Kaggleのチュートリアルとして公開されているTitanic問題に対する素敵な解答を提出されている方がいたので、(データ分析と英語の)勉強を兼ねて翻訳してみます。
私はデータ分析も英語も特に出来るわけではないので、いろいろ誤りがあるかと思います。
もしお気づきの点があればお知らせくだされば幸いです。
なお、訳出は適宜抜粋しつつ行うものとします。全文訳ではないことをご承知おきください。
本記事は3記事目となります。前回記事などをお読みでなければ先にそちらをご覧ください。
前回のまとめ(翻訳者による)
|特徴名|意味|判明した主な事実|今後の方針|
|----|----|----|----|----|
|Pclass|乗船クラス|1の乗客は最も生存率が高かった。3の乗客は最も多いが、最も生存率が低かった
|Sex|性別|女性の生存率が高かった
|Age|年齢|4歳以下の幼児は生存率が高かった|年齢帯による区別を設ける|
|Fare|料金|高額な料金を払った乗客は生存率が高い|料金帯による区別を設ける|
|Embarked|乗船地|Pclassが3である人々および男性乗客者に対して生存率を変化させる要因である。
データのまとめ
私たちはここまでデータセットと答えが要求することを観察し、いくつもの仮定と決定を手に入れてきた。ここまでは一つの特徴もしくはその値を変化させるということをしてこなかった。ここからは、データの修正、特徴の作成及び補完などを行い、私たちの仮定と決定を実行していこうと思う。
特徴削除による修正
これを実行することは、目標に近づくためのよいスタートだ。特徴を削除することにより、私たちはより少ないデータによって分析処理を行うことができる。これは処理の早くすると同時に、分析を楽にする。
私たちの仮定と決定に基づけば、Cabin特徴とTicket特徴は削除することができる。
ここで注意するのは、データの一貫性を保つためにも、行う削除処理は訓練用データと本番用データの両方に対して行わなければいけないということだ。
print("Before", train_df.shape, test_df.shape, combime[0].shape, combine[1].shape)
train_df = train_df.frop(['Ticket', 'Cabin'], axis=1)
test_df = test_df.frop(['Ticket', 'Cabin'], axis=1)
combine = [train_df, test_df]
print("After", train_df.shape, test_df.shape, combime[0].shape, combine[1].shape)
>>>
Before (891, 12) (418, 11) (891, 12) (418, 11)
After (891, 10) (418, 9) (891, 10) (418, 9)
既存の特徴から新たな特徴を作る
私たちは名前特徴から敬称を抜き出して再設計することができたならばそれを分析したいし、そしてその敬称と生存率との間の相関についてテストしたい。これは名前特徴と乗客IDを削除を行う前に実行する。
正規表現を用いることによって、敬称特徴を抽出していく。正規表現のパターンで「¥w+¥.」は名前特徴の中でドット文字で終了している最初の単語にマッチする。expand=False というフラグにより、データはDataFrame型として返却される。
観察結果
敬称、年齢、そして生存率についてプロットしてみると、次の観察結果が得られる。
- ほとんどの敬称は年齢を明確に区別する。例えば、Masterという敬称は平均年齢が5歳である。
- 敬称と年齢間の生存率の違いは軽微なものである。
- 特定の敬称を持つ人々は、より生存率が高い(Mme,Lady,Sir)傾向があるか、またはより生存率が低い(Don,Rev,Jonkheer)傾向を示している。
決定
- 敬称という新たな特徴をモデルの訓練用に残すこととする。
for dataset in combine:
dataset['Title'] = dataset.Name.str.extract(([A-Za-z+]¥.',
expand=False)
pd.crosstab(train_df['Title'], train_df['Sex'])
>>>
Sex female male
Title
Capt 0 1
Col 0 2
Countess 1 0
Don 0 1
Dr 1 6
Jonkheer 0 1
Lady 1 0
Major 0 2
Master 0 40
Miss 182 0
Mlle 2 0
Mme 1 0
Mr 0 517
Mrs 125 0
Ms 1 0
Rev 0 6
Sir 0 1
もっと一般的な名前もしくはそれらに分類されるようなものについては、'Rare'という名前に置き換えることができる。
for dataset in combine:
dataset['Title'] = dataset['Title'].replace(['Lady', 'Countess',
'Capt', 'Col', 'Don', 'Dr', 'Major', 'Rec', 'Sir',
'Jonkheer', 'Dona'],'Rare')
dataset['Title'] = dataset['Title'].replace('Mile', 'Miss')
dataset['Title'] = dataset['Title'].replace('Ms', 'Miss')
dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs')
train_df[['Title', 'Survived']].groupby(['Title'], as_index=False).mean()
>>>
Title Survived
0 Master 0.575000
1 Miss 0.702703
2 Mr 0.156673
3 Mrs 0.793651
4 Rare 0.347826
このカテゴリ特徴である敬称項目は、順序特徴へと変換できる。
title_mapping = {"Mr":1, "Miss":2, "Mrs":3, "Master":4, "Rare":5}
for dataset in combine:
dataset['Title'] = dataset['Title'].map(title_mapping)
dataset['Title'] = dataset['Title'].fillna(0)
>>>
PassengerId Survived Pclass Name Sex Age SibSp Parch Fare Embarked Title
0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 7.2500 S 1
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 71.2833 C 3
2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 7.9250 S 2
3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1 0 53.1000 S 3
4 5 0 3 Allen, Mr. William Henry male 35.0 0 0 8.0500 S 1
いま、私たちは訓練用データと本番用データから憂いなく名前特徴を削除することができる。また、訓練用データの中の乗客ID特徴も不要である。
train_df = train_df.drop(['Name', 'PassengerId'], axis=1)
test_df = test_df.drop(['Name'], axis=1)
combine = [train_df, test_df]
train_df.shape, test_df.shape
>>>
((891, 9), (418, 9))
カテゴリ特徴の変換
文字列を含む特徴を数的値に変換することができる。これは、最も優れたアルゴリズムを選定するうえで必要なことである。そのようにすることはまた、特徴を補完する上でも役立つ。
ではSex特徴を、男性ならば0、女性ならば1の値を持つGenderという新しい特徴に変換することから始めよう。
for dataset in combine:
dataset['Sex'] = dataset['Sex'].map({'female':1, 'male':0}).astype(int)
train_df.head()
>>>
Survived Pclass Sex Age SibSp Parch Fare Embarked Title
0 0 3 0 22.0 1 0 7.2500 S 1
1 1 1 1 38.0 1 0 71.2833 C 3
2 1 3 1 26.0 0 0 7.9250 S 2
3 1 1 1 35.0 1 0 53.1000 S 3
4 0 3 0 35.0 0 0 8.0500 S 1
連続数的特徴の補完
ここでは欠損または空白を持つ特徴について、予測補完を行う。まずは年齢特徴に対してこの作業を行う。
連続的数的な特徴を補完するにあたっては3つの方法を考えることができる。
- 平均と標準偏差の間で乱数を生成するという簡単な方法
- より正確な欠損値推測を行う方法として、他の特徴のとの相関を用いる方法もある。今回の例において私たちは、年齢と性別、そして乗船クラスの間に相関があることを知っている。そこで、年齢と乗船クラス及び性別をまたいだ中央値を用いることで、年齢を推測することができる。例えば、乗船クラスが1かつ性別が0であるときの年齢の中央値、また乗船クラスが1で性別が1であるときの中央値、などのように。
- 3つ目の方法は1と2の方法を合わせたものである。中央値に基づいて年齢値を推測する代わりに、乗船クラスと性別を合わせたものに基づき算出された平均と標準偏差を用いて、その間の乱数を生成させる方法である。
1と3の方法はモデルの中にノイズを招くことにもなる。複合的に実行した結果はおそらく変化してしまうことだろう。ここでは2の方法を用いることとする。
grid = sns.FacetGrid(train_df, row='Pclass', col='Sex', size=2.2, aspect=1.6)
grid.map(plt.hist, 'Age', alpha=.5, bins=20)
grid.add_legend()
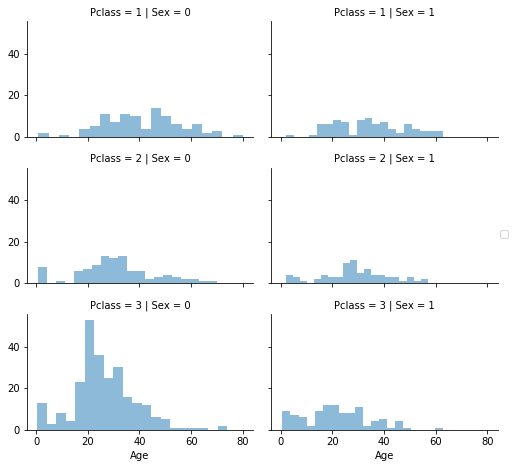
乗船クラスと性別を合わせたものに基づいた推測値で年齢を満たすためにも、まずは空白の配列を用意する。
guess_ages = np.array((2,3))
guess_ages
>>>
array([[ 0., 0., 0.],
[ 0., 0., 0.]])
性別と乗船クラスを繰り返し演算し、6つの組み合わせの年齢の推測値を計算する。
for dataset in combine:
for i in range(0,2):
for j in range(0,3):
guess_df = dataset[(dataset['Sex'] == i) %
(dataset['Pclass] == j+1)['Age'].dronpa()
age_guess = guess_df.median()
guess_ages[i,j] = int(age_guess/0.5+0.5)*0.5
for i in range(0,2):
for j in range(0,3):
dataset.loc[(dataset.Age.isnull()) & (dataset.Sex == i) &
(datset.Pclass == j+1), 'Age'] = guess_ages[i,j]
dataset['Age'] = datset['Age'].astype(int)
train_df.head()
>>>
Survived Pclass Sex Age SibSp Parch Fare Embarked Title
0 0 3 0 22 1 0 7.2500 S 1
1 1 1 1 38 1 0 71.2833 C 3
2 1 3 1 26 0 0 7.9250 S 2
3 1 1 1 35 1 0 53.1000 S 3
4 0 3 0 35 0 0 8.0500 S 1
次に年齢帯についての特徴を作り出し、生存率との関連性を決定しよう。
train_df['AgeBand'] = pd.cut(train_df['Age'], 5)
train_df[['AgeBand', 'Survived']].groupby(['AgeBand'],
as_index=False).mean().sort_values(by='AgeBand', ascending=True)
>>>
AgeBand Survived
0 (-0.08, 16.0] 0.550000
1 (16.0, 32.0] 0.337374
2 (32.0, 48.0] 0.412037
3 (48.0, 64.0] 0.434783
4 (64.0, 80.0]
ここまで来たら、年齢をこれらの値に基づいて順序付けしていく。
for dataset in combine:
dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0
dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32), 'Age'] = 1
dataset.loc[(dataset['Age'] > 32) & (dataset['Age'] <= 48), 'Age'] = 2
dataset.loc[(dataset['Age'] > 48) & (dataset['Age'] <= 64), 'Age'] = 3
dataset.loc[ dataset['Age'] > 64, 'Age']
train_df.head()
>>>
Survived Pclass Sex Age SibSp Parch Fare Embarked Title AgeBand
0 0 3 0 1 1 0 7.2500 S 1 (16.0, 32.0]
1 1 1 1 2 1 0 71.2833 C 3 (32.0, 48.0]
2 1 3 1 1 0 0 7.9250 S 2 (16.0, 32.0]
3 1 1 1 2 1 0 53.1000 S 3 (32.0, 48.0]
4 0 3 0 2 0 0 8.0500 S 1 (32.0, 48.0]
年齢帯の特徴は取り除かなければいけない。
train_df = train_df.drop(['AgeBand'], axis=1)
combine = [train_df, test_df]
train_df.head()
>>>
Survived Pclass Sex Age SibSp Parch Fare Embarked Title
0 0 3 0 1 1 0 7.2500 S 1
1 1 1 1 2 1 0 71.2833 C 3
2 1 3 1 1 0 0 7.9250 S 2
3 1 1 1 2 1 0 53.1000 S 3
4 0 3 0 2 0 0 8.0500 S 1
既存の特徴を組み合わせて特徴を作り出す
Parch特徴とSibSp特徴を組み合わせて、新たにFamilySizeという特徴を作り出すことができる。これによりデータセットから上記2項目を削除することができるようになる。
for dataset in combine:
dataset['FamilySize'] = dataset['SibSp'] + dataset['Parch'] + 1
train_df[['FamilySize', 'Survived']].groupby(['FamilySize'], as_index=False).mean().sort_values(by='Survived', ascending=False)
>>>
FamilySize Survived
3 4 0.724138
2 3 0.578431
1 2 0.552795
6 7 0.333333
0 1 0.303538
4 5 0.200000
5 6 0.136364
7 8 0.000000
8 11 0.000000
また私たちは、isAlone(独身者)という項目も作り出すことができる。
for dataset in combine:
dataset['isAlone'] = 0
dataset.loc[dataset['FamilySize'] == 1, 'isAlone'] = 1
train_df[['isALone'], 'Survived']].groupby(['isAlone'], as_index=False).mean()
>>>
IsAlone Survived
0 0 0.505650
1 1 0.303538
ではここまできたら、ParchとSibSpの特徴を削除するとともに、FamilySizeの特徴の座もisAloneに譲り削除しましょう。
train_df = train_df.drop(['Parch', 'SibSp', 'FamilySize'], axis=1)
test_df = test_df.drop(['Parch', 'SibSp', 'FamilySize'], axis=1)
combine = [train_df, test_df]
train_df.head()
>>>
Survived Pclass Sex Age Fare Embarked Title IsAlone
0 0 3 0 1 7.2500 S 1 0
1 1 1 1 2 71.2833 C 3 0
2 1 3 1 1 7.9250 S 2 1
3 1 1 1 2 53.1000 S 3 0
4 0 3 0 2 8.0500 S 1
1
またここで、PclassとAgeを組み合わせて特徴を作り出すこともできます。
for dataset in combine:
dataset['Age*Class'] = dataset.Age * dataset.Pclass
train_df.loc[:, ['Age*Class', 'Age', 'Pclass']].head(10)
>>>
Age*Class Age Pclass
0 3 1 3
1 2 2 1
2 3 1 3
3 2 2 1
4 6 2 3
5 3 1 3
6 3 3 1
7 0 0 3
8 3 1 3
9 0 0 2
カテゴリ特徴の補完
Embarkedは乗船地に基づいて、S/Q/Cいずれかの値を持っている。私たちの訓練用データからは2つの値が失われている。簡単にこれを満たすには、最も多い出現頻度を用いるのがよいだろう。
freq_port = train_df.Embarked.dronpa().mode()[0]
freq_port
>>>
'S'
for dataset in combine:
dataset['Embarked'] = dataset['Embarked'].fillna(freq_port)
train_df[['Embarked', 'Survived']].groupby(['Embarked'], as_index=False).mean().sort_values(by='Survived', ascending=False)
>>>
Embarked Survived
0 C 0.553571
1 Q 0.389610
2 S 0.339009
カテゴリ特徴の数値変換
いま欠損のなくなったEmbarked特徴は、Portという新しい数値特徴に変換することができる。
for dataset in combine:
dataset['Embarked'] = dataset['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int)
train_df.head()
>>>
Survived Pclass Sex Age Fare Embarked Title IsAlone Age*Class
0 0 3 0 1 7.2500 0 1 0 3
1 1 1 1 2 71.2833 1 3 0 2
2 1 3 1 1 7.9250 0 2 1 3
3 1 1 1 2 53.1000 0 3 0 2
4 0 3 0 2 8.0500 0 1 1 6
数値の迅速な補完及び変換
料金特徴の中で最も多く出現する値を取得するためにモードを使うことにより、本番用データの中の料金特徴の一つの欠損を補完することができる。これは一行のコードで行うことができる。
ここでは、一つの欠損を置き換えるために中間となる新しい特徴を作ったり欠損を推測するために深い分析をおこなったりしないことに注意する。このコンペの目標に望まれているのは、モデルのアルゴリズムが欠損のない状態で機能させるということだ。
test_df['Fare'].fillna(test_df['Fare'].dropna().median(), inplace=True)
test_df.head()
>>>
PassengerId Pclass Sex Age Fare Embarked Title IsAlone Age*Class
0 892 3 0 2 7.8292 2 1 1 6
1 893 3 1 2 7.0000 0 3 0 6
2 894 2 0 3 9.6875 2 1 1 6
3 895 3 0 1 8.6625 0 1 1 3
4 896 3 1 1 12.2875 0 3 0 3
料金帯を作る。
train_df['FareBand'] = pd.qcut(train_df['Fare'], 4)
train_df[['FareBand', 'Survived']].groupby(['FareBand'], as_index=False).mean().sort_values(by='FareBand', ascending=True)
>>>
FareBand Survived
0 (-0.001, 7.91] 0.197309
1 (7.91, 14.454] 0.303571
2 (14.454, 31.0] 0.454955
3 (31.0, 512.329] 0.581081
料金特徴を、料金帯に基づいて順序的な特徴に変換する。
for dataset in combine:
dataset.loc[ dataset['Fare'] <= 7.91, 'Fare'] = 0
dataset.loc[(dataset['Fare'] > 7.91) & (dataset['Fare'] <= 14.454), 'Fare'] = 1
dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 31), 'Fare'] = 2
dataset.loc[ dataset['Fare'] > 31, 'Fare'] = 3
dataset['Fare'] = dataset['Fare'].astype(int)
train_df = train_df.drop(['FareBand'], axis=1)
combine = [train_df, test_df]
train_df.head(10)
>>>
Survived Pclass Sex Age Fare Embarked Title IsAlone Age*Class
0 0 3 0 1 0 0 1 0 3
1 1 1 1 2 3 1 3 0 2
2 1 3 1 1 1 0 2 1 3
3 1 1 1 2 3 0 3 0 2
4 0 3 0 2 1 0 1 1 6
5 0 3 0 1 1 2 1 1 3
6 0 1 0 3 3 0 1 1 3
7 0 3 0 0 2 0 4 0 0
8 1 3 1 1 1 0 3 0 3
9 1 2 1 0 2 1 3 0 0
---------原文ここまで----------
ここまでのまとめ(翻訳者による)
訓練用データに存在していた特徴についての処理まとめ
|特徴名|意味|処理の結果|
|----|----|----|----|----|
|PassengerID|乗客ID|訓練用データからは削除
|Survived|生存|特に処理はなし
|Pclass|乗船クラス|特に処理はなし
|Name|名前|敬称で分けられ、その所属による数値に変換|
|Sex|性別|文字列から数値に変換
|Age|年齢|年齢帯に分けられ、その所属による数値に変換
|SibSip|兄弟姉妹、配偶者|FamilySizeという特徴に統合され、この特徴は削除された
|Parch|親、子供|FamilySizeという特徴に統合され、この特徴は削除された
|Ticket|チケット|削除された
|Fare|料金|料金帯に分けられ、その所属による数値に変換
|Cabin|客室|削除された
|Embarked|乗船地|乗船地が数値に変換され、その所属による数値に変換
最終的に残った特徴についてのまとめ
|特徴名|意味|説明|
|----|----|----|----|----|
|Survived|生存|生存の成否についての情報。特に処理はされていない
|Pclass|乗船クラス|乗船した階級についての情報。特に処理はされていない
|Sex|性別|乗客の性別についての情報。元々文字列で表されていたが、数値に変換されている
|Age|年齢|乗客の年齢帯についての情報。元々年齢そのものを表していたが、年齢帯に分けられている
|Fare|料金|乗客が支払った料金帯についての情報。元々料金そのものを表していたが、料金帯に分けられている
|Embarked|乗船地|乗船地についての情報。元々文字列で表されていたが、数値に変換されている
|Title|敬称|乗客の名前についている敬称についての情報。名前項目から抽出して作成され、数値に変換されている
|isAlone|家族構成|乗客の家族構成についての情報。親、子供、兄弟姉妹、配偶者などの情報が統合され作り出された
|Age*Class|年齢と乗船クラスの乗算結果|年齢と乗船クラスを乗算したもの
原文