本記事のテーマ
Azure Data Factory の Mapping Data Flow を使うと GUI ベースで簡単にスケーラブルな ETL 処理を作成できます。Mapping Data Flow は様々な組み込み機能を持っており、いわゆる縦持ち形式のデータを横持ち形式に変換する ピボット変換 や、その逆に横持ち形式のデータを縦持ち形式に変換する ピボット解除変換 などがあります。
ただ、CSV 形式で一つのカラムの中に区切り文字付きで複数の要素が入っているような場合にはピボット変換 / ピボット解除変換が適用できないため、一手間掛ける必要があります。稀によくあるケースなので、本記事で簡単な対応方法をまとめたいと思います。
入出力ファイルのイメージ
入出力のファイルの格納先は Data Factory が対応していれば何でも良いのですが、本記事では Input: Azure Data Lake Storage Gen2 (ADLS Gen2) -> Process: Mapping Data Flow -> Output: ADLS Gen2 という流れを例にしたいと思います。
入力ファイルのイメージ
あるディレクトリの配下に同じレイアウトの CSV ファイルが複数ある想定にしています。
-
入力ファイル1
- ストレージアカウント:
stnakazaxqiitadf(ADLS Gen2) - コンテナ:
horizontal-vertical-container - ファイルパス:
/horizontal/horizontal1.csv
- ストレージアカウント:
"UserId","FavoriteColor"
"1","red,blue,yellow"
"2","white,black
-
入力ファイル2
- ストレージアカウント:
stnakazaxqiitadf(ADLS Gen2) - コンテナ:
horizontal-vertical-container - ファイルパス:
/horizontal/horizontal2.csv
- ストレージアカウント:
"UserId","FavoriteColor"
"3","red,green,blue"
出力ファイルのイメージ
いわゆる縦持ちの形式で1ファイルにまとめる想定にしています。
-
出力ファイル
- ストレージアカウント:
stnakazaxqiitadf(ADLS Gen2) - コンテナ:
horizontal-vertical-container - ファイルパス:
/vertical/vertical.csv
- ストレージアカウント:
"UserId","FavoriteColor"
"1","red"
"1","blue"
"1","yellow"
"2","white"
"2","black"
"3","red"
"3","green"
"3","blue"
Mapping Data Flow での処理フロー例
Mapping Data Flow の処理フロー例は以下の通りです。色々なやり方があると思いますので、これが絶対の正解という訳ではなく方法の一つだと捉えて頂ければと思います。
| No. | 処理内容 | 利用する組み込み機能 |
|---|---|---|
| 1 | 入力ファイルを読み込み | ソース変換 |
| 2 | 1カラム内に複数の要素を持つ FavoriteColor の型を string -> 配列に変換 |
派生列変換 と split (文字列を区切り文字で分割して配列を返す式関数) |
| 3 |
UserId と FavoriteColor の配列の1要素の組み合わせ = 1行という形に変換 |
フラット化変換 |
| 4 | 結果ファイルを出力 | シンク変換 |
以下のキャプチャは Mapping Data Flow で処理フローを組み上げたときの完成形のイメージです。
以降では各フローの簡単なポイントについて紹介します。

ソース変換
ソース変換で入力ファイルを指定する際にワイルドカード * が使えます。
以下のように指定すると /horizontal ディレクトリの horizontal1.csv horizontal2.csv ... horizontalN.csv のようにまとめて読み込めます。
ワイルドカードパスはオプションなので省略可能です。省略した場合はデータセットで指定したディレクトリ直下の全ファイル、またはデータセットで指定したファイルが読み込まれます。
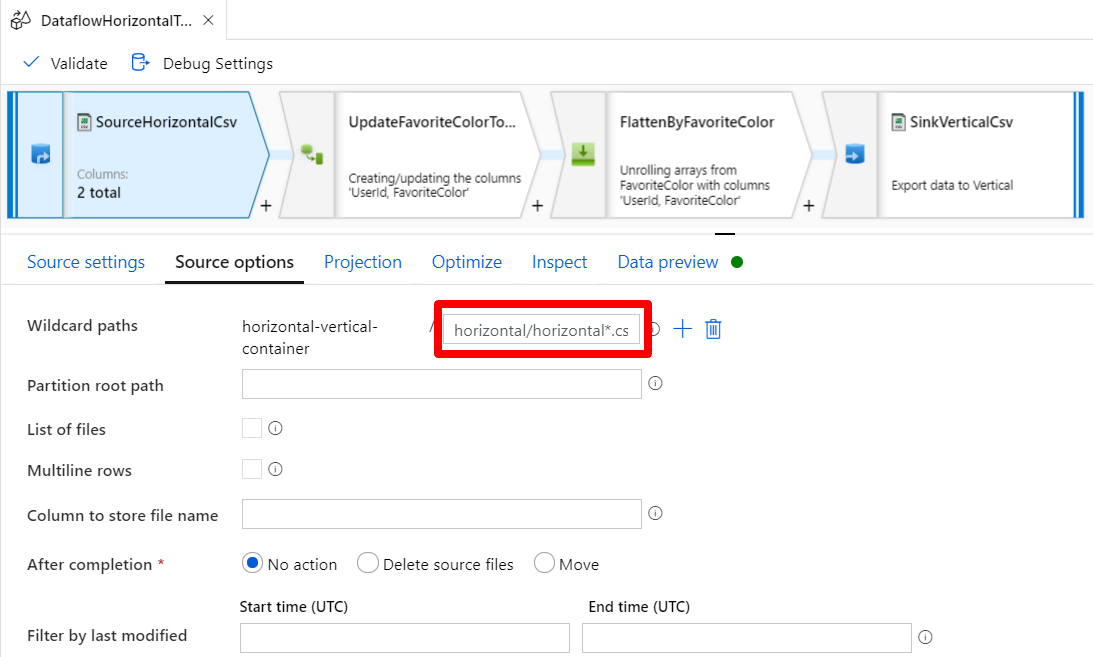
Data flow debug をオンにして [Data preview] タブを見ると複数ファイルがまとめて読み込まれていることが分かります。また UserId と FavoriteColor の横に abc と表示されていますが、これは string として解釈されていることを表しています。

派生列変換
FavoriteColor は string として解釈されていますが、式関数 split(FavoriteColor, ",") のように指定することで , で分割して配列にすることができます。
なお、ここでは [Columns] に元々のカラム名 FavoriteColor を指定しているのでカラムの型が更新されることになりますが、新たにカラムを追加したい場合は例えば DevivedFavoriteColor など元々のカラム名と違う名前を指定すれば OK です。

処理に問題がなければ [Inspect] タブで以下のように配列になっていることが確認できるはずです。
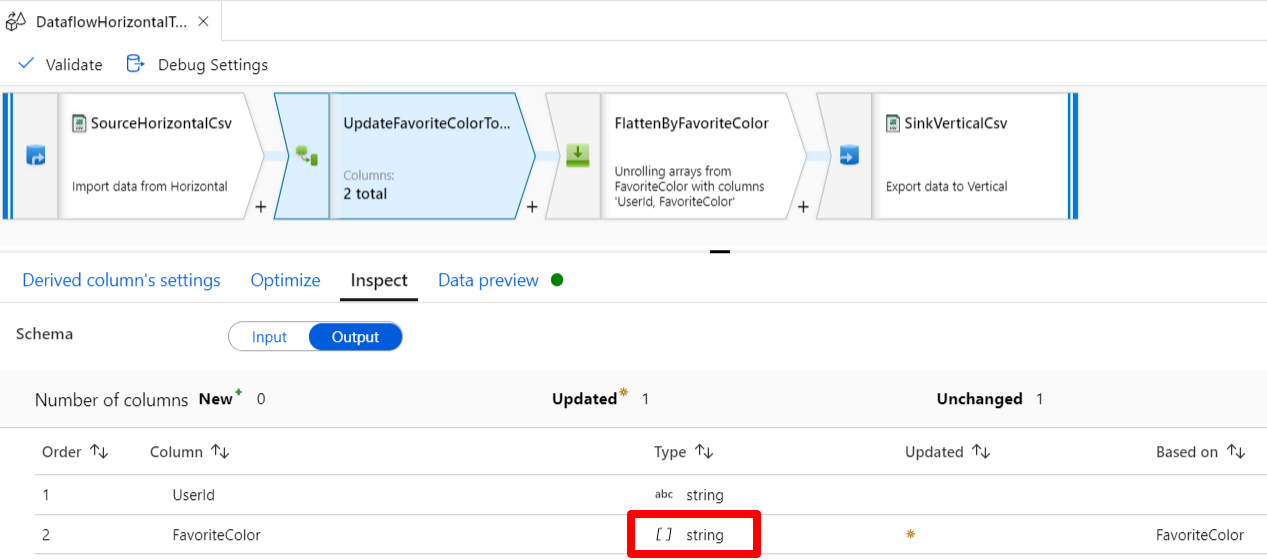
フラット化変換
[Unroll by] に先ほど配列にした FavoriteColor を指定することで、UserId と FavoriteColor の配列の1要素で1行という形に変換することができます。

Data flow debug をオンにして [Data preview] を見ると以下のようにいわゆる縦持ちの形式になっていることが確認できるはずです。

シンク変換
[Settings] タブで出力ファイルの形式を指定できます。Mapping Data Flow では裏側で Spark という分散処理フレームワークが使われており、通常は複数台のマシンが並行して結果ファイルを出力します。そのためデフォルトでは結果ファイルは複数に分かれるのですが、Output to single file を指定することで一つのファイルにまとめることができます。
ただし、結果ファイルの出力を一台のマシンが担当することになるため、大規模なデータセットを扱う場合にデフォルトと比べるとパフォーマンスに影響を与えるおそれがあります。ですので Output to single file は小規模なデータセットに対して適用するのが無難です。
もし大規模なデータセットを一つのファイルにまとめる必要がある場合はテスト実行してみてパフォーマンスに問題が無いかを確認した方が良いでしょう。
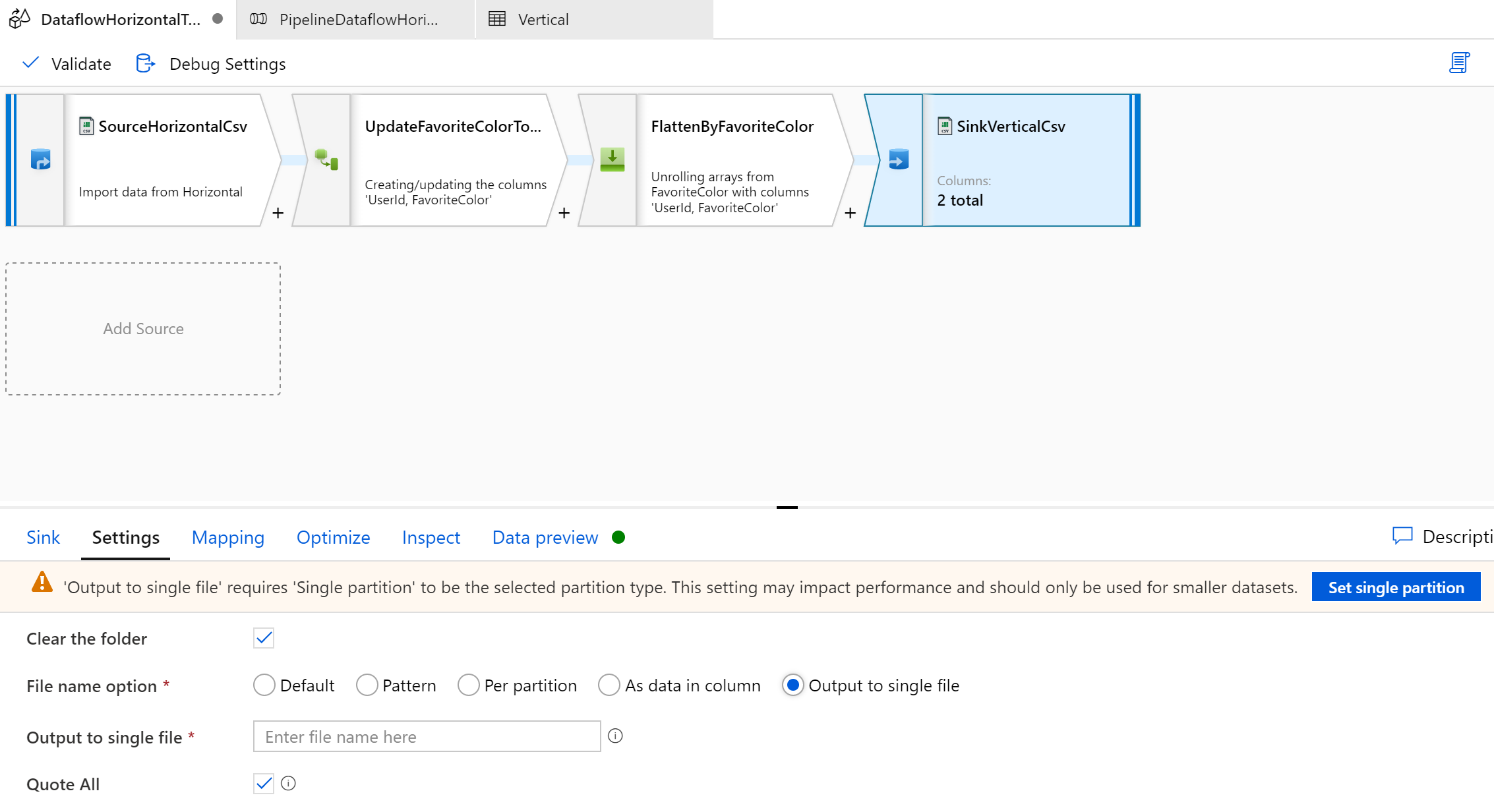
あとはこの Mapping Data Flow を呼び出すパイプラインを定義して実行することで、上述の [出力ファイルのイメージ] に記載したようないわゆる縦持ちの結果ファイルが出力されるはずです。
以上です。