今回やりたかったこと
- 目標:ChatGPT(GPT-4) で一撃でスクレイピングするコードを生成
するにはどうしたらいいのか、ChatGPT のハードルとかコツとかを知りたい。
※最終的なプロンプトの入力と出力の全文は本ページ下部に貼り付けてます。
作ったもの概要
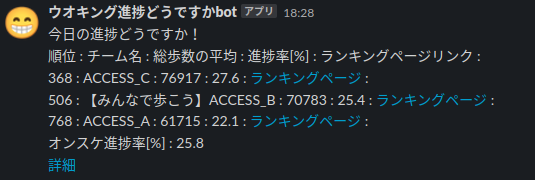
保険組合のウォーキングイベントの会社内の3チームの歩数進捗の slack への自動投稿 bot を作成しました。
処理は大きく2つに分かれています。
- ウォーキングイベントサイトから歩数をスクレイピング&スプシへアップロード
- スプシの GAS で投稿文字列作成& slack へ自動投稿
今回 ChatGPT でやったのは1の方です。
2は前回半年前開催分のコードをほぼそのまま流用しました。
運良く(?)今回のタイミングでウォーキングイベントのサービスサイトが変わり、 HTML がまるっと変わり1のスクレイピングコードは作り直しが必要だったので、チャレンジに丁度良いと思い ChatGPT を使ってコード生成してみました。
環境
- ChatGPT(GPT-4)
- Mac macOS 12.5.1
作成物スクリーンショット
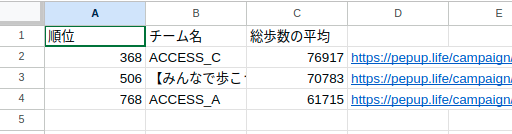
スプシ
slack bot
対応時間
5月7日の1人日で対応しました。
体感としては「半年前に似たものを作った」経験を活かし、今回手動作成なら半日で行けたはずですが、ChatGPTへの慣れで1人日かかりました。
しかし多分今後更に似たような処理をするなら ChatGPT に任せたらより短く(半日以下で)出来るはずです。
ChatGPT の入力上限(執筆時点(2023/05/07)で3時間で25回)、に1回引っかかりました。
#実際は2回で、子供が PC 画面覗き込んで「これなんで自動で文字出てくるの!?」と興味持ったので、途中一緒に「ドラえもんの誕生日」「面白い名前の魚」とか子供と一緒に遊んだ結果、1回制限に引っかかりました。
#ChatGPT で出力させたいイメージが固まる前の試行錯誤段階は「ちょこちょこ試し、制限に引っかかった待ち時間は休憩時間に当てる」くらいが良いかもしれません。
感想
- まぁまぁ大変。ちゃんと動かせたかったらその分文章書く必要あり。
- 最初は試行錯誤する。けど今回 ChatGPT 自体に慣れたから次はもう少しスマート&短時間で行けるはず
- 実際のプロンプトの操作イメージ(体感)
- 最初に「やりたいことの50%」を入力しプロンプト出力。実行すると「エラー発生したり、最初の入力で言い忘れたこと」を認識。
- 「エラー対処や次の処理」5%分追加し再出力。
- 以下繰り返し
- みたいな感じ
問題と対策(得られた知見)
- GPT-4 に慣れると GPT-3 は出力が弱い(上記 GPT-4 の入力上限に引っかかったときに GPT-3 で同じことさせたが全体的にイケてない。期待通りの出力にならない)
- 対策→ GPT-4 の入力数上限に達したら、待つ
- ログインが必要なページのスクレイピングは基本やってくれない。「ログイン出来ない」と言われる
- 対策→スクレイピングしたい HTML を DevTools で取り出し、サンプルで数行渡してあげると対応してくれる
- 生成毎にコードのスタイルがどかっと変わる。変わった場所とは全然無関係の処理を追加してるはずなのに。結果整合が取れず動かないがち。
- 変数名。「TARGET_TEAM_NAMES」だったり「TARGET_TEAMS」だったり、等々。
- 関数名
- 使用ライブラリ
- 関数化有無(処理ベタ書きだったり、関数化したり)
- 変数を上部にまとめてくれたり、中に埋め込んだり
→対策1:それらも指定する。「チーム名、ファイル名、シート名等あとから変更する可能性があるものはコードの上部にまとめて記載して」等。
→対策2:下にコメントを続けず、冒頭の依頼文を編集して再生成させると全体の整合は取れやすい。
- ログイン画面の HTML は ChatGPT がアクセス出来るはずだが、何故か微妙に selector を間違えてた。
- メールアドレス入力欄の ID が正しくは「sender-email」だが最初の出力は「sender_email」だった
- パスワード入力欄の ID が正しくは「user-pass」だが最初の出力は「user-password」だった
→対策:それらも指定する。「ID、パスワードの selector はそれぞれ以下。sender-email user-pass」等。
- ライブラリ/ツールのバージョン問題にちょいちょいぶち当たる。僕の手元の selenium ver は4だったが、ランダムで3向けのコードを吐く
→対策:バージョンも指定する。「selenium 4」等。 - バージョン指定しても誤出力することがある
→対策:API も指定する。「driver.find_element_by_id 等は使用せず、driver.find_element(By.ID, 等を使用する」等。
未解決問題
- 生成毎にコードブロックが外れがち。外れると python 的にはインデントし直すのが手間。コードブロック成功率を上げるおまじない「テキストはコードブロックで」等はあるが、確実ではない。
→暫定対策:少し上の「XXX 関数の頭から書いて」と言うと気持ちコードブロック化してくれやすい?コピペしやすい。 - 明示してるのに未考慮なコードがたまーに出力される。「headless モード有りオプション。デフォルトはheadlessモードオフ。」と言ってるのに、出力毎にたまに「デフォルトオン、オフ」が変わる。。
→暫定対策:特になし。。気にせず他の処理追加してたら最後の出力で希望の「デフォルトオフ」になってくれてた。。
コツ
- 続きの出力は「つづき」で OK。最初は丁寧に「続きを書いてください」と書いていたが。
- 実行時エラー発生したらエラーテキスト貼り付けるだけで OK。最初は丁寧に「エラー発生。<実際のエラーテキスト>」と書いていたが。
最終的なプロンプト
注:入力テキスト出力テキストどちらも基本はコピペですが、スプシの ID 等は「XXX」に置き換えてます。
注:入力テキストは試行錯誤&継ぎ足し継ぎ足しした結果で未整理なので、必要条件ではあるけど十分条件ではないかもです(=もっと整理し短く出来るかも)
入力
以下の条件を満たすコードを python で作成お願いします。
コードはインデントに注意してコードブロックで出力お願いします。
■やりたいこと
ウォーキングイベントのチーム対抗ランキングの特定3チームの、順位、チーム名、総歩数の平均をgoogle スプレッドシートに保存する。
■条件
・使用ライブラリ/ツール
・selenium 4
・driver.find_element_by_id 等は使用せず、
driver.find_element(By.ID, 等を使用する
・webdriver
webdriver.Chrome()のexecutable_path引数は使用しない。
Serviceオブジェクトを使用する。
・webdriver-manager
https://pypi.org/project/webdriver-manager/
・Google Sheets API
・認証情報は同じ場所に credentials.json として保存されている
・service_account.Credentials.from_service_account_file の引数は2つ
・特定3チームのチーム名
・「ACCESS_A」が含まれるチーム。
実際は「【募集】ACCESS_A」等前後に別のテキストが含まれる可能性あり
・「ACCESS_B」が含まれるチーム
・「ACCESS_C」が含まれるチーム
・起動引数でオプション
・headless モード有りオプション。
・デフォルトはheadlessモードオフ。
・コードはベタ書きではなく適切に関数化
・チーム名、ファイル名、シート名等あとから変更する可能性があるものはコードの上部にまとめて記載
・IDとパスワードは login_info.json に記載し、そこから読み込むようにしてください
・credentials.json や login_info.json のローカルファイルは cron で実行できるように 本スクリプトの PATH を起点にしてファイルを開けるようにしてください
・特定チームが見つかった時点のスクリーンショットを取得
・まずアクセスする URL は
https://pepup.life/campaign/XXXX/ranking?mode=team&page=1
だが、ログインが必要なので
https://pepup.life/users/sign_in
に自動的にリダイレクトされる。
ログイン完了後は
https://pepup.life/campaign/XXXX/ranking?mode=team&page=1
に自動的に遷移する。
その後順次以下のように URL を変更し巡回する。
https://pepup.life/campaign/XXXX/ranking?mode=team&page=2
https://pepup.life/campaign/XXXX/ranking?mode=team&page=3
・エラー処理
・ランキングの table タグの tr タグが空だったり、「集計中」が含まれたテキストが表示された場合はそこで終了。その旨エラー出力して。
■ログインページの selector
ID、パスワード、ログインボタン、それぞれ以下。
sender-email
user-pass
<input type="submit" name="commit" value="ログイン" class="btn btn-default btn btn-primary btn-block" data-disable-with="ログイン">
■取得するデータ
・ランキングの table タグ。
3列あり、左から「順位」、「チーム名」、「総歩数の平均」。
1ページ30位まで記載があり、何ページまであるかは分からない。
1つの順位分の tr タグ例は以下。
これらのHTMLを selector としてしてください。
<table>
<tbody>
<tr class="table-row head"><td style="text-align: right;">順位</td><td style="text-align: left;">チーム名</td><td style="text-align: right;">総歩数の平均</td></tr>
<tr class="table-row"><td style="text-align: right;"><span class="num-value">768</span><span class="gray">位</span></td><td style="text-align: left;">ACCESS_A</td><td style="text-align: right;"><span class="num-value">61715</span><span class="gray">歩</span></td></tr>
■保存先
https://docs.google.com/spreadsheets/d/XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX/edit
シート名:ウオキング
A1セル:「順位」というテキスト
B1セル:「チーム名」というテキスト
C1セル:「総歩数の平均」というテキスト
D1セル:「URL」というテキスト
A2セル:ACCESS_A チームの順位
B2セル:「ACCESS_A」というテキスト
C2セル:「ACCESS_A チームの総歩数の平均」という数値
D2セル:ACCESS_A チームの URL
A3セル:ACCESS_B チームの順位
B3セル:「ACCESS_B」というテキスト
C3セル:「ACCESS_B チームの総歩数の平均」という数値
D3セル:ACCESS_B チームの URL
A4セル:ACCESS_C チームの順位
B4セル:「ACCESS_C」というテキスト
C4セル:「ACCESS_C チームの総歩数の平均」という数値
D4セル:ACCESS_C チームの URL
出力
以下のコードをご確認ください。条件に合わせてコードを作成しました。
import json
import os
import sys
from pathlib import Path
from google.oauth2 import service_account
from googleapiclient.discovery import build
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
# 設定
TARGET_TEAM_NAMES = ["ACCESS_A", "ACCESS_B", "ACCESS_C"]
SPREADSHEET_ID = "XXXX"
SHEET_NAME = "ウオキング"
HEADLESS = "--headless" in sys.argv
# Google API認証
CREDENTIALS_PATH = Path(__file__).resolve().parent / "credentials.json"
SCOPES = ["https://www.googleapis.com/auth/spreadsheets"]
creds = service_account.Credentials.from_service_account_file(str(CREDENTIALS_PATH), scopes=SCOPES)
# ログイン情報取得
LOGIN_INFO_PATH = Path(__file__).resolve().parent / "login_info.json"
with open(LOGIN_INFO_PATH, "r") as f:
login_info = json.load(f)
def init_driver(headless):
options = webdriver.ChromeOptions()
if headless:
options.add_argument("--headless")
service = Service(executable_path=ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=options)
return driver
def login(driver, email, password):
driver.get("https://pepup.life/users/sign_in")
driver.find_element(By.ID, "sender-email").send_keys(email)
driver.find_element(By.ID, "user-pass").send_keys(password)
driver.find_element(By.XPATH, '//input[@type="submit" and @value="ログイン"]').click()
def find_target_teams(driver):
found_teams = []
page = 1
while True:
driver.get(f"https://pepup.life/campaign/XXXX/ranking?mode=team&page={page}")
table_rows = driver.find_elements(By.CSS_SELECTOR, "table tr.table-row")
if not table_rows or "集計中" in table_rows[0].text:
print("集計中または空のページが見つかりました。終了します。")
break
for row in table_rows:
team_name = row.find_element(By.CSS_SELECTOR, "td:nth-child(2)").text
for target_team_name in TARGET_TEAM_NAMES:
if target_team_name in team_name:
rank = row.find_element(By.CSS_SELECTOR, "td:nth-child(1) span.num-value").text
avg_steps = row.find_element(By.CSS_SELECTOR, "td:nth-child(3) span.num-value").text
found_teams.append((rank, team_name, avg_steps, driver.current_url))
driver.save_screenshot(f"{target_team_name}_screenshot.png")
TARGET_TEAM_NAMES.remove(target_team_name)
break
if not TARGET_TEAM_NAMES:
return found_teams
page += 1
def save_to_sheet(teams_data):
service = build("sheets", "v4", credentials=creds)
for i, team_data in enumerate(teams_data, start=2):
range_ = f"{SHEET_NAME}!A{i}:D{i}"
values = [list(team_data)]
body = {"values": values}
service.spreadsheets().values().update(
spreadsheetId=SPREADSHEET_ID,
range=range_,
valueInputOption="USER_ENTERED",
body=body,
).execute()
def main():
driver = init_driver(HEADLESS)
login(driver, login_info["email"], login_info["password"])
found_teams = find_target_teams(driver)
if found_teams:
save_to_sheet(found_teams)
driver.quit()
if __name__ == "__main__":
main()
このコードは、指定された条件に従って特定のチームを探し、見つかったチームの情報をGoogleスプレッドシートに保存します。
最後に
この記事自体も ChatGPT さんに整形してもらいましたw
体感「箇条書きで言いたいことなぐり書きしたら、良い感じに敬語に直してくれる」。
敬語部分のタイプ量数割減、くらい?
便利は便利。
本記事のプロンプト抜粋
このチャットで生成したコードを Qiita に記事化したいです。
https://qiita.com/naohikowatanabe
の文体で qiita 記事の作成作成お願い。
markdown 形式で記載し、全ての出力のプレーンテキストをまとめて一つのコードブロックで出力して。
記事タイトル:ChatGPT(GPT-4) で一撃でスクレイピングするコードを生成出来たので感想とコツ
内容は以下を含めてください。
■今回やりたかったこと
・ChatGPT(GPT-4) で一撃でスクレイピングするコードを生成
■作ったもの概要
・保険組合のウォーキングイベントの会社内の3チームの歩数進捗の slack への自動投稿 bot
・処理は大きく2つ
・1. 「サイトのスクレイピング&スプシへアップロード」
・2. スプシの GAS で投稿文字列作成& slack へ投稿
・今回 ChatGPT でやったのは1の方。2は前回半年前開催分のコードをほぼそのまま流用。
・運良く(?)今回のタイミングでウォーキングイベントの運営が変わり、
サイトがまるっと変わったので1のスクレイピングコードは作り直しが必要だった。