Colaboratoryから無料でTPUが使えるようになっていたので,Kera経由で試してみました.
公式のドキュメントは
になります. 手順としては,
- ハードウェアアクセラレータを「TPU」に変更し,
- Keras ModelをTPU形式に変換
するだけで利用できるようになるみたいです. また,注意事項として,
- XLA Compilerに対応し,
- Optimizerは
tf.train.Optimizerを利用
する必要があります. 公式のLSTMの学習を試してみたところ,5倍ほどTPUのほうがGPUより早くなっていました.
以下では,CIFAR10にTPUを試してみた方法について記載しています. ただ,GPU版のほうが1.5倍程度早かったので,むにゃむにゃ...
手順
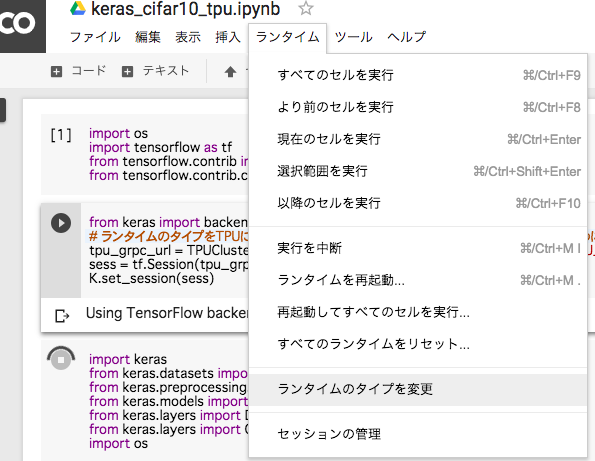
"ランタイム > ランタイムのタイプを変更"を選択する.
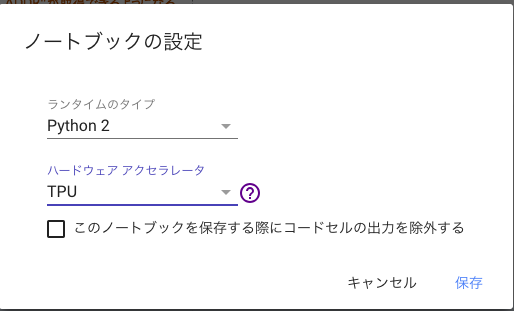
ハードウェアアクセラレータを「TPU」に変更する
-
この設定に変更することで,環境変数"COLAB_TPU_ADDR"が追加されるので,その値をTPUClusterResoluverに渡す.
-
どうも8 TPU使っているみたいなので,TPUDistributionStrategyで複数のTPUが動くようにさせる.
import os
import tensorflow as tf
from keras.datasets import cifar10
num_classes = 10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = tf.keras.utils.to_categorical(y_train, num_classes)
y_test = tf.keras.utils.to_categorical(y_test, num_classes)
y_train = y_train.astype("float32")
y_test = y_test.astype("float32")
# XLA Compilerに通るようモデルを構築
def build_model(input_shape, num_classes):
source= tf.keras.Input(name="seed", shape=input_shape, batch_size=batch_size)
x = tf.keras.layers.Convolution2D(32, (3, 3), padding='same', activation="relu")(source)
x = tf.keras.layers.Convolution2D(32, (3, 3), activation="relu")(x)
x = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(x)
x = tf.keras.layers.Dropout(0.25)(x)
x = tf.keras.layers.Convolution2D(64, (3, 3), padding='same', activation="relu")(x)
x = tf.keras.layers.Convolution2D(64, (3, 3), activation="relu")(x)
x = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(x)
x = tf.keras.layers.Dropout(0.25)(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(512, activation="relu")(x)
x = tf.keras.layers.Dropout(0.5)(x)
prediction = tf.keras.layers.Dense(num_classes, activation="softmax")(x)
model = tf.keras.Model(inputs=[source], outputs=[prediction])
print model.summary()
return model
batch_size = 32
epochs = 100
tf.keras.backend.clear_session()
model = build_model(x_train.shape[1:], num_classes)
# 標準のKeras Optimizerではなく,tf.train.Optimizerを利用
model.compile(
optimizer=tf.train.RMSPropOptimizer(learning_rate=0.01),
loss='categorical_crossentropy',
metrics=['categorical_accuracy']
)
# 環境変数に登録されているTPUサーバーへ接続
TPU_WORKER = "grpc://" + os.environ["COLAB_TPU_ADDR"]
strategy = tf.contrib.tpu.TPUDistributionStrategy(
tf.contrib.cluster_resolver.TPUClusterResolver(TPU_WORKER)
)
# Keras ModelをTPU形式へ変換
tpu_model = tf.contrib.tpu.keras_to_tpu_model(
model,
strategy=strategy
)
tpu_model.fit(
x_train,
y_train,
batch_size=batch_size,
epochs=epochs,
# steps_per_epoch=int((len(y_train) + batch_size - 1) / batch_size),
validation_data=(x_test, y_test)
)
実行結果
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
seed (InputLayer) (200, 32, 32, 3) 0
_________________________________________________________________
conv2d (Conv2D) (200, 32, 32, 32) 896
_________________________________________________________________
conv2d_1 (Conv2D) (200, 30, 30, 32) 9248
_________________________________________________________________
max_pooling2d (MaxPooling2D) (200, 15, 15, 32) 0
_________________________________________________________________
dropout (Dropout) (200, 15, 15, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (200, 15, 15, 64) 18496
_________________________________________________________________
conv2d_3 (Conv2D) (200, 13, 13, 64) 36928
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (200, 6, 6, 64) 0
_________________________________________________________________
dropout_1 (Dropout) (200, 6, 6, 64) 0
_________________________________________________________________
flatten (Flatten) (200, 2304) 0
_________________________________________________________________
dense (Dense) (200, 512) 1180160
_________________________________________________________________
dropout_2 (Dropout) (200, 512) 0
_________________________________________________________________
dense_1 (Dense) (200, 10) 5130
=================================================================
Total params: 1,250,858
Trainable params: 1,250,858
Non-trainable params: 0
_________________________________________________________________
None
INFO:tensorflow:Querying Tensorflow master (grpc://10.38.159.74:8470) for TPU system metadata.
INFO:tensorflow:Found TPU system:
INFO:tensorflow:*** Num TPU Cores: 8
INFO:tensorflow:*** Num TPU Workers: 1
INFO:tensorflow:*** Num TPU Cores Per Worker: 8
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:CPU:0, CPU, -1, 11556836988503006684)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:XLA_CPU:0, XLA_CPU, 17179869184, 1783908194868454108)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:XLA_GPU:0, XLA_GPU, 17179869184, 4319195988297713)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:0, TPU, 17179869184, 5085047460198715945)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:1, TPU, 17179869184, 2663973885407591592)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:2, TPU, 17179869184, 6004005296145049325)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:3, TPU, 17179869184, 12753917047490435149)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:4, TPU, 17179869184, 15621670725617450162)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:5, TPU, 17179869184, 10895028410283243594)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:6, TPU, 17179869184, 4055921698657050266)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:7, TPU, 17179869184, 12873494186499823987)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU_SYSTEM:0, TPU_SYSTEM, 17179869184, 7589809631221082468)
WARNING:tensorflow:tpu_model (from tensorflow.contrib.tpu.python.tpu.keras_support) is experimental and may change or be removed at any time, and without warning.
Train on 50000 samples, validate on 10000 samples
Epoch 1/100
INFO:tensorflow:New input shapes; (re-)compiling: mode=train, [TensorSpec(shape=(25, 32, 32, 3), dtype=tf.float32, name=u'seed0'), TensorSpec(shape=(25, 10), dtype=tf.float32, name=u'dense_1_target_10')]
INFO:tensorflow:Overriding default placeholder.
INFO:tensorflow:Remapping placeholder for seed
INFO:tensorflow:Started compiling
INFO:tensorflow:Finished compiling. Time elapsed: 2.23141384125 secs
INFO:tensorflow:Setting weights on TPU model.
49800/50000 [============================>.] - ETA: 0s - loss: 2.1481 - categorical_accuracy: 0.1998INFO:tensorflow:New input shapes; (re-)compiling: mode=eval, [TensorSpec(shape=(25, 32, 32, 3), dtype=tf.float32, name=u'seed0'), TensorSpec(shape=(25, 10), dtype=tf.float32, name=u'dense_1_target_10')]
INFO:tensorflow:Overriding default placeholder.
INFO:tensorflow:Remapping placeholder for seed
INFO:tensorflow:Started compiling
INFO:tensorflow:Finished compiling. Time elapsed: 1.13871693611 secs
50000/50000 [==============================] - 22s 433us/step - loss: 2.1485 - categorical_accuracy: 0.2003 - val_loss: 1.9970 - val_categorical_accuracy: 0.2824
Epoch 2/100
50000/50000 [==============================] - 16s 314us/step - loss: 1.6160 - categorical_accuracy: 0.4259 - val_loss: 1.4855 - val_categorical_accuracy: 0.4784
Epoch 3/100
50000/50000 [==============================] - 16s 318us/step - loss: 1.3112 - categorical_accuracy: 0.5368 - val_loss: 1.1347 - val_categorical_accuracy: 0.6040
Epoch 4/100
50000/50000 [==============================] - 16s 316us/step - loss: 1.1523 - categorical_accuracy: 0.5987 - val_loss: 1.0523 - val_categorical_accuracy: 0.6104
Epoch 5/100
50000/50000 [==============================] - 15s 308us/step - loss: 1.0200 - categorical_accuracy: 0.6397 - val_loss: 0.9605 - val_categorical_accuracy: 0.6536