データサイエンス初学者のための実践的な学習環境
「データサイエンス100本ノック(構造化データ加工編)」をGitHubに無料公開
https://digitalpr.jp/r/39499
こちらをやってみようと思います。
ちなみにRは全くわからないのでやらないと思います。
環境
・Windows10
・Docker for Desktop
・Git
環境構築
Docker起動
wsl -e docker-desktop
Gitからクローン
git clone https://github.com/The-Japan-DataScientist-Society/100knocks-preprocess.git
Dockerをビルド
cd 100knocks-preprocess
docker-compose up -d --build
しばらく時間がかかります・・・
なんかいろいろ落としてるぽい・・・
環境構築の注意点
Docker Toolboxを使っている場合、アクセス先のURLが変わります。
http://192.168.99.100:8888
クライアントツールを使ってDBにアクセスする場合のホストも合わせて変わります。
100本ノック環境の確認
以下にアクセス
http://localhost:8888
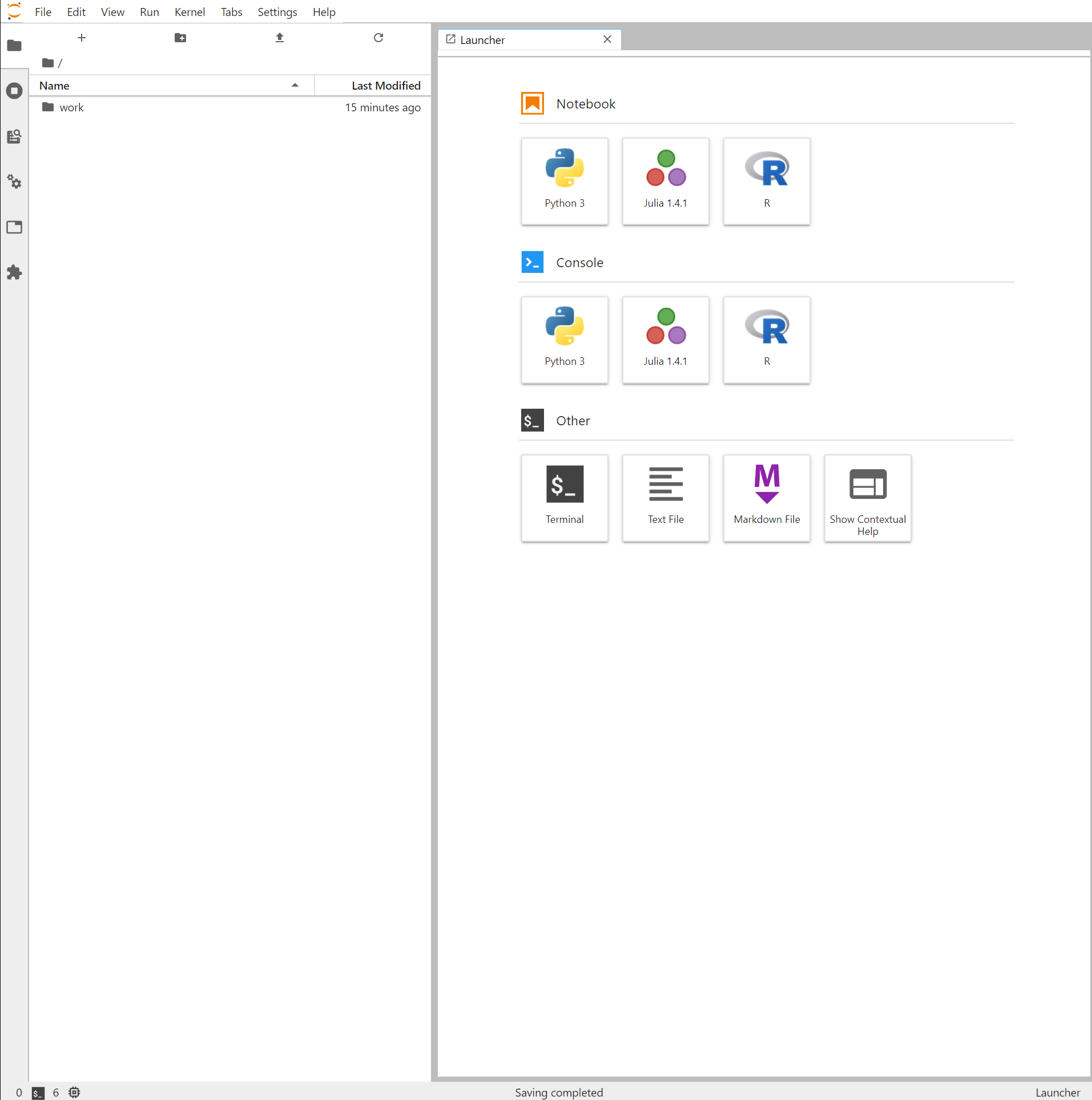
こんな画面が開くはず
work/preprocess_knock_SQL.ipynbを開くと
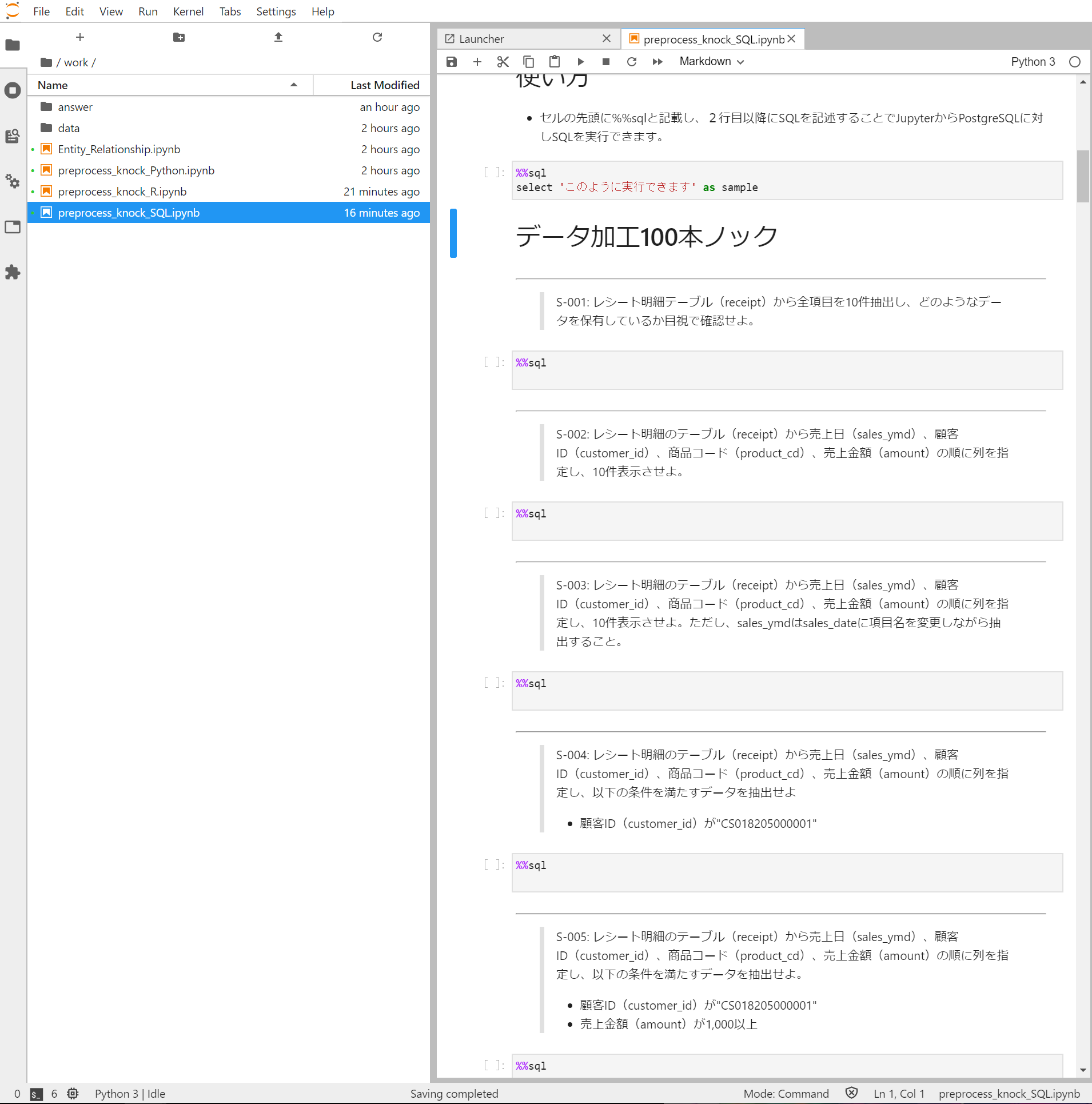
こんな感じでSQLの問題があります。
Python、Rも同様でanserフォルダの中に答えもあるみたい。
DBはPostgre12です。
ザラっと見た感じそんな難しくはない感じですが、第3正規化しろとか言われるとだいさん・・・?って一瞬なってググりますねw
おまけ
この環境はJupyter Notebookっていうのを使ってるみたいですね。
なんかよく見るなって思ってたけどよく知らないので調べてみました。
Jupyter notebookはJupyterプロジェクトの一つでOSSのWebアプリケーションです。
Jupyterプロジェクトとは、複数の言語にまたがって対話的な処理実行を実現するためのサービスやOSSを開発するためのプロジェクトです。
そしてプログラムの実行結果などをまとめて管理することができます。
*.ipynbって拡張子のこの画面を作っているみたいで、中を開くと以下のようなjson形式のファイルでした。
{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# DB論理設計(ER図)\n",
"- 一部、FKとなっているデータについて、マスターテーブルに存在しないデータを有することもあります\n",
"- 例)非会員の顧客IDは顧客テーブルに含まれません\n",
"- そのため、FKの情報は一般的なデータベースにおける外部参照制約を満たすものではありません\n",
"- データを結合する際の参考情報として利用してください"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.6"
}
},
"nbformat": 4,
"nbformat_minor": 4
}
参考
今さら聞けない Jupyter notebook https://qiita.com/szk3/items/920fd3e905ed16469780