まえおき
Hamee Advent Calendar 24日目の記事です。
今年はサンタさんには Yogibo Max(3万円) をお願いしました。年末はゴロゴロ過ごしたい。
(昨年サンタさんにお願いしたホットサンドメーカーはこの1年間よく働いてくれました)
やりたいこと
さて、今回は自分のチームでやってるデータ活用例を1つ紹介したいと思っています。
マーケティングチームにJOINした際に、こういう課題がありました。
- 新規ユーザ登録(CV)があった場合に、通知を見て1件ずつSpreadsheetに企業を追加
- アクセスログ一覧から行動情報や過去の接触情報を追って、結果をシートに手で反映
- アクセスログはTreasureDataに溜まってて、ログを日次で吐き出すようにされてた
- アクセスログには企業情報がないので、ログの日次とclient_id等でそれっぽい企業を目視判定してた
もうちょっと楽かつ高精度にできそうな部分がいくつかあるなと思ったので、このへんを整備します。
フロー設計
集約先はみんなが手軽に閲覧・書き込みができるSpreadsheetを引き続き利用します。
- 新規ユーザから申込があればシートに書き出す
- TreasureDataのデータも日次で別シート吐き出す
- 書き出したユーザの情報と、TreasureDataのアクセスログを突き合わせる
- 対象があればユーザシート側に追記
こんなかんじでやればできそう
1はGmailを5分おきに見にいって新規があればシートに書き出す、というおなじみのやつ。
2はTD側で吐き出したいクエリを書いて、設定で出力先とcronを指定すればOK。
それぞれわかりやすい記事がたくさんあるので割愛。
今回の肝は、シートの顧客情報とTDのアクセス情報の突合です。
解決したい課題
- アクセスログには顧客情報が載っていない
- TDの3rd party cookieでデバイス間のユーザの一意判定ができるが、Appleの対策によってiOSなどでは同一判定ができない。Appleユーザは一定数いる。
- 登録フォームはシステムが持っているが、アクセスログはwebページが持っている。よってクロスドメインなので制約あり
- 登録フォームからシステムのDBに登録された情報はTDに同期されているので使えそう
1. どうやって3rdPartyCookieが効かないユーザを一意判定するか
TDの3rd party cookieはiOSとsafari以外で利用し、それ以外はIPとデバイス情報で一致とします。
これをunique_idとして一意キーとして利用できるようにします。
CASE
WHEN td_browser in ('Mobile Safari','Safari','Chrome Mobile iOS') THEN CONCAT(td_ip, td_user_agent)
ELSE td_global_id
END AS unique_id
完全じゃないですが、今まで6〜7割くらいしか判定できなかった情報が
これで9割くらいは一致判定できるようになりました。
2. unique_idごとの企業情報が欲しい
登録時にはユーザが顧客情報を入力するので、
そのときのアクセスと突き合わせれば、unique_idと顧客情報を紐付けられるはずです。
登録後はログインidが発行され、そのidがクライアント側で取れるので、これをTDで取得します。
(jsでtd.set('pageviews', {user_id: xxxxxx})という感じにする)
ちなみに、解析したいアクセスログを取りたいwebページと、
登録フォームがあるシステムは別ドメインなので、
登録フォームのあるシステム側の情報を取得する必要があります。
これを日次で、users_unique_ids マスタとして保存しておきます。クエリは以下。
-- uniqeu_idとシステムのユーザidとを突き合わせてマスタデータに投入
INSERT INTO users_unique_ids(user_id, unique_id, pageviews_min_time)
SELECT
p.user_id as user_id
,p.unique_id as unique_id
,MIN(p.time) as pageviews_min_time
FROM (
SELECT DISTINCT
CASE
WHEN td_browser in ('Mobile Safari','Safari','Chrome Mobile iOS') THEN CONCAT(td_ip, td_user_agent)
ELSE td_global_id
END AS unique_id
,user_id
,time
FROM pageviews
WHERE TD_TIME_RANGE(
time
,TD_TIME_FORMAT(TD_TIME_ADD(TD_SCHEDULED_TIME(), '-1d'), 'yyyy-MM-dd 00:00:00', 'JST')
,TD_TIME_FORMAT(TD_SCHEDULED_TIME(), 'yyyy-MM-dd 00:00:00', 'JST')
,'JST')
AND user_id is not null
) AS p
LEFT JOIN users_unique_ids AS u
ON p.uesr_id = u.user_id
AND p.unique_id = u.unique_id
WHERE u.user_id is null -- 重複のINSERTがないように
GROUP BY p.user_id, p.unique_id
ORDER BY pageviews_min_time
TD側でcron設定しておきます。
翌日に前日のデータを溜める、なのでバッファみて1時〜朝までのどこかで実行できればOK
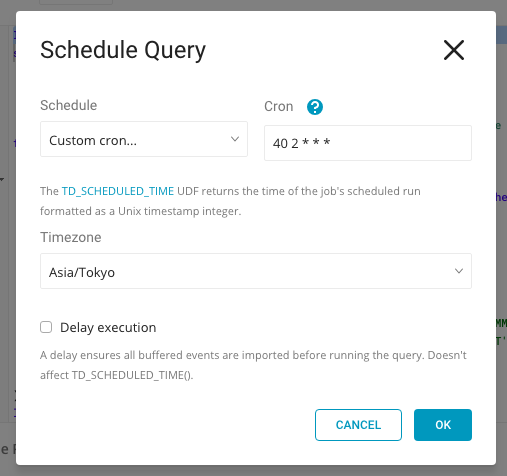
こういうデータが扱えるようになりました。
あとは、TDに同期した登録データとuser_idをJOINすれば、ユーザや企業を特定できます。
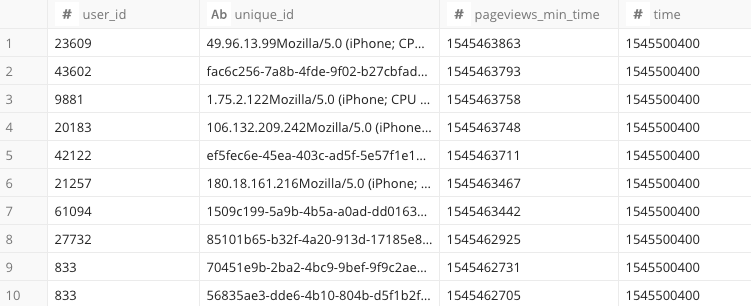
3.Spreadsheetに欲しいアクセスログ情報を吐き出す
あとはTDのクエリを、同じように日次でシートに吐き出して加工するだけです。
シート上にはメール等から取り出したユーザの「company_id」が載っているので、
これをキーにできるよう、TD側で「company_id」が吐き出せるようにします。
今回欲しいアクセスログ情報は、以下とします。
- 登録フォームの直前のURL -> CVのトリガーとなりやすいページを特定するため
- 登録フォームのURLのパラメータ -> 特定の経路からの流入であればパラメータが付与されるため
- 登録フォームのアクセスの時間 -> CVまでのリードタイムを確認するため
-- 昨日の発行ユーザのアクセスログを取得する
select
cv.user_id
,cv.unique_id
,c.company_id
,c.company_name
,p.ref_new_url -- 登録直前のURL
,p.new_url -- 登録フォームのURL(キャンペーンコードや広告流入のパラメータ有無を確認するため)
,TD_TIME_FORMAT(p.time, 'yyyy-MM-dd HH:mm:ss', 'JST') as datetime -- 登録フォームにアクセスした日時
from (
-- 昨日の登録ユーザ
SELECT user_id, unique_id, pageviews_min_time
FROM users_unique_ids
WHERE TD_TIME_RANGE(
time
,TD_TIME_FORMAT(TD_TIME_ADD(TD_SCHEDULED_TIME(), '-1d'), 'yyyy-MM-dd 00:00:00', 'JST')
,TD_TIME_FORMAT(TD_SCHEDULED_TIME(), 'yyyy-MM-dd 00:00:00', 'JST')
,'JST')
) cv
INNER JOIN companies AS c -- 登録されたDBの企業情報とくっつける。今はDB名とかは適当
ON c.user_id = cv.user_id
LEFT JOIN (
-- ユーザ登録の前後のアクセスを取得
select *
from (
SELECT
time
,unique_id
,ROW_NUMBER() OVER( PARTITION BY unique_id ORDER BY time ) AS row_num
,URL_DECODE(td_referrer) AS ref_new_url
,td_url as new_url -- 基点
,LEAD(td_url, 1) OVER (PARTITION BY unique_id ORDER BY time) AS created_url -- new_urlの1つ次
FROM
(
SELECT time, td_url, td_referrer, td_path, unique_id -- 整形済みとする
FROM pageviews
where
TD_TIME_RANGE( -- 遡るのは最大1週間前まで
td_pageviews_time
,TD_TIME_FORMAT(TD_TIME_ADD(TD_SCHEDULED_TIME(), '-7d'), 'yyyy-MM-dd 00:00:00', 'JST')
,TD_TIME_FORMAT(TD_SCHEDULED_TIME(), 'yyyy-MM-dd 00:00:00', 'JST')
,'JST'
)
)
)
where
new_url LIKE 'https://example.com/user/new%' -- 登録フォームURL。パラメータがくっついてる場合があるのでLIKE
and created_url = 'https://example.com/user/created' -- 登録完了URL
) p
ON cv.unique_id = p.unique_id
-- 登録前のログに絞る
AND p.time <= cv.pageviews_min_time
ポイント
- 登録フォームへの直前のアクセス(=ref_new_url)
- 登録フォームへのアクセス(=new_url)
- 登録完了(=created_url)
という3種類の判定をしたかったので、真ん中の「new_url」を基点としました。
取得したい情報が多いレコードを基点としておけばいろんなデータが取り出しやすくなります。
欲しい情報はたいていWindow関数で取ってこれます。
あとはこれをさっきのINSERT同様、日次でcron設定しておけばOK。
異なるのは、今度は外部のSpreadsheetとの連携なので、どのシートに吐き出すか設定が必要となります。
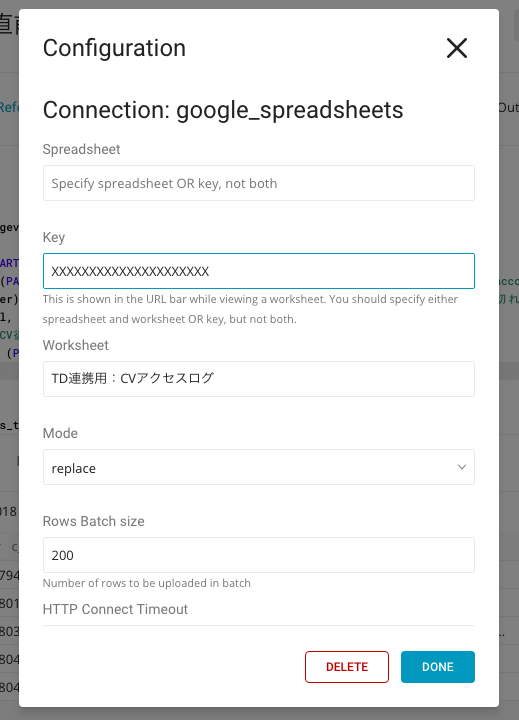
このcronが実行されれば、「TD連携用:CVアクセスログ」というシート名に以下のようなデータが入ってます。

4.シート側の対象行を特定して、TreasureDataの情報を特定列に更新
あとはGASで、吐き出されたシートの情報から突き合わせできればOK。
当たり前ですがシートへの吐き出し後の時間に動くよう設定しないとダメです。
/**
* TDから日時でCVしたユーザのログデータをダウンロードし、シートをUPDATEする
* 朝4時〜5時 実行
*/
function updateRowTdAccessLogData() {
var ss = SpreadsheetApp.getActiveSpreadsheet();
// 読み取りデータ生成
var read_sheet = ss.getSheetByName('TD連携用:CVアクセスログ');// 読み取りシート名
var read_last_row_index = read_sheet.getLastRow();
if (read_last_row_index < 2) {
console.log('対象なしのため実行しない');
return;
}
var values = read_sheet.getRange(2, 1, read_last_row_index -1, 11).getValues();
var company_ids = {};
for (var i = 0; i < values.length; i++) {
var row = values[i];
var company_id = row[2];
// アクセスのdatetimeがなくて、既にcompany_idがセットされていれば何もしない
if (row[6] === '' && company_id in company_ids) {
continue;
}
company_ids[company_id] = [
row[1] // unique_id
, row[4] // ref_new_url
, row[5] // new_url
, row[6] // datetime
]
}
// 書き出し
var sheet = ss.getSheetByName('CVユーザ一覧');
var last_row = sheet.getLastRow();
var search_count = 100; // 直近100行を対象にすると決める。対象全行とすると負荷がかかるため
var search_values = sheet.getRange(last_row +1 -search_count, 1, search_count, 4).getValues(); // 検索範囲A〜D列
//今日の0時0分0秒
var today = new Date();
var today_0 = new Date(today.getFullYear(), today.getMonth(), today.getDate(), 0, 0, 0);
for (var k = 0; k < search_count; k++) {
var company_id = search_values[k][0]; // A列
var datetime = search_values[k][1]; // B列
var unique_id = search_values[k][3]; // D列
// 今日0時以降&TD情報入力済みであれば判定前にスキップ
if (datetime >= today_0 && unique_id !== '') {
continue;
} else if (company_id in company_ids) {
var td_value = company_ids[company_id];
var row_num = last_row +1 -search_count +k;
sheet.getRange('D'+ row_num +':G'+ row_num).setValues([td_value]); // 対象列D〜Gに入れる
}
}
}
ポイント
- 転記内容を配列にまとめておく
- 検索対象の範囲がどこからスタートしたかをベースに行数を特定し、キーが合致したらその行にset
- TD側のデータは「昨日登録」だけを取得しているが、シート側はリアルタイムで書き込みされるので、「今日0時」より前を条件とする
- アクセスログが取れていない場合、TDが吐き出した結果に載ってないのでスキップさせる
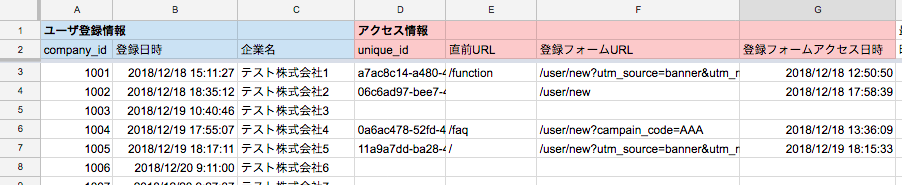
このGASがちゃんと実行できていれば、ユーザ一覧だけが載ってたシートに、
アクセスログ情報を付与することが出来ます\(^o^)/(↓D列〜)
他にも
このシート連携はいろいろ応用ができるので、
「CV対象」と「アクセスログ」を何にするかでいくらでも使い道があります。
今実際にやってる例
- 登録時だけでなくMarketoフォームを利用したインバウンド回収(資料請求や申込問い合わせ)をCVとし、ユーザ登録されていない顧客のアクセスを特定
- MarketフォームをTDに飛ばしておくことで、CVのDBと同じようにJOIN可能
- 感度の高いユーザに営業チームが接触したり、ユーザ把握するために利用
- アクセスログをもとに広告の経路も割り出したい
- WINDOW関数+URI関数などで取り出したりしてます。こんな感じ
-- 広告経由のアクセスログのうち最後のアクセス
select
unique_id
,url_extract_parameter(ad_p.last_ad_url, 'utm_medium') as ad_utm_medium
,url_extract_parameter(ad_p.last_ad_url, 'utm_campaign') as ad_utm_campaign
,ad_p.last_ad_url as ad_last_url
from (
select
unique_id
,FIRST_VALUE(td_url) OVER (PARTITION BY unique_id ORDER BY time DESC) AS last_ad_url
,FIRST_VALUE(time) OVER (PARTITION BY unique_id ORDER BY time DESC) AS last_ad_time
from pageviews
where
td_url != ''
and td_url LIKE 'https://example.com%?%utm_source=ad%' -- utm_sourceがついたURL
) ad_p
最後に
実際これまで取れなかったデータが目に見えるようになったりすると
自分もすごく嬉しいしチームのマーケターたちにも喜んでもらえるし、
こういう活動をやっていくことには意味があると思っています。
ただ、もっとわかりやすくするとか見やすくするとか、部内でのデータ民主化も含めて、
データを意思決定に利用してもらうためにはまだまだ課題が多いなと感じています。
今年はいろんなことにチャレンジできた1年だったかなと思うので、
来年もわんだほーな1年になるようにがんばります![]() !
!
おわり