はじめに
Databricks/Apache Sparkで開発を行っている際にTempViewを使用していたのですが、TempViewはメモリ上のデータを参照していると誤った認識をしていたため嵌りました。結論と対応方法を備忘録も兼ねてこの記事で共有させてください。
実際に嵌った話
処理の最初にDatabricks外部のDB から大量データをDatabricksに抽出し、TempViewに格納して、後続の処理ではTempViewを参照してデータを加工していく処理があります。
このTempViewを参照している箇所の処理が軒並み遅くメモリ上に格納されているのになぜ・・・?となったのがきっかけです。
誤った認識
Apache SparkのTempViewはメモリ上にデータが格納されていると思っていました。例えば下記SQLをDatabricks上で実行したときにTMP_COMMENTSはメモリ上からデータが参照されると誤った認識をしていました。
val commentsDF = spark.read.jdbc(jdbcUrl, "comments", connectionProperties)
if(commentsDF.count() == 0) dbutils.notebook.exit("0件のため処理を終了します。")
commentsDF.createOrReplaceTempView("TMP_COMMENTS")
SELECT *
FROM TMP_COMMENTS
ただDB側のSQL実行ログを確認するとTMP_COMMENTSを参照したタイミングでDBにSQLが実行されていることが判明し、メモリ上を参照しているわけではなく毎回DBに対してSQLが実行されているとわかりました。
結論
Apache SparkのTempViewはあくまでもRDBのViewと同様に実態を持たないViewでしかありません。
メモリ上に格納したい場合、cache()コマンドを実行しましょう。
公式の説明
Apache Spark のドキュメントにはこう書いてあります。
ビューは、
SQLクエリの結果セットに基づいています。CREATE VIEWは、物理データを持たない仮想テーブルを構築するため、ALTER VIEWやDROP VIEWなどの他の操作は、メタデータのみを変更します。
うーん、少しわかりづらいですね。。。
ただ物理データは持たないと書いてあるのであくまでクエリ情報しか保持していないと分かるような気もします。
Stack OverflowによるQA
同じような疑問を持った人がStack Overflowにもいらっしゃって下記回答がありました。
How does createOrReplaceTempView work in Spark?
createOrReplaceTempViewcreates (or replaces if that view name already exists) a lazily evaluated "view" that you can then use like a hive table in Spark SQL. It does not
persist to memory unless you cache the dataset that underpins the view.
簡単に翻訳すると、createOrReplaceTempViewは遅延評価されるViewでしかなく、cacheしない限りメモリ上に永続化されないと記載があります。
なるほど。。。createOrReplaceTempViewではメモリ上に格納されないのですね。。。
実際にcache()コマンドを使用するしないでどう挙動が変わるか確認していきましょう。
実際の挙動と対応策
キャッシュを利用しない場合
まずは取得するデータをキャッシュせずcreateOrReplaceTempViewを実行した場合、どういった挙動なのか確認していきましょう。
外部DBのcommentsテーブルはレコードを20万件投入して試していきます。
val commentsDF = spark.read.jdbc(jdbcUrl, "comments", connectionProperties)
if(commentsDF.count() == 0) dbutils.notebook.exit("0件のため処理を終了します。")
commentsDF.createOrReplaceTempView("TMP_COMMENTS")
SELECT *
FROM TMP_COMMENTS
実行結果
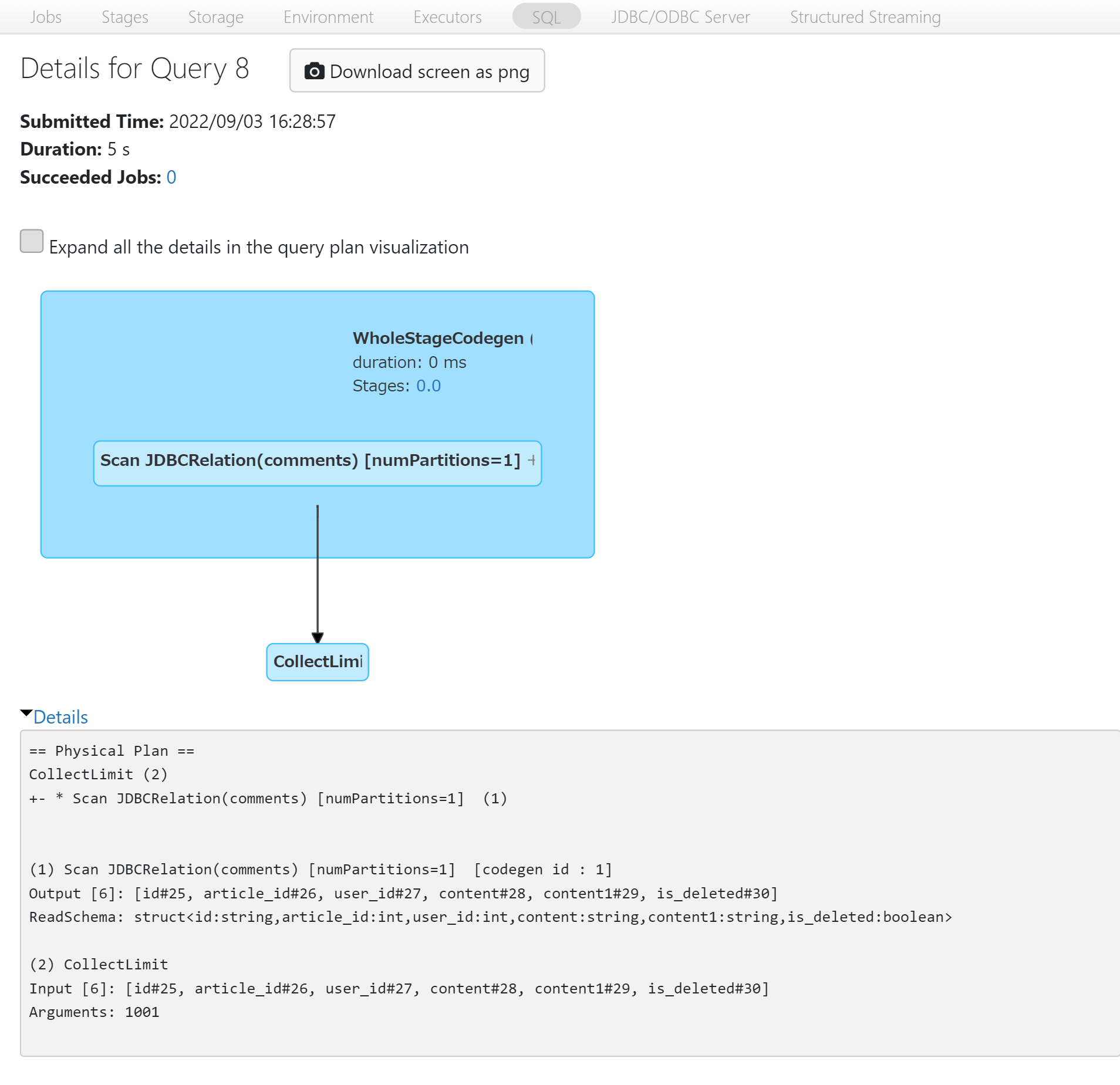
Storage

Scan JDBCRelationしか表示されていないためリモートに存在するDBに接続されていますね。このままだとTMP_COMMENTSを参照するたびにDBにクエリが実行されてしまいます。
またStorageを見てもデータが一切キャッシュされていないことが確認できます。
キャッシュを利用した場合
DataFrameに備わっているcache()コマンドを実行後、createOrReplaceTempViewを実行した場合はどういった挙動をするのか確認していきましょう。
//.cache()を追加
- val commentsDF = spark.read.jdbc(jdbcUrl, "comments", connectionProperties)
+ val commentsDF = spark.read.jdbc(jdbcUrl, "comments", connectionProperties).cache()
if(commentsDF.count() == 0) dbutils.notebook.exit("0件のため処理を終了します。")
commentsDF.createOrReplaceTempView("TMP_COMMENTS")
SELECT *
FROM TMP_COMMENTS
実行結果
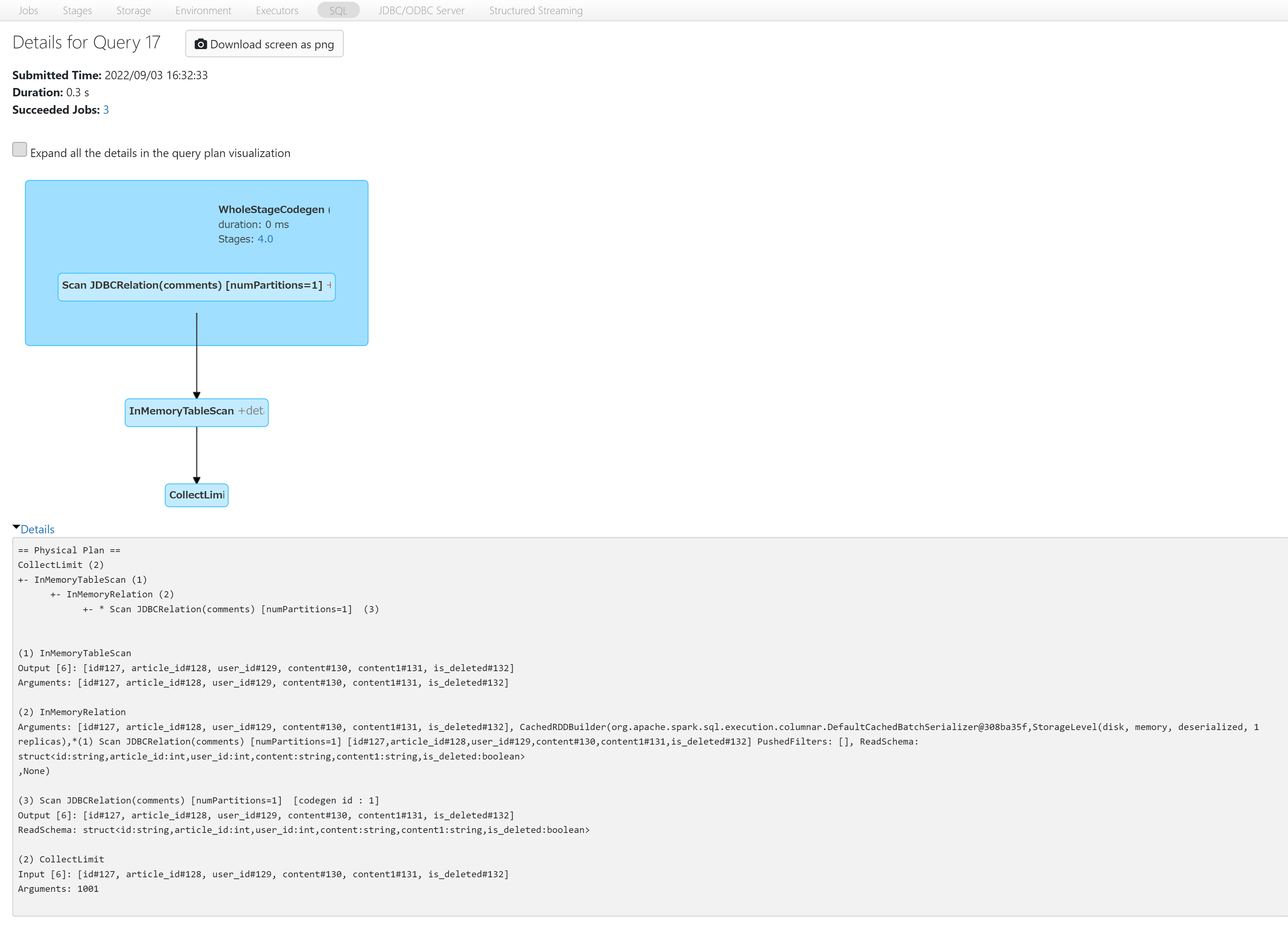
Storage
今度はScan JDBCRelation後にInMemoryTableScanが実行されていますね。
TempViewの元となるDataFrameを評価して、Scan JDBCRelationも実行されますがキャッシュされていると判断してInMemoryTableScanがその後実行されています。
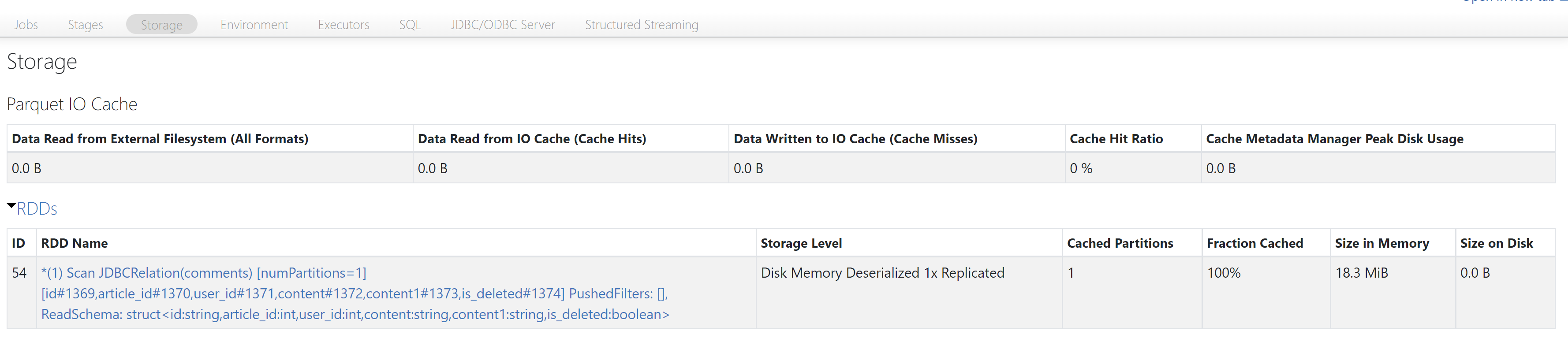
実行時間が5.0s→0.3sと短くなっていることや、Storageにキャッシュ情報が記載され、上の表でFraction Cashed(日本語でキャッシュされた率)が100%となっていることから、メモリ上にあるデータを参照していることが確認できます。
cache()コマンドを実行することでメモリ上のデータを参照できるようになりましたね!
注意点
DataFrameは遅延評価のため、正確にはcount()が実行されたタイミングでデータがキャッシュされています。(DataFrameの変数宣言している箇所はクエリ情報を保持しているだけ)
キャッシュしていない場合は、外部DBに毎回クエリを実行していますが、cache()コマンドを実行した場合、count()後はキャッシュされたデータを参照しています。
おわりに
TempViewでメモリ上のデータを参照したい際は、DataFrameのcache()コマンド実行後にcreateOrReplaceTempViewを実行すればいいことが分かりました。
そんなの常識だよ!!と思うかもしれませんが少しでも参考になる方がいましたら幸いです。