、GCSに吐き出しています。
public static void main(String[] args) {
kt.funcs.testCall();
DataflowPipelineOptions options = PipelineOptionsFactory.create().as(DataflowPipelineOptions.class); //Dataflow.classを用いているがただのPipeLineだとローカルで動作する
options.setProject("ai-training-16-gcp"); // GCPのプロジェクトを追加する
options.setStagingLocation("gs://abc-tmp/STAGING"); // stagingはJavaのコンパイルされたjarファイル等が置かれる
options.setTempLocation("gs://abc-tmp/tmp"); // 何かの中間ファイルなどが吐かれる、ことがある
options.setRunner(DataflowRunner.class);
options.setStreaming(true);
options.setJobName("streamingJob6"); // Jobの名前
Pipeline p = Pipeline.create(options);
PCollection p1 = p.apply(PubsubIO.readStrings().fromSubscription("projects/ai-training-16-gcp/subscriptions/sub3")) // Pub/Subのデータをpull方式で取得できるサブスクリプションを追加する
.apply(Window.<String>into(FixedWindows.of(Duration.standardMinutes(1)))); // 何分ごとにpullしてデータを処理するか
POutput p2 = p1.apply( TextIO.write() // ここにpipelineで処理を追加すれば必要な変換やサニタイズを行うことができますが、直接GCSに吐き出しています。
.withWindowedWrites()
.withNumShards(1)
.to("gs://abc-tmp/OUTPUT") );
p.run().waitUntilFinish();
}
Beam SDK 1.Xから2.Xで対応すべきこと
最初の頃は、JavaをKotlinで一部ラップアップして使っていたのですが、どうにも2.Xにしてからうまく動作しません。
わかったことでは、パイプラインの.applyメソッドをチェーンして動作を定義していくのですが、型推論に失敗するようです。
そのため、かなり冗長ですが、コンパイルに失敗する段階で、POoutputの変数に束縛することで、動作します(ツラすぎる...)
(以下はminimal wordcountの例)
public static void main(String[] args) {
//kt.funcs.filter1(" ");
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options);
PCollection p1 = p.apply(TextIO.read().from("gs://apache-beam-samples/shakespeare/*"))
.apply( ParDo.of(new kt.KProc1()))
.apply( Filter.by( (String chars) -> kt.funcs.filter1(chars) ))
.apply( ParDo.of(new kt.KProc2()))
.apply( GroupByKey.create())
.apply( ParDo.of(new JProc1()) );
POutput p2 = p1.apply( TextIO.write().to("wordcounts") ); // ここで、このようにする必要がある
p.run().waitUntilFinish();
}
コード
今回、意図通りに動作していることを確認した、全体のappengineのコード、pubsubのセットアップスクリプト、dataflowのコードは以下のgithubのこのディレクトリにまとめてあります。(必要ならばリテラルを適宜書き換えてください)
まとめ
最近のクラウド利用法一般に言えることですが、何やら、ここの言語の選定やら細かいところとかいろいろあるのですが、なにかやりたいXに対して、素晴らしい解決策のこれとこれとこれを組み合わせると動くよ!というデザインが一般化されているように思います。