この記事は AWS Analytics Advent Calendar 2021 の 16日目の記事です。re:Invent 2021 で発表された新しい機能はすでに素敵なエントリがたくさんあったので、自分の興味に寄せてオープンデータの分析・可視化で記事を書いてみようと思います。実は、あまりこういうのに慣れていないので、不備がありましたら優しくご指摘いただけると助かります。
S3にあるオープンデータを分析して、可視化するまでにどんなサービスが利用できるのか、全体の流れを記事にしてみようと思います。要約するとこのような流れになっています。
- Open Data on AWS のデータへのアクセス
- Python を利用してデータの理解を深める
- SageMaker Notebook でデータの探索
- Lambda で前処理した結果を S3 に保存
- Athenaでクエリして結果を集約
- QuickSight に取り込んで可視化
Notebook でこういう可視化とか

QuickSight でこういう可視化とか
をやっていきます。
Open Data on AWS のデータにアクセス
AWS には Registry of Open Data on AWS という、オープンデータを見つけることができるレジストリがあります。SNS(Facebook Data for Good)やCOVID-19(Foldingathome COVID-19 Datasets)など、様々な分野のオープンデータが利用できます。

最近はニュースになることも多い宇宙の領域から、気象衛星ひまわりのデータを分析してみたいと思います。
https://registry.opendata.aws/noaa-himawari/
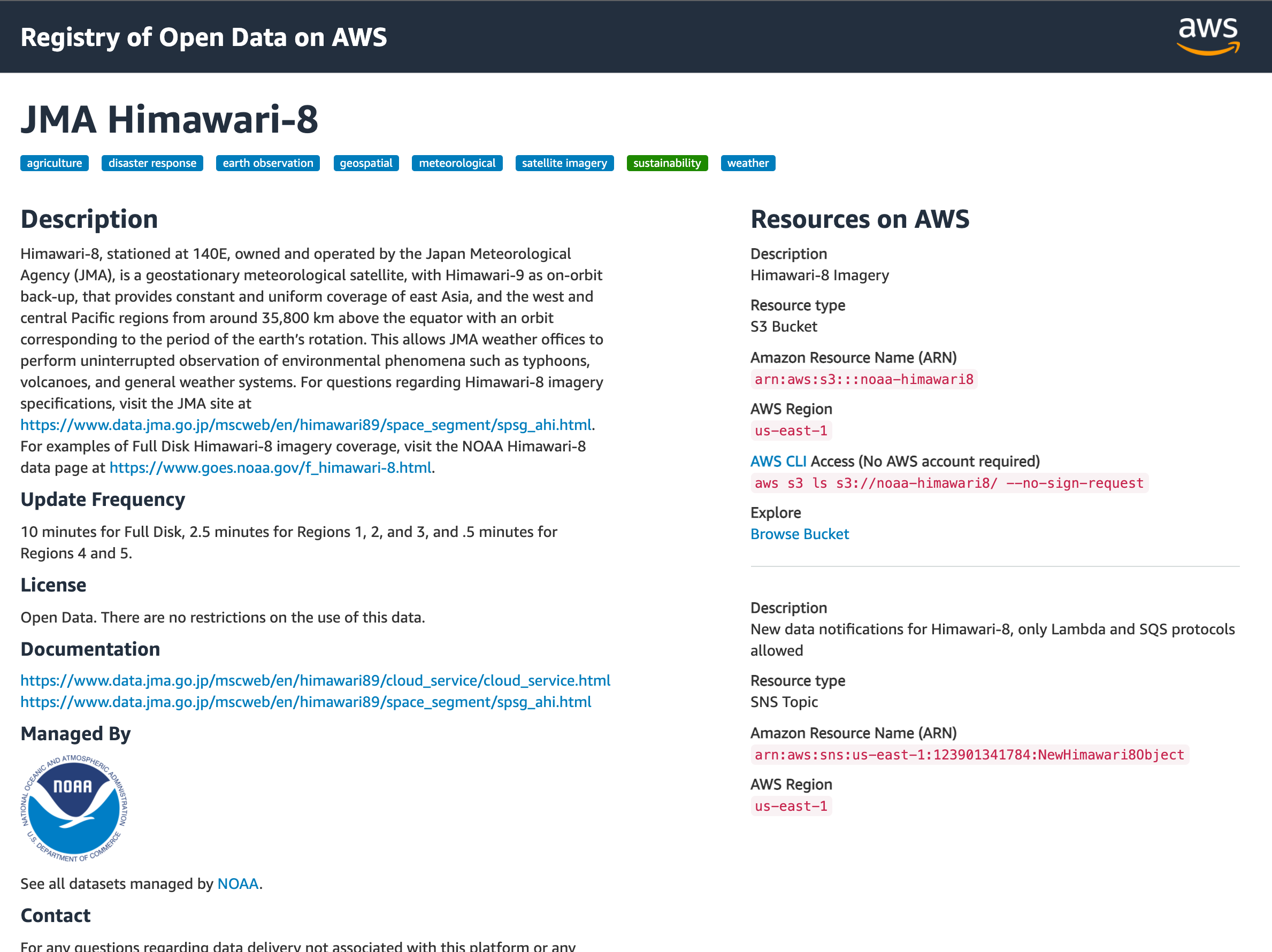
オープンデータはS3でホストされていて、ARNやリージョン、AWS CLI を利用したアクセス方法が右側に記載されています。ブラウザからバケットに含まれるオブジェクトを見るためのリンクも用意されています。リンクを開いてみると、AWS S3 Explorer でデータを見ていくことができます。

README.txt には、保存されているファイルの説明が書かれています。AHI = Advanced Himawari Imager の略であることや、保存されているデータの意味などを確認することができます。
Analytics の勉強として、H8 Rainfall Rate を見ていきたいと思います。(今回は扱いませんが、画像の解析も面白そうですね)
データの理解を深める
一つファイルをダウンロードしてみたところ、 .nc という拡張子が設定されていました。file コマンドで調べてみると、Hierarchical Data Format (version 5) という大量のデータを格納・構造化できるフォーマットであることがわかります。
$ file AHI-CPHS_v1r0_h08_s202112110020202_e202112110020535_c202112110035214.nc
AHI-CPHS_v1r0_h08_s202112110020202_e202112110020535_c202112110035214.nc: Hierarchical Data Format (version 5) data
python の h5py を利用してファイルにアクセスができますので、中身を見てみましょう。一つのファイルの中に、複数のデータセットが含まれていることが確認できました。
$ python
Python 3.7.6 (default, Jan 8 2020, 13:42:34)
[Clang 4.0.1 (tags/RELEASE_401/final)] :: Anaconda, Inc. on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import h5py
>>> f = "./RRQPE-AHI-INST_v1r1_h08_s202112040000202_e202112040000536_c202112040015145.nc"
>>> infh = h5py.File(f, 'r')
>>> infh.keys()
<KeysViewHDF5 ['Columns', 'DQF', 'Diag', 'Latitude', 'Longitude', 'NumQAVals', 'PQI', 'QA_Bit0_Set', 'QA_Bit1_Set', 'QA_Bit2_Set', 'QA_Bit3_Set', 'QA_Bit4_Set', 'QA_Bit5_Set', 'QA_Bit6_Set', 'QA_Bit7_Set', 'QA_Value_0', 'RRQPE', 'Rows', 'StartColumn', 'StartRow', 'TotalRainArea', 'TotalRainVol', 'TotalRetrievals', 'latitude', 'latitude_bounds', 'number_of_LZA_bounds', 'number_of_SZA_bounds', 'number_of_lat_bounds', 'quantitative_local_zenith_angle', 'quantitative_local_zenith_angle_bounds', 'retrieval_local_zenith_angle', 'retrieval_local_zenith_angle_bounds', 'solar_zenith_angle', 'solar_zenith_angle_bounds', 'x', 'y']>
>>> infh['Columns']
<HDF5 dataset "Columns": shape (5500, 5500), type "|i1">
このドメイン特有の略語も Google で調べながら、データの理解を深めていきます。
- DQF = Data Quality Flag
- PQI = Product Quality Indicator
- RRQPE: Rainfall Rate Quantitative Precipitation Estimation
5500 x 5500 の範囲でデータが入っていますね。また、静止衛星ですので、データ中央(2750:2750)の緯度経度は、常に同じ値が入っているようで、なるほどとなりました。
>>> f1 = "./RRQPE-AHI-INST_v1r1_h08_s202112040000202_e202112040000536_c202112040015145.nc"
>>> infh1 = h5py.File(f1, 'r')
>>> f2 = './RRQPE-AHI-INST_v1r1_h08_s202112090910202_e202112090910536_c202112090925005.nc'
>>> infh2 = h5py.File(f2, 'r')
>>> infh1['Latitude'][2750,2750], infh1['Longitude'][2750,2750]
(-0.0090436945, 140.70898)
>>> infh2['Latitude'][2750,2750], infh2['Longitude'][2750,2750]
(-0.0090436945, 140.70898)
RRQPE (推定降水量)についても確認してみると。最大が 143 の値が入っているようです。他にも、地球が写り込んでいないところは、-999が設定されているようです。
>>> pandas.DataFrame(infh['RRQPE'][2750]).describe()
0
count 5500.000000
mean -15.054545
std 125.638132
min -999.000000
25% 0.000000
50% 0.000000
75% 0.000000
max 143.000000
ここまでで、アクセスできるデータの中身についての理解を深めていきました。Terminal だとそろそろ限界を感じてきましたので、Notebook を使ってデータを深堀りしてみましょう。
Amazon SageMaker Notebook インスタンスでデータを探索
Amazon SageMaker Notebook インスタンスを利用すると、マネージドな Notebook 環境を簡単に利用することができます。
マネジメントコンソールから Amazon SageMaker を開き、Notebook インスタンスを作成します。インスタンスが作成できたら、「Jupyter を開く」で接続して、Notebook を作成します。
まず、扱うデータを S3 から取得しましょう。Sigv4の署名をつけるとアクセスできないので、--no-sign-request のオプションを付けるのがポイントです。
!aws s3 cp s3://noaa-himawari8/AHI-L2-FLDK-RainfallRate/2021/12/01/0000/RRQPE-AHI-INST_v1r1_h08_s202112010000201_e202112010000535_c202112010015102.nc . --no-sign-request
続いて、データを可視化するコードを作っていきます。5500 x 5500 のデータはサイズも大きいので、東京近辺の緯度経度に絞り込んで、3D でレンダリングしてみます。
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
f = "./RRQPE-AHI-INST_v1r1_h08_s202112010000201_e202112010000535_c202112010015102.nc"
infh = h5py.File(f, "r")
row = slice(750, 1250)
col = slice(2500, 3000)
lat = pandas.DataFrame(np.array(infh['Latitude'][row, col])).stack()
lon = pandas.DataFrame(np.array(infh['Longitude'][row, col])).stack()
rr = pandas.DataFrame(np.array(infh['RRQPE'][row, col])).stack()
lat = lat[rr > 0]
lon = lon[rr > 0]
rr = rr[rr > 0]
fig = plt.figure(figsize=(10,10))
ax = Axes3D(fig)
bottom = np.zeros_like(lat)
width = depth = .01
ax.bar3d(lon, lat, bottom, width, depth, rr, shade=True)
plt.show()

緯度経度(東経140°、北緯36°の周辺)に対して、 推定降水量を可視化できました。そういえばこの時間帯に、東京付近では冬の冷たい雨が降っていました。ここまでで、ある日時における降水量を位置情報にマッピングして可視化することができました。ソースとなるデータの 1 ファイルに閉じた処理なので、データの処理はそこまで複雑ではありません。
料金がかからないよう、Notebook インスタンスは停止しておきます。
Lambda で前処理した結果を S3 に保存
複数のファイルに分散したデータを集約してみたいと思います。オープンデータは大量のデータを扱うためにHDF5 を採用していますが、Athena のようなサービスから扱うのは少し不便です。今回は RRQPE にフォーカスしていますので、各ファイルから 緯度、経度とRRQPE を抽出して、自分の AWS アカウントが保有する S3 に保存してみましょう。
一つ一つのファイルはそこまで大きくない(60MB - 70MB)こと、データの扱い方はすでに h5py を利用してわかってきたので、今回は ETL 処理に Lambda (python)を使用します。私は Lambda 関数を作成する場合は、SAM を利用することが多いです。
import json
import boto3
import h5py
import gzip
import pandas
import tempfile
from io import BytesIO
import numpy as np
from datetime import datetime
from botocore import UNSIGNED
from botocore.config import Config
unauth_s3 = boto3.client("s3", config=Config(signature_version=UNSIGNED))
s3 = boto3.resource("s3")
def lambda_handler(event, context):
bucket = 'noaa-himawari8'
key = event['key']
df = pandas.DataFrame()
# download file
with tempfile.NamedTemporaryFile() as fp:
unauth_s3.download_file(bucket, key, fp.name)
infh = h5py.File(fp.name, "r")
df['Latitude'] = pandas.DataFrame(np.array(infh['Latitude'])).stack()
df['Longitude'] = pandas.DataFrame(np.array(infh['Longitude'])).stack()
df['RRQPE'] = pandas.DataFrame(np.array(infh['RRQPE'])).stack()
# set datetime when file created
date = datetime.strptime(key.split('_')[3][1:-3], '%Y%m%d%H%M')
df['datetime'] = str(date)
# upload file
buf = BytesIO()
with gzip.open(buf, mode="wt") as f:
df.to_csv(f)
s3_obj = s3.Object('<<my-bucket-name>>', key[:-2] + "csv.gz")
s3_obj.put(Body=buf.getvalue())
return {
"statusCode": 200,
"body": json.dumps({
"message": "saved file",
}),
}
S3 からオープンデータを取得してきて、DataFrame を作成して、S3 にアップロードしています。署名なしで S3 にアクセスするところとか、ファイルの中に日付が入っていないのでファイル名から取ってきたりしているところとか、GZIP で圧縮してアップロードするところとか、色々つまりましたが、とりあえず今回の記事ではサラリと進みましょう!
実行してみると、1 つのファイルの処理時間は5分ぐらい、使用メモリは5.8GBとなりました。S3 → Lambda → S3 の呼び出しを、とりあえず1日分(10分間隔なので144ファイル/日)で実行してみます。サーバーレス構成にしているので、100 並行で実行してもスイスイ動きます。
while read line;
do
PAYLOAD="{ \"key\": \"$line\" }";
aws lambda invoke \
--region us-east-1 \
--function-name himawari-HelloWorldFunction-5PloauF5LAh5 \
--invocation-type Event \
--cli-binary-format raw-in-base64-out \
--payload "$PAYLOAD" \
response.json;
done < object_list.txt
S3 にファイルが生成されていることが確認できました。パーティションを切っているので1つしか表示されていませんが、他にも 100 個以上のファイルが生成されていることが確認できました。
Athena でクエリして結果を集約
それでは、csv.gz 形式で保存された 1 日分のファイル群を、Athena からのクエリで集計してみましょう。
- Glue のクローラーを動かして、S3 に保存したデータの Glue Data Catalog を作成する
- Athena からクエリして、データを集計する
という手順を進めていきます。
データを保存した S3 を指定して Glue クローラを実行すると、テーブル定義が自動で作られます。CSV で出力していたファイルの列や、S3 の key に埋め込んだパーティションが自動的に認識されていました。(下の画像は、「スキーマの編集」から、列名をわかりやすいものに変更しています)

Glue Data Catalog にテーブル定義がはいりましたので、Athena でクエリができるようになりました。緯度(30 - 40°)、経度(130° - 140°)の範囲のデータについて、1度ごとに集約して RRQPE の平均値を集計しています。クエリの結果は、Athena が S3 へ出力してくれています。
SELECT AVG(cast("rrqpe" as double)),
floor(cast("latitude" as double)),
floor(cast("longitude" as double)),
"datetime"
FROM "opendata"."ahi_l2_fldk_rainfallrate"
WHERE cast("latitude" as double) > 30 and
cast("latitude" as double) < 40 and
cast("longitude"as double) > 130 and
cast("longitude"as double) < 140
GROUP BY "datetime",floor(cast("latitude" as double)), floor(cast("longitude"as double))
ORDER BY "datetime"
QuickSight で集計結果を可視化
QuickSight をセットアップして、Athena が S3 に出力したファイルを取り込みます。S3 からの取り込みには、マニフェストファイルをアップロードします。
{
"fileLocations": [{
"URIs": ["<<S3 URI>>"]
}]
}
あとは、QuickSight でダッシュボードを作成していきましょう。
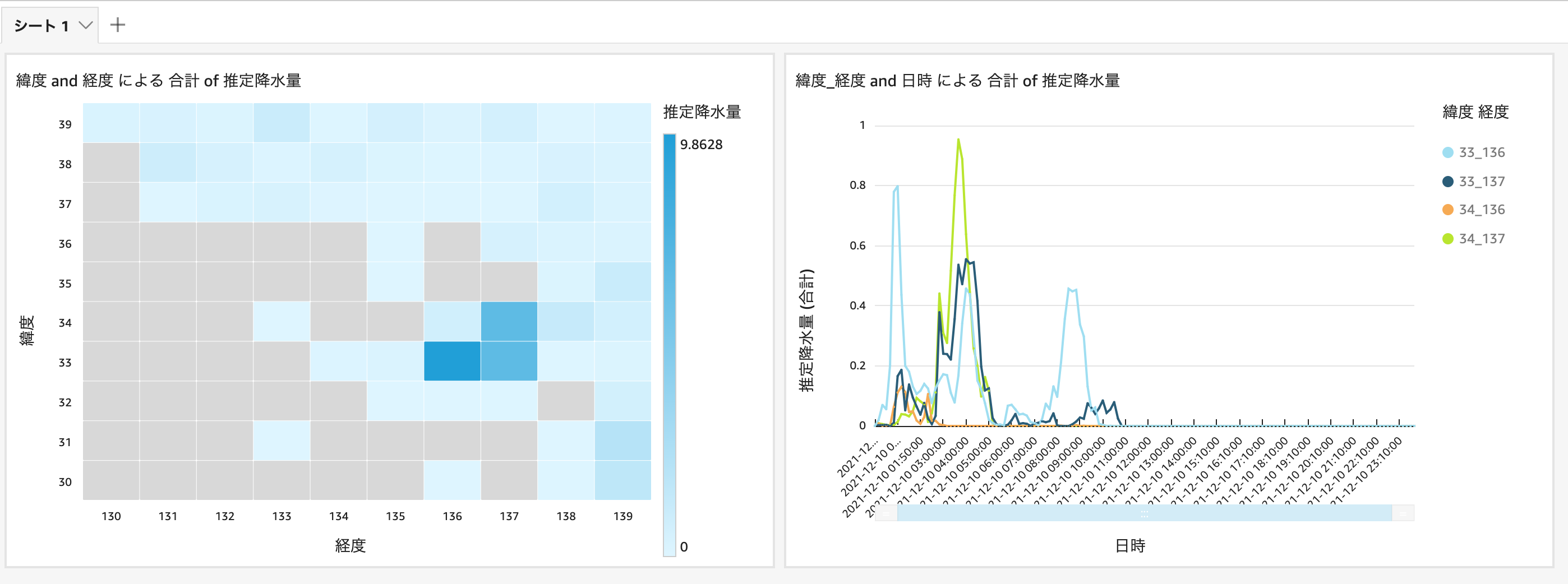
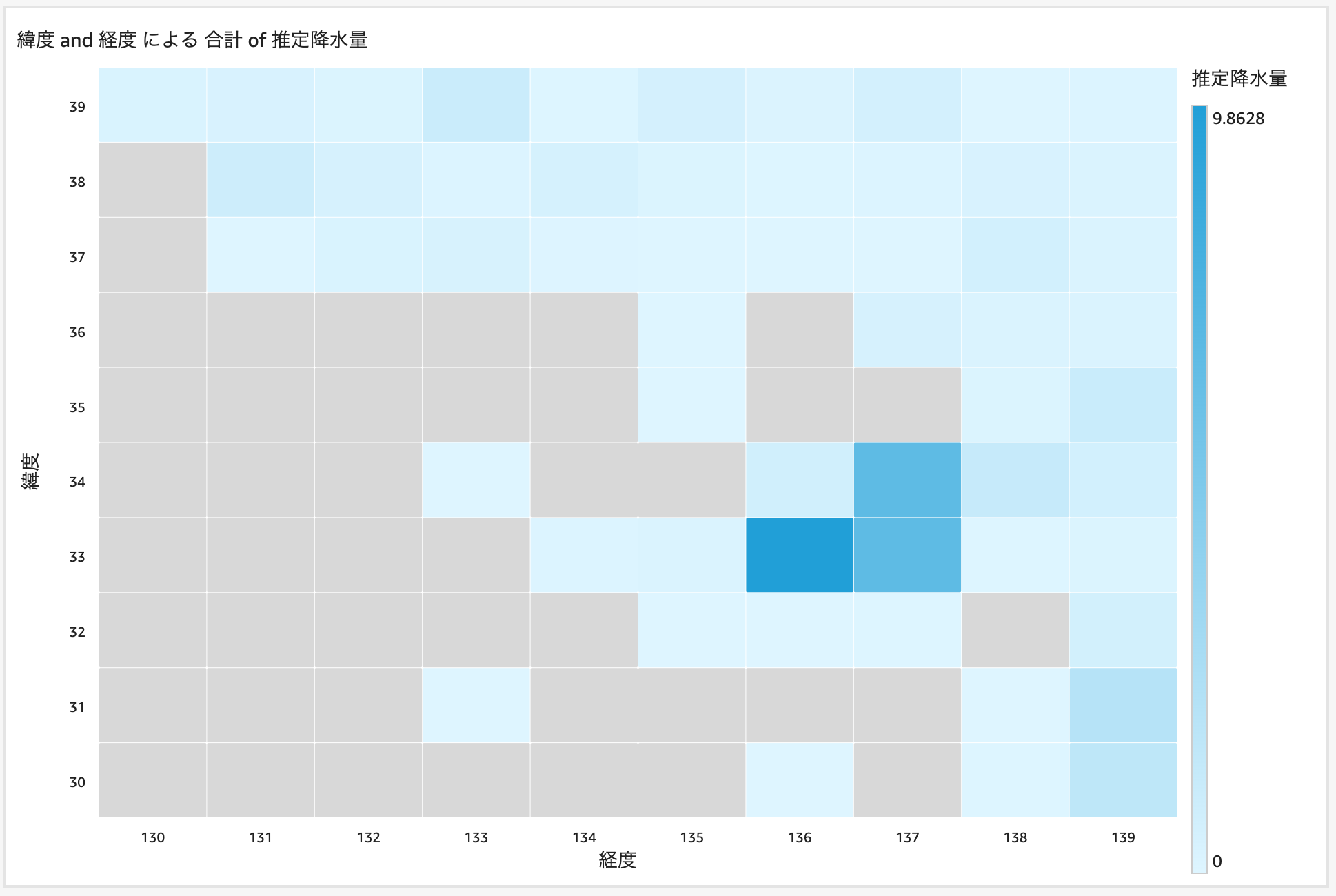
緯度経度ごとの、1日の推定降水量を合計して、この日に降水量が多かった地域を絞り込みます。緯度が33 - 34度、経度が136 - 137度のところで、降水量が多かったことが確認できます。
それでは、この地域の降水量を時系列で確認してみましょう。データに緯度と経度のフィルタをかけて、00:00 - 11:20(UTC)の範囲での降水量を可視化することができました。

まとめ
気象衛星ひまわりが生成しているデータを分析して、可視化するまでの流れを実践してみました。まずはデータの理解を進めながら、データの処理や可視化を進めていく中で様々なAWSサービスが活用できるということを理解することができました。
気象衛星ひまわりは今回のデータを10分ごとに生成していますので、サブスクライブして継続的に Lambda を処理してデータを取り込み続けることができます。
おまけ
はじめてこういう記事を書いてみようと思い、まずは日付を決めてエントリしてみました。実際は時間切れ感があり、特に後半は丁寧に記載する時間が取れませんでした。。。ただ、実践してみると常に学びがありますので、それぞれのポイントで深堀り記事を書いてみたいな、なんて思います。