日本語大規模言語モデルの春到来
ChatGPT以来、オープンな言語モデルに注目が集まっていましたが、商用利用可能かつ日本語が思い通りに出力できるモデルはなかなか現れませんでした。Llama派生のモデルは前述どおり商用利用ではありませんでした。
しかし2023年5月17日、革命が起きました。
CyberAgent社によるopen-calmとRinna社によるjapanese-gpt-neox-3.6bが公開されました。
このおかげで純正日本語モデルのファインチューニングが行えるようになりました。(一応これ以前にもRinnaから1bモデルは公開されていた)
そこで最近目にした下記の画像について気になることありました。
これはChinchillaなどのモデルを作っているDeepmindのDr Alan D. Thompsonさんによって作成された画像です。
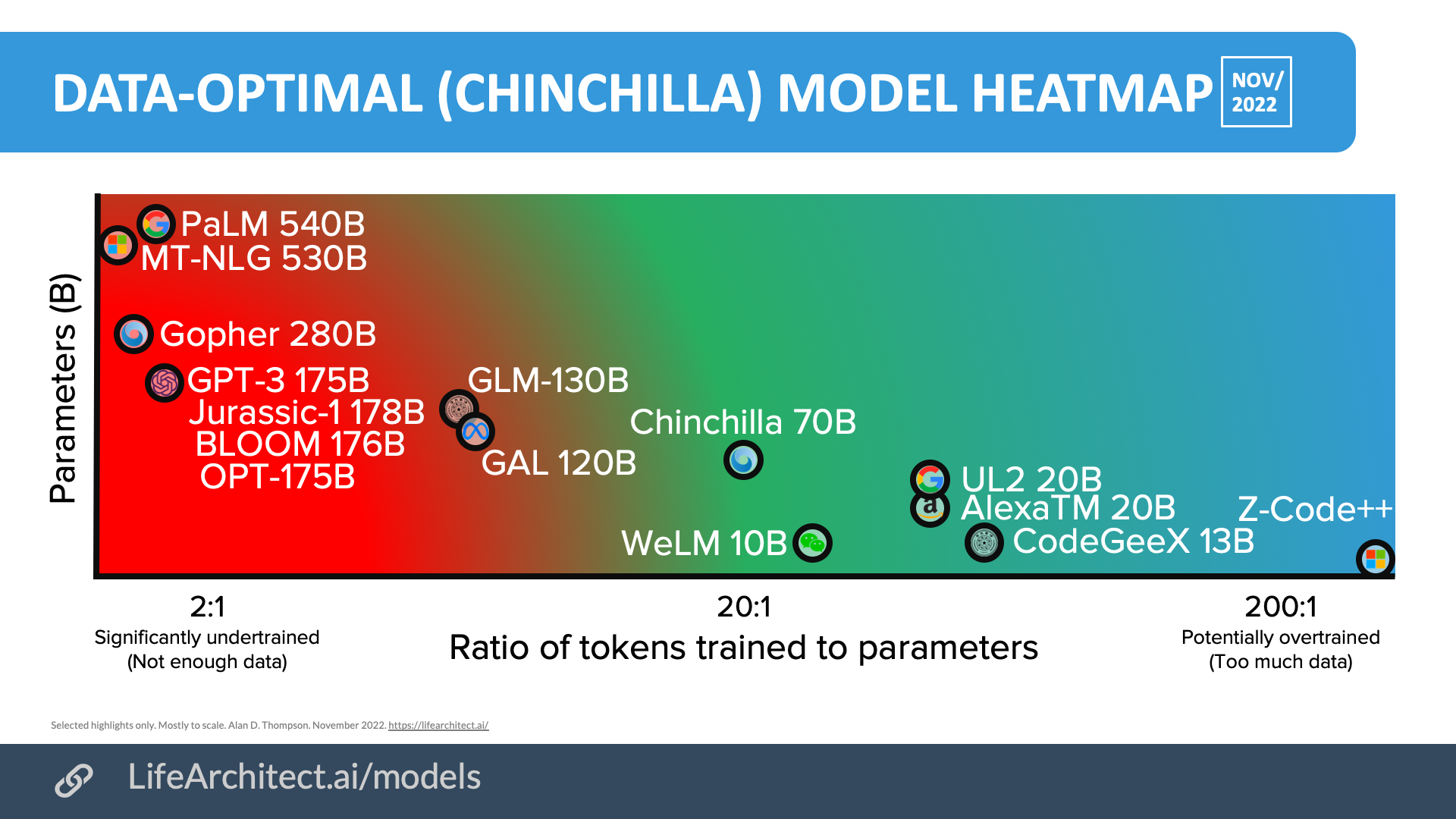
図1 学習データセットのトークン数とパラメータの最適な比率について
引用元
この図によると、トークン数とパラメータの比は20:1が最適でパラメータがこの比より少ない場合は過学習、多い場合は学習不足になるとのことでした。
今回はopen-calmとjapanese-gpt-neox-3.6bについてデータセットを調べて、トークン数とパラメータの比を確認しようと思います。
open-calmとjapanese-gpt-neox-3.6bのデータセット
open-calmとjapanese-gpt-neox-3.6bに使われているデータセットはどちらも同じで使われているのはwikipedia、mc4、cc100の3つがどちらも使われていました。
ようするに現在の大規模かつ良質な日本語データセットはこの3つと考えてもいいのでしょう。
それぞれの文字数は以下の通りです。
| データセット | 文字数 |
|---|---|
| wikipedia | 10億文字 |
| cc100 | 253億文字 |
| mc4 | 3,500億文字 |
こうしてみるとmc4がやけに大きいですが、こちらにはちょこちょこ違う言語が混じっているそうです。
トークン数の計算ですが、さすがにデータセットをすべてトークナイザーにかけられないので概算します。
下記はトークン数の確認です。ちょっとさぼってopen-calmのトークナイザーで少ない文字数で実験をしてみます。トークン数を計算するのは以下のコードになります。
text = "昨日の夜は友達と美味しいディナーを楽しんだ。レストランで新鮮なサラダやシーフードパスタを堪能した後、甘いデザートを頬張った。食事の後は散歩しながら街を散策し、楽しい時間を過ごした。今日は天気が良くて気分も爽やかだ。午後は図書館で勉強し、新しい本を見つけた。興味深い内容で、夢中になって読み進めた。夕方にはスポーツジムでエクササイズし、体を動かすことでストレスも解消された。帰り道で美味しいコーヒーを買って、リラックスしながら家に帰った。今週末は友人と旅行予定があるので、ワクワクしている。楽しい時間を過ごすために準備を進めなければ。"
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("cyberagent/open-calm-7b", device_map="auto", torch_dtype=torch.float16)
tokenizer = AutoTokenizer.from_pretrained("cyberagent/open-calm-7b")
tokens = tokenizer.encode(text, add_special_tokens=True) # add_special_tokens=Trueは特殊トークンの追加を指定するオプションです
num_tokens = len(tokens)
print("トークン数:", num_tokens)
日本語266文字が大体112トークンになるので、今回は50%弱になると考えていきます。
先ほどの表にトークン数の概算を追加すると下記になります
| データセット | 文字数 | トークン数 |
|---|---|---|
| wikipedia | 10億 | 5億 |
| cc100 | 253億 | 125億 |
| mc4 | 3,500億 | 1,750億 |
この3つを足すとデータセット合計で1880億トークンになります。
トークン数とパラメータ数との比率
| モデル名 | 最大パラメータ数 | トークン数:パラメータ数 |
|---|---|---|
| open-calm | 68億 | 約27:1 |
| japanese-gpt-neox-3.6b | 36億 | 約52:1 |
結果
これを見てみると、Open-Calmのほうは最適な比率に近いことがわかり、一方でjapanese-gpt-neox-3.6bのほうはパラメータ数がやや足りないという結果になりました。
日本語データセットに明るくないので確かなことは言えないのですが、過剰なパラメータ数になっていないのはやはり日本語の良質なデータセットが少ないためでしょうか。
図1ではGPT3ではパラメータが過剰ということになっていますが一方である程度のパラメータ数はある程度は正義だと思うのでもっと大きなモデルが出てきてくれるとまた面白くなってきますね。