タイトル通りランダム君を相手に強化学習をしてみました。
networkに与える入力値のサイズは883
一層目には自分の石の情報
二層目には相手の石の情報
三層目には合法手の情報
を0と1のみで表現しています。
network構造は
フィルターサイズが108のcnnを12層
ユニットサイズが512の全結合層が5層となっています。
活性化関数はprelu(マイナスの値を自動で学習してくれる関数)
活性化の前にbatch_normalizationを挟んでいます。
出力層は64個のsoftmax関数です。
学習時のドロップアウトはcnnと全結合共に0.5です
学習で使うデータはランダム君との対局データをそのまま使います。
勝った試合はその試合中にとった全ての行動を正解とし、その行動がより出やすくなるように勾配下降します。
負けた試合は反対に、その行動が出にくくなるように勾配下降します。
正解ラベルの与え方はごく単純でmnnistでお馴染みのone_hot_labelを与えるだけです。
その行動をより出しやすくしたい時[0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
その行動を出にくくしたい時[1, 0, 1, 1, 1, 1, 1, 1, 1, 1]
今回は64個の出力値なのでこれの64個版のone_hot_labelになります。
また、不正な手を指さないように、
合法手の中で出力値が最も大きいものを指し手として採用しています。
また強化学習をする際は、通常ランダム行動を取り入れますが、今回はなしにしました。
学習のグラフ↓
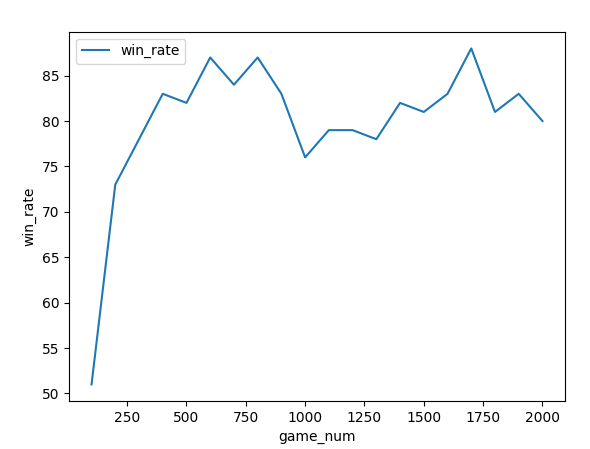
ランダム君との対局という事で、勝率にばらつきはあるものの、8割ぐらいは勝てるようになっているのがわかります。
他に、以下のような事も試しましたが、これと言った効果はありませんでした。
・経験再生
リストなどに局面のデータと、行動した時のデータを保存しておき、
一定のタイミングでミニバッチ学習として再度する手法
経験再生はディープラの強化学習で肝となる手法というイメージでしたが
1000試合毎に直近1000試合分のデータを用いて再度学習させてみたもののこれと言った効果はありませんでした
・負けた時のみ学習させる
8割近くで止まってしまうのはnetworkが慢心してしまうからじゃね?と思ったので
負けた時のみ、その行動が出にくくなるように学習をさせてみましたが、勝率が6割~7割になってしまい性能が悪くなりました。
やはり勝った時のコツも教えてあげるのが大事なようです。
ランダム行動もさせてもみましたが、結果は同じでした。
とにもかくにも、dqnのようなやや複雑な式を組まなくてもそれなりに学習出来る事がわかりました。
次はゼロからの状態でランダム君に100%勝てるようしたいなーと思ってます。