複数キーによるドリルダウン
Groonga4.0.8より、複数のキーによるドリルダウンがサポートされました。
といわれても、さっぱりわからないと思います。私もよくわかりません。
ざっくりいうと、複数のカラムを組み合わせて、一つの複合キーと見なして、ドリルダウンを行える機能のようです。
たとえば、年度と会社名を示すカラムがあったとしましょう。
| ID | 年度 | 会社名 |
|---|---|---|
| 1 | 2001 | A 社 |
| 2 | 2001 | B 社 |
| 3 | 2001 | A 社 |
| 4 | 2002 | A 社 |
| 5 | 2002 | C 社 |
| 6 | 2003 | C 社 |
これまでは年度ごとか会社名ごとしかドリルダウンできなかったのが、年度+会社名の組み合わせで、件数をカウントすることができます。もちろん全文検索と組み合わせても高速に集計することができます。
| ID | 年度 - 会社名 | 件数 |
|---|---|---|
| 1 | 2001 - A 社 | 2 |
| 2 | 2001 - B 社 | 1 |
| 3 | 2002 - A 社 | 1 |
| 4 | 2002 - C 社 | 1 |
| 5 | 2003 - C 社 | 1 |
ただ、これ、複数のカラムの項目を組み合わせるため、種類数がやたら多くなってしまうので、使いどころが難しいなと感じました。種類が多い場合はうまく絞り込む必要がありそうです。
1つのカラムごとにリミットを設けられたら良さそうだなぁと思いましたが、たぶん無理な気がしました。
たとえば、「データベース」という検索クエリでヒット件数が上位4位の会社の年度ごとの推移を集計してみます。
まずは、上位4位の会社を求めます。
select ftext \
--match_columns 'title||content' \
--query 'データベース' \
--output_columns app_id \
--limit 0 \
--drilldown company \
--drilldown_output_columns _key,_nsubrecs \
--drilldown_sortby -_nsubrecs \
--drilldown_limit 4
[
[
0,
1418024062.11402,
0.105336666107178
],
[
[
[
331148
],
[
[
"app_id",
"ShortText"
]
]
],
[
[
44468
],
[
[
"_key",
"ShortText"
],
[
"_nsubrecs",
"Int32"
]
],
[
"株式会社H",
13981
],
[
"株式会社T",
13160
],
[
"F株式会社",
11115
],
[
"N株式会社",
10789
]
]
]
]
次に、上位4位の会社の2000年~2010年の出現件数を求めます。
select ftext \
--match_columns 'title||content' \
--query 'データベース +year:>=2000 +year:<=2010' \
--filter '(company == "株式会社H") || (company == "株式会社T") || (company == "F株式会社") || (company == "N株式会社")' \
--output_columns app_id --limit 0 \
--command_version 2 \
--drilldown[vector].keys year,company \
--drilldown[vector].output_columns _key[0],_key[1],_nsubrecs \
--drilldown[vector].sortby -_value.company,-_value.year,-_nsubrecs \
--drilldown[vector].limit 200
[
[
0,
1418024421.07761,
12.4310584068298
],
[
[
[
26744
],
[
[
"app_id",
"ShortText"
]
]
],
{
"vector": [
[
44
],
[
[
"_key[0]",
null
],
[
"_key[1]",
null
],
[
"_nsubrecs",
"Int32"
]
],
[
2010,
"F株式会社",
495
],
[
2009,
"F株式会社",
582
],
[
2008,
"F株式会社",
739
],
[
2007,
"F株式会社",
626
],
[
2006,
"F株式会社",
793
],
[
2005,
"F株式会社",
563
],
[
2004,
"F株式会社",
627
],
[
2003,
"F株式会社",
608
],
[
2002,
"F株式会社",
685
],
[
2001,
"F株式会社",
674
],
[
2000,
"F株式会社",
361
],
[
2010,
"株式会社T",
324
],
[
2009,
"株式会社T",
347
],
[
2008,
"株式会社T",
414
],
[
2007,
"株式会社T",
527
],
[
2006,
"株式会社T",
543
],
[
2005,
"株式会社T",
446
],
[
2004,
"株式会社T",
431
],
[
2003,
"株式会社T",
559
],
[
2002,
"株式会社T",
717
],
[
2001,
"株式会社T",
847
],
[
2000,
"株式会社T",
717
],
[
2010,
"株式会社H",
467
],
[
2009,
"株式会社H",
518
],
[
2008,
"株式会社H",
611
],
[
2007,
"株式会社H",
711
],
[
2006,
"株式会社H",
720
],
[
2005,
"株式会社H",
778
],
[
2004,
"株式会社H",
836
],
[
2003,
"株式会社H",
862
],
[
2002,
"株式会社H",
808
],
[
2001,
"株式会社H",
846
],
[
2000,
"株式会社H",
708
],
[
2010,
"N株式会社",
478
],
[
2009,
"N株式会社",
662
],
[
2008,
"N株式会社",
659
],
[
2007,
"N株式会社",
662
],
[
2006,
"N株式会社",
508
],
[
2005,
"N株式会社",
506
],
[
2004,
"N株式会社",
533
],
[
2003,
"N株式会社",
385
],
[
2002,
"N株式会社",
433
],
[
2001,
"N株式会社",
578
],
[
2000,
"N株式会社",
850
]
]
}
]
]
ちなみに、時間がかかっているのはほとんどfilterの部分で、ドリルダウンのところにはさほど時間がかかっていません。(このデータベースは非常にサイズが大きく、また、なぜかベクターカラムのインデックスがうまく効いていなく一致検索にしたため、遅いです。ちゃんとインデックス使えばもっと速いです。)
これで得られたデータをごにょごにょすれば、以下のようになります。
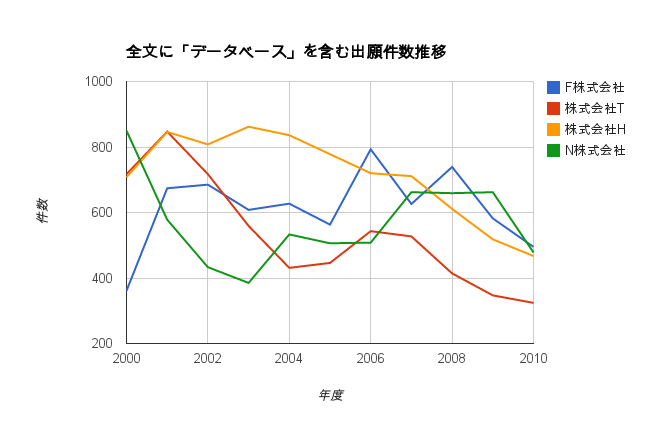
なお、これじゃない方法でもできるかもしれませんが、どの程度、効率的かどうかは特に検討していません。
in_values関数
Groonga4.0.7から、in_valuesという関数が実験的に追加されています。
これは、(column @ query) OR (column @ query)という形式よりも複数のクエリが含まれているかどうかを効率的に絞り込むことができます。
たとえば、上記のクエリをin_valuesに書き換えると以下のようになります。
select ftext \
--match_columns 'title||content' \
--query 'データベース +year:>=2000 +year:<=2010' \
--filter 'in_values(company,"株式会社H","株式会社T","F株式会社","N株式会社")' \
--output_columns app_id --limit 0 \
--command_version 2 \
--drilldown[vector].keys year,company \
--drilldown[vector].output_columns _key[0],_key[1],_nsubrecs \
--drilldown[vector].sortby -_value.company,-_value.year,-_nsubrecs \
--drilldown[vector].limit 200
[
[
0,
1418025207.46389,
5.28521847724915
],
[
[
[
26744
],
[
[
"app_id",
"ShortText"
]
]
],
{
"vector": [
[
44
],
[
[
"_key[0]",
null
],
[
"_key[1]",
null
],
[
"_nsubrecs",
"Int32"
]
],
[
2010,
"F株式会社",
495
],
[
2009,
"F株式会社",
582
],
・・・(略)
}
]
]
結果は変わらずに2倍以上高速化できていることがわかります。
| in_values あり | in_values なし |
|---|---|
| 5.28521847724915 sec | 12.4310584068298 sec |
なお、in_valuesが1件だけの場合は、逆に遅くなることもあるようなので注意が必要です。
select ftext \
--match_columns 'title||content' \
--query 'データベース +year:>=2000 +year:<=2010' \
--filter 'in_values(company,"株式会社H")' \
--output_columns app_id --limit 0 | jq .
[
[
0,
1418025464.79051,
1.93979430198669
],
[
[
[
7865
],
[
[
"app_id",
"ShortText"
]
]
]
]
]
select ftext \
--match_columns 'title||content' \
--query 'データベース +year:>=2000 +year:<=2010' \
--filter '(company == "株式会社H")' \
--output_columns app_id --limit 0
[
[
0,
1418025478.24595,
0.680641412734985
],
[
[
[
7865
],
[
[
"app_id",
"ShortText"
]
]
]
]
おまけ
Groongaのドキュメントにまだ書かれていない機能があったりしますが、以下を参照すれば、だいたいわかると思います。
-
組み込みコマンドのテストケース(使い方がわかる)
https://github.com/groonga/groonga/tree/master/test/command/suite -
組み込みコマンドや関数の実装箇所(引数とか処理がわかる)
https://github.com/groonga/groonga/blob/master/lib/proc.c