導入・目的
Twitterでは#名刺代わりの小説10選というタグが存在し、2018 ~ 2020/10/25までにおおよそ8000ツイートをちまちまと集めることができました。
このタグから、レコメンドを行いたいと思います。データ数的に、けんすうさんが制作したMNMほどデータを集めることができなかったので、機械学習のアプローチを用いずにレコメンドを行いたいと思います。
|
|---|
| サンプルツイート |
方法
どんなレコメンドであっても基本は共起を用いたアプローチを取ることが多いです。これは行列分解を行うMatrix Factorizationなどや類似のアルゴリズムは共起を基本としたアルゴリズムほとんどに言えることです。
一般には機械学習をベースとしたアプローチが主流ですが、次元圧縮等を伴わない場合(つまり、汎化を気にしない場合)、テーブル操作のみで同等のことが行えます。
#名刺代わりの小説10選のツイート構造が好きな10冊の本のタイトルを紹介するもので、ある一冊に着目し、周辺に共起となるタイトルが散らばっていると考えることができます。
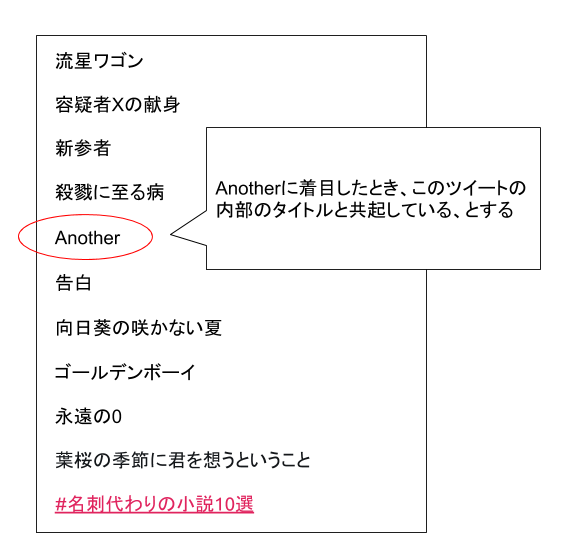
あるタイトルの周辺に散らばっているタイトルをうまく集計していくことで、どのような本がある本の近くに現れやすいのかを定量化することができます。
前処理
ツイートは自然言語で記述されており、基本は"本のタイトル"/"著者"で構成されていますが、例外も多く、『』でタイトルや本が指定されているもの、|で分画されているもの、タイトルと著者が逆転しているものと様々です。
基本的にはヒューリスティックにそこそこパースできるプログラムを目指すのですが、以下のようなコードになってしまいます。
import re
import mojimoji
total = []
for tweet in df["tweet"]:
if not isinstance(tweet, str):
continue
block = []
tweet = mojimoji.zen_to_han(tweet, kana=False)
for line in tweet.split("\n"):
line = line.strip()
if "#" in line:
continue
if line == "":
continue
if "「" in line and "」" in line:
a = re.search("「(.*?)」", line).group(1)
b = re.sub("「.*?」", "", line)
block.append(a)
block.append(b)
elif "『" in line and "』" in line:
a = re.search("『(.*?)』", line).group(1)
b = re.sub("『.*?』", "", line)
block.append(a)
block.append(b)
elif "(" in line and ")" in line:
a = re.search("\((.*?)\)", line).group(1)
b = re.sub("\(.*?\)", "", line)
block.append(a)
block.append(b)
elif "/" in line and line.count("/") == 1:
a, b = line.split("/")
block.append(a)
block.append(b)
elif "|" in line and line.count("|") == 1:
a, b = line.split("|")
block.append(a)
block.append(b)
elif re.split("\s{1,}", line).__len__() == 2:
a, b = re.split("\s{1,}", line)
block.append(a)
block.append(b)
else:
pass
total.append([x.strip() for x in block])
精度は64%で、64%のツイートでパースすることに成功しました。
著者情報
また、Wikipediaの小説家一覧より、小説家をすべて定義します。そうすることで、タイトルだけをユニークに取り出すことができ、著者とタイトルを分離できます。
# 著者の名前が記されたcsvを読み込み
names = pd.read_csv("var/auths.csv")["name"].tolist()
# titleの抽出
total = [[x for x in block if x not in names and x in titles ] for block in total ]
total = [x for x in total if x.__len__() >= 1]
人気の本、著者
本筋からはずれますが、みなさんがよく上げる10冊の中にあるタイトルには、以下のようなタイトルがあることが分かりました。
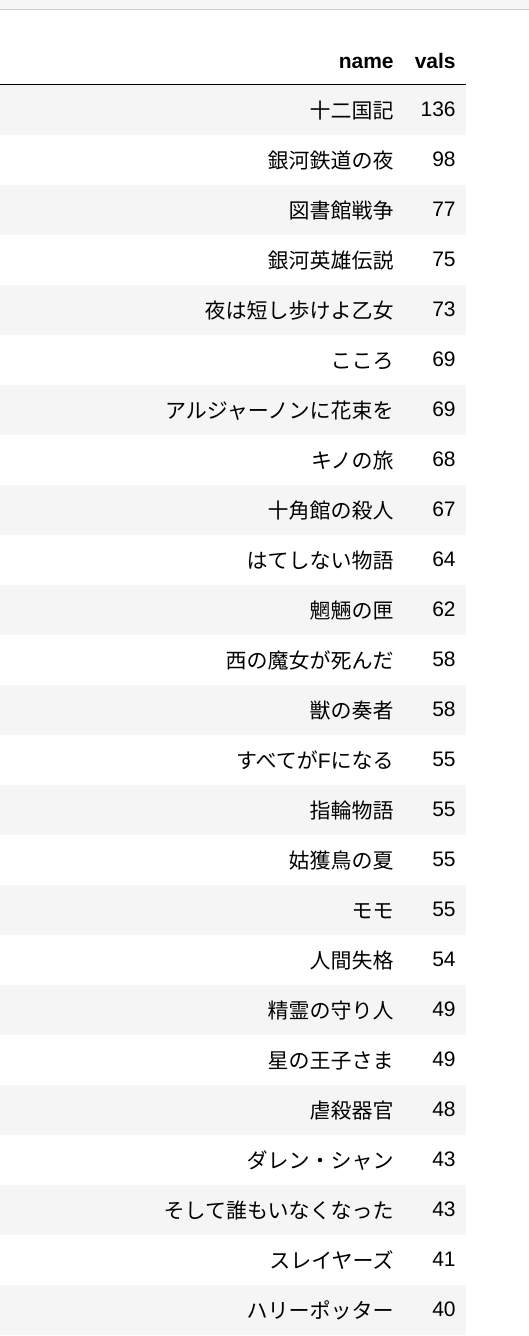
この中からだと、私は星の王子さまと虐殺器官が好きです。
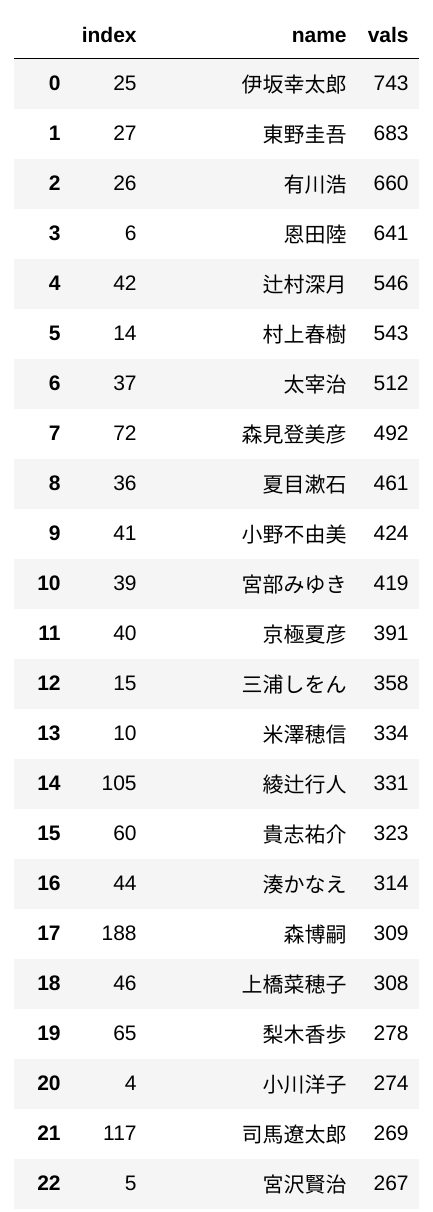
また作家ランキングだと以下のようになります。
共起を計算する
totalというlistを共起するタイトルをtitle_cos 変数の中にどんどん追加していき、すべて追加し終わったあとに、最大値で割り込むことでnormalizeした各タイトル(title)ごとに共起しやすいタイトル(co)を一覧で表現することができます。
title_cos = {}
for block in total:
for title in block:
title_cos[title] = title_cos.get(title, []) + block
tmps = []
for title, cos in list(title_cos.items()):
cos = Counter(cos)
max_ = max(cos.values())
tmp = pd.DataFrame({"co": list(cos.keys()), "val": list(cos.values())})
tmp["title"] = title
tmp = tmp[tmp.val >= 2]
tmp["val"] /= max_
tmps.append(tmp.sort_values(by=["val"], ascending=False)[:300])
#print(title)
ret = pd.concat(tmps)
ret = ret[["title", "co", "val"]]
ret
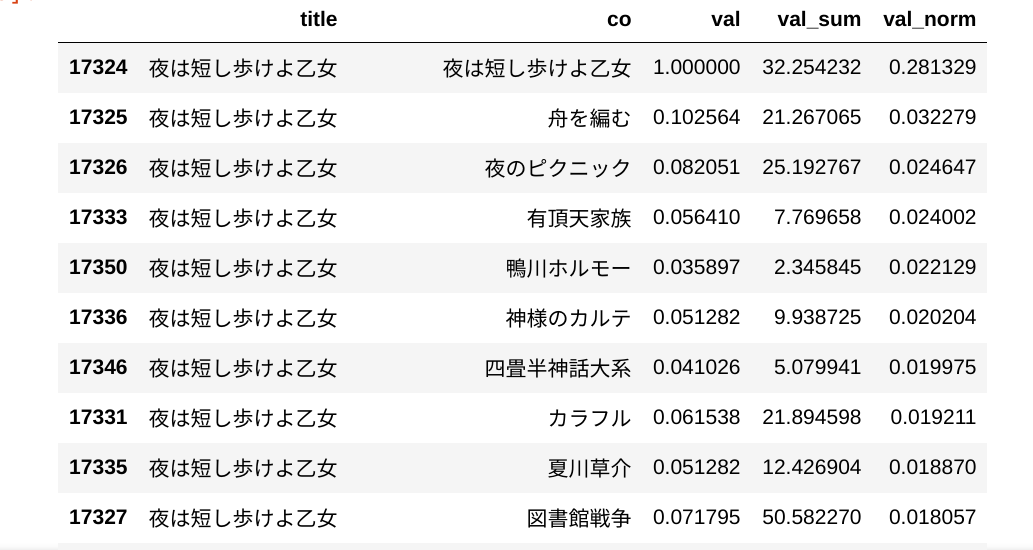
例えば、夜は短し歩けよ乙女を見てみるとそれらしく出ています。
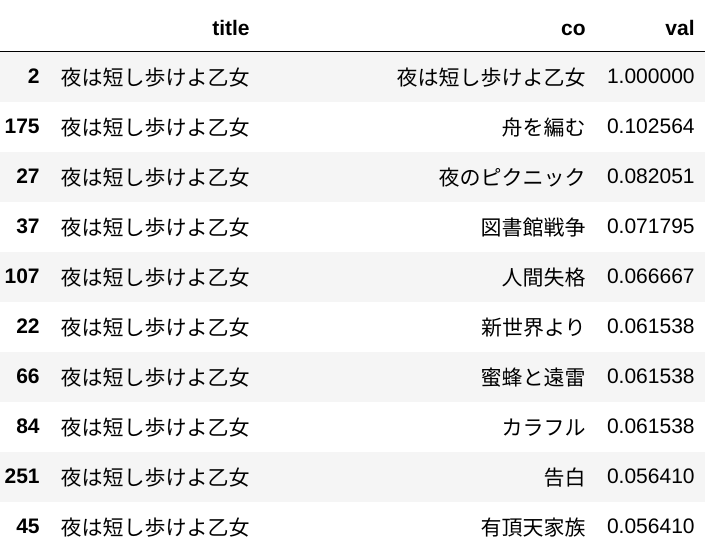
頻出するものは重要でない仮説を導入する
自然言語処理などでよく使われる理論にtfidf等が存在しますが、idf部分はレアリティが高いものを高いスコアに、頻出するものは低いスコアにするヒューリスティックです。
この仮説は割とどこでも適応可能で、今回のようなケースにも実際に適応可能でした。
具体的にはTOP 300以内によく登場する本はあまり重要でない仮説を導入します。
w = ret.groupby(by=["co"]).agg(val_sum=("val", "sum")).reset_index()
df = pd.merge(ret, w, on=["co"], how="left")
df["val_norm"] = df["val"]/np.log(df["val_sum"]+np.e)
tmps = []
for title, s in df.groupby(by=["title"]):
tmps.append(s.sort_values(by=["val_norm"], ascending=False))
df = pd.concat(tmps)
その上で、夜は短し歩けよ乙女を見てみると微妙に内容的に遠いのでは?と考えていた、図書館戦争や人間失格が有名だから共起していましたが、この改良版ではランクが下がりました。
結果
作家の粒度でも簡単に実行でき、村上春樹だと以下のようになります。

Google Spreadsheetで誰でも見れるようにおいてあるのでご自身の好きなタイトルや作家さんを探してみましょう(作者名フィルタで落としきれなかったノイズも多少あり、これは手動でフィルタを追加するしかなさそうです)
私はハーモニーに関連する本をいくつか読んで自分で定性的に評価したのですが、かなり良かったです。紫色のクオリアとか淵の王とはちゃんと出るのは良さがあります。
考察
データ数がそんなになくとも、pandasでデータをゴニョゴニョしてテーブル操作するだけで、割とまともな結果を得ることができました。
MatrixFactorizationなどをこのような課題設定で使うことも可能なのですが、そのまま適応してしまうと、メジャーなタイトルに寄せられてしまう問題やハイパラであるどういう性質がある本にどういう割引を行うか、などを機械学習のブラックボックス性故に少し感覚値がつかみにくいなどがあります。しかし、今回の方法だと目で見て感覚を掴みながら調整できるので、どのへんが良さそうなのかすぐ探索できます。
まとめ
個人でさっとバズったTwitterのハッシュタグを集めて分析して、自分のQoLを上げるのは良さそうです。
今回、集めた8000近くのツイートやjupyterのクソコード等はGitHubで公開していますので、ご自由にどうぞ。。。