はじめに
Azure Synapse Analytics や Azure Data Factory のパイプラインを用いて、あるデータ ストアから別のデータ ストアにデータを簡単にコピーすることができます。コピー元のデータ ストアが Azure SQL Database などの RDB (リレーショナル データベース) の場合、コピー対象のデータを SQL で抽出することができます。
本記事では、RDB に複数のテーブルがあり、テーブルごとに異なる SQL を使ってデータを抽出したい場合を想定して、テーブルごとに利用する SQL やコピー先のファイル名などの情報を Azure Table Storage で管理する方法についてまとめます。
(Table Storage を利用しているのはあくまで一例です。Synapse パイプラインの Lookup アクティビティは Table Storage 以外にも多くのデータ ストアに対応しています。もしお好みデータ ストアがあれば Table Storage ではなくそちらをお使い頂くことも当然可能です)
以下が本記事で作成する Synapse パイプラインとその周辺のデータ ストアの関係をまとめたイメージ図になります。

下準備: 各種リソース作成 (Azure ポータルでの作業)
下準備として Azure ポータルから以下のリソースを作成します。
- リソース グループ
- リソース グループ名の例:
rg-hinakaza-synapse-demo-etl
- リソース グループ名の例:
- Azure SQL Database
- データベース名の例:
AdventureWorksLT - サーバー名の例:
sql-hinakaza-synapse-demo-etl - [追加設定] で [既存のデータを使用します] > [サンプル] を選択
- データベース名の例:
- Azure Synapse Analytics ワークスペース
- ワークスペース名の例:
syn-hinakaza-demo-etl - ADLS Gen2 アカウント名の例:
sthinakazasyndemoetl - ADLS Gen2 ファイル システム名の例:
synapse-container
- ワークスペース名の例:
Azure Table Storage にテーブルとエンティティを作成
- Synapse ワークスペースとともに作成されたストレージ アカウントにアクセス
- ストレージ ブラウザーでテーブルを作成
- テーブル名の例:
CopySettingsForAdventureWorksLT
- テーブル名の例:
- テーブルに以下 2 件のエンティティを登録
| PartitionKey | RowKey | Query | FilePathCsv |
|---|---|---|---|
| SalesLT | Address | select * from SalesLT.Address | Address.csv |
| SalesLT | Customer | select * from SalesLT.Customer | Customer.csv |
以上で下準備は終わりです。
Synapse Studio での作業
ここからは Synapse Studio 上で作業を進めます。Synapse Studio には以下赤枠のリンクからアクセスします。
Lookup 向け編集
Table Storage のリンク サービスを作成
- [管理] ハブから Azure Table Storage に接続するためのリンク サービスを作成します
- リンク サービス名の例:
AzureTableStorage_sthinakazasyndemoetl

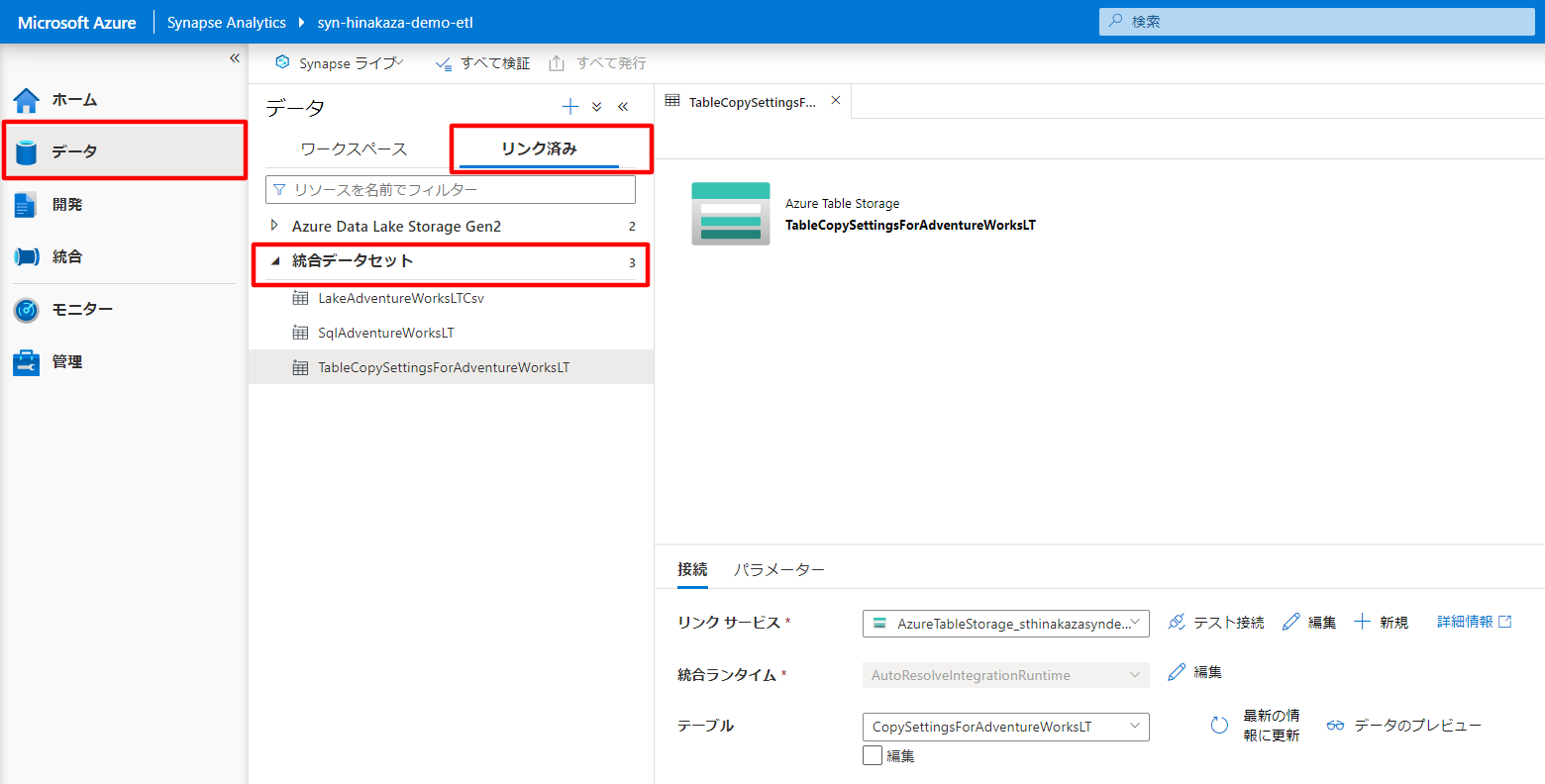
Table Storage のデータセットを作成
- [データ] ハブから Table Storage のテーブル
CopySettingsForAdventureWorksLTに対応するデータセットを作成します - データセット名の例:
TableCopySettingsForAdventureWorksLT
パイプラインを作成
- [統合]ハブからパイプラインを作成します
- パイプライン名の例:
PipelineCopyAdventureWorksLTSqlToLakeByQuery

パイプラインに Lookup (参照) アクティビティを設定
- パイプラインのアクティビティ一覧の [全般] の中にある [参照] アクティビティをキャンバスにドラッグ & ドロップします
- [参照] アクティビティ > [設定] タブ
- ソースデータセット: TableCopySettingsForAdventureWorksLT`
- クエリの仕様: テーブル
- 見つからなかったテーブルを無視: チェックしない
- 先頭行のみ: チェックしない

デバッグ実行
- デバッグ実行を行い Table Storage に登録した 2 件のエンティティが出力されることを確認します

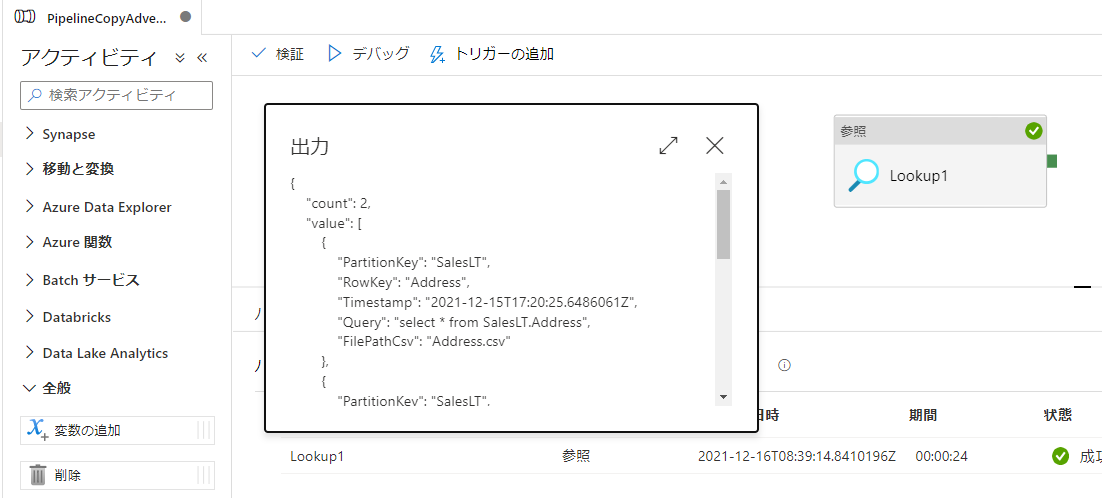
{
"count": 2,
"value": [
{
"PartitionKey": "SalesLT",
"RowKey": "Address",
"Timestamp": "2021-12-15T17:20:25.6486061Z",
"Query": "select * from SalesLT.Address",
"FilePathCsv": "Address.csv"
},
{
"PartitionKey": "SalesLT",
"RowKey": "Customer",
"Timestamp": "2021-12-15T17:20:45.735506Z",
"Query": "select * from SalesLT.Customer",
"FilePathCsv": "Customer.csv"
}
],
"effectiveIntegrationRuntime": "AutoResolveIntegrationRuntime (Japan East)",
"billingReference": {
"activityType": "PipelineActivity",
"billableDuration": [
{
"meterType": "AzureIR",
"duration": 0.016666666666666666,
"unit": "DIUHours"
}
]
},
"durationInQueue": {
"integrationRuntimeQueue": 0
}
}
ForEach & Copy 向け編集
Azure SQL Database のリンク サービスを作成
- [管理] ハブから Azure SQL Database に接続するためのリンク サービスを作成します
- リンク サービス名の例:
AzureSqlDatabase_AdventureWorksLT
Azure SQL Database のデータセットを作成
- [データ] ハブから Azure SQL Database のデータベース
AdventureWorksLTの各テーブルに対応するデータセットを作成します- データセット名の例:
SqlAdventureWorksLT - テーブル名は一旦 [なし] で作成します
- データセット名の例:

- データセットの [パラメーター] に
tableNameを追加します - データセットの [接続] > [テーブル] のテーブル名について
@dataset().tableNameとし、パラメーターtableNameに指定した値を参照するようにします

ADLS Gen2 に CSV ファイル出力用のフォルダを作成
- [データ] ハブから ADLS Gen2 に新しいフォルダ (ここでは
AdventureWorksLTCsv) を作成します

ADLS Gen2 ののデータセットを作成
- [データ] ハブからコピー結果の CSV ファイルに対応するデータセットを作成します
- データセット名の例:
LakeAdventureWorksLTCsv - 作成したデータセットの
- [パラメーター] に
fileNameを追加 - [接続] で [先頭行をヘッダーとして] にチェック
- [接続] > [ファイルパス] のファイル名について
@dataset().fileNameとし、パラメーターfileNameに指定した値を参照するようにします
- [パラメーター] に
- データセット名の例:

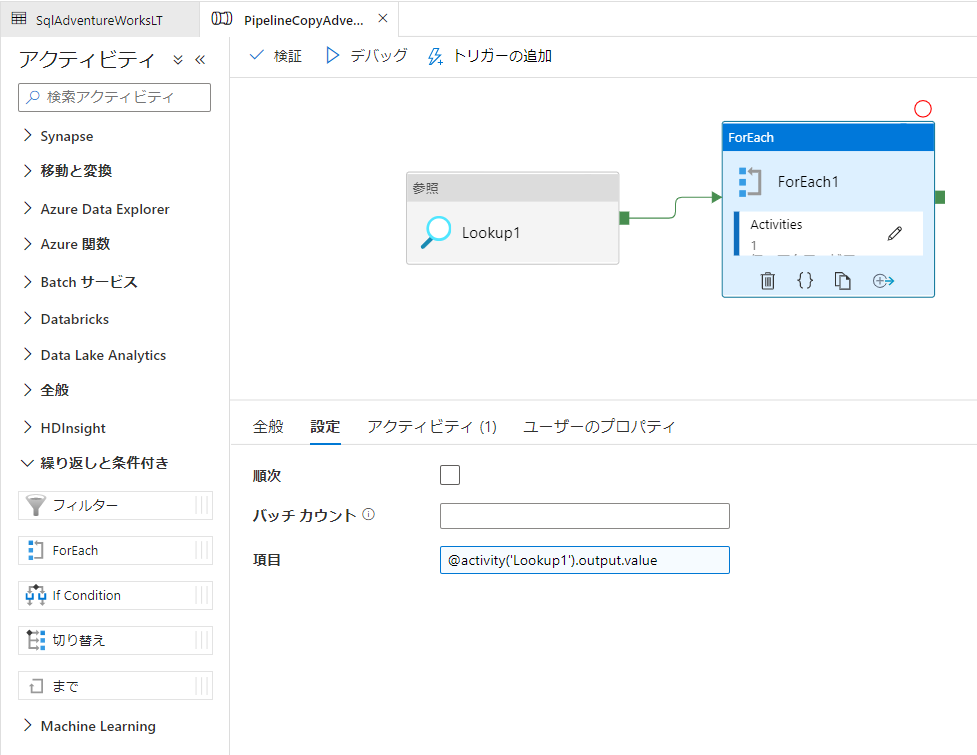
パイプラインに ForEach アクティビティを設定
- パイプラインのアクティビティ一覧の [繰り返しと条件付き] の中にある [ForEach] アクティビティをキャンバスにドラッグ & ドロップし、Lookup アクティビティと接続します
- [ForEach] アクティビティ > [設定] タブ
- 項目:
@activity('Lookup1').output.value
- 項目:
- [ForEach] アクティビティ > [アクティビティ] タブで編集アイコンを押し、[移動と変換] セクションの [データのコピー] アクティビティをドラッグ & ドロップ
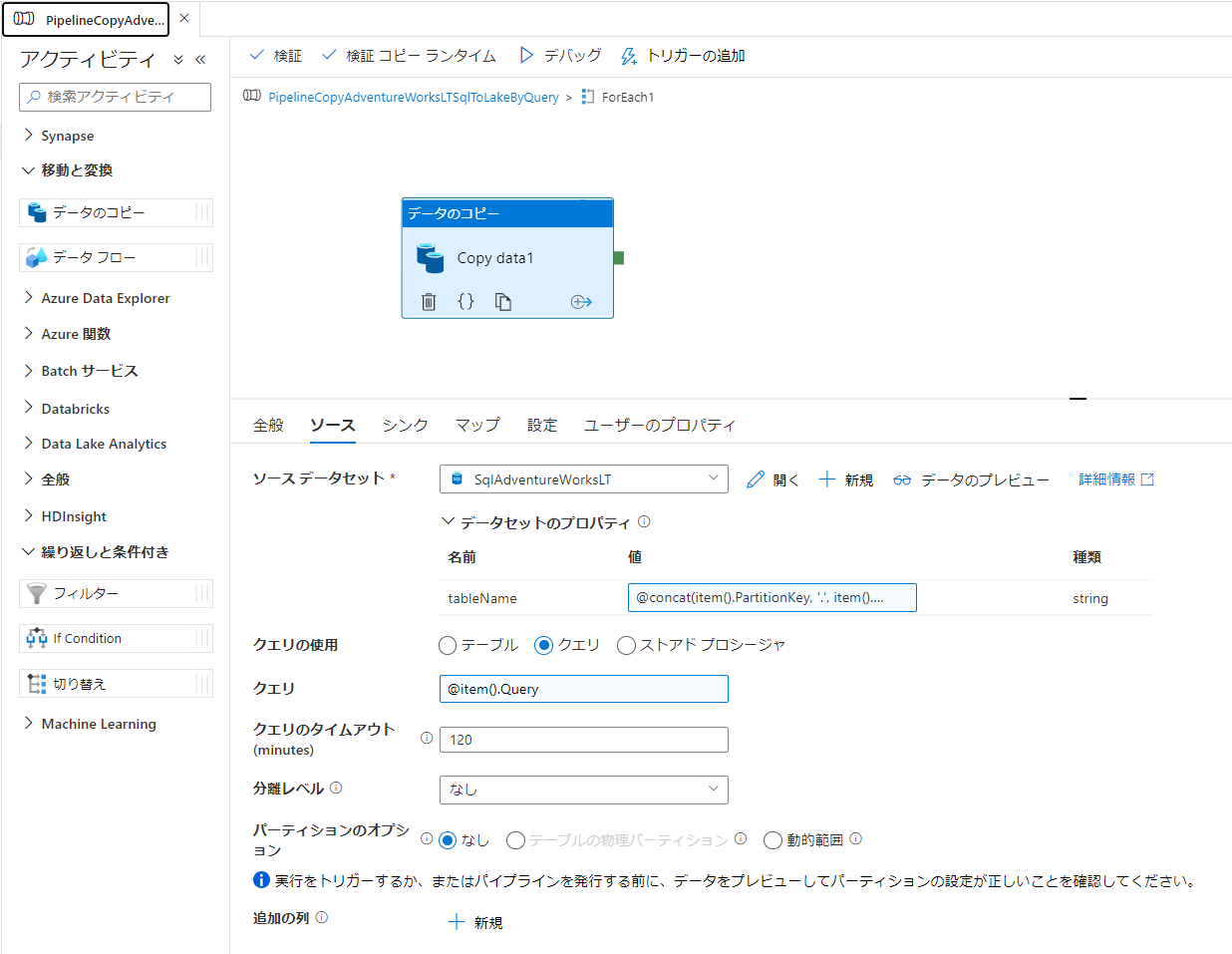
- [データのコピー] アクティビティ > [ソース] タブ
- ソース データセット:
SqlAdventureWorksLT - tableName:
@concat(item().PartitionKey, '.', item().RowKey) - クエリの使用: クエリにチェック
- クエリ:
@item().Query
- ソース データセット:
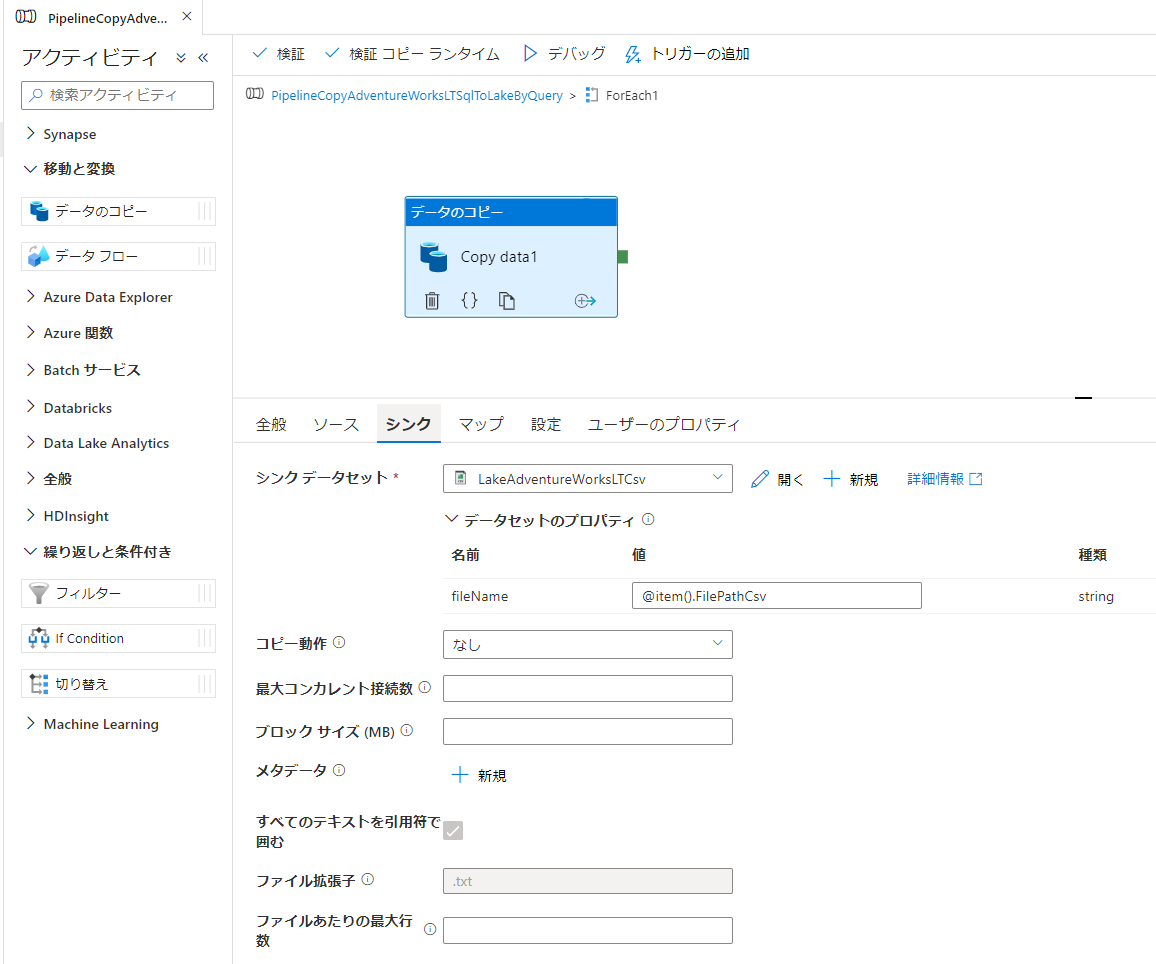
- [データのコピー] アクティビティ > [シンク] タブ
- シンク データセット:
LakeAdventureWorksLTCsv - fileName:
@item().FilePathCsv
- シンク データセット:
結果確認
以上で編集作業は完了です。
画面上部のすべて検証をクリックしてエラーがなければパイプラインをデバッグ実行し、処理が正常すること及び ADLS Gen2 に 2 つの CSV ファイルが生成されていることを確認します。

これで Synapse パイプラインのデータ コピーのクエリを外部で管理する構成は完成です。あとは Table Storage に対象のテーブルを追加したり、クエリを変更することで、コピー対象を制御することができるようになります。
以上です。