Keras im2txt (Show and Tell)
Kerasでのim2txtの実装系
TensorFlowの有名な例である、im2txt(Show and Tell)の実装系をGoogleの識別ネットワークのGoogLeNetではなく、VGG16というモデルを用い、
VGG16はもとの1000クラス識別問題に最適化されたプリトレインドモデルを用いるなどをして、計算負荷を下げたモデルを構築しました
日本語を出力するネットワークはまだわたしも知らないので、あまり見たことがないネットワークかもしれません
Tensorflowとの違い
- 学習できる
- GoogLeNetではなくVGG16を利用
- 日本語(カタカナのみ)に対応
- 画像識別層をフリーズしているので高速の可能性がある
- 画像識別層が直接decoderのRNNに入力されるわでなく、encoderのRNNに一度入力される
ネットワーク
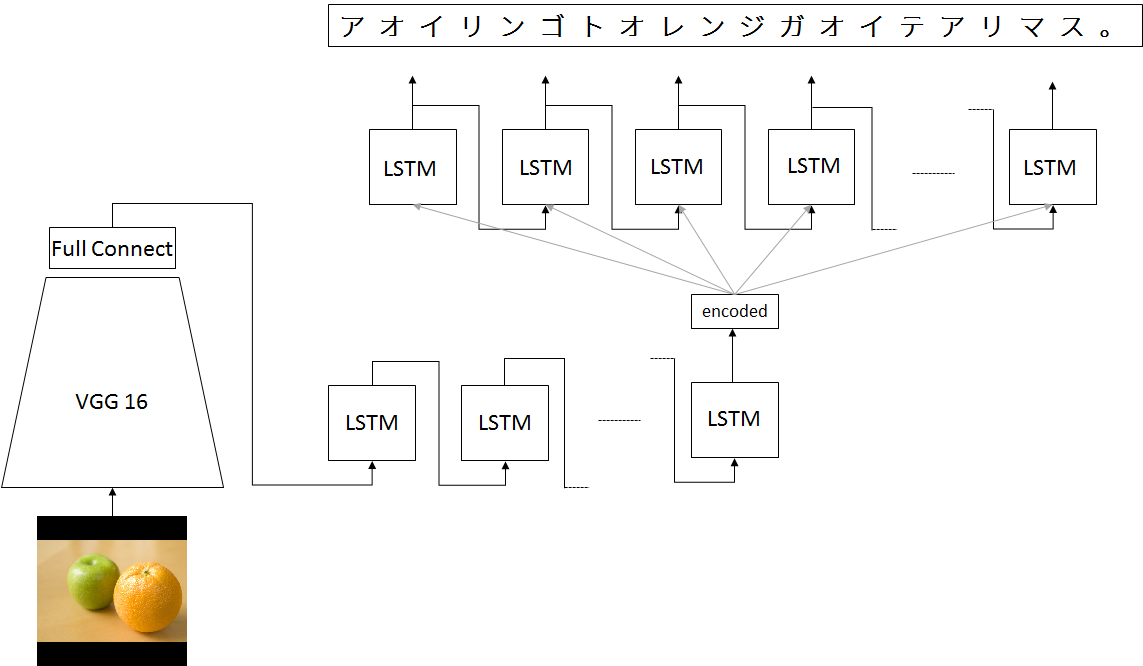
直接VGG16からの入力を用いるのではなく、一度、seq2seqのモデルを参考に、エンコードしています
これには理由があって、VGG16がプリトレインモデルを利用したためか、直接、decoderの入力にすると収束してくれる気配がありません
試行錯誤しているなかで、encoderの入力にVGGの出力を利用するとうまくいくことを発見しました
モデル
Keras2でモデルを組みました
Attentionを取り出そうかと思ったのですが、また別の機会にそれはやってみたいと思います
input_tensor = Input(shape=(150, 150, 3))
vgg_model = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
vgg_x = vgg_model.layers[-1].output
vgg_x = Flatten()(vgg_x)
vgg_x = Dense(768)(vgg_x)
DIM = 128
timesteps = 50
""" encoder側は、基本的にRNNをスタックしない """
inputs = RepeatVector(timesteps)(vgg_x)
encoded = LSTM(768)(inputs)
encoder = Model(input_tensor, encoded)
timesteps = 50
DIM = 128
x = RepeatVector(timesteps)(encoded)
x = Bi(LSTM(768, return_sequences=True))(x)
decoded = TD(Dense(DIM, activation='softmax'))(x)
t2i = Model(input_tensor, decoded)
t2i.compile(optimizer=Adam(), loss='categorical_crossentropy')
データセット
MS COCO2014というアノテーション付きのデータセットを用いて学習を行いました
残念ながら、MS COCOは英語のアノテーションなので、Yahoo Japanがクラウドソーシングでデータをつけ直したものを用いて、日本語で学習します
今回は簡単のため、char levelのRNNを構築しました。ボキャブラリが増えすぎることは望ましくないという判断で、日本語をすべてカタカナ表現にして、one hot vector表現としました
結果として128次元に収めることができました
学習
もともとMS COCOと日本語アノテーションがつく件数がそんなに多くなかったのと、手持ちの学習環境ではそんなにたくさん学習することができなかったため、5000件程度にとどめてあります
当然汎化性能を十分に確保するには、十分なデータセットが必要になります
input image size: 150 x 150
RNN-length : 50
optimizer : Adam, SGD, RMSprop
epoch : 3000(1200epochぐらいがよい)
loss-function : softmax + categorical-crossentropy
学習の結果です、lossが下がり続けています
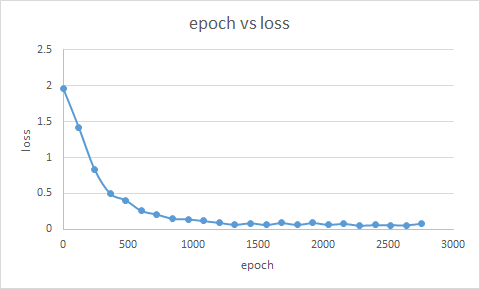
図2. epoch vs loss
結果
テストデータに関して汎化が十分になく、30000件ほどしか学習データが確保できませんでした
そのため、未知の学習データセットで、まだ十分に汎化が確保できていません。大学の研究や、国家機関、大企業などがやると良いかもしれません

コード
github.com
(コードに関しては、MITライセンスとかにしたいと思います。再利用していただいて構いません)