書かれた時期: 2015/6/8
著者: Song Han, Jeff Pool, John Tran, William J. Dally
原著リンク
Abstract
- ニューラルネットワークの冗長な重みを間引いて計算効率を向上させる提案
Introduction
- ニューラルネットワークは進歩とともにパラメータ数が多くなり計算コストが増大
- DRAMアクセスも増えてより多くのエネルギーが必要

DRAMアクセスが消費エネルギーの中で支配的であることが読み取れる - 精度を維持しつつパラメータを間引いて計算コストを下げる
- これによりモバイル機器上でリアルタイム処理も可能になる
Related Work
-
[11] Vincent Vanhoucke, Andrew Senior, and Mark Z Mao. Improving the speed of neural networks on cpus. In Proc. Deep Learning and Unsupervised Feature Learning NIPS Workshop, 2011.
8bit固定小数点を使って計算を端折る研究 -
[12] Emily L Denton, Wojciech Zaremba, Joan Bruna, Yann LeCun, and Rob Fergus. Exploiting linear structure within convolutional networks for efficient evaluation. In NIPS, pages 1269–1277, 2014.
オリジナルのニューラルネットに対して1%以内の精度低下で低ランクの近似したパラメータを見つける研究 -
[13] Yunchao Gong, Liu Liu, Ming Yang, and Lubomir Bourdev. Compressing deep convolutional networks using vector quantization. arXiv preprint arXiv:1412.6115, 2014.
深層畳み込みネットワークをベクトル量子化により圧縮する研究
パラメータの間引きとは別のアプローチのネットワーク圧縮手法 -
[14] Song Han, Huizi Mao, and William J Dally. Deep compression: Compressing deep neural network with pruning, trained quantization and huffman coding. arXiv preprint arXiv:1510.00149, 2015.
上記の研究の発展、というかこの提案と上記の量子化とさらにハフマン符号化の圧縮の3つを組み合わせたもの -
[15] Min Lin, Qiang Chen, and Shuicheng Yan. Network in network. arXiv preprint arXiv:1312.4400, 2013.
全結合レイヤーをglobal average poolingに置き換えることでパラメータ数を削減する研究
ネットワークインネットワークアーキテクチャを使ったもの -
[16] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. arXiv preprint arXiv:1409.4842, 2014.
上記でGoogLenetを使ったもの
事前学習済みのパラメータを使うトランスファーラーニングにおけるファインチューニングではこのアプローチは難しい
リニアレイヤーを頭に追加してトランスファーラーニングに問題に対して有効との提案 -
[17] Stephen Jose Hanson and Lorien Y Pratt. Comparing biases for minimal network construction with back-propagation. In Advances in neural information processing systems, pages 177–185, 1989.
ネットワークの複雑さと過適合を防ぐパラメータの間引きについての初期の研究でWeight Decayをベースにしたもの -
[18] Yann Le Cun, John S. Denker, and Sara A. Solla. Optimal brain damage. In Advances in Neural Information Processing Systems, pages 598–605. Morgan Kaufmann, 1990.
Hessian損失関数に基づくネットワーク接続の削減の研究
Weight Decayによる大きさベースの間引き手法よりも精度が良いと提案
ただし計算量が増えている -
[20] Wenlin Chen, James T. Wilson, Stephen Tyree, Kilian Q. Weinberger, and Yixin Chen. Compressing neural networks with the hashing trick. arXiv preprint arXiv:1504.04788, 2015.
HashedNetsはハッシュ関数を使ってランダムに接続をグルーピングしてモデルサイズを削減する最近の手法の研究
グルーピングされたパラメータは一つのパラメータで代表する
この研究はパラメータの間引きと相性が良いかもしれない -
[22] Kilian Weinberger, Anirban Dasgupta, John Langford, Alex Smola, and Josh Attenberg. Feature hashing for large scale multitask learning. In ICML, pages 1113–1120. ACM, 2009.
上記の関連
ハッシュ衝突を最小化して効率化する
Learning Connections in Addition to Weights
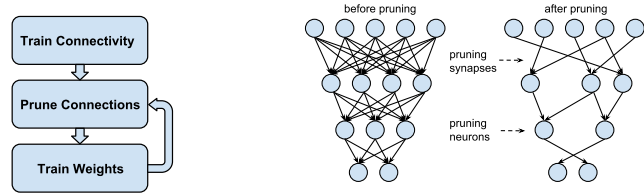
提案手法は左図に示す3ステップ
- 通常のニューラルネットワークのトレーニング
- ただし、L1又はL2の正則化を行う
- 間引き (右図)
- 閾値以下の重みパラメータは0としてコネクションを間引く
- 入力又は出力が0のニューロン(訳注:ユニットのこと)はニューロンごと間引く
- これに該当するニューロンはネットワークに何の貢献もしておらず、最終的にはこのニューロンに対する全てのコネクションが消滅する
- 畳み込みニューラルネットワーク(CNN)の場合はまず畳み込み層を固定して全結合層のみ間引き、そのご逆に全結合層を固定して畳み込み層を間引く
- ネットワークが深くなって勾配消滅問題が顕在化すると間引きによるエラーを回復するのが難しくなるため
- 間引き後のトレーニング
- 正則化は1と同様に行う
- ドロップアウト率を次のように設定
- Ni: i層目のニューロンの数
- Ci: i層目のコネクションの数
- Cio: 元のネットワークモデルにおけるi層目のコネクション数
- Cir: 間引いた後のネットワークモデルにおけるi層目のコネクション数
- Do: 元のネットワークモデルのドロップアウト率
- Dr: 間引き後に適用すべきドロップアウト率

Experiments
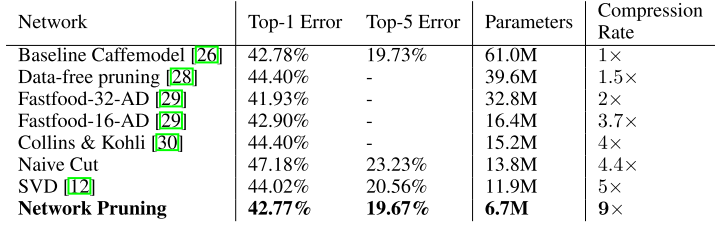
次の表が各種ネットワークモデルに本手法を適用した結果
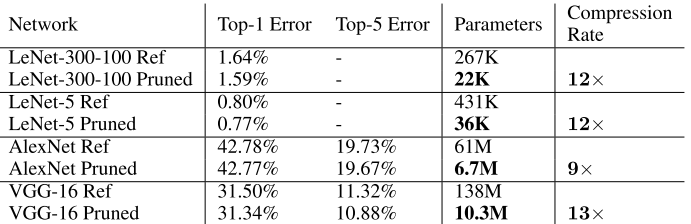
2列目がエラーレート、3列目がパラメータ数で一番右がパラメータ数の圧縮率、Refがついてる方はオリジナル、Prunedの方は間引き後
-
LeNet-300-100 はMnistで全結合の300ユニットと100ユニットの2つの隠れ層をもつ
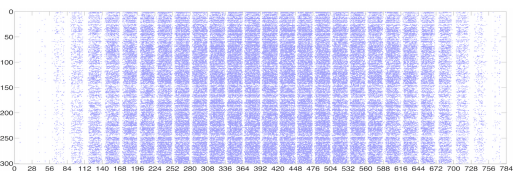
上の図で横軸は1層目の全結合層の入力、縦軸が出力、色の濃さは各パラメータの大きさ
28個のバンドを形成しているのは画像が28x28のため
中央付近が濃くなっているのは隅は特徴として使えるものが少なく中央に行くほど重要度の高い情報と評価された結果 -
LeNet-5はMnistでCNNのネットワークモデル
-
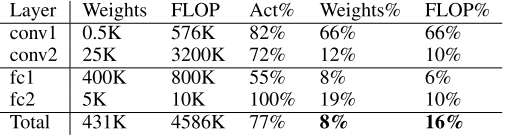
AlexNetはImageNet(ILSVRC-2012)、1.2Mをトレーニングサンプル、50Kを検証サンプルとして使用
- CaffeのAlexNetモデルを使用
- Nvidia Titan X GPUで75時間学習後間引いて学習率を1/100にして、173時間学習
-
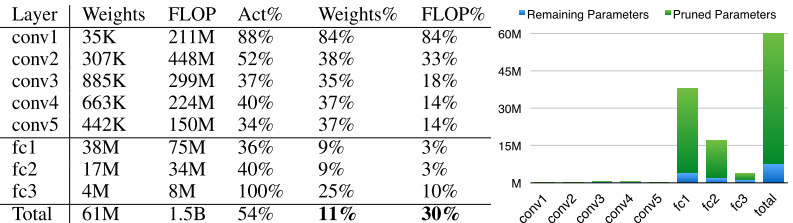
VGG-16は上のAlexNetモデルをVGG-16モデルに置き換えたもの
Discussion
精度と間引き率のトレードオフを調べた結果が次の図
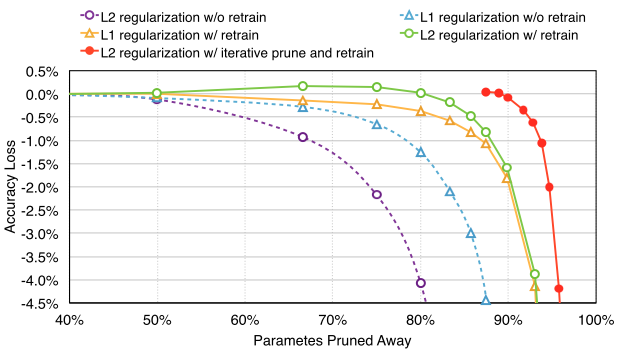
- 紫: L2正規化で間引き後の学習をしない場合
- 水: L1正規化で間引き後の学習をしない場合
- 橙: L1正規化で間引き後の学習をした場合
- 緑: L2正規化で間引き後の学習をした場合
- 赤: L2正規化で間引き後の学習をした後、もう一度間引いて学習した場合
次のFigure6はCNNで畳み込み層(CONV)と全結合層(FC)の比較
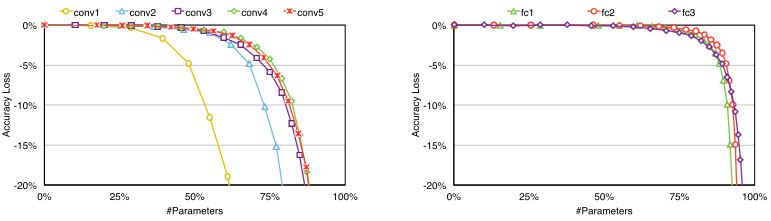
畳み込み層の方が間引きに対する耐性が低い
畳み込み層は冗長性が少ないためと思われる
耐性が低い層に対しては間引く閾値を小さめに調整した
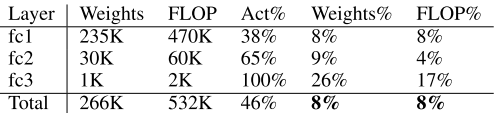
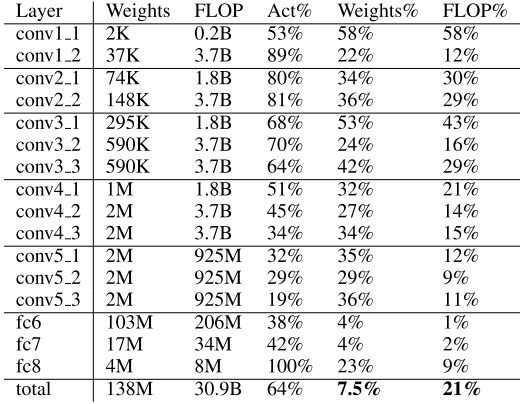
上記以外のネットワークへの適用結果は次の表
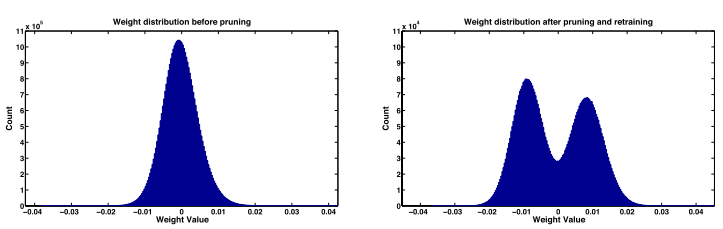
間引き前(左)と後(右)の各パラメータの値の分布
Conclusion
AlexNetで1/9、VGG-16で1/13にパラメータ数を圧縮