サーバー上での作業などで,とりあえずcurlとかwgetでGoogle Drive上の一般公開されているデータをダウンロードしたいといったときの対処方法です.
ファイルサイズが小さい場合
ファイルを右クリック > 共有可能なリンクを取得 > FILE_ID("id="以降の文字列)を取得し,
wget "https://drive.google.com/uc?export=download&id=<FILE_ID>" -O <FILE_NAME>
の形式でダウンロードすることができます.
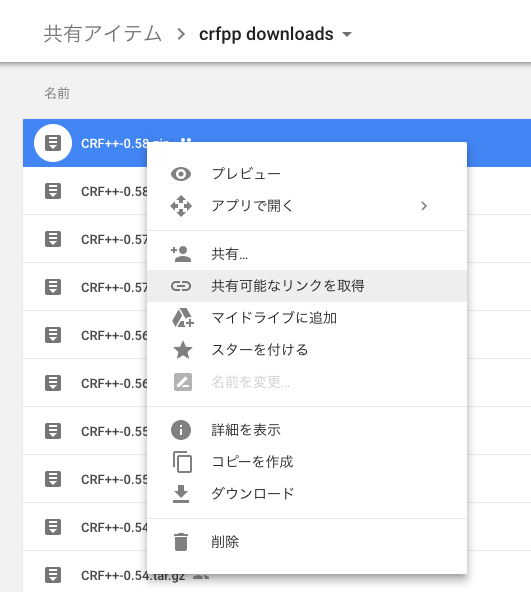
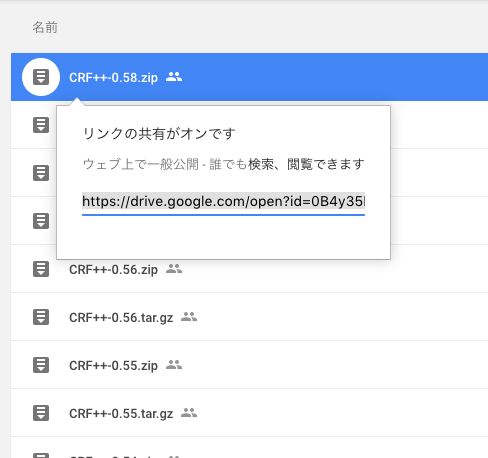
例: CRF++のダウンロード
Google Driveにアクセスしてみると
共有可能なリンクは
https://drive.google.com/open?id=0B4y35FiV1wh7QVR6VXJ5dWExSTQ
となっているので,
wget "https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7QVR6VXJ5dWExSTQ" -O CRF++-0.58.tar.gz
とすればダウンロードできます.
ファイルサイズが大きい場合
ファイルサイズの小さい場合と手順は同じですが,「ファイルのウイルス スキャンが実行できません」という確認ダイアログが出るため,もう一手間必要になります.

中身を調べてみるとconfirm=XXXXという四文字のランダムな文字列が追加で必要とわかるので,
curl -sc /tmp/cookie "https://drive.google.com/uc?export=download&id=<FILE_ID>" > /dev/null
CODE="$(awk '/_warning_/ {print $NF}' /tmp/cookie)"
curl -Lb /tmp/cookie "https://drive.google.com/uc?export=download&confirm=${CODE}&id=<FILE_ID>" -o <FILE_NAME>
として4文字のパスを引っこ抜く処理を追加すればダウンロードできます.
例: CaboChaのダウンロード
cabocha-0.69.tar.bz2をダウンロードする例です.
からFILE_ID="0B4y35FiV1wh7SDd1Q1dUQkZQaUU"を入手します.
FILE_ID=0B4y35FiV1wh7SDd1Q1dUQkZQaUU
FILE_NAME=cabocha-0.69.tar.bz2
curl -sc /tmp/cookie "https://drive.google.com/uc?export=download&id=${FILE_ID}" > /dev/null
CODE="$(awk '/_warning_/ {print $NF}' /tmp/cookie)"
curl -Lb /tmp/cookie "https://drive.google.com/uc?export=download&confirm=${CODE}&id=${FILE_ID}" -o ${FILE_NAME}