この記事はドワンゴ Advent Calendar 2020 最終日の記事です。年の瀬ですね。
はじめに
本記事は、WHATWG Living Standardに準拠することを目的としたHTMLパーサである「gammo」の紹介を目的としている。gammoが実現していることを詳細に伝えるため、単なるgemの紹介に留まらず、HTMLの歴史や昨今のHTMLを取り巻く状況を簡単に解説し、WHATWG Living StandardにおけるHTML文書の解析アルゴリズムについて、実例と共に紹介する。
本記事で紹介するgammoの開発に取り掛かった理由は、主に以下の二点が挙げられる。
- WHATWG Living Standardに準拠したHTMLパーサをRubyGemsの中から見つけられなかったため。
- 現在HTMLパーサの機能を持つライブラリの中で、最も利用されていると考えられるNokogiriと比較して、より簡単にインストール可能なHTMLパーサを求めたため。
なお、WHATWG Living Standardは常にアップデートされ続けているため、現在の仕様とgammoの実装、およびこの記事の解説内容が、最新のWHATWG Living Standardと乖離している可能性がある点に注意されたい。
TL;DR
- 2020年12月現在、HTMLやDOMの標準仕様は、WHATWGによって定義される。
- 2019年5月以前から、ChromiumやGecko・Webkitといったブラウザは、WHATWG Living Standardにおける標準仕様を尊重していた。
- 2019年5月に、W3CとWHATWGによるHTML・DOMの標準仕様に対する二重管理が是正され、WHATWG Living Standardに一本化された。
- HTML文書の解析には大きく分けて、Tokenization(字句解析)とTree Construction(構文解析・DOMツリーの構築)という二つのステージが存在する。
- Tokenizationはステートマシンによって表現でき、入力として受け取るHTML文書をHTMLのトークンに分割する。
- Tree Constructionも同様にステートマシンによって表現でき、その状態を「Insertion Mode(挿入モード)」と呼ぶ。このアルゴリズムの中では、挿入モードの中に定められた処理の仕様や、Adoption Agency Algorithm(養子縁組アルゴリズム)などの特徴的なアルゴリズムが存在し、それらがHTML文書のエラーを許容したり、補完することによって、適切なDOMツリーを構築しようとする。
- WHATWG Living Standardに基本的に準拠したHTMLパーサである「gammo」をリリースした。
- C/C++によるNative Extensionを含まないPure Rubyな実装となっている。
- Pure Rubyであること・標準仕様に準拠することの二つを重視しており、パフォーマンスは重視していない。
- XPath 1.0によるTraverse機能が実装されているため、gammoによって構築したDOMツリーに対し、XPathによる要素・属性等の抽出が可能となっている。
- 詳細は「RubyでXPath 1.0 パーサを実装した
」を参照されたい。
- 詳細は「RubyでXPath 1.0 パーサを実装した
HTMLの標準仕様
本題に入る前に、まずはHTMLの歴史や昨今のHTMLを取り巻く状況について簡単に解説する。
HTMLの歴史
HTMLの歴史は古く、1989年から1990年にかけて、Tim Berners-LeeによってHTMLの原型とされる仕様文書と実装が公開されたことに始まる。この段階では、ウェブの根幹をなす文書を構造化する技術仕様というよりも、研究機関の中で文書やデータを共有するための一ソリューションという位置付けとなっている。
そこから幾年かの時を経て、1993年、正式なHTML仕様とされるHTML 1.0が策定された。そして実際に多くの人がHTMLというものに触れる機会を多くしたのは、パーソナルコンピュータが急速に普及した1990年代中盤から後半にかけて、HTML仕様が2.0から4.0にかけての変遷が見られた頃であろうか。
日本では、ここからさらに2000年代初頭にかけて多く存在したHTMLタグ辞典のようなウェブサイトや、ホームページビルダーのようなソフトウェアによって、HTML仕様に準拠しない文書が量産されたり、視覚的作用を期待した物理要素(e.g. font要素・center要素)が使用されるケースが散見された。その一方で、現在もなおHTML仕様に準拠しない文書については、可能な限り解析アルゴリズムの中でそれを許容するように工夫がなされている。視覚的作用しかもたらさない物理要素についても同様に、その大半が既にHTML5の仕様からは削除されているものの、未だWHATWG Living Standardにおいては解析アルゴリズムの中で、その取り扱い方が定義されている。
言い換えれば、HTMLの標準仕様から削除されたはずの物理要素や不正な文書を解析するためのサポートは、未だにHTML文書の解析アルゴリズムの中に残り続けているということになる。しかし、これは合理性を欠くものではなく、過去(あるいは新規)に作成された標準仕様に準拠しないHTMLによって表現されるウェブサイトを誰もが、可能な限り、違和感なく閲覧できるようにするために必要なものであると言える。
一方、実に興味深い事実として、最初期に定義されたほとんどの要素は、HTML5が世に出て久しい2020年にあっても、微妙に定義を変えて残り続けていることが挙げられる。途中、HTML4.01 StrictやHTML5にアップデートされる際、前述の通り多くの物理要素が非推奨・廃止とされるなどの変化はあったものの、それらを除く多くの要素が持つ有用性は、現在もこのウェブを支え続けることによって証明していると言えるだろう。
HTML文書の解析の難しさ
HTML文書を書く上での仕様の話だけでなく、何度も触れている「HTML文書を解析するためのアルゴリズム」についても掘り下げていこう。
HTML文書の解析アルゴリズムについては、2020年12月現在、詳細な仕様が定められているが(後述)、その仕様はBNFのような言語によって表現されているわけではない。
HTML文書の解析仕様が、BNFのような文脈自由法によって定義可能な場合、LR法などによって対象を解析することは容易である。しかしながら、HTML文書はその特性ゆえに、文脈自由法に基づくことによって容易にその仕様を定義することができない。次に示すHTML文書の解析における仕様が、その主な要因となる。
- 開始・終了タグの省略が可能
- 特定のタグが(暗黙的に追加されることを期待して)省略可能
- 歴史的な経緯によって、文法的に正しくないHTML文書のエラーを許容する必要性
このことから、通常の解析手法によってHTML文書の構文解析を行うことは難しい。また、HTMLにはDTDによる仕様の定義が存在するが、DTDは文脈自由法に基づかない。
これにより、ブラウザ開発者は、主にHTML文書を書く人に向けられた標準的な仕様やDTDを基にしつつも、エラーを許容するような寛大さを持つHTMLパーサを独自に開発するか、あるいは他のブラウザ開発者によって書かれた既存のHTMLパーサを流用するしかなかったと考えられる。
HTML文書のパーサの歴史
HTML5以前、HTML文書には正式な解析アルゴリズムについての仕様が存在しなかった。つまりブラウザは独自の実装によって、標準化された仕様を満たさなければならなかった。これに起因して多くの微妙な挙動の差が生じ、クロスブラウザ対応など、当時フロントエンドを生業としていたエンジニアは複数のブラウザでの動作確認に長い時間を割いていたはずだ。
長きにわたって、HTMLの解析アルゴリズムについての正解が曖昧で、ブラウザが独自に正式な仕様を満たすような実装をしなければならなかった時代が続いていたということである。
しかしHTML5からはこの問題の解消を目指し、HTML5の標準仕様と共に、HTML文書の解析アルゴリズムがW3C・WHATWG双方の団体から提供されるようになった。これにより、ブラウザにおけるHTML文書を解析するアルゴリズムが統一可能となり、HTML文書のエラーに対する振る舞いを含む基本的な挙動が、複数の主要なブラウザの間で統一されることが期待されている。
WHATWG Living Standard vs W3C HTML Specification
前述の通り、2008年に最初のHTML 5.0のドラフトバージョンがリリースされて以来、長らくWHATWGの仕様と、W3Cがそれを基に変更を加えたものの二種類が標準仕様として存在していた。
多くのブラウザはWHATWG Living Standardに準拠することを目指した一方で、多くのウェブサイトのマークアップを担うエンジニア・コーダーは、そのどちらに準拠したら良いのかがわからないという状況が続いていた。
しかし2019年5月、その状況が一変し、WHATWG Living Standardの仕様をHTMLおよびDOMの唯一の標準仕様とすることで、W3CとWHATWGが合意した。この経緯の詳細はHTML標準仕様の策定についてW3CとWHATWGが合意発表。今後はWHATWGのリビングスタンダードが唯一のHTML標準仕様にを参照されたい。
前述の解析アルゴリズムについても同様に、WHATWG Living Standardの定義するものに一本化されている。
HTML文書の解析の仕組み
HTML文書の解析には標準仕様が存在し、2020年12月現在、WHATWG Living Standardに定められるものが唯一の仕様であると解説した。ここからはその解析アルゴリズムの内容を紹介するとともに、その中からいくつかの特徴的な機能を紹介し、gammoのコードを用いながら解説する。
解析モデルの概要
まず、HTML文書の解析アルゴリズムの流れについて端的に表した図を、Parsing HTML documentsから引用する。
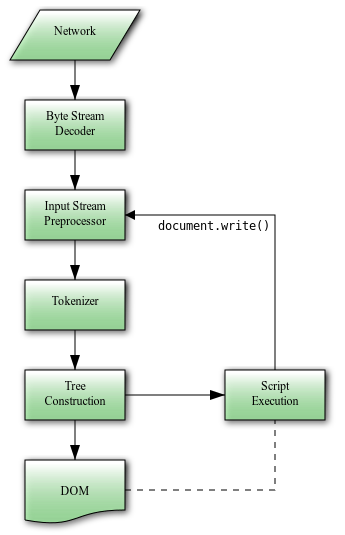
図にある通り、HTMLの解析アルゴリズムでは、入力を受け取り、それをHTMLトークン※1に変換している。これをTokenizationと呼ぶ。
Tokenizationによって生成されたトークンは、一つずつTree Constructorに受け渡され、Tree Constructorがそれらを処理することによって、DOMツリーを構築していく。これをTree Constructionと呼ぶ。
この図では7個のフェーズに分かれているが、HTMLパーサが主に実装しなければならないのは「Tokenization」と「Tree Construction」の二つである。次の節からは、この二つのアルゴリズムについて解説していく。
なおブラウザでは、Tree Construction中に発生し得るJavaScriptコードの実行時に、document.write APIなどによってinput streamが書き換えられる可能性を考慮する必要があるが、今回実装したHTMLパーサであるgammoはJavaScriptの実行処理を担わないため、省略している。
※1 自動終了タグ (e.g. <img>)、 開始タグ (e.g. <a>)、 終了タグ (e.g. </a>)、 コメント (e.g. <!-- comment -->)、 文字 (e.g. hello)、そして DOCTYPE (e.g. <!DOCTYPE html>) が存在する。
Tokenization
HTMLパーサにおけるTokenizationはステートマシンによって表される。このステートマシンにおける状態は一文字もしくは複数の文字を消費(consume)し、その消費された文字によって次の状態を決定する。このステートマシンの仕様については13.2.5 Tokenizationにまとめられている。
イメージを掴みやすくするために、次に示すシンプル且つ正しいHTML文書※2を入力としてTokenizerに渡し、どのようなトークンが生成されるのかを確認する。
<!doctype html><title>hello</title>
Tokenizerには、本記事で紹介するgammoのTokenizerを使用する。実際に、字句解析したHTMLトークンを順番に出力するサンプルコードを次に示す。
require 'gammo/tokenizer'
tokenizer = Gammo::Tokenizer.new('<!doctype html><title>hello</title>')
next_token = nil
puts (next_token = tokenizer.next_token) until next_token === Gammo::Tokenizer::EOS
ここから得られる結果は次の通りである。
<Gammo::Tokenizer::DoctypeToken data="html">
<Gammo::Tokenizer::StartTagToken tag="title" data="title">
<Gammo::Tokenizer::CharacterToken data="hello">
<Gammo::Tokenizer::EndTagToken tag="title" data="title">
<Gammo::Tokenizer::ErrorToken data="end of string">
このようにTokenizerは入力の最後(EOS)に到達するまで、受け取った入力をトークンに分割し、分割されたトークンは次に説明するTree Constructionによって処理される。
※2 html要素・head要素・body要素、いずれもが特定の条件下では省略可能。
Tree Construction
Tree Constructionとは、Tokenizationによって作られたHTMLトークンを順番に処理し、DOMツリーを構築するためのアルゴリズムである。実際の処理の流れに進む前に、HTML文書解析における固有の変数について、本記事の中で触れるものを簡単に解説する。
| 用語名 | 定義 |
|---|---|
| The insertion mode (挿入モード) | Tree Constructionにおける主要な動作を制御する状態変数。(e.g. "in body" 挿入モード) |
| The stack of open elements | 要素の開始タグの検出によって「開いている」要素を管理するためのスタック。終了タグが見つかるか、パーサによって暗黙的に閉じられる時に、その要素はスタックから削除される。 |
| The list of active formatting elements | 誤ってネストされたFormatting elementを処理するために用いるリスト。主に後述のAdoption Agency Algorithmの中で参照される。 |
| Other parsing state flags |
frameset-okやscriptingなど、パーサの状態を管理するフラグ。例えばscriptingフラグは、JavaScriptが有効な環境下でHTML文書を解析する際にtrueとなる。 |
| The original insertion mode | text 挿入モードなど、テキストの解析を開始する前の時点での挿入モードを記録しておくための変数。通常、テキストの解析終了後にはoriginal insertion modeにセットされた挿入モードにリセットされる。 |
解析アルゴリズムの流れ
その仕様が膨大であることから詳細な説明は省き、ここではどのようにして、Tree ConstructionがHTMLトークンを処理するのかを解説する。Tree Constructionの詳細な仕様については13.2.6 Tree constructionにまとめられている。
はじめに、Tree ConstructionはDocumentオブジェクトと呼ばれるrootとなるオブジェクトを生成する。
そして、Tokenizationによって得られたトークンを一つずつ、Tree Constructionの中で処理していく過程で、Documentオブジェクトに対し、新しいノードを追加・削除・更新していくことによって、DOMツリーを構築する。
ここでは、Tokenizationの解説の際に用いたシンプルで正しいHTML文書のサンプル(<!doctype html><title>hello</title>)とgammoを用いて、実際にDOMツリーを構築し、それを可視化する。次に示すものは、その一連の処理をgammoによって実装したコードである。
require 'gammo'
def dump_for(node, result = [], level = 0)
result << ' ' * 2 * level
case node
when Gammo::Node::Element
result << '<%s>' % node.tag
when Gammo::Node::Text
result << '%s' % node.data
when Gammo::Node::Doctype
result << '<!DOCTYPE html>'
end
isdoc = node.is_a?(Gammo::Node::Document)
result << ?\n unless isdoc
child = node.first_child
while child
dump_for(child, result, isdoc ? level : level.next)
child = child.next_sibling
end
result.join
end
puts dump_for(Gammo.new('<!doctype html><title>hello</title>').parse)
この処理を実行すると、次の結果が得られる。
<!DOCTYPE html>
<html>
<head>
<title>
hello
<body>
これは生成したDOMツリーを見やすくするために整形したもので、gammoの中では各ノードが独自のオブジェクトによって表されている。
このDOMツリーを構築するために、どのような処理が行われたのかを順番に見ていこう。内部的に処理されるHTMLトークンは次に示す通り、Tokenization で生成したものと同一となる。
<Gammo::Tokenizer::DoctypeToken data="html">
<Gammo::Tokenizer::StartTagToken tag="title" data="title">
<Gammo::Tokenizer::CharacterToken data="hello">
<Gammo::Tokenizer::EndTagToken tag="title" data="title">
<Gammo::Tokenizer::ErrorToken data="end of string">
- 全ての解析は
initial挿入モードという状態から開始され、Tokenizationによって生成されたトークンを原則的には順番に処理する。なお、rootとなるDocumentノードはパーサ作成時に作成される。 -
initial挿入モードがDoctypeトークンを受け取って処理を開始する。- Doctypeトークンを解析し、
Documentノードの子要素としてdoctypeノードを追加する。 - 挿入モードを
before htmlに変更する。 - 次のトークンへ。
- Doctypeトークンを解析し、
-
before html挿入モードが<title>開始タグトークンを受け取る。-
html要素ノードを作成し、Documentノードの子要素として追加する※3。 - 追加した
html要素ノードをstack of open elementsに追加する。 - 挿入モードを
before headに変更する。
-
-
before head挿入モードが<title>開始タグトークンを受け取る。-
head要素ノードを作成し、3.1で作成したhtml要素ノードの子要素として追加する。 - 追加した
head要素ノードをstack of open elementsに追加する。 - 挿入モードを
in headに変更する。
-
-
in head挿入モードが<title>開始タグトークンを受け取る。-
title要素ノードを作成し、4.1で作成したhead要素ノードの子要素として追加する。 - 追加した
title要素ノードをstack of open elementsに追加する。 - パーサの
original insertion modeに現在の挿入モードin headをセットする。 - 挿入モードを
textに変更する。 - 次のトークンへ。
-
-
text挿入モードがhelloという文字トークンを受け取る。-
helloというコンテンツを持つテキストノードを作成し、5.1で作成したtitle要素ノードに追加する。 - 次のトークンへ。
-
-
text挿入モードが</title>終了タグトークンを受け取る。-
stack of open elementsから先頭のノードを削除する(言い換えれば<title>を閉じる)。 - 挿入モードを
original insertion modeに変更する。 - 次のトークンへ
-
-
in head挿入モードがEOSトークンを受け取る。-
stack of open elementsから先頭のノードを削除する(言い換えれば<head>を閉じる)。 - パーサの挿入モードを
after headに変更する。
-
-
after head挿入モードがEOSトークンを受け取る。-
body要素ノードを作成し、html要素ノードの子要素として追加する。 - 挿入モードを
in bodyに変更する。
-
-
in body挿入モードがEOSトークンを受け取る。- 解析を終了する。
このように、doctypeとtitle要素のみからなるHTML文書であっても、上で説明した処理の流れを追うことになる。
実際の流れの中で、仕様上省略可能とされている要素が、各挿入モードの中で適切に補完されていることも読み取れるだろう。Tree Constructionの中では、例え入力が単純なHTML文書であっても、これだけの数のステップを踏む必要があり、実際にウェブサイトにアクセスする際には、これよりも膨大な解析処理がブラウザの内部で行われているというイメージが伝われば幸いである。
※3 「子要素として追加する」と記載しているものは、stack of open elementsで最上位に位置する要素ノードの子要素として追加されることを意味する。
養子縁組アルゴリズム (Adoption Agency Algorithm)
ここまではTree Construction全体の流れを実例と共に解説したが、ここからはTree Constructionにおけるいくつかの特徴的な機能について触れていく。
前述の通り、この世には文法的に正しくないHTML文書が多く存在する。しかしその一方で、HTML文書のパーサの歴史でも触れたように、文法的に正しくないエラーを許容することによって、HTMLはここまでの地位を確立したといっても過言ではないだろう。実際、それらの問題をはらむウェブサイトを閲覧しようとする際に、ブラウザが常に解析エラーによって処理を諦めていては、ほとんどのウェブサイトを閲覧することができなくなってしまう。
Adoption Agency Algorithm は、そのような不適切なHTML文書に対処するためのアルゴリズムのうちの一つで、タグの入れ子関係が不適切なHTML文書を修正するためのアルゴリズムだ。要素の親を付け替えることによってその問題の解消を試みることに由来して、「養子縁組アルゴリズム(Adoption Agency Algorithm)」と呼ばれる。
アルゴリズムについてはWHATWG Living Standardに詳細な説明があるが、内容がやや複雑なため、ここではその詳細には触れず、このアルゴリズムがどのように作用するのかを簡単な例を交えて解説する。
まず入力として、次のような入れ子関係の不適切なHTML文書を想定する。
<p>1<b>2<i>3</b>4</i>5</p>
上記のHTML文書はどのようなDOMとして解釈されるべきだろうか。まず、html要素・head要素・body要素は自動的に補完されることが期待される。そして次に示すように、3のテキストノードまでは特に問題なく解釈できるはずだ。
<html>
<head>
<body>
<p>
1
<b>
2
<i>
3
Tree Constructionの解析アルゴリズムの流れで紹介した変数について、この時点でのAdoption Agency Algorithmが参照する値を確認しておこう。stack of open elementsは要素に(html, body, p, b, i)を持っており、list of active formatting elements は(b, i)の要素を持っている。挿入モードはin bodyである。
3の次のHTMLトークンである</b>(終了タグ)を受け取ると、パーサはAdoption Agency Algorithmを実行する。Adoption Agency Algorithmによって、list of active formatting elementsは直近の開始タグであるiのただ一つを持つことになり、stack of open elementsは要素に(html, body, p)を持つことになる。
次のHTMLトークンである 4を受け取ると、パーサはactive formatting elementsを再構築する※4。これにより、4というテキストノードを持つi要素が新規作成される。最後のHTMLトークンである5を受け取ると、5というテキストノードが直近の開始タグに挿入される。
その結果、DOMツリーは次のように構築されることが期待される。
<html>
<head>
<body>
<p>
1
<b>
2
<i>
3
<i>
4
5
gammoがこれを期待通りに処理できているかどうかは、次のようにして確認することができる。
require 'gammo'
def dump_for(node, result = [], level = 0)
result << ' ' * 2 * level
case node
when Gammo::Node::Element
result << '<%s>' % node.tag
when Gammo::Node::Text
result << '%s' % node.data
when Gammo::Node::Doctype
result << '<!DOCTYPE html>'
end
isdoc = node.is_a?(Gammo::Node::Document)
result << ?\n unless isdoc
child = node.first_child
while child
dump_for(child, result, isdoc ? level : level.next)
child = child.next_sibling
end
result.join
end
puts dump_for(Gammo.new('<p>1<b>2<i>3</b>4</i>5</p>').parse)
ここで触れたものは、Adoption Agency Algorithmの中でも非常にシンプルなケースである。その一方で、実際には他の様々な要因によって、より複雑な処理をAdoption Agency Algorithmが担うことになる。興味のある方はThe adoption agency algorithmを読んでみてほしい。
※4 i要素を一度クローズし、stack of open elementsによって管理されている中の最上位に位置するp要素(直近の閉じられていない開始タグ)を親とする新規のi要素を作成する。
HTML Fragment Parsing Algorithm
ここまでの内容は、完全なHTML文書を想定する解析アルゴリズムが入力を自動的に補完したり、エラーを修正することによってDOMツリーの構築を行うことを示すものであった。Living Standardの中にはそのようなケースだけでなく、DocumentFragmentを代表的な例として、完全なHTML文書ではない断片化されたHTML文書(Fragment)を解析するためのアルゴリズム仕様も存在する。これをHTML Fragment Parsing Algorithmと呼ぶ。ここではそのアルゴリズムを紹介する。
例えば、<p>hello</p>のようなHTML文書を考える。通常の解析アルゴリズムに則ってこの文字列を解析すると、次のようなDOMツリーが構築される。
<html>
<head>
<body>
<p>
hello
p要素の親要素が自動的に追加されている。これは入力を完全なHTML文書として解析しようと試みた結果である。
次にHTML Fragment Parsing Algorithmに則って同じ文字列を解析すると、次のように自動補完されることなくDOMツリーが構築される。
<p>
hello
gammoでは、FragmentParserとしてこの機能を実装している。実際にこの機能を試すには、次のコードを実行する。
require 'gammo'
def dump_for(node, result = [], level = 0)
result << ' ' * 2 * level
case node
when Gammo::Node::Element
result << '<%s>' % node.tag
when Gammo::Node::Text
result << '%s' % node.data
when Gammo::Node::Doctype
result << '<!DOCTYPE html>'
end
isdoc = node.is_a?(Gammo::Node::Document)
result << ?\n unless isdoc
child = node.first_child
while child
dump_for(child, result, isdoc ? level : level.next)
child = child.next_sibling
end
result.join
end
# FragmentParser#parseの戻り値は配列となる。
# これはHTML Fragment Parsing Algorithmの戻り値が0個以上のリストを返却するという仕様に準拠するためである。
# また、HTML Fragment Parsing Algorithmはcontext nodeを入力として受け取ることによって、
# パーサがどのようなコンテキストで入力された文書を解析するのかを決定する。詳細は以下の仕様を参照されたい。
# https://html.spec.whatwg.org/#parsing-html-fragments
puts dump_for(Gammo.new('<p>hello</p>', context: Gammo::Node::Element.new, fragment: true).parse.first)
実行結果は次の通りで、想定通りの挙動となっている。
<p>
hello
WHATWG Living Standardではこのようにして、通常のHTML文書の解析とは異なる断片化されたHTML文書を解析するアルゴリズムも定義されている。この機能は、例えばブラウザのDOM Inspector機能における局所的なHTML文書の書き換えなどに用いられる(と思う)。
gammoでの実装
この章の中で解説してきたHTML文書の解析アルゴリズムを、Rubyによって実装したのがGammo::TokenizerやGammo::Parser、そしてGammo::FragmentParserである。これらのクラスを用いることによって、gammoは文字列を入力として受け取り、DOMツリーを構築する。
しかしながら、単にDOMツリーを構築しただけでは、多くのユースケースでは不十分と言えるだろう。なぜならRubyという言語を想定すると、スクレイピングをはじめとして、構築されたDOMツリーから任意の要素や値を取得するようなケースが大半だと考えられるからだ。
gammoによって構築したDOMツリーに対し、XPath 1.0によって任意の要素・値を取得する方法については、RubyでXPath 1.0 パーサを実装したという記事にその内容を記したので、そちらも本記事と併せて読んでいただけると幸いである。
おわりに
本記事では、HTMLの歴史やその標準仕様、そしてその実装の中身、XPathについて触れてきた。WHATWG Living Standardに基づいて実装を進めていくというのは非常に大変ではあるが、ブラウザ開発の奥深さや難しさについて理解を深められたように思う。実際、gammoの開発では、多くの場面でWebkitやGecko・Chromiumの実装を参考にしている。
gammoがこの先、Ruby界隈におけるHTMLパーサとしての確固たる地位を獲得できるかは分からないが、それはともかくとしても、gammoの開発を通して多くのことを学ぶことができたという点で、この取り組みは非常に有意義であったと言えるだろう。
また筆者は元来、長期にわたって一歩ずつ趣味プロダクトの開発を進めていくのがあまり得意ではなかったが、gammoは一日三十分程度のコーディングを半年近く積み重ねていった先に出来上がったものであり、個人的にも感慨深いプロダクトである。これに倣い、今後も個人の興味の赴くまま、コードを書き続けていきたいと思う2020年の聖夜なのであった。
というわけで、メリークリスマス。良いおとしを。
おわり