初めに
この記事はKaggleのデータ「Bag of Words Meets Bags of Popcorn」のデータでbag of wordsを作り、Random Forestで予測するまでを説明する初心者向けの記事です。
英語記事でいいものを見つけたので、英語が苦手な方向けに和訳+初心者向けに補足したものになっております。
また、投稿自体が初めてのなのでアドバイスをいただければ幸いです。
Kaggleのデータからbag of wordsを作ってみた(2/3)
Kaggleのデータからbag of wordsを作ってみた(3/3)
環境
- Python 3.6.0 :: Anaconda custom (x86_64)
- Mac OS X 10.12.5
データの読み込み
import pandas as pd
train = pd.read_csv("labeledTrainData.tsv", header=0, \
delimiter="\t", quoting=3)
これで、"labeledTrainData.tsv"がtrainに読み込まれます。
細かい補足
- header=0, 最初の一列目は各行の名前であることを示している。
- delimiter="\t", データはタブによって別れていることを示す。
- quoting=3, Python用のエラー防止
train.shape #学習データのデータ数と次元数の確認
(25000, 3)
これでこのデータはデータ数25000,次元数3であることがわかります。
以下のようにtrainと打ち込むだけでも見ることもできます。
train
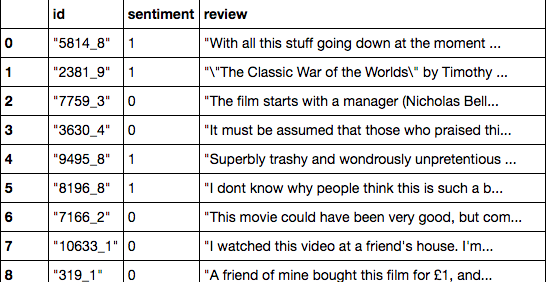
データのクリーニング
まずは一番最初の人のレビューを見てみます。
print (train["review"][0])

実はこのデータは汚い状態(扱いにくい)にあります。
これから、このデータを綺麗にしていきます。具体的には以下のことをします。
- タブの消去
- 文字以外(?,.,')の処理
- 大文字、小文字の処理
BeautifulSoupを使ったタブの消去

ちゃんとタブが消えているのが確認できます。
reを使った文字以外の処理
ここからは、(?,.,/,#,",')のような文字以外のものを処理していきます。
import re
letters_only = re.sub("[^a-zA-Z]", #この条件に合致するものを
" ", #これ(今回は空白)に置換する
example1.get_text() ) #対象とするテキストデータ
print(letters_only)
ちょっと見えにくいですが、「.」や「"」が消えているのが確認できます。

大文字、小文字の処理
最後に全ての文字を小文字にします。このままだた、Withとwithが別の文字として処理されてしまうためです。
lower_case = letters_only.lower() #全て小文字に変換する
print(lower_case)

ちゃんと小文字になっていますね。
今回はこれで終わりです。
次回から本格的にbag of wordsを作っていきます。