こちらの記事はケーシーエスキャロット Advent Calendar 2019の15日目の記事です。
ちょっと遡って5日前の記事はgaramanさんのくずし字を読む (準備編)でした。
子供の頃、百人一首をやった記憶はありますが、普通の日本語で書かれていました。
その為、くずし字をあまり見た記憶がありませんが、プログラムで解析しようとする発想がスゴいです。
さて、本日はメトリクスの値を監視する AWS CloudWatch - Alarm に関して記載してみようと思います。
CloudWatch - Alarm の監視方法としては、指定した閾値を
- 以上 (GreaterThanOrEqualToThreshold)
- 以下 (LessThanOrEqualToThreshol)
- より上 (GreaterThanThreshold)
- より下 (LessThanThreshold)
となった場合にアラーム状態へ遷移する静的しきい値のみだったのですが、今年の夏ごろから異常検出という方法も可能になりました。
この異常検出をコンソールから設定する方法は、異常検出に基づいて CloudWatch アラームを作成する等のサイトに記載がありますが、CloudFormation でデプロイする際のテンプレート記載例が見当たらなかった(探し方が悪いかもですが)ので記載してみようと思います。
CPU 使用率アラームを異常検出へ書き換えた例。
CPUAlarmForAnomaly:
Type: AWS::CloudWatch::Alarm
Properties:
AlarmName: anomaly-alarm
AlarmDescription: CPU alarm for my instance
AlarmActions: Ref: "logical name of an AWS::SNS::Topic resource"
Metrics:
- Id: m1
ReturnData: true
MetricStat:
Period: 60
Stat: Average
Metric:
MetricName: CPUUtilization
Namespace: AWS/EC2
Dimensions:
- Name: InstanceId
Value: Ref: "logical name of an AWS::EC2::Instance resource"
- Id: a1
Expression: ANOMALY_DETECTION_BAND(m1, 2)
EvaluationPeriods: 3
ThresholdMetricId: a1
ComparisonOperator: GreaterThanUpperThreshold
以上! …だとそっけなさ過ぎるので、簡単に説明を記載すると、
- Id: m1
ReturnData: true
MetricStat:
Period: 60
Stat: Average
Metric:
MetricName: CPUUtilization
Namespace: AWS/EC2
Dimensions:
- Name: InstanceId
Value: Ref: "logical name of an AWS::EC2::Instance resource"
の部分が監視するメトリクスの宣言となります。
注意点としては、静的しきい値と比較すると統計方法の記載が異なる(Statistic⇔Stat)ことです。
そして、
- Id: a1
Expression: ANOMALY_DETECTION_BAND(m1, 2)
の部分で、監視対象メトリクスの値を異常検出と見なす想定値の範囲を指定(2)しています。
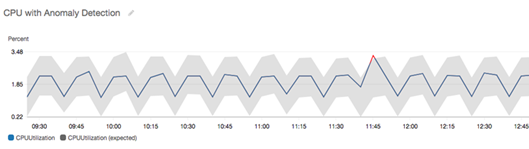
異常検出方式で Alarm として設定してみると、上図のような感じで実際のメトリクスの値に沿って想定値の範囲(グレーの部分)が設定(想定)されます。
詳細はCloudWatch の異常検出の使用を参照。
因みに、監視方法(ComparisonOperator)も静的しきい値と異なっていて
- 想定値の範囲を上回った場合 (GreaterThanUpperThreshold)
- 想定値の範囲を下回った場合 (LessThanLowerThreshold)
- 想定値の範囲を上回った or 下回った場合 (LessThanLowerOrGreaterThanUpperThreshold)
の3つから指定可能です。
この異常検出の使いどころとしては、しきい値が設定しにくい(時間帯や日によって異なる等)場合に良いかもしれませんね。