前回の記事では、モデルとは何なのかということ、そして選定したモデルが適切であるかをどのように評価するかをまとめました。
今回はモデルの中身とはどのようなものなのか、そのアルゴリズムをまとめていきます。
依然として初級レベルの個人メモレベルですので、誤りなどあれば指摘していただけると嬉しいです。
モデル俯瞰
前回、モデルとは入力データを引数にとり結果を算出する関数のようなものだとまとめました。つまりそこには、データをどのように取り扱うのかというアルゴリズムが存在しています。
実際の関数にも多くの種類があるように、機械学習のモデルにおいても、取り扱うデータによって適切なモデル(アルゴリズム)というものが異なってきます。
モデルの種類を大別すると以下のように分けられます。
回帰(Regression)
「回帰」とは、正解データが連続であるときに、正解値を予測する手法のことです。
例えば、過去の株価データを元に明日の株価を予想したい、という場合にはこの手法を用いることになります。
本記事で扱うのはこちらのモデルとなります。
・過去の株価
| 1/1 | 1/2 | 1/3 | 1/4 |
|---|---|---|---|
| 100 | 120 | 130 | 110 |
→ここから、一つの正解データ、「1/5の株価」を求めたい ・・・ 回帰が適切
| 1/5 |
|---|
| ??? |
分類(classfication)
分類とは、正解データが2つ以上の値であるときに、正解データを予測手法のことです。
例えば、たくさんの画像の中から「犬」と「猫」の画像を判別したい、という場合にはこの手法を用いることになります。
本記事では、こちらは扱いません、
・画像データ
| (・w・) | (・v・) | (@x@) | (@m@) |
|---|---|---|---|
| 犬 | 鳥 | 兎 | 猫 |
→ここから、複数の正解データ「犬」と「猫」を求めたい ・・・ 分類が適切
回帰のアルゴリズムについて
前述したように、データをどのように処理するかというのはモデルのアルゴリズムによって異なるわけですから、適切なモデルを選定するということは、適切なアルゴリズムを選定するということに他なりません。
が、今回はアルゴリズムの説明は割愛します。別途アルゴリズムについてもまとめます。
プログラムによる実践
データの用意
まずは使用するデータを用意します。今回使用するのは、学習用として用意されているsklearnのボストンデータです。
今回の正解データとなる価格情報を y , 正解データを導き出すのに用いられる各種情報を x とします。
import pandas as pd
from sklearn.datasets import load_boston
dataset = load_boston()
x = pd.DataFrame(dataset.data, columns=(dataset.feature_names)) #data:正解データを除く格納データ feature_names:特徴名
y = pd.DataFrame(dataset.target, columns=['target']) #target:用意されている正解データ
今回扱うデータの統計情報を確認しましょう。
print('xの特徴の名前:%s' %dataset.feature_names)
#実行結果:xに用意されている特徴の名前:['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO' 'B' 'LSTAT']
print('x のデータ数:%i , 特徴数:%i' %x.shape) #実行結果:x のデータ数:506 , 特徴数:13
print('y のデータ数:%i , 特徴数:%i' %y.shape) #実行結果:y のデータ数:506 , 特徴数:1
#データと正解データを結合させてものの先頭5行を抽出して確認する
x.join(y).head()
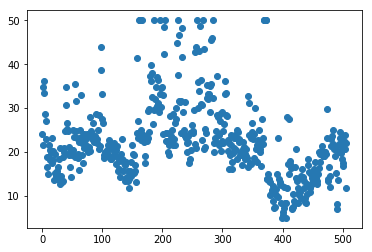
次に正解データyの分布を確認してみます。
用意したxには各種特徴量が格納されているわけですが、それらから導き出されるべき正解データの分布です。これと同じような分布図をxから導きだせばいいわけですね。
import numpy as np
from matplotlib import pyplot #描画用ライブラリ
count = np.linspace(0,y.target.count(),y.target.count()) #yのデータ数の数だけの要素を持つ一次元配列
pyplot.plot(count, y, 'o',) #x軸にデータ番号、y軸にデータの値を設定し、分布を点で描画した図をセット
pyplot.show() #描画開始
アルゴリズム使用による予測値の算出
ここまでで作成したデータを利用して、実際にモデルを組んでいきます。
といっても、機械学習まわりのライブラリにはすでに組まれたモデルが存在しており、アルゴリズムも呼び出すだけですの、自分でロジックを組む必要はありません。
from sklearn.linear_model import LinearRegression #線形回帰モデル
from sklearn.metrics import r2_score #正解データと予測値の比較を行う指標
model = LinearRegression() #一番シンプルな形での線形回帰モデルの呼び出し
y_matrix = y.as_matrix().ravel() #正解データをnumpy配列に変換後、次元を落とす
model.fit(x, y_matrix) #生成したモデルに、データxと正解値yを学習させる。これによりモデルはxについての予測値を持つようになる。
result1 = model.predict(x) #生成したモデルにxを読み込ませ予測値を抽出する
pyplot.plot(result1,'bo',y_matrix, 'ro')
pyplot.show()
#予測値と正解値の分布を重ね合わせて比較する。青が予測値で赤が正解値なので、生成したモデルはxを適切に学習し予測値を導き出したことがわかる。
print('予測値と正解値の相関性:%f..3' %r2_score(result1, y)) #予測値と正解値の相関性を確認する
#実行結果:予測値と正解値の相関性:0.973
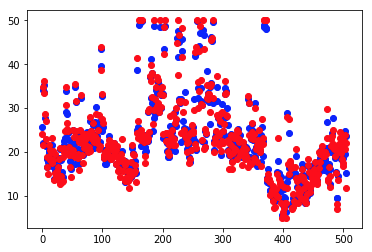
青の点がxから算出された予測値、赤が正解データとなりますので、今回のモデルはかなりの制度で正解値を予測できたと判断できます。
相関性を示すR2値も、0.973と高い値を示しています。
これがモデル構築の流れとなります。
本来であれば、データxでモデルを作成し、未知のデータをモデルに処理させることで未来を推測することになりますが、今回は簡便に済ませたかったので、モデル生成に用いたデータをそのままモデルに処理させています。
ので、高い精度で予測値を算出できたのは当たり前といえば当たり前です。
今回はここまでとなります。
次回以降、また他のクラスを使ったモデル構築や手法についてまとめていきます。
以上。