seq2seq sort
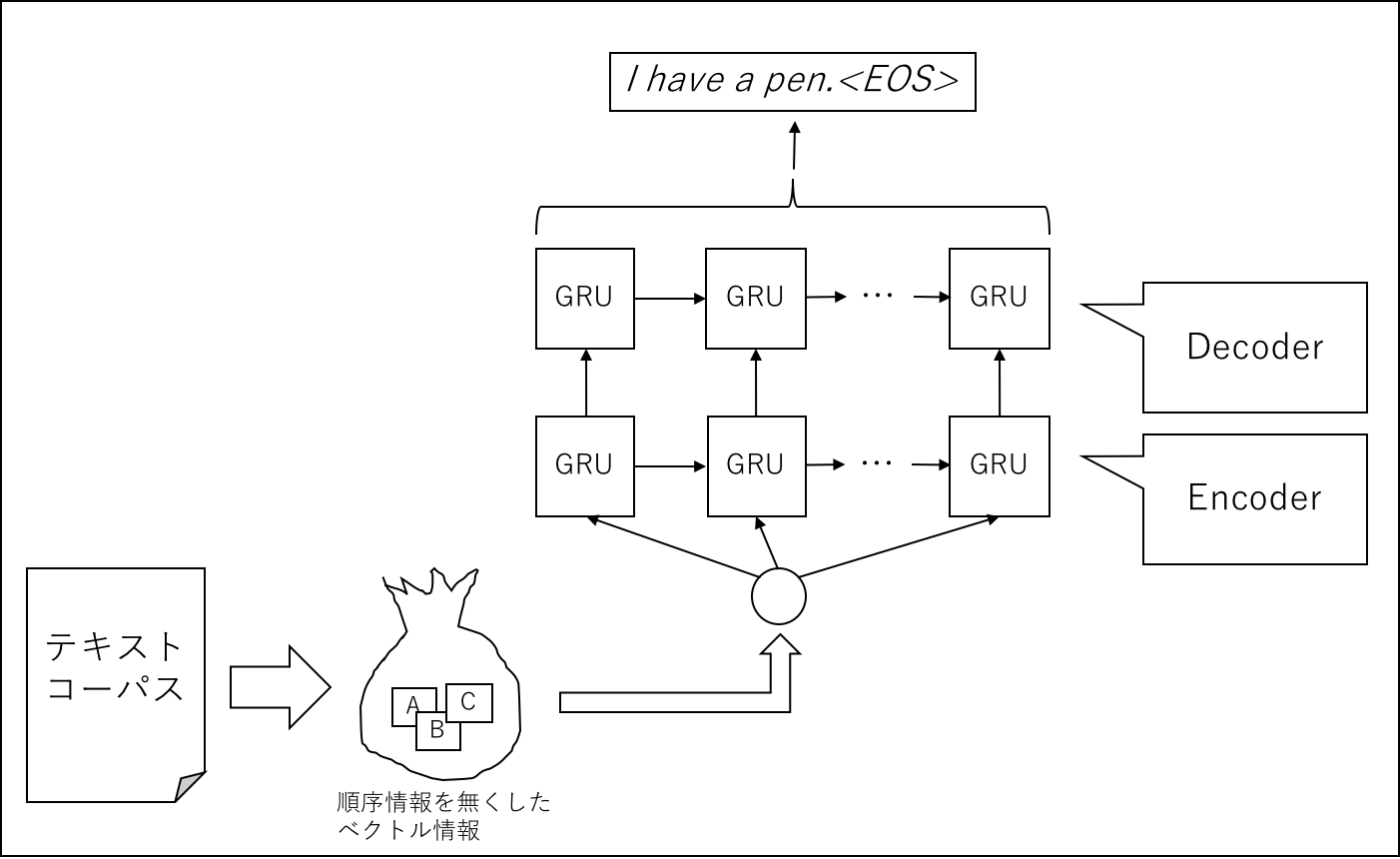
並び順がなくなった文字列から、文字のもとの文字列を復元
-
seq2seqのタスクの一つであるソートを自然言語に拡張します
-
キャラクタレベル(文字粒度)で順序情報を失ったベクトル情報に対してベクトルを入力として、元の文章を構築しようと試みます
もともとの想定していたユースケースとしては、アイディアを出し合うようなブレインストーミングなどで、よく付箋などを使ってキーワードをポスイットなどで張って、それから最終的に言いたいことを構築するようなことを、よくやるのですが、そういったキーワード群を投入することで、自然に導きたい情報を帰結させることもできるなとか思いました。
単語でやろうとすると入力次元が高次元になりすぎて、ネットワークサイズの限界にぶつかり、文字の並び替えのタスクを今回は与えてみます
先行研究
文字列を破壊してキャラクタ粒度のベクトル列から元の文字列の並びを復元する
- 東洋経済さんのオンラインコンテンツの記事タイトルを利用
- キャラクタ粒度で分解してBag of Wordsのようなベクトル表現に変換
- Encoderの入力を行いキャラクタをベクトル化して、Decoderで元の文字列の並びを予想
ネットワーク
なんどか試してうまくいったモデルを使用したいと思います
enc = input_tensor
enc = Flatten()(enc)
enc = RepeatVector(30)(enc)
enc = GRU(256, dropout=0.15, recurrent_dropout=0.1, return_sequences=True)(enc)
enc = TimeDistribute(Dense(3000, activation='relu'))(enc)
enc = Dropout(0.25)(enc)
dec = Bidirect(GRU(512, dropout=0.30, recurrent_dropout=0.25, return_sequences=True))(enc)
dec = TimeDistribute(Dense(3000, activation='relu'))(dec)
dec = Dropout(0.5)(dec)
dec = TimeDistribute(Dense(3000, activation='relu'))(dec)
dec = Dropout(0.1)(dec)
decode = TimeDistribute(Dense(3135, activation='softmax'))(dec)
前処理
東洋経済さんのコンテンツをスクレイピング
$ python3 12-scan.py
スクレイピングしたhtml情報を解析してテキスト情報を取り出す
$ python3 16-parse-html.py
テキスト情報とベクトル情報のペアを作成
$ python3 19-make_title_boc_pair.py
機械学習できる数字のベクトル情報に変換
$ python3 23-make_vector.py
学習
学習を行う
(データサイズが巨大なので、128GByte程度のメインメモリが必要になります)
$ python3 24-train.py --train
...
categorical_crossentropyの損失が0.3程度に下がると、ある程度の予想が可能にまります
GTX1060で三日程度必要でした
評価
入力に用いた順番が崩された情報と、それらを入力に、並び替えてそれらしい文字のペアはこのようになります
入力 ['、', 'が', 'ル', 'ダ', '子', 'を', '日', '銀', '本', '団', '上', 'メ', '男', '定', '体', '以', '確', '球', '卓']
出力 卓球男子団体、日本が銀メダ以以上を確定<EOS>
入力 ['は', 'い', 'リ', 'た', 'ャ', 'ル', '界', 'し', 'に', 'て', '戦', '由', '表', 'シ', '挑', '自', '限', '現']
出力 シャルリは表現の自由の限界に挑戦していた<EOS>
入力 ['「', 'は', '」', 'た', '国', 'と', 'に', 'る', '消', 'え', '攻', '米', '北', '朝', '鮮', '先', 'よ', '撃', '制', '藻', '屑']
出力 米国による「北朝鮮先制攻撃」は藻屑と消えた<EOS>
入力 ['、', 'が', '国', '世', '界', '子', '主', '沸', '騰', 'す', '部', 'る', 'マ', 'ス', '業', '中', '品', '電', '救', 'ホ']
出力 中国スマホが救世主、沸騰する電子部品業界<EOS>
コード
GitHubにございますので、確認してください
終わりに
最初、単語粒度のベクトルを入力に文字列の復元をやっていたんですが、入力があまりにも高次元になってしまったこと、コンピュータリソース的に学習が難しいという背景がございました
そのため、何度か手法を整理したのですが、キャラクタ粒度は学習が簡単な反面、あまり面白くないです
RNNで最大の課題だなと感じるのが、オンメモリで入力用の密行列を保持するのが難しいことです。メモリの量が有限なので、なんらかの方法で安定化させる方法が求めらていますが、なんかうまい方法ないでしょうかね。