この記事の目的
構築時の検証にて、IBMCloud vSRX(HA)のハードウェア障害時の切り替わりまでのダウンタイムを計測したため、参考情報として共有します。
(IBMCloud vSRX(HA)障害時のダウンタイムの記事を参考にさせていただきました。)
本記事ではポータルからハード・リブート(即時リブート)による障害テストを実施しました。
ご参考になれば幸いです。
環境
- IBMCloud GatewayAppliance:Juniper vSRX Junos18.4R1-S1.3
テスト実施および結果
1. HAステータスの事前確認
- HW障害発生をさせる前のHAステータスは以下の通りです。
- Node0: Primary / Node1: Secondary となっていることが確認できます。
admin@xxx-srx00-vsrx-vSRX-Node0> show chassis cluster status
Cluster ID: 3
Node Priority Status Preempt Manual Monitor-failures
Redundancy group: 0 , Failover count: 1
node0 255 primary no yes None
node1 1 secondary-hold no yes None
Redundancy group: 1 , Failover count: 5
node0 100 primary yes no None
node1 1 secondary yes no None
{primary:node0}
admin@xxx-srx00-vsrx-vSRX-Node0>
2. HWリブート時を実施
- [クラシック・インフラストラクチャ] -> [Network] -> [GatewayAppliance] を選択し、対象となるvSRXデバイスを表示します。
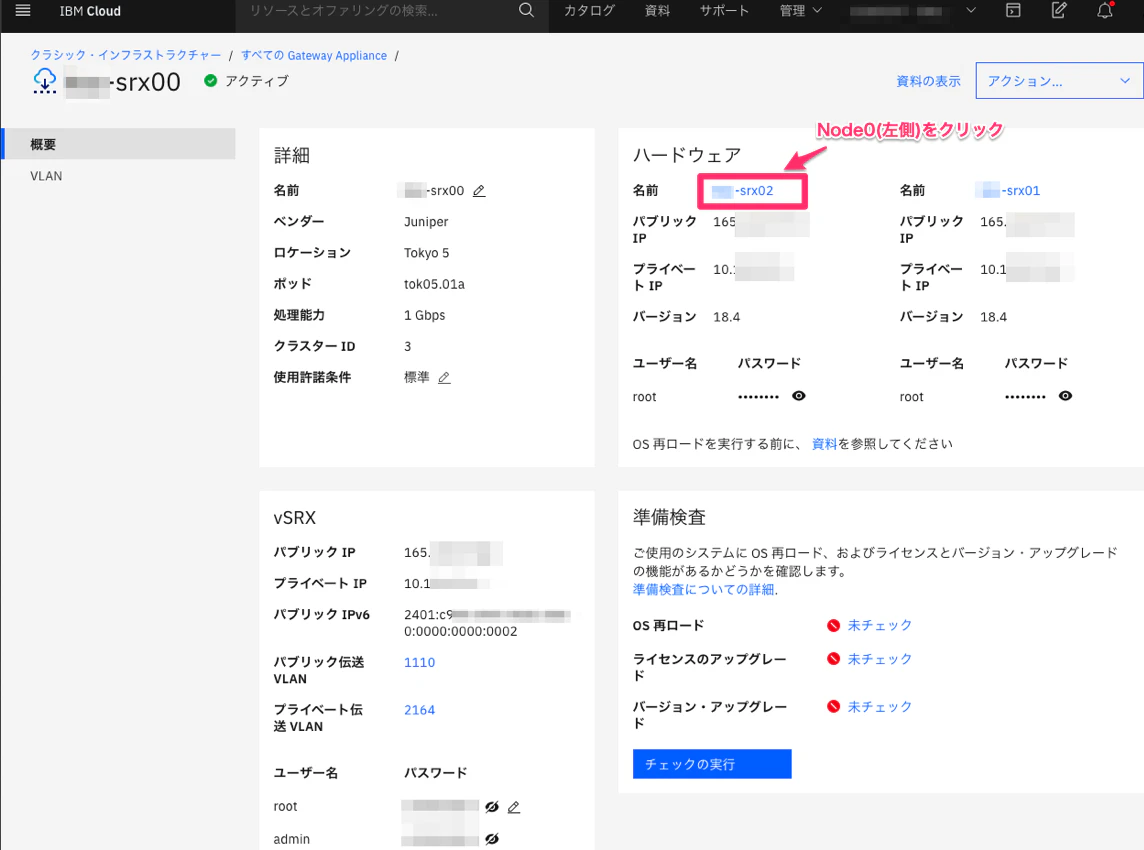
-
Node0のデバイス詳細に入り、[アクション] -> [リブート] をクリック。
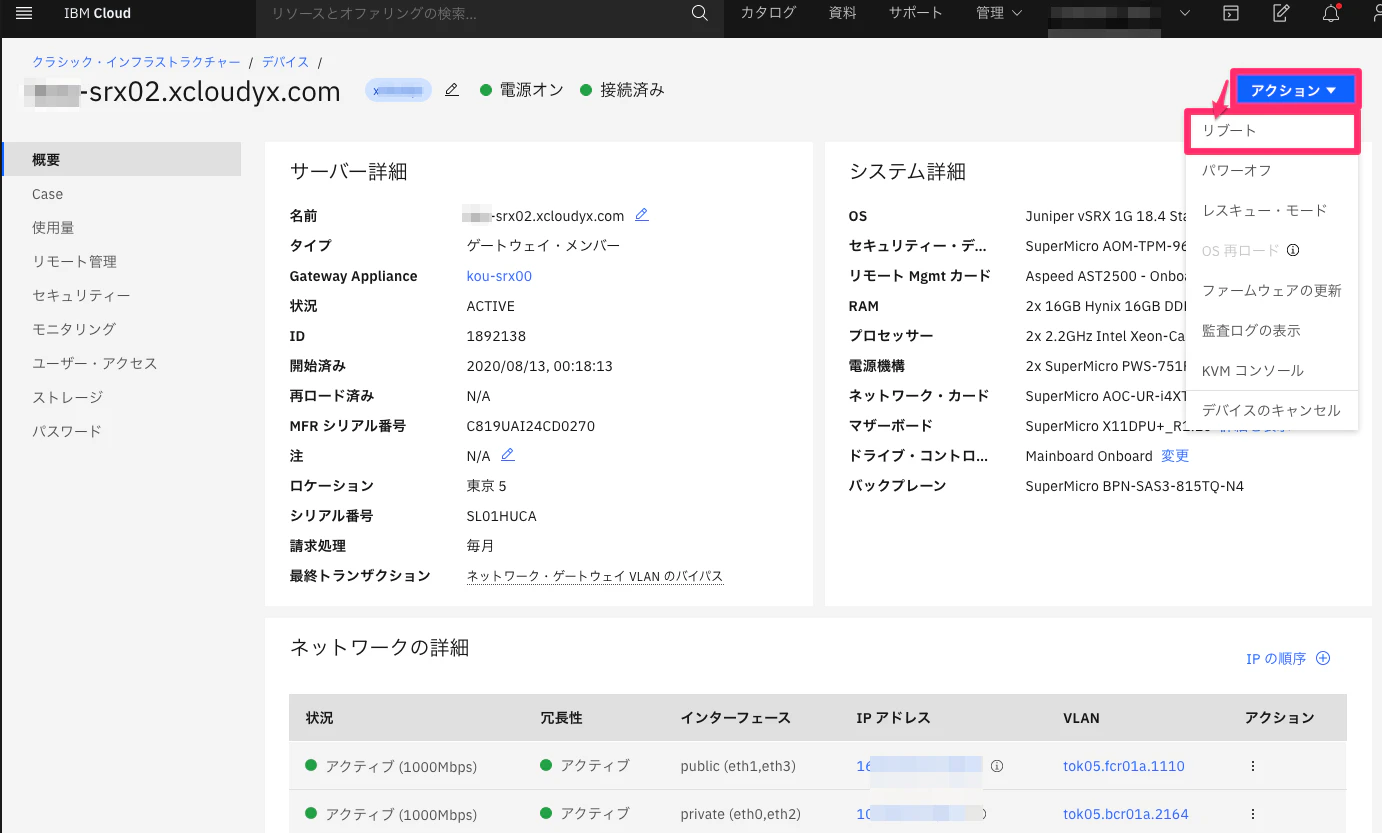
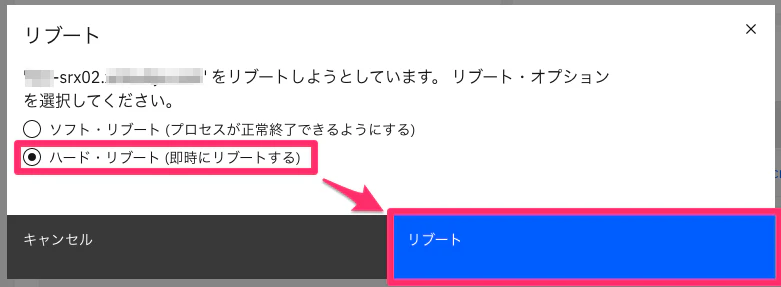
-
上記リブートボタンを押下後、数秒程度でポータル画面右上に正常完了したメッセージが表示されます。
-

3. 障害断時間の結果
- Ping断時間
20:22:53 - 20:23:15 (23sec)
$ ping 10.193.88.35 | while read pi; do echo "$(date '+[%Y/%m/%d %H:%M:%S]') $pi"; done
[2020/11/15 20:22:49] 64 bytes from 10.193.88.35: icmp_seq=60 ttl=56 time=1.54 ms
[2020/11/15 20:22:50] 64 bytes from 10.193.88.35: icmp_seq=61 ttl=56 time=1.79 ms
[2020/11/15 20:22:51] 64 bytes from 10.193.88.35: icmp_seq=62 ttl=56 time=1.60 ms
[2020/11/15 20:22:52] 64 bytes from 10.193.88.35: icmp_seq=63 ttl=56 time=1.58 ms
[2020/11/15 20:23:16] 64 bytes from 10.193.88.35: icmp_seq=87 ttl=56 time=2.24 ms
[2020/11/15 20:23:17] 64 bytes from 10.193.88.35: icmp_seq=88 ttl=56 time=1.61 ms
[2020/11/15 20:23:18] 64 bytes from 10.193.88.35: icmp_seq=89 ttl=56 time=1.58 ms
- Curl(HTTP)断時間 20:22:55 - 20:23:25 (31sec)
$ while true; do date&curl http://10.193.88.35; sleep 1s; done
Sun Nov 15 20:22:53 CST 2020
Hello World!
Sun Nov 15 20:22:54 CST 2020
Hello World!
Sun Nov 15 20:23:26 CST 2020
Hello World!
Sun Nov 15 20:23:27 CST 2020
Hello World!
Sun Nov 15 20:23:28 CST 2020
Hello World!
最後に
手動でのソフトリブート結果に比べ、ハード・リブートを実施した場合のフェイルオーバ時間は長い通信断の結果となりました。