機械学習用のデータセットを訓練データと検証データに分割する際、GroupKFoldは頻繁に使用される方法の1つだと思いますが、前処理にPandas API on Sparkを使っていたらデータセットをGroupKFoldで分割する際に困ったので、記事にまとめてみました。
なお、以下の作業は全てDatabricksのNotebook上で実行したものです。
サンプルデータの準備
まず、この先の説明で使用するサンプルデータを準備します。今回はDatabricks上にあるサンプルデータを使用します。データの内容はこの記事においては特に重要ではありませんが、とある企業の顧客への請求データらしきものになっています。
一応コードを記載していますが、これはあくまでもDatabricks上でのやり方で、ここに深い意味は無いのでサラッと流して頂いて問題ありません。
# Databricks上にあるサンプルデータを一旦Sparkで読み込み、Pandas DataFrameに変換
sample_pddf = spark.read.option("header", "True").csv("/databricks-datasets/online_retail/data-001/data.csv").toPandas()
# この後のGroupKFoldでグループのキーに使う "CustomerID"列がNULLのレコードを削除
sample_pddf.dropna(subset=["CustomerID"], inplace=True)
display(sample_pddf)
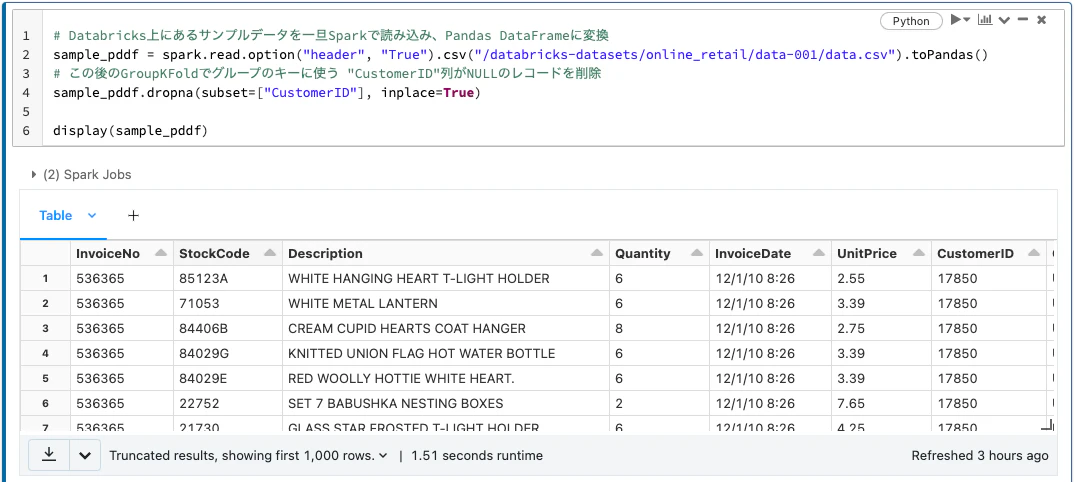
上記のデータに含まれる CustomerID というカラムをグループのキーにして、GroupKFoldをするのが目的です。つまり、同じCustomerIDを持つデータは必ず同一のFoldの中に含まれ、異なるFoldを跨いで分割されることが無いようにします。
PandasでScikit-learnのGroupKFoldを使用する場合 (当然うまくいく)
通常のPandas DataFrameを使用している場合、GroupKFoldはScikit-learnを使用することで簡単に出来ます。以下の様な具合ですね。
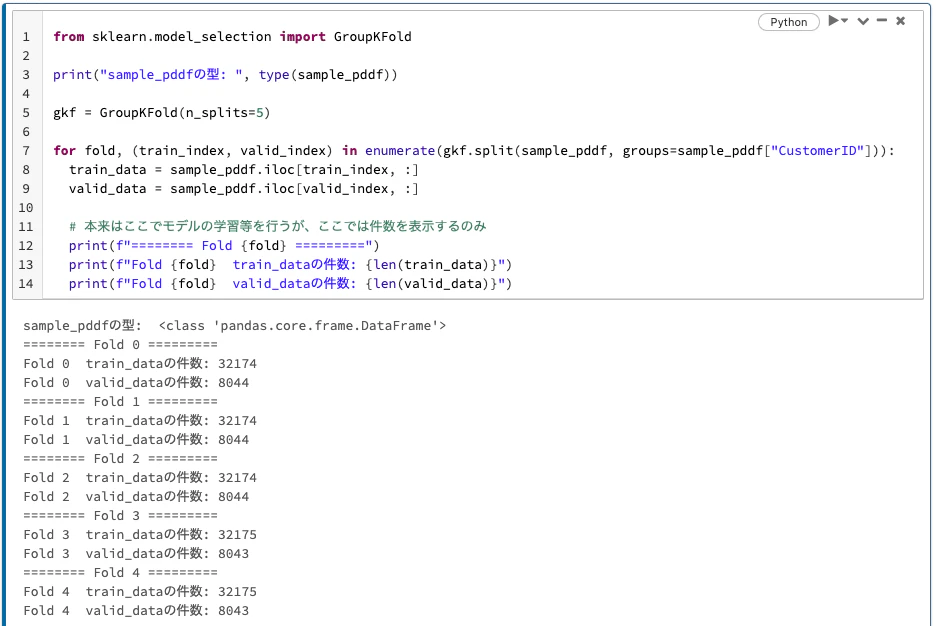
from sklearn.model_selection import GroupKFold
print("sample_pddfの型: ", type(sample_pddf))
gkf = GroupKFold(n_splits=5)
for fold, (train_index, valid_index) in enumerate(gkf.split(sample_pddf, groups=sample_pddf["CustomerID"])):
train_data = sample_pddf.iloc[train_index, :]
valid_data = sample_pddf.iloc[valid_index, :]
# 本来はここでモデルの学習等を行うが、ここでは件数を表示するのみ
print(f"======== Fold {fold} =========")
print(f"Fold {fold} train_dataの件数: {len(train_data)}")
print(f"Fold {fold} valid_dataの件数: {len(valid_data)}")
Pandas API on Spark を使用する場合 (失敗する)
一方、Pandas API on SparkのDataFrameを使用している場合、同じ様には行きません。実行しようとすると以下のように PandasNotImplementedError になります。
from sklearn.model_selection import GroupKFold
import pyspark.pandas as ps
# ネイティブなPandas DataFrameを、Pandas API on SparkのDataFrameに変換
sample_psdf = ps.from_pandas(sample_pddf)
print("sample_psdfの型: ", type(sample_psdf))
gkf = GroupKFold(n_splits=5)
for fold, (train_index, valid_index) in enumerate(gkf.split(sample_psdf, groups=sample_psdf["CustomerID"])):
train_data = sample_psdf.iloc[train_index, :]
valid_data = sample_psdf.iloc[valid_index, :]
# 本来はここでモデルの学習等を行うが、ここでは件数を表示するのみ
print(f"======== Fold {fold} =========")
print(f"Fold {fold} train_dataの件数: {len(train_data)}")
print(f"Fold {fold} valid_dataの件数: {len(valid_data)}")
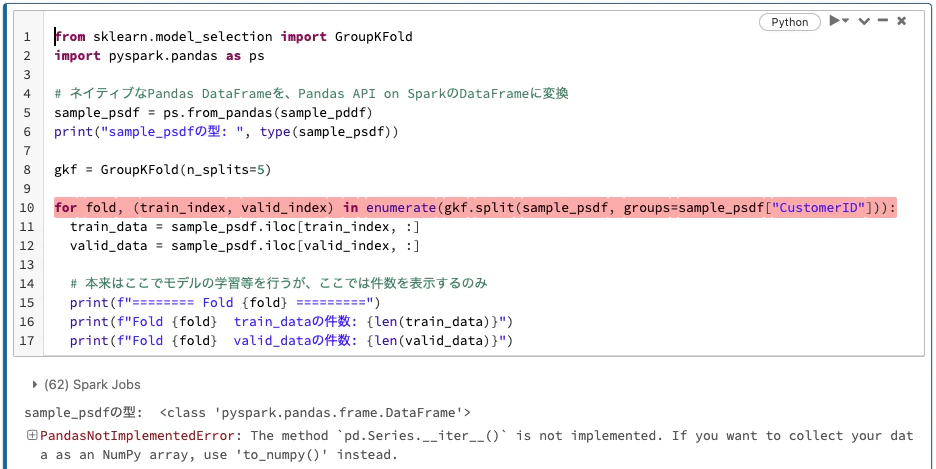
メッセージから察するに、sklearnはネイティブなPandas DataFrameとして扱おうとしているが、実際はPandas API on SparkのDataFrameなのでエラーが発生しているように見えます。
もちろん Pandas API on SparkのDataFrameをネイティブなPandas DataFrame を変換すればsklearnのGroupKFold がそのまま使えるわけですが、それではSparkが機能せずシングルノードの処理となり、大規模なデータセットには対応できなくなってしまいます。
Pandas API on Spark のみで実装する代替案
そこでsklearnのGroupKFoldを使わずに、Pandas API on Sparkのみの簡単なコードで代替できるか試してみます。
基本的な考え方は、
- CustomerID毎にレコードの件数を出し、
- それをもとに各Foldに含まれるレコード件数がだいたい同じくらいになるようにし、
- 同じCustomerIDのレコードは必ず同じFoldに属する
ようにできれば最低限は使えそうだな、というものです。これを実装したのが以下の関数です。
# 分割したいDataFrame, グループのキーとするカラムの名前、分割数を引数に取る
def group_k_fold_ps(df, group_column, n_splits=5):
# group_column毎のレコード件数をカウント
counts_by_group = df.groupby(group_column)[group_column].count().rename("num_records", axis=1).reset_index()
# group_column毎のレコード件数のCumlative Sumを追加
counts_by_group["cum_sum"] = counts_by_group["num_records"].cumsum()
# 全体の件数を分割数で割り、1 Foldあたりの件数の目安を決める
n_per_fold = round(counts_by_group["num_records"].sum() / n_splits)
# "fold"列を追加し、デフォルト値としてダミーの値をセット
counts_by_group["fold"] = 99
# 最終Foldの1つ前までは、1 Foldあたりの件数の目安を元にFoldの値を割り当てる
for fold in range(n_splits - 1):
lower_boundary = n_per_fold * fold
upper_boundary = n_per_fold * (fold + 1)
counts_by_group.loc[(counts_by_group["cum_sum"] >= lower_boundary) & (counts_by_group["cum_sum"] < upper_boundary), "fold"] = fold
# 残っている(foldがダミーのままになっている)レコードには最終Foldを割り当て
counts_by_group.loc[counts_by_group["fold"] == 99, "fold"] = n_splits - 1
fold_assignments = counts_by_group[[group_column, "fold"]]
# group_columnを結合キーにして、元々のDataFrameに割り当てたfoldを付加する
return df.merge(fold_assignments, on=group_column, how="left")
この関数を今回のサンプルデータに対して実行してみます。
ps.set_option('compute.ops_on_diff_frames', True)
sample_psdf_with_folds = group_k_fold_ps(sample_psdf, group_column="CustomerID", n_splits=5)
display(sample_psdf_with_folds)

結果、一番右に"fold"列が追加されているのが分かります。
それでは同じCustomerIDのレコードがきちんと同じFoldに属しているかどうか、確認します。
# CustomerID毎に、fold列のユニークの値の数を出す
n_folds_per_session = sample_psdf_with_folds.groupby("CustomerID")["fold"].nunique()
# ユニークの値の数が1でないものを表示
n_folds_per_session[n_folds_per_session != 1]

上記の結果から、複数のFoldに属しているCustomerIDは無く、どのFoldに属していないCustomerIDも無いことが分かります。ここは期待通りの結果になっています。
ここまで出来ればあとはこの結果を使うだけで、以下の様にすればCVが行えるかと思います。
for fold in range(5):
train_data = sample_psdf_with_folds[sample_psdf_with_folds["fold"] != fold]
valid_data = sample_psdf_with_folds[sample_psdf_with_folds["fold"] == fold]
# 本来はここでモデルの学習等を行うが、ここでは件数を表示するのみ
print(f"======== Fold {fold} =========")
print(f"Fold {fold} train_dataの件数: {len(train_data)}")
print(f"Fold {fold} valid_dataの件数: {len(valid_data)}")

まとめ & 残課題
作業としてはこれで終わりなのですが、上記の結果を見てよろしくない点に気付かれた方も多いでしょう。sklearnを使った場合と比べると、trainとvalidの件数がFoldによって結構違ってしまっています。
今回の実装だと、各CustomerIDが持つCumlative Sumの値が各Foldの下限値(lower_boundary)と上限値(upper_bondary)に間に収まるかどうかでFoldを決めています。そのため、ちょうど境界部分にくるCustomerIDが他のCustomerIDよりも著しく多くのレコードを持っていたりすると、Fold間での件数の差が大きくなってしまうことがあります。また、今回使用しているサンプルデータは4万件程度しかないのですが、このような小さなデータセットほど、この件数差が与える影響は大きなものになるでしょう。
一方、大規模なデータセットの場合、この件数差があっても割合としては非常に小さなものになるので、その影響はさほど無いと言っても良いかなと思いました。