これは m3の M3 TechTalk #80の発表資料です。
Kibanaの基本的な使い方について説明しました。
はじめに
kibanaとは
kibanaは elasticsearch(データベース)に対するフロントエンドでデータのビジュアライズを行う
基本的には時系列データを扱うことを主目的にしている
幾つかの形式のグラフ描画をサポートしていてGUIで設定するだけでグラフを作成できる
深いことをしようとするとelasticsearchの使い方を勉強していくことになる
名称説明
- インデックス
- RDBでいうところのテーブルと同じイメージ。
key-valueの形式でレコードを保持 - フィールド
- keyのこと。フィールドに応じて型を定義し、それに応じて条件や集計の方法が決まる
- Discover
- レコード1件づつの詳細をみることができるモード
- Visualize
- 検索結果をいろいろなグラフで表示するモード
- Dashboard
- Discover, Visualizeで作成したパーツを並べて表示するダッシュボード
使い方
使い方: Discover
実際のレコードの内容を参照するモード
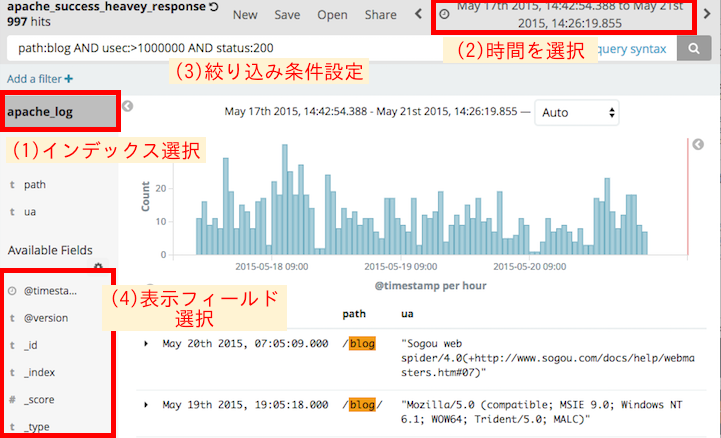
- Discover を開いて、左上のところで インデックスを選択する
- 右上のとこでデータを取得する時間の範囲を指定する
- 余り長くしすぎると検索対象のデータが多くなって検索が重くなるので注意
- 上部にある検索窓で絞り込み条件を記入する
- この条件は、elasticsearchがもつ Query Stringという条件式の記述方法で表記する
- 左側の"Available Fields"の一覧から、表示させたいフィールドを[add]で追加
- フィールド名の「▲」「▼」でソート
- [Save]で名前をつけて 条件式や表示するフィールドなどの設定を保存する
- 時間の範囲は保存されない
- [Share]で今見ている条件設定を再現できるURLを取得する
- 短縮URLを生成する機能があるので短縮してから共有すると良い
使い方: Visualize
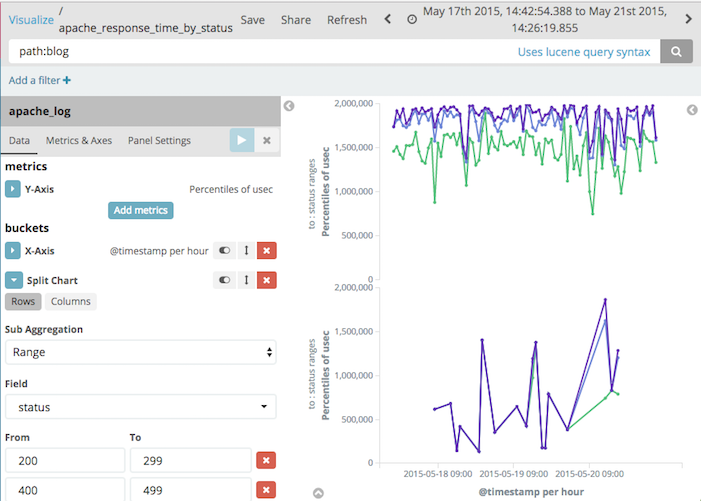
- 作成するグラフの種類を選択(あとからは変えられない)
- Line: 線グラフ。時系列の値の変化をみるならとりあえずこれを選ぶ
- Data Table: 時系列に関係なく、データを集計した値を算出したいときはこれを選ぶ
- ここでは"Line"を選択
- グラフ化するインデックスを選択する(あとからは変えられない)
- [X-Axis]で"Data Histogram"を選択して、[Apply Changes]ボタンをクリックする
- 時系列での一定時間単位のレコード件数の棒グラフになる
- [Interval]で集計間隔を変えられる
- [Y-Axis]で"Percentiles"を選択、 [Field]で"usec"を選択、
[Percents]から必要な軸だけを残す - [X-Axis]で[Add sub-buckets]-[Split Series]を選択、
軸を分割する条件を設定 - [X-Axis]で[Add sub-buckets]-[Split Chars]を選択、
グラフを分割する条件を設定 - [Save]でグラフを名前をつけて保存する
使い方: Dashboard
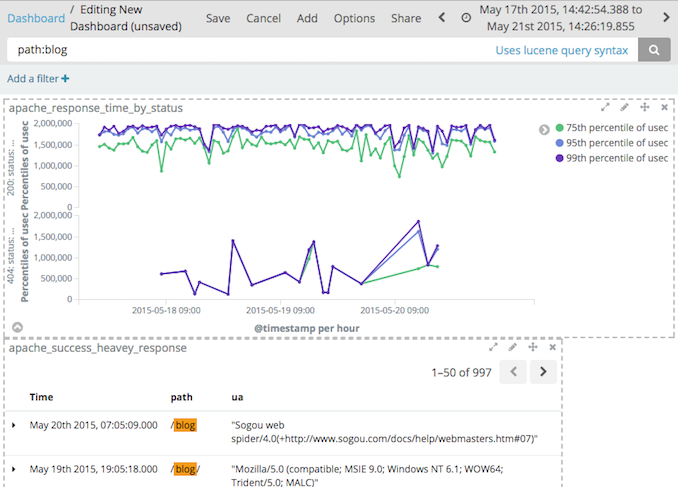
- [Add]で、先に作成したVisualizeか Discover(表記上は"Search")を選択
- 表示されたパーツの配置を変える
- 検索窓、Filterで絞り込み条件を指定
- 各Search、Visualizeの中で指定されている条件に加えてさらに絞り込まれる
- Search、Visualizeが使っているインデックスによっては
条件中のフィールドが存在しないこともある
- [Save]でDashboardを名前をつけて保存する
- [Store time with dashboard]をチェックすると時間設定も保存される
検索条件式
公式説明リンク
- https://www.elastic.co/guide/en/kibana/current/kuery-query.html
- https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-query-string-query.html#query-string-syntax
完全一致
- {key名}:{値}, {key名}:"{値}"
- ダブルクオートで値を囲ってもいい
- title:(quick OR brown)
- 値がどちらでもいい場合
部分一致
- title:"qu?ck bro*"
- ?は1文字、*は任意文字数に一致
正規表現
- title:/qu.ck bro.*/
- path:/\/api\/accounts.*/
- "/"はエスケープしなければならない
- 値の先頭から終端までの全体一致なので注意
範囲
数値型のフィールドに使える。
- status:[200 TO 299]
- 下限(200)、上限(299)の値を含む
- status:{199 TO 300}
- 下限(199)、上限(300)の値を含まない
- status:[200 TO 300}
- 片方だけ使うこともできる
- status:[200 TO *]
- 片方だけの条件にしたいときは*を指定する
- status:>=200, status:<300
- 不等号でも記述できる
否定
- NOT {key名}:{値}
- !{key名}:{値}
結合
- {key名}:{値} AND ({key名}:{値} OR {key名}:{値})
- AND,ORは大文字でなければ機能しないので注意
Filter条件
Filterは、条件式とともに検索結果を絞りこむ条件となる
- 1つの条件ごとにON/OFFできる
- 条件の反転をすることができる
- query string以外の elasticsearchで使える詳細な条件を記載できる
ので、基礎となる条件を設定しておく使い方によい
DiscoverやVisualize で「(+)」マークや「(-)」マークでフィルタを追加できる
(「(+)」マーク: マッチすること、「(-)」マーク: マッチしないこと)
データの読み方の注意
- Percentileは総数を意識して見ること
- 99%はOK, 1%はダメ → 総数 * 1% = 本来の影響件数は?
- HTTP Statusでの判定はアプリの特性に注意
- 302 Redirectは本当に問題ないステータスなのか?
- グラフのY軸の最大値を自動調整にするか、固定にするか
- 日々見るグラフを自動調整にするとぱっと見で変動がわかりにくいときがある
- 期待する範囲での最大値を固定しておいた方が変動に気づきやすい
さらにできること
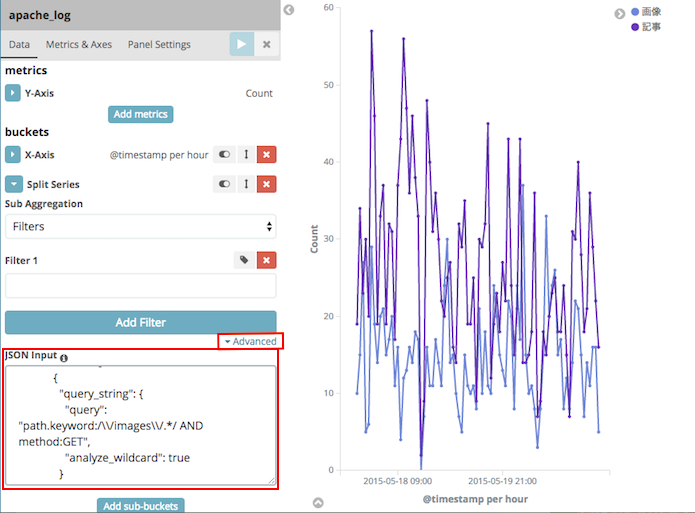
URLのグループごと折れ線グラフを作成する
Visualizeの条件は"Advanced"欄でelasticsearchのクエリを直接記述できる。
これを使って[X-Axis]の詳細な条件を一括で指定できる
- 以下のスクリプトでAPI定義を生成するSwaggerからクエリとなるJSONを生成
- [X-Axis]のaggregateを"Filters"にする
- [Advanced]-[JSON input]に先に作ったJSONを入力
注意
- JSONの条件式中の"Query String"の正規表現は大文字がマッチできないので"."(dot)にする必要がある
- kibanaが条件式を小文字化して使ってしまう様子
- 類似問題の
lowercase_expanded_termsの設定が効かない
- "Filters"の条件が最低1つは必要
スクリプトから検索する
kibanaは以下のことをやっている
- elasticsearchに対してJSON形式のクエリを投げる
- 検索、集計された結果(JSON)を使ってグラフを作図
curl などのhttpアクセスができれば検索のところはできる
kibanaが生成する検索条件を以下から取得して流用できる
- DiscoverやVisualizeの結果画面で下部の[△]ボタンをクリック
- 詳細情報が表示される
- [Request]のページを開き、そのページのJSONを取得する
rubyのelasticsearch-rubyとかを使うと便利
# 検索条件式のみで検索
curl -s -X GET 'http://localhost:9200/apache_log/_search?q=path:blog&pretty=true'
# 複雑なクエリで検索
curl -s -X POST 'http://localhost:9200/apache_log/_search?pretty=true' -d "$(cat <<EOS
{
"query": {
"bool": { "must": [
{
"query_string": { "query": "path:blog" }
},
{
"range": {
"@timestamp": {
"gte": 1431841374388, "lte": 1432185979855,
"format": "epoch_millis"
}
}
}
]}
},
"size": 500
}
EOS
)"
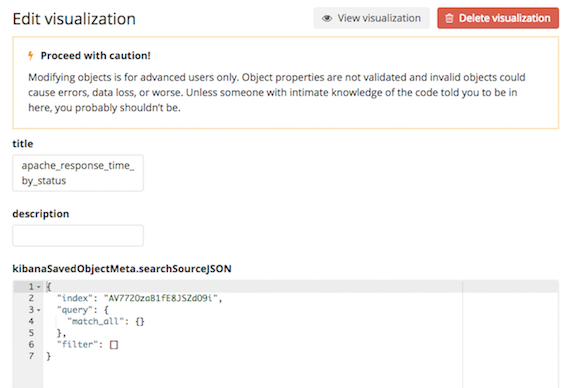
作成したグラフ設定を直接編集
作成したグラフ設定は、elasticsearch上に通常データと同じようにJSONで保存されている
そのJSONを直接編集すれば同じようなグラフを複製することができる(はず)
好きなデータをグラフ化
httpのPOSTやPUTメソッドを使えばelasticsearch上にデータを投入することができる
手持ちのCSVやログファイルを logstashなどのツールで一括で投入することもできる
(参考: インデックスの操作説明)
- 定期監視の結果を投入してkibanaダッシュボードで参照する
- 定期的なレポートの結果を逐次投入してグラフ化
- 分析用のデータを生成して一括投入しておき、グラフ化や詳細分析はビジネスチームに任せる
といった使い方もできる
kibana 5系の機能
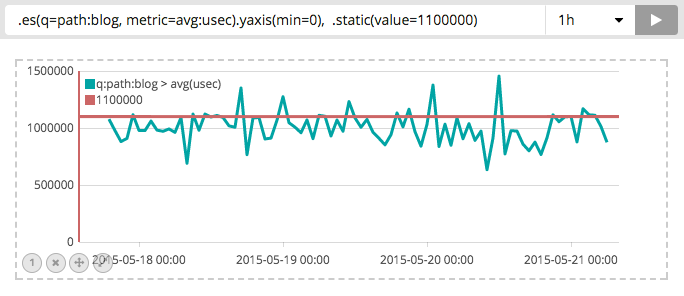
Timelion (タイムライン)
Kibana 5系から Timelionという機能がある
https://www.elastic.co/jp/blog/timelion-timeline
グラフの作図設定をメソッドチェーン的なクエリ式で表す
まだ、percentileを使えなかったりとまだ発展途上な感じ
まとめ
kibanaは検索が速く、グラフ化も慣れれば簡単にできる
- Apacheログをgrepで調べるよりは、かなりお手軽で速い
- 障害発生時の状況把握をすぐできる
- 毎日のシステムの状況監視もダッシュボードで一望できる