本記事のテーマ
Azure Data Factory の コピーアクティビティ を用いて Azure Cosmos DB のデータを Azure Data Lake Storage Gen2 に1日1回コピーする方法についてまとめます。
なお、同様の処理を マッピングデータフロー でも行うことができますが、本記事では扱いません。
完成形イメージ
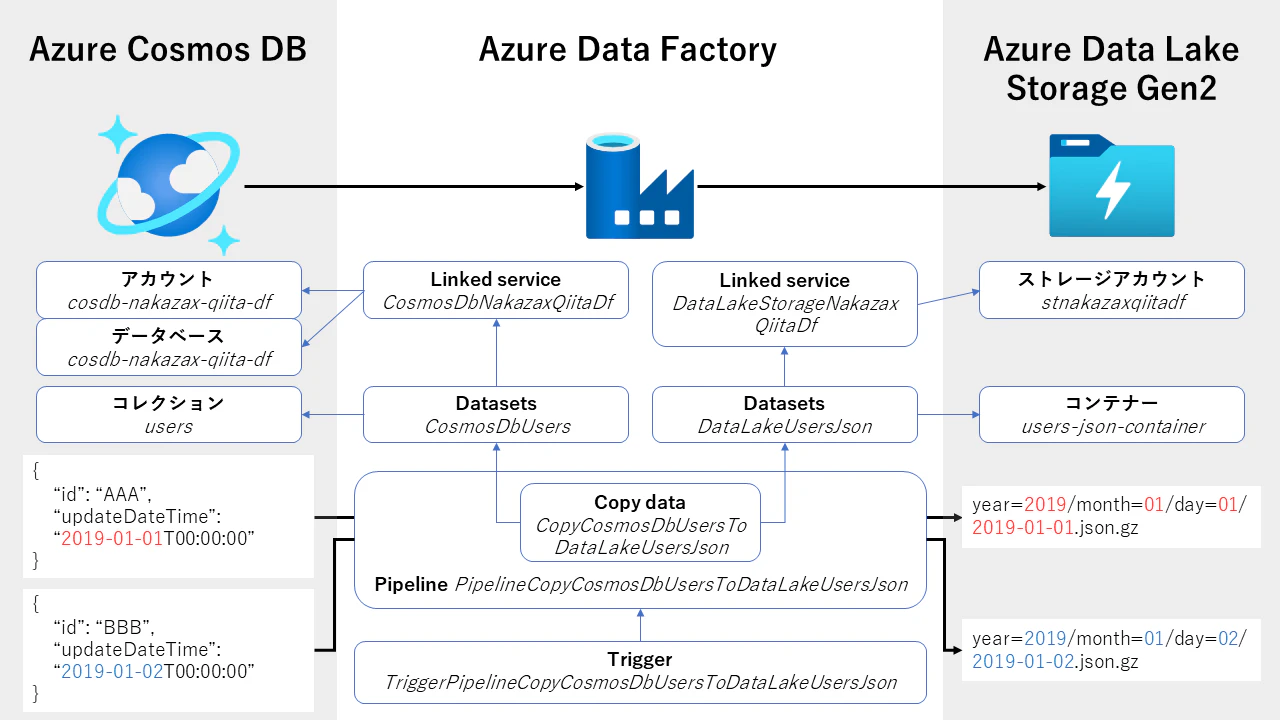
以下が完成形のイメージ図です。黒矢印はデータフロー、青矢印は参照を表しています。
1日1回起動する Data Factory が Cosmos DB の users コレクションのドキュメント内の updateDatetime という更新日時を条件にしてクエリを実行して Data Lake Storage に Gzip 圧縮された 1行1JSON の形式で出力するというフローになります。
前提
以下のリソースがあることを前提としています。もし無い場合は各サービスのチュートリアルなどを参考に作成頂ければと思います。
- Azure Cosmos DB のアカウント、データベース、コレクションがあること
- Azure Data Lake Storage Gen2 のストレージアカウントとコンテナーがあること
- Azure Data Factory を作成済みであること
1. Linked services
まず、Data Factory から Cosmos DB と Data Lake Storage に接続できるように Linked services を設定します。
1-1. Cosmos DB
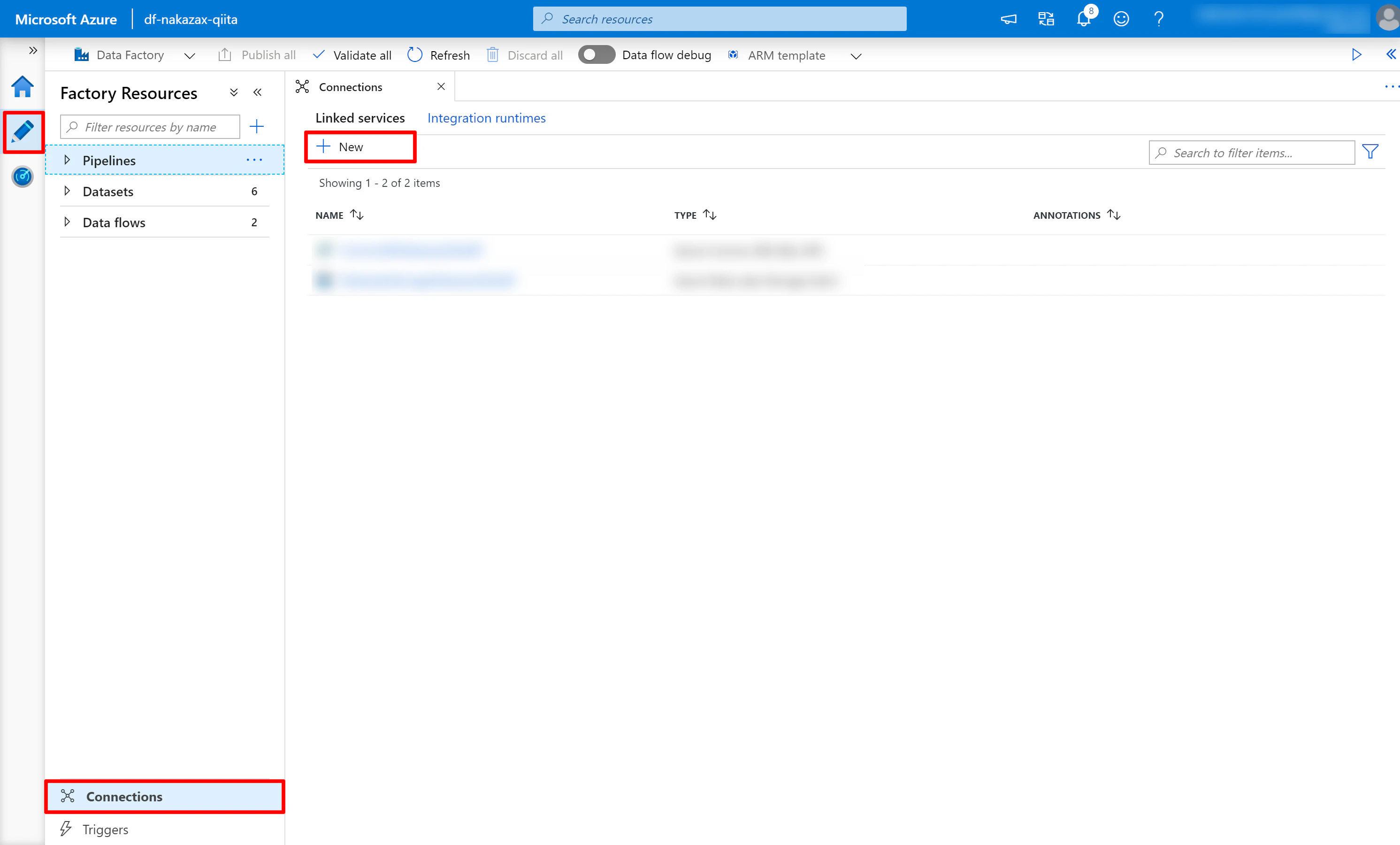
(1) 画面左の鉛筆マークをクリック > Connections > Linked services の [New] をクリックします。
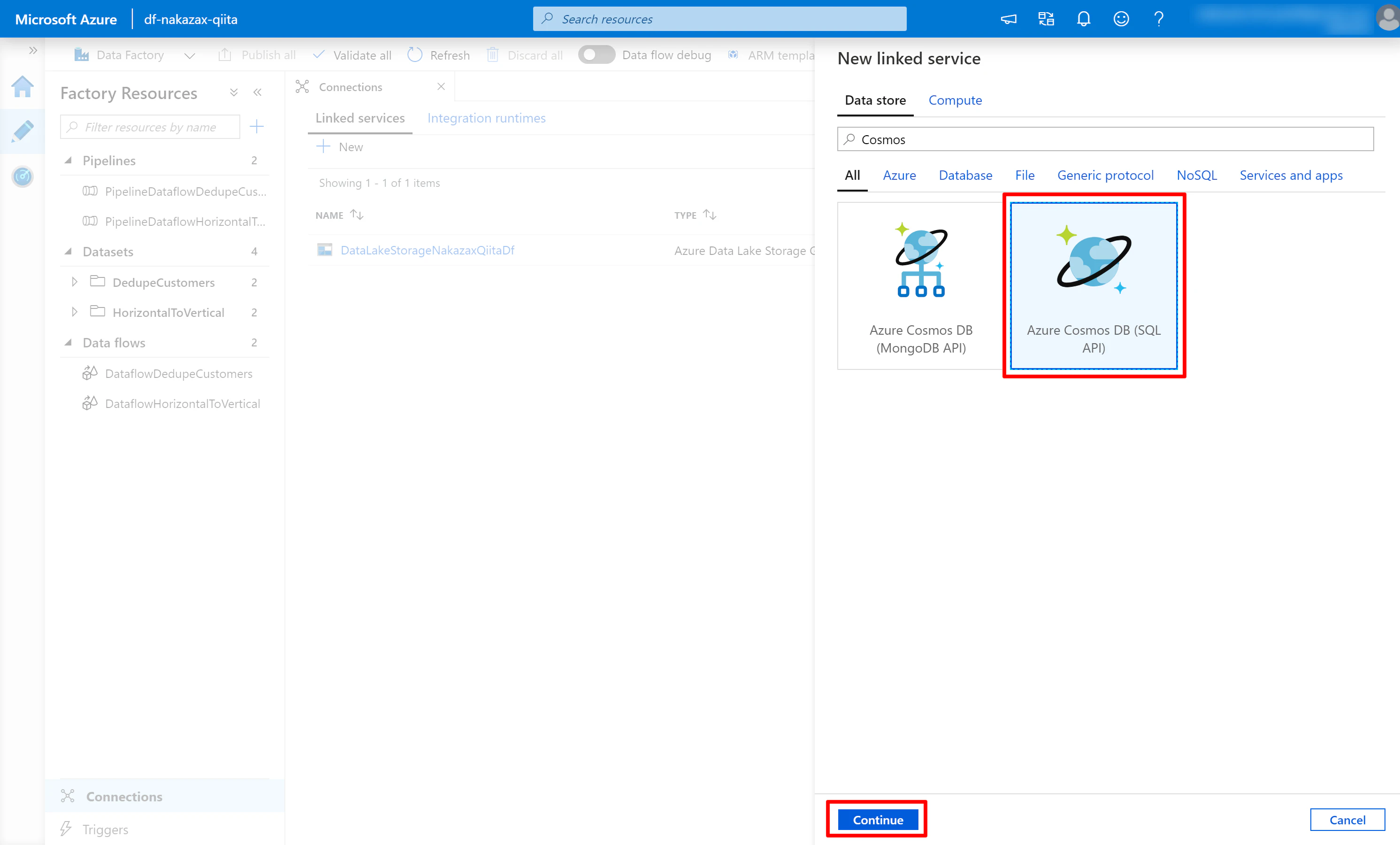
(2) 検索キーワードに cosmos などと入力し [Azure Cosmos DB (SQL API)] を選択して [Continue] をクリックします。
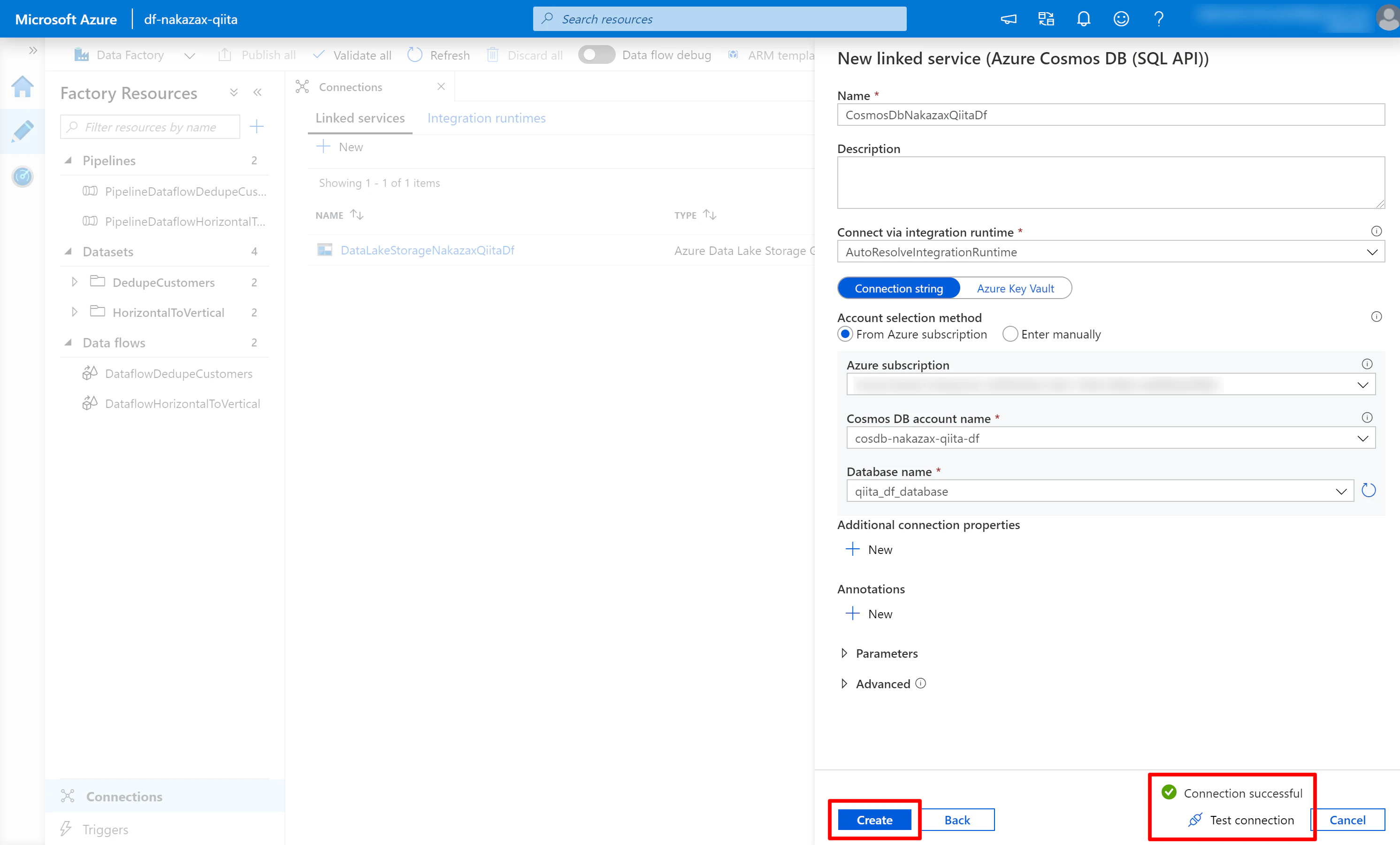
(3) 必要な項目を入力します。
- Name には任意の名前を入力、ここでは
CosmosDbNakazaxQiitaDfを使用します - Account selection method で [From Azure subscription] にチェックします
- [Azure subscription] に対象の Azure サブスクリプションを選択
- [Cosmos DB account name] に対象の Cosmos DB アカウント名を選択
- [Database name] に対象の Cosmos DB データベース名 を選択
- 他の項目を必要に応じて編集した後、画面下部の [Test connection] をクリックし、Connection successful と表示されたら [Create] をクリック
以上で Cosmos DB の接続設定は完了です。
1-2. Data Lake Storage
(1) 画面左の鉛筆マークをクリック > Connections > Linked services の [New] をクリックし、検索キーワードに Data Lake などと入力し [Azure Data Lake Storage Gen2] を選択して [Continue] をクリックします。
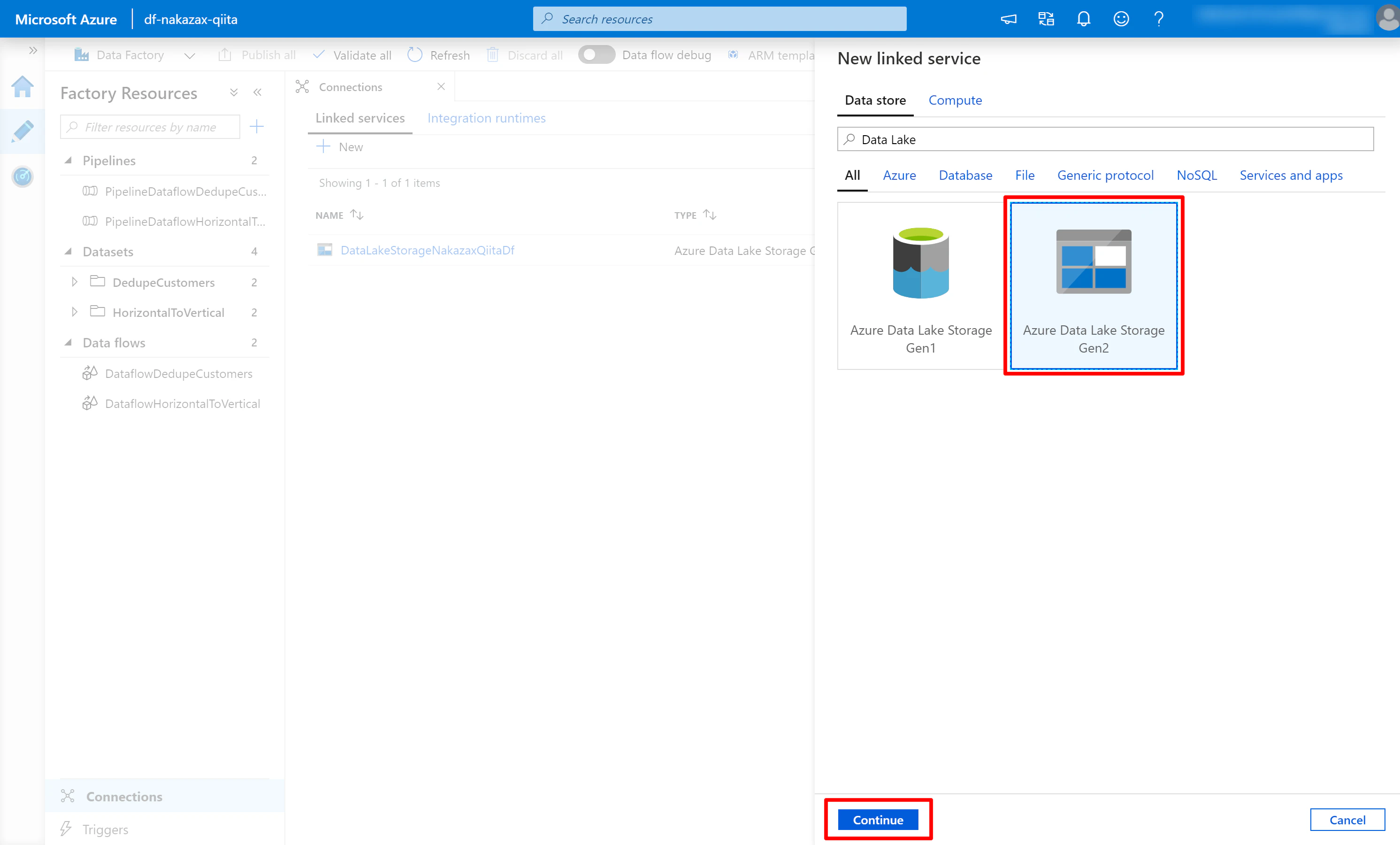
(2) 必要な項目を入力します。
- Name には任意の名前を入力、ここでは
DataLakeNakazaxQiitaDfを使用します - Account selection method で [From Azure subscription] にチェックします
- [Azure subscription] に対象の Azure サブスクリプションを選択
- [Storage account name] に対象のストレージアカウント名を選択
- 他の項目を必要に応じて編集した後、画面下部の [Test connection] をクリックし、Connection successful と表示されたら [Create] をクリック
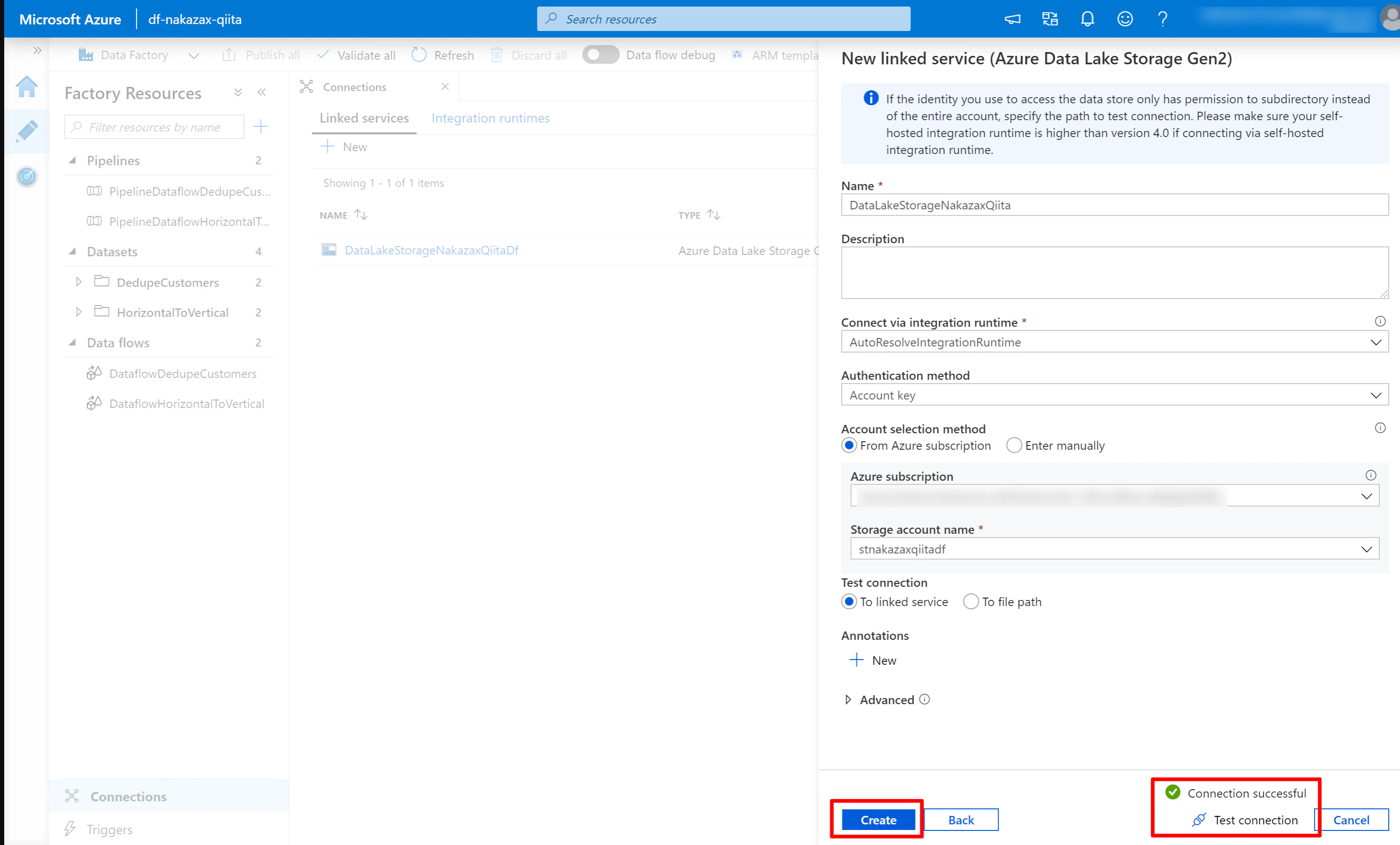
以上で Data Lake Storage の接続設定は完了です。
2. Datasets
接続情報を設定したら、次に Datasets を設定していきます。
2-1. Cosmos DB
(1) 画面左側の Datasets にフォーカスを当てると [...] と表示されるので [New dataset] をクリックします。
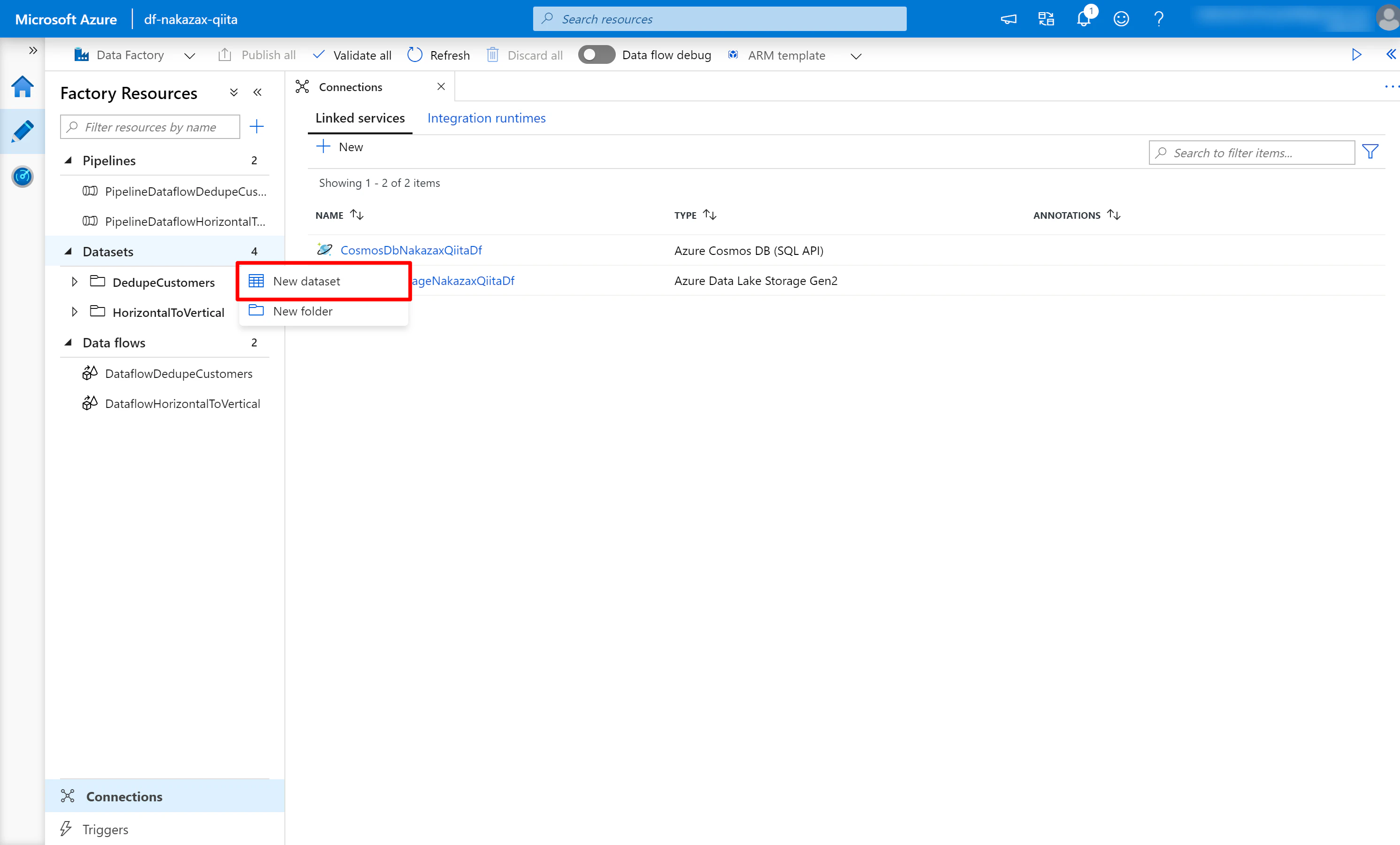
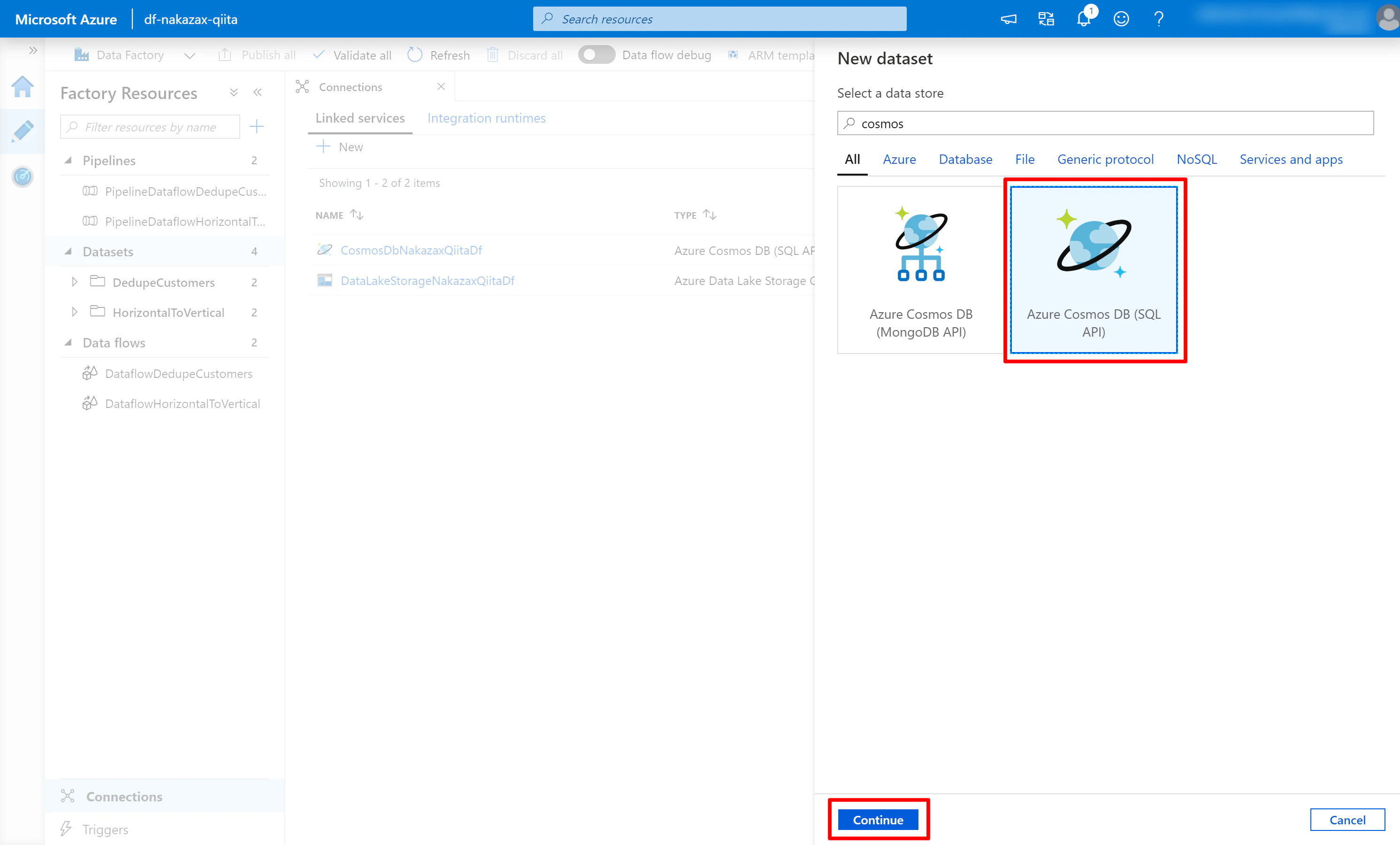
(2) 検索キーワードに cosmos などと入力し [Azure Cosmos DB (SQL API)] を選択して [Continue] をクリックします。
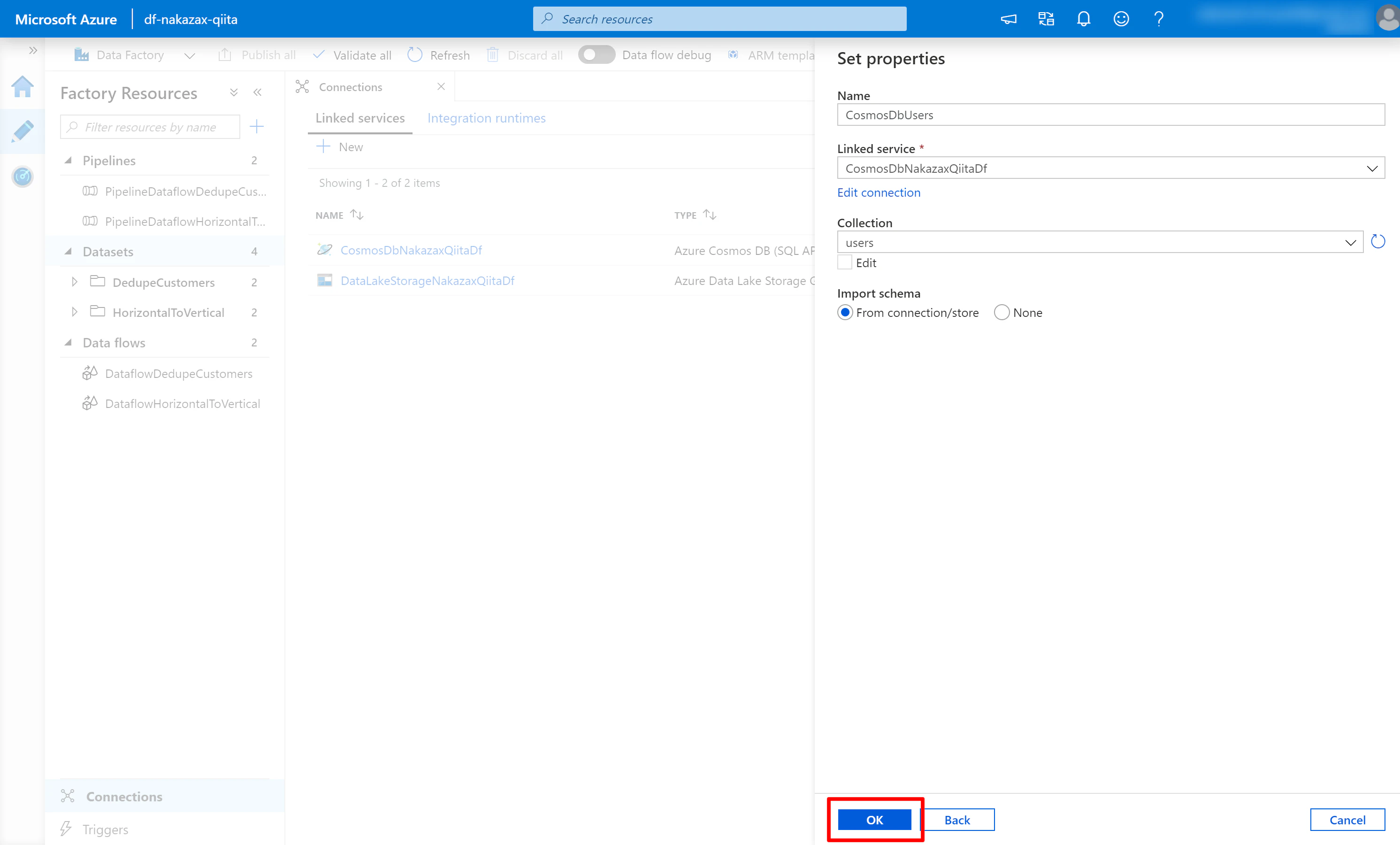
(3) 必要な項目を入力し [OK] をクリックします。
- Name には任意の名前を入力、ここでは
CosmosDbUsersを使用します - Linked service で先に作成したものを選択、ここでは
CosmosDbNakazaxQiitaDfを使用します - Collection に対象の Cosmos DB コレクションを選択します
- Import schema で [From connection/store] にチェックします
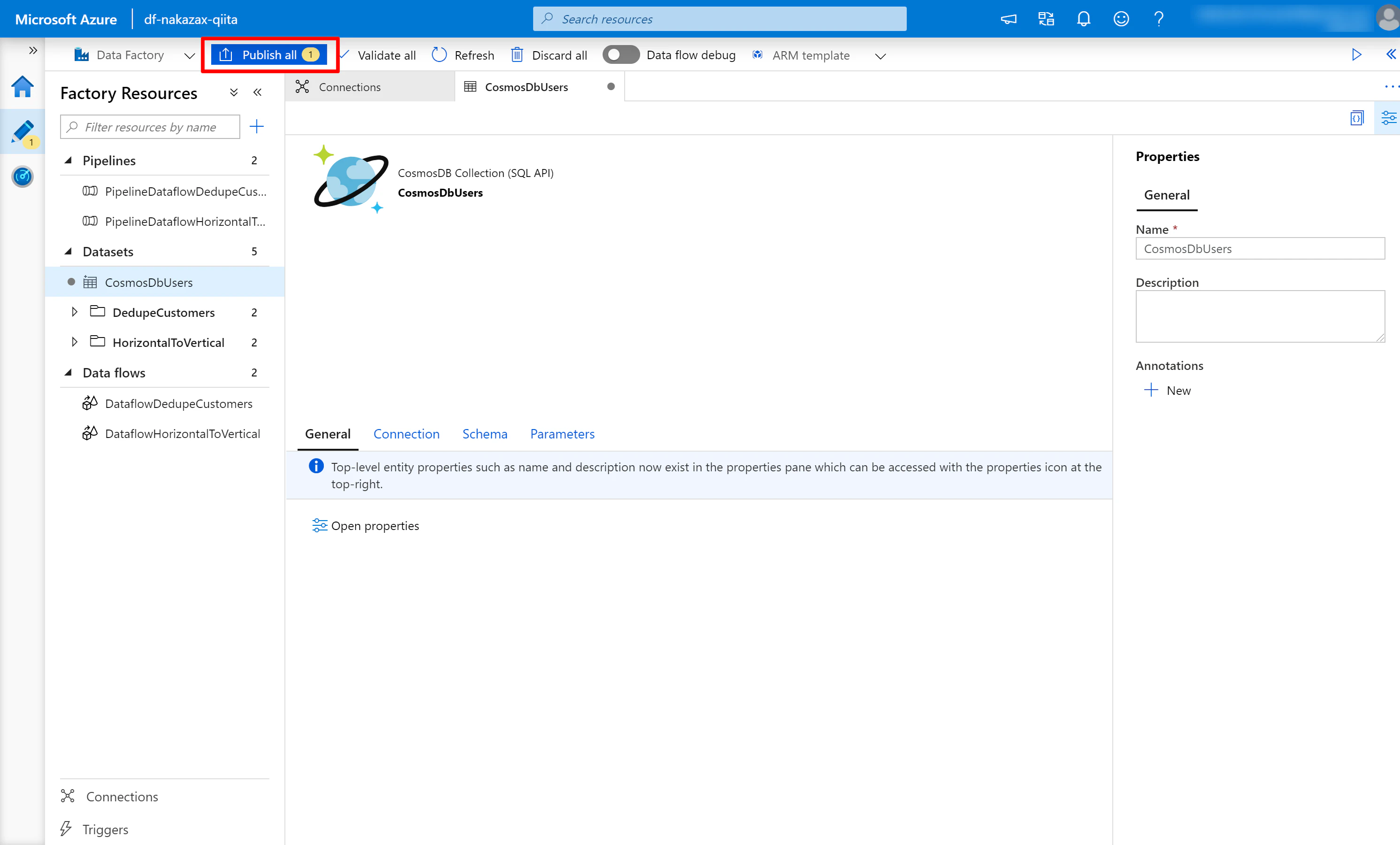
(Tips) Publish all について
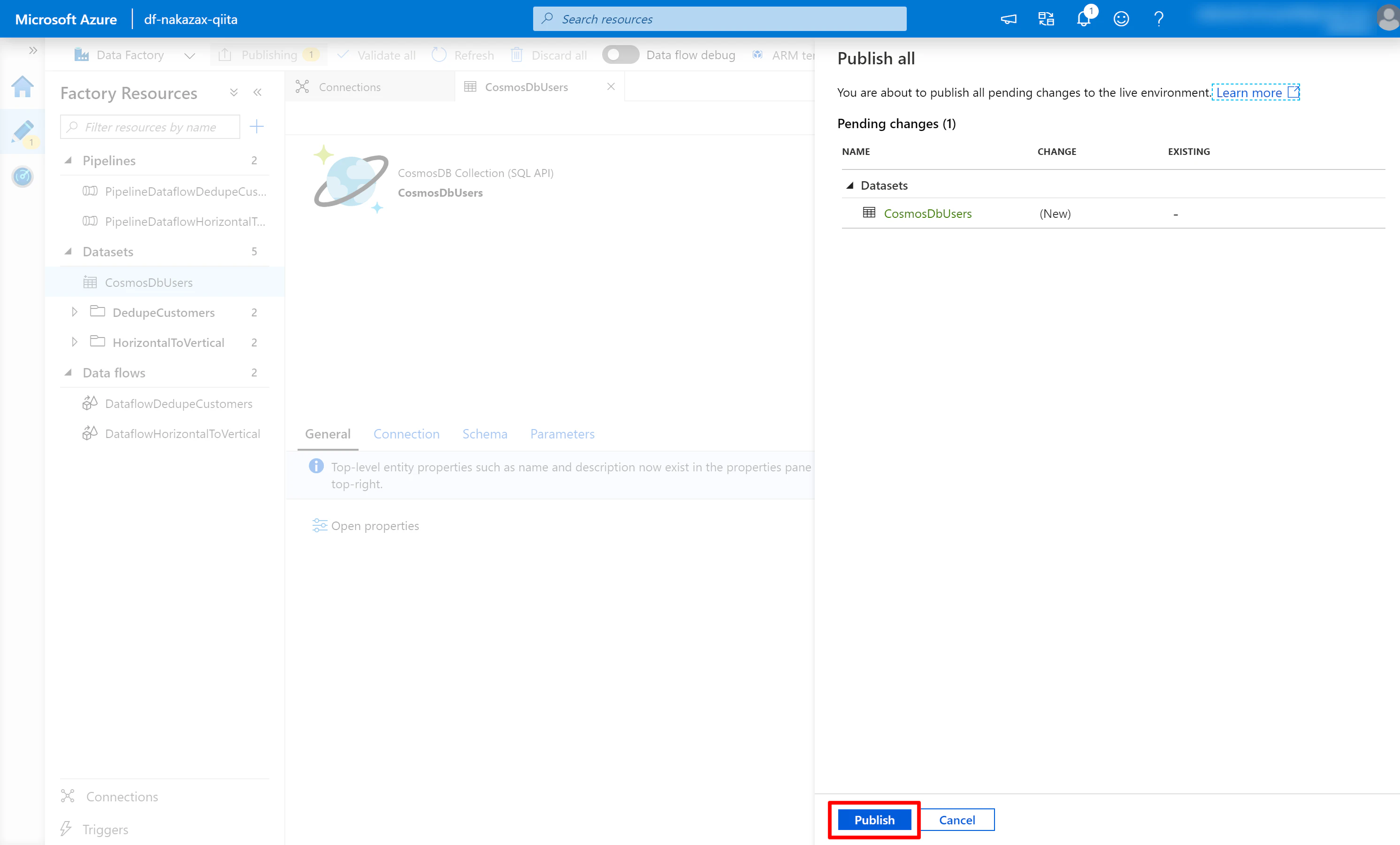
Data Factory 上で何かしらの変更を行うと画面左上の [Publish all] の横に数字が表示されます。この数字は、保存されていない変更の数を表しています。この状態でブラウザをリフレッシュすると変更が破棄されてしまいます。変更を保存するために、キリの良いタイミングで [Publish all] を押すようにしましょう。
2-2. Data Lake Storage
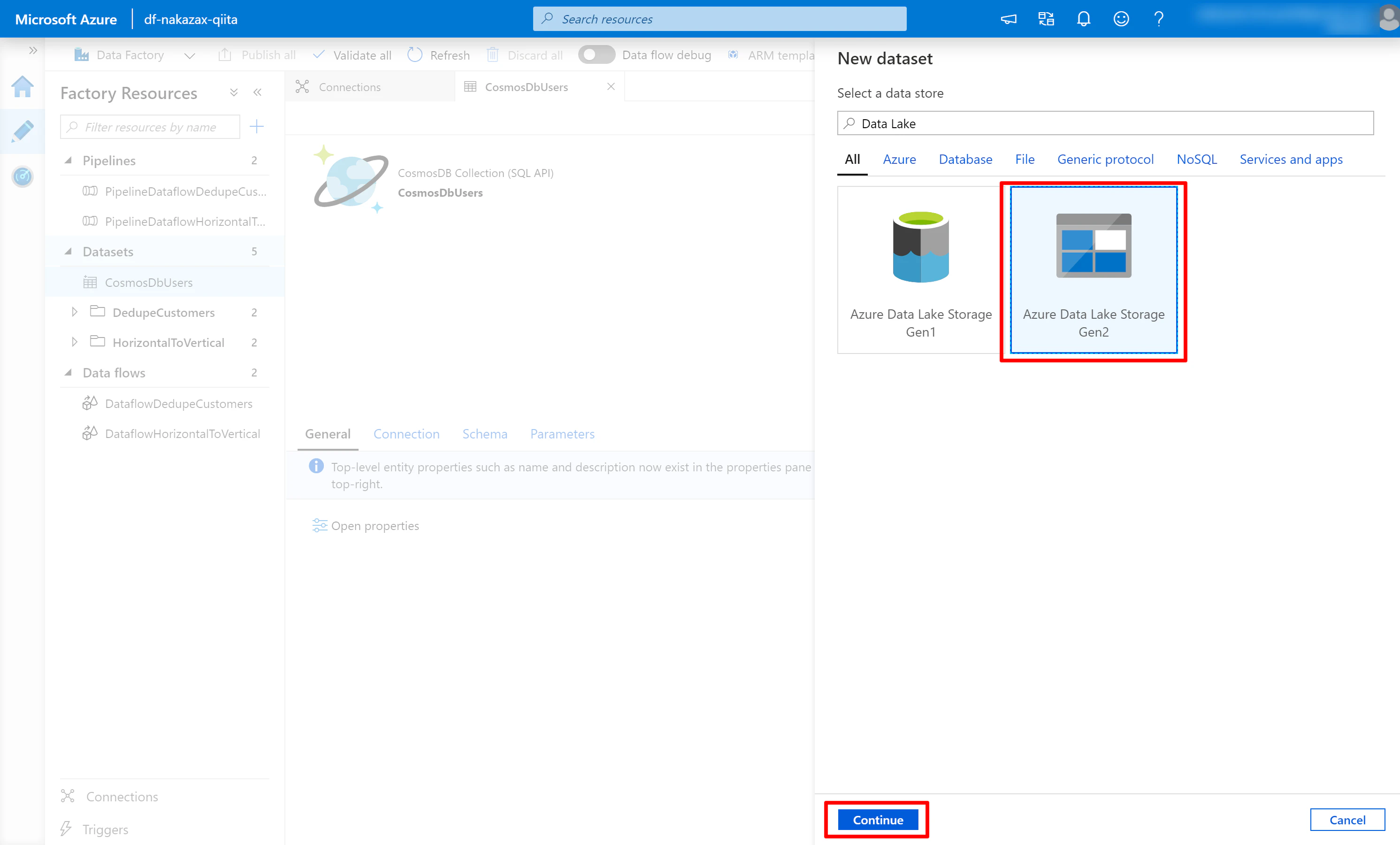
(1) 画面左側の Datasets にフォーカスを当てると [...] と表示されるので [New dataset] をクリックします。検索キーワードに Data Lake などと入力し [Azure Data Lake Storage Gen2] を選択して [Continue] をクリックします。
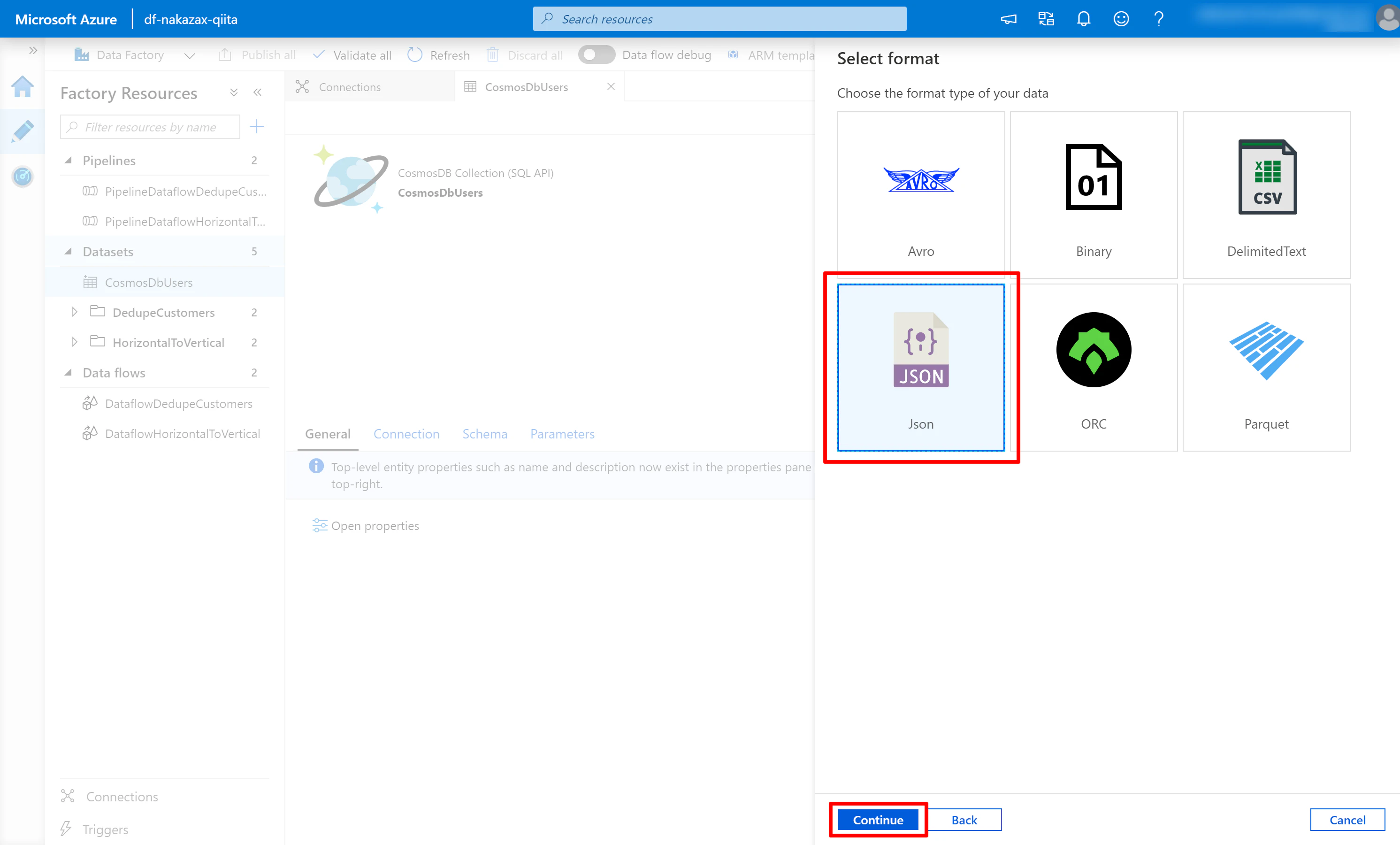
(2) [Json] を選択して [Continue] をクリックします。
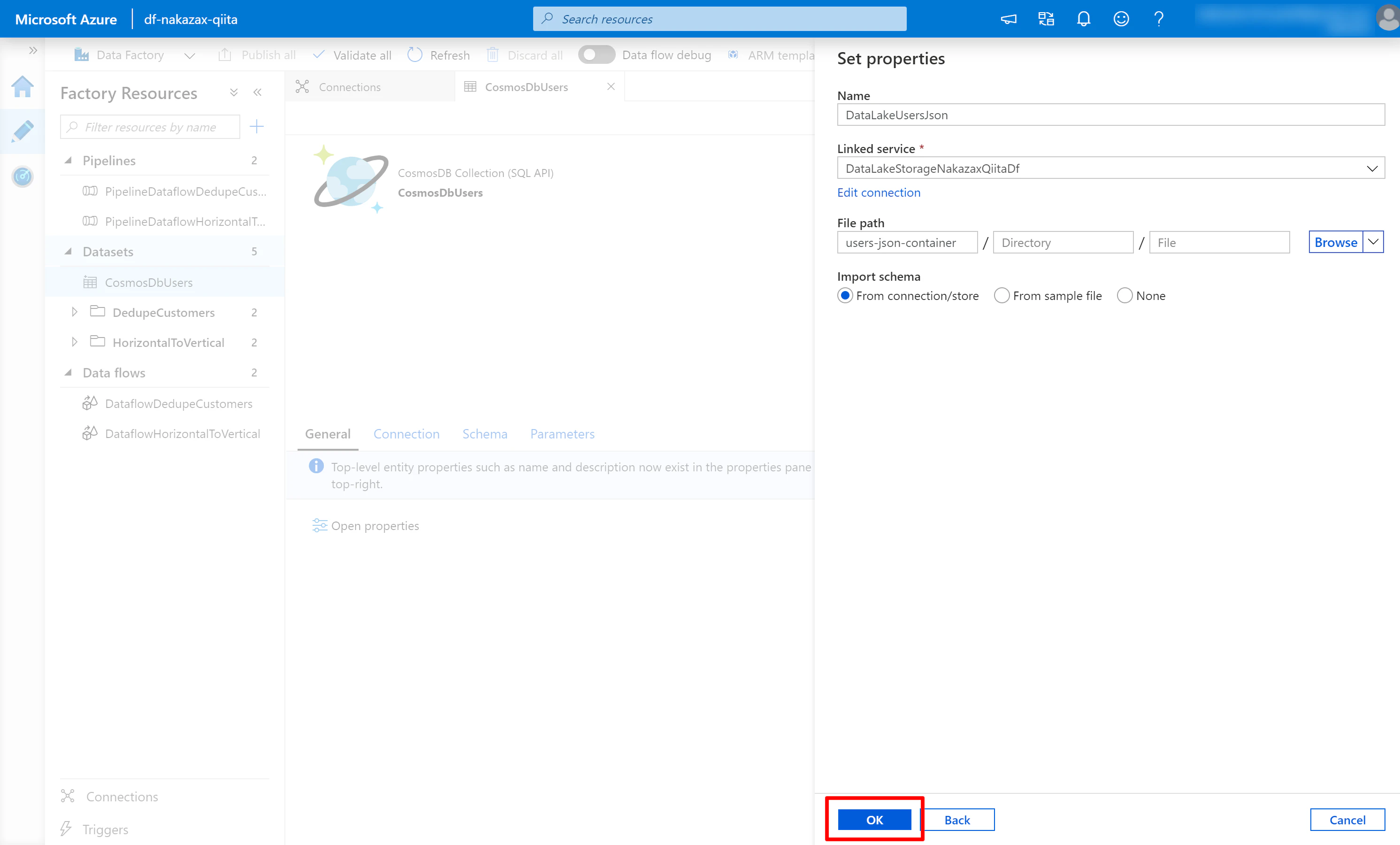
(3) 必要な項目を入力し [OK] をクリックします。
- Name には任意の名前を入力、ここでは
DataLakeUsersJsonを使用します - Linked service で先に作成したものを選択、ここでは
DataLakeStorageQiitaDfを使用します - File path の一番左のテキストボックスに Data Lake Storage のコンテナー名を入力します
- Import schema で [From connection/store] にチェックします
2-3. Data Lake Storage - Parameters
Dataset にはパラメーターを渡すことができます。ここでは、Data Lake Storage について year=2019/month=01/day=01 のように年月日をディレクトリのパスに入れるための設定をします。
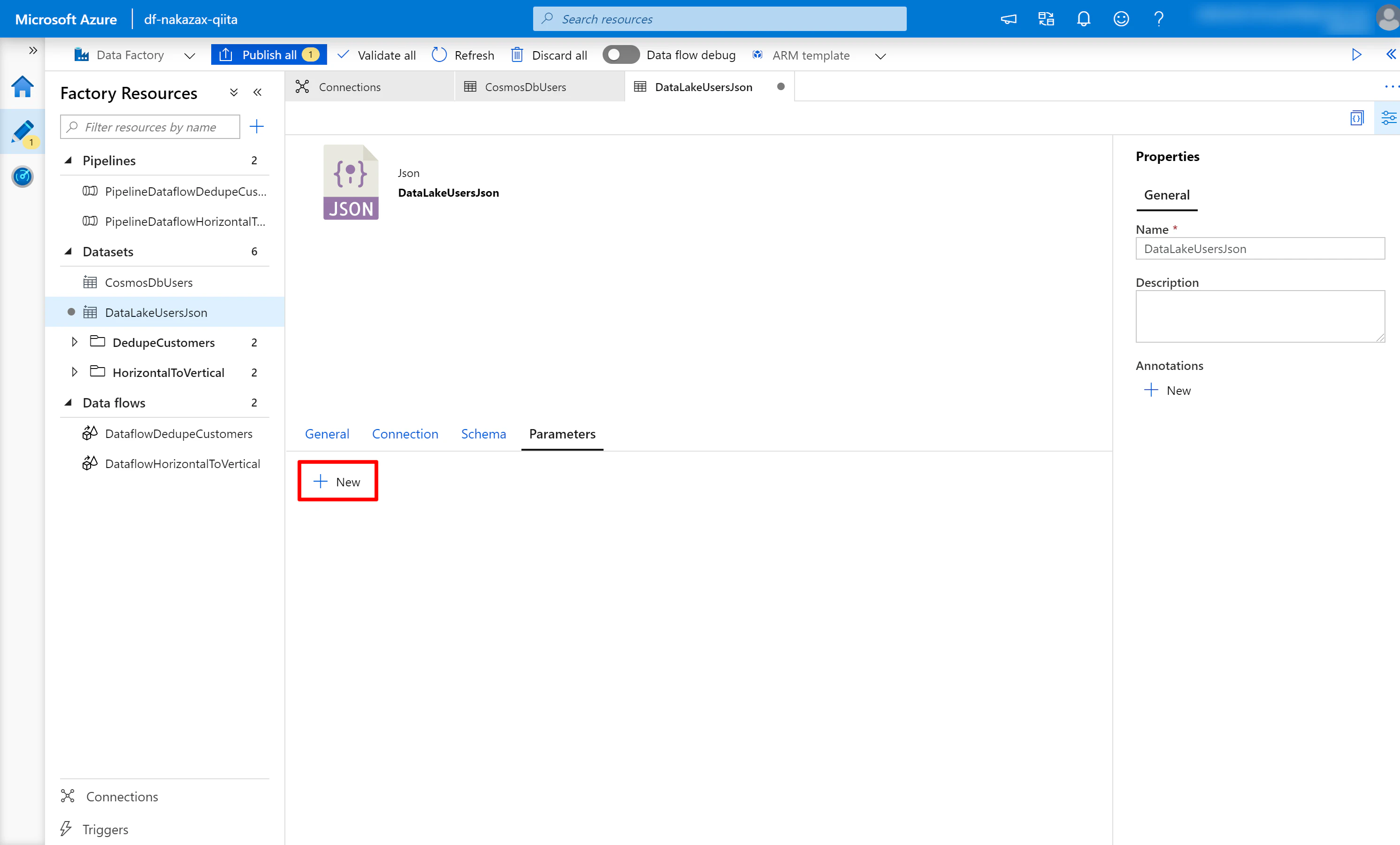
(1) 作成した Data Lake Storage の Dataset の [Parameters] タブの [New] をクリックします。
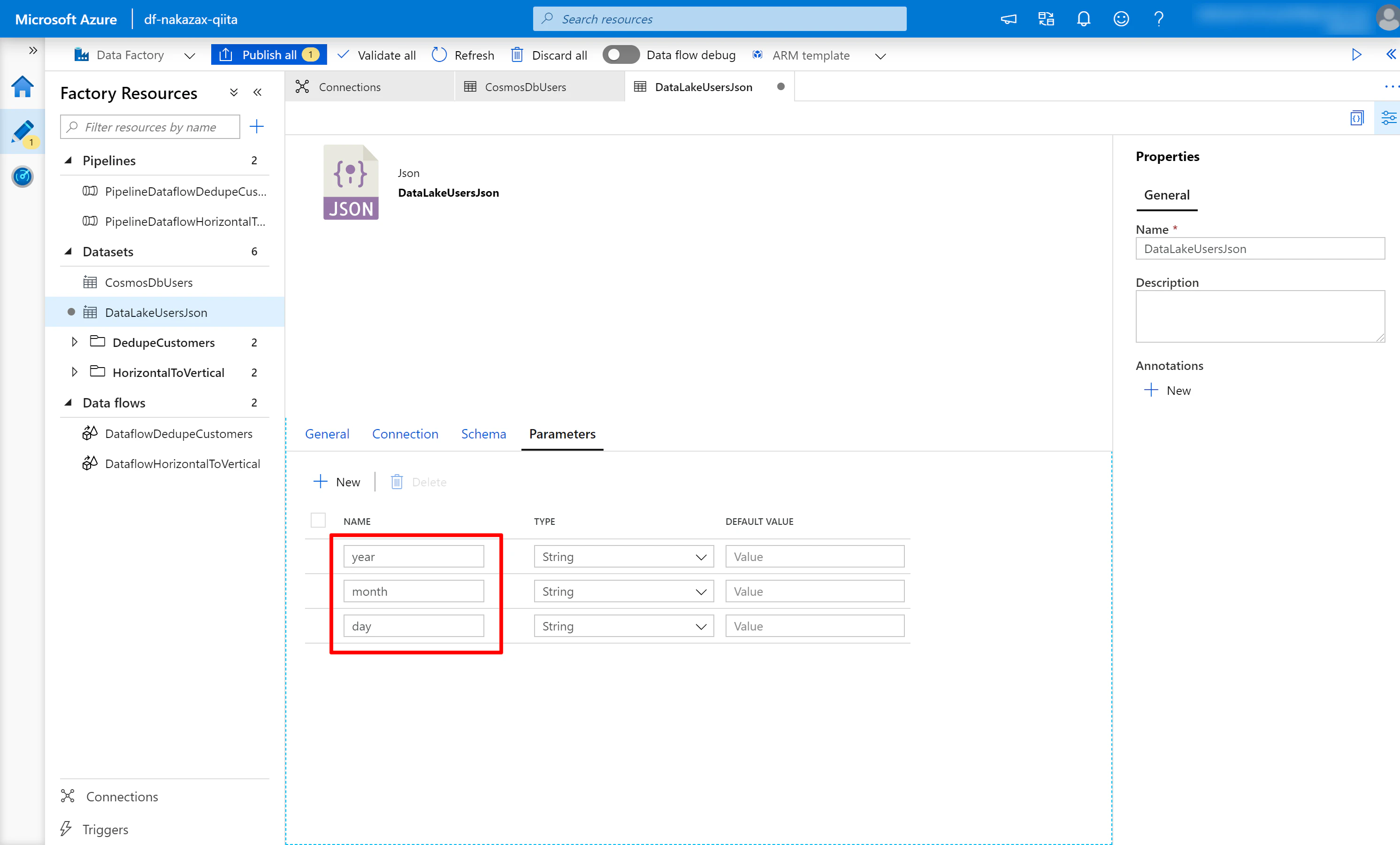
(2) 以下キャプチャのように year month day を定義します。
(3) [Connection] タブの Directory テキストボックスの下の Add dynamic content をクリックします。
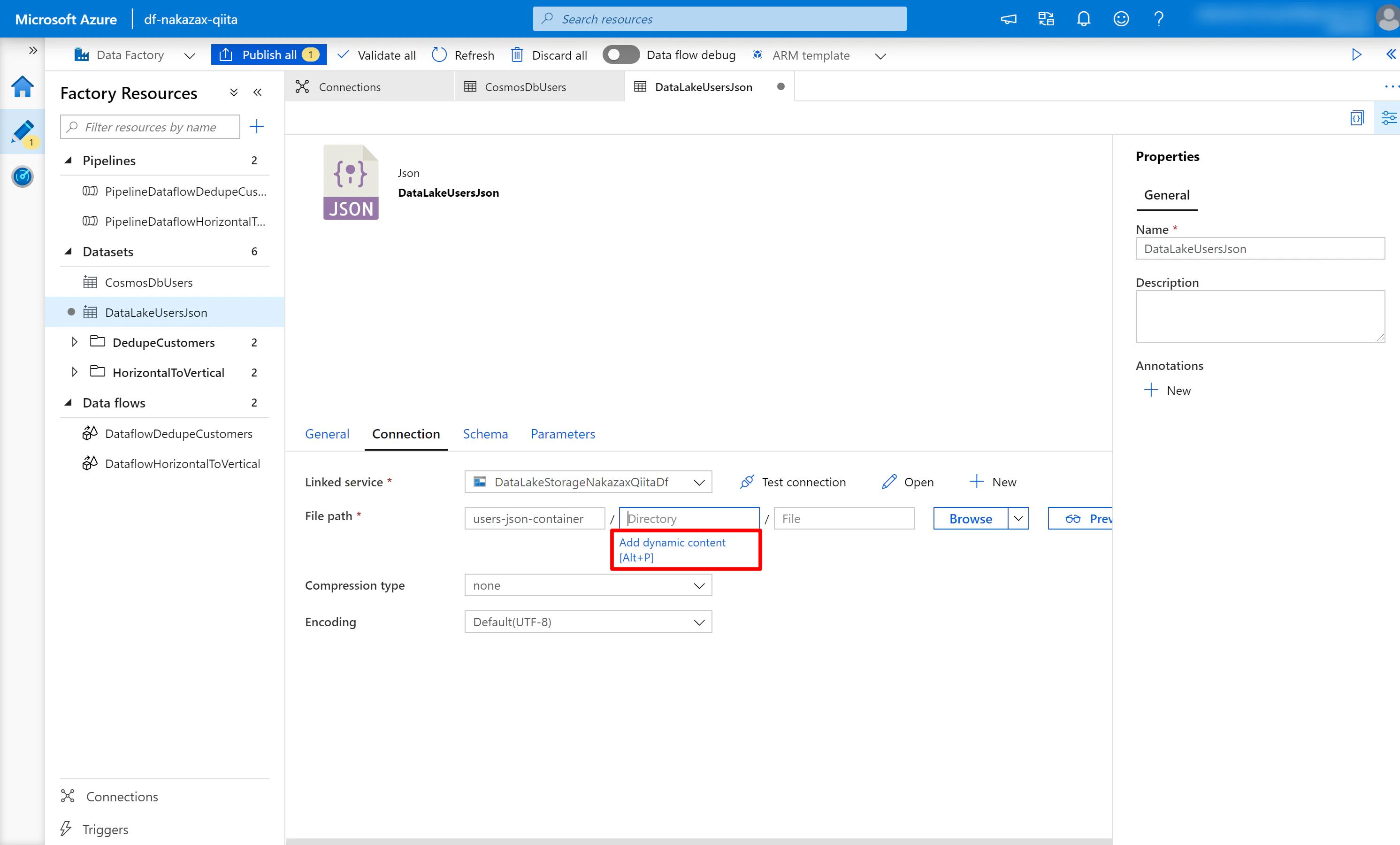
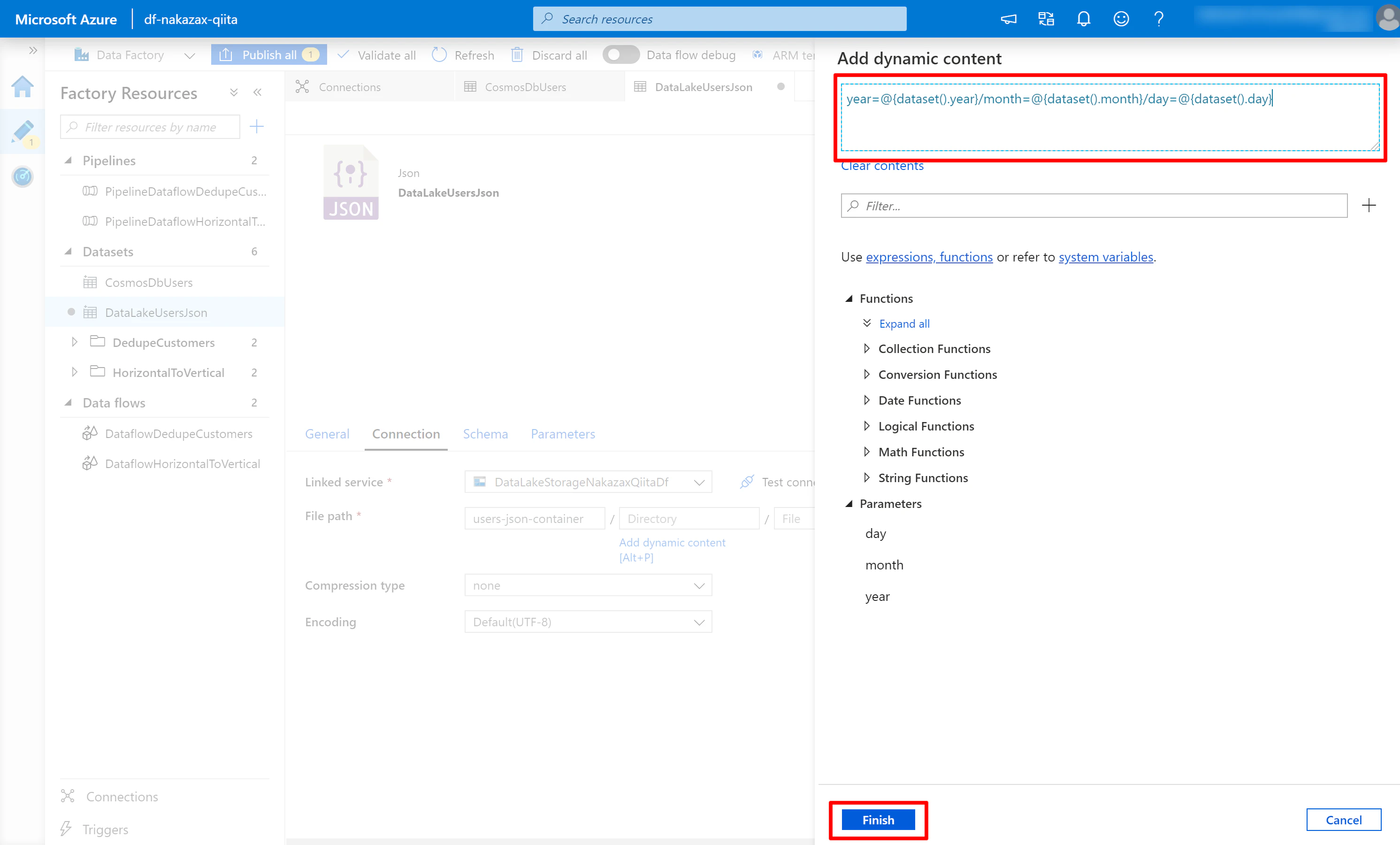
(4) 以下の内容を入力し [Finish] をクリックします。
year=@{dataset().year}/month=@{dataset().month}/day=@{dataset().day}
(5) [Connection] タブの File テキストボックスの下の Add dynamic content をクリックします。
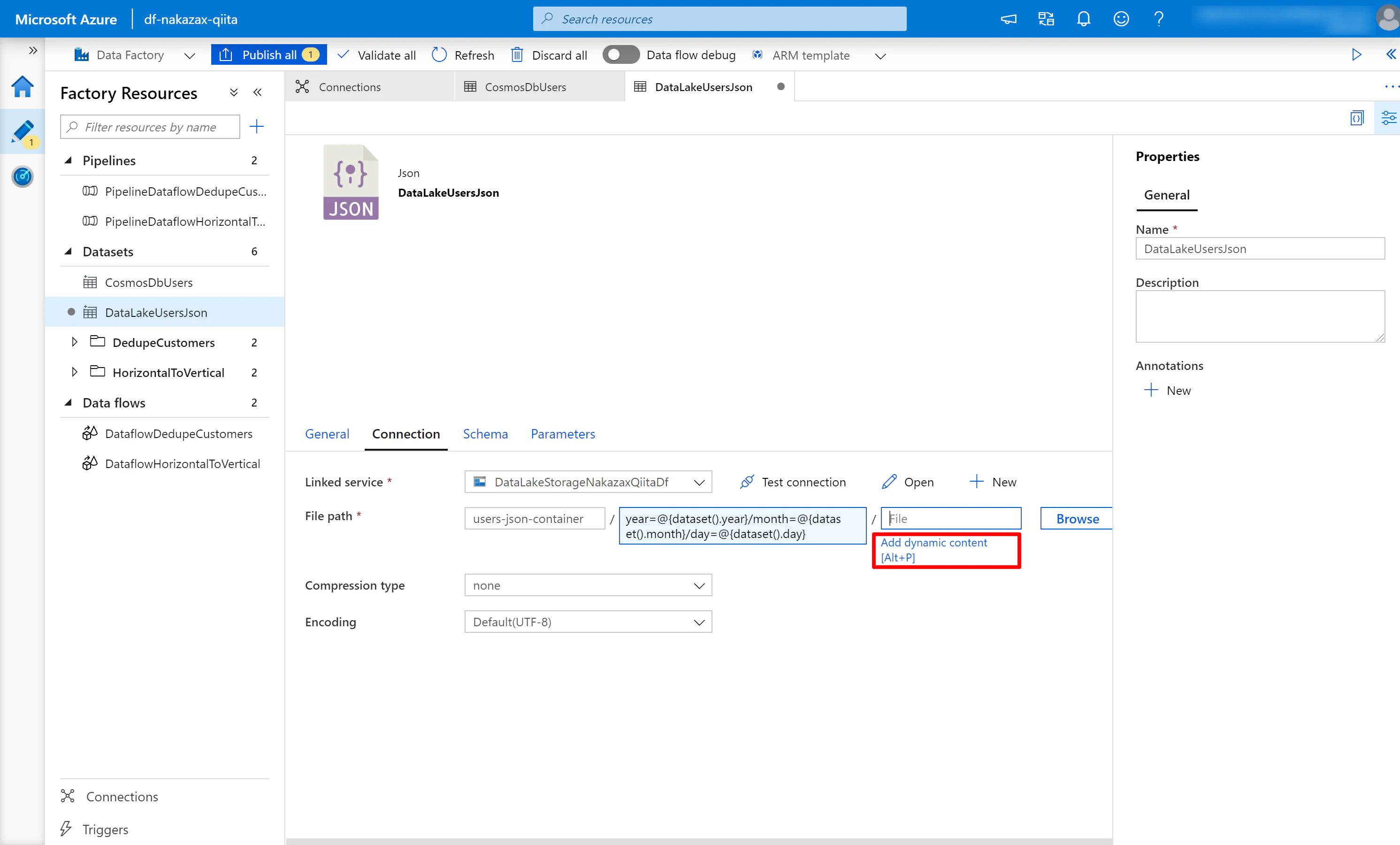
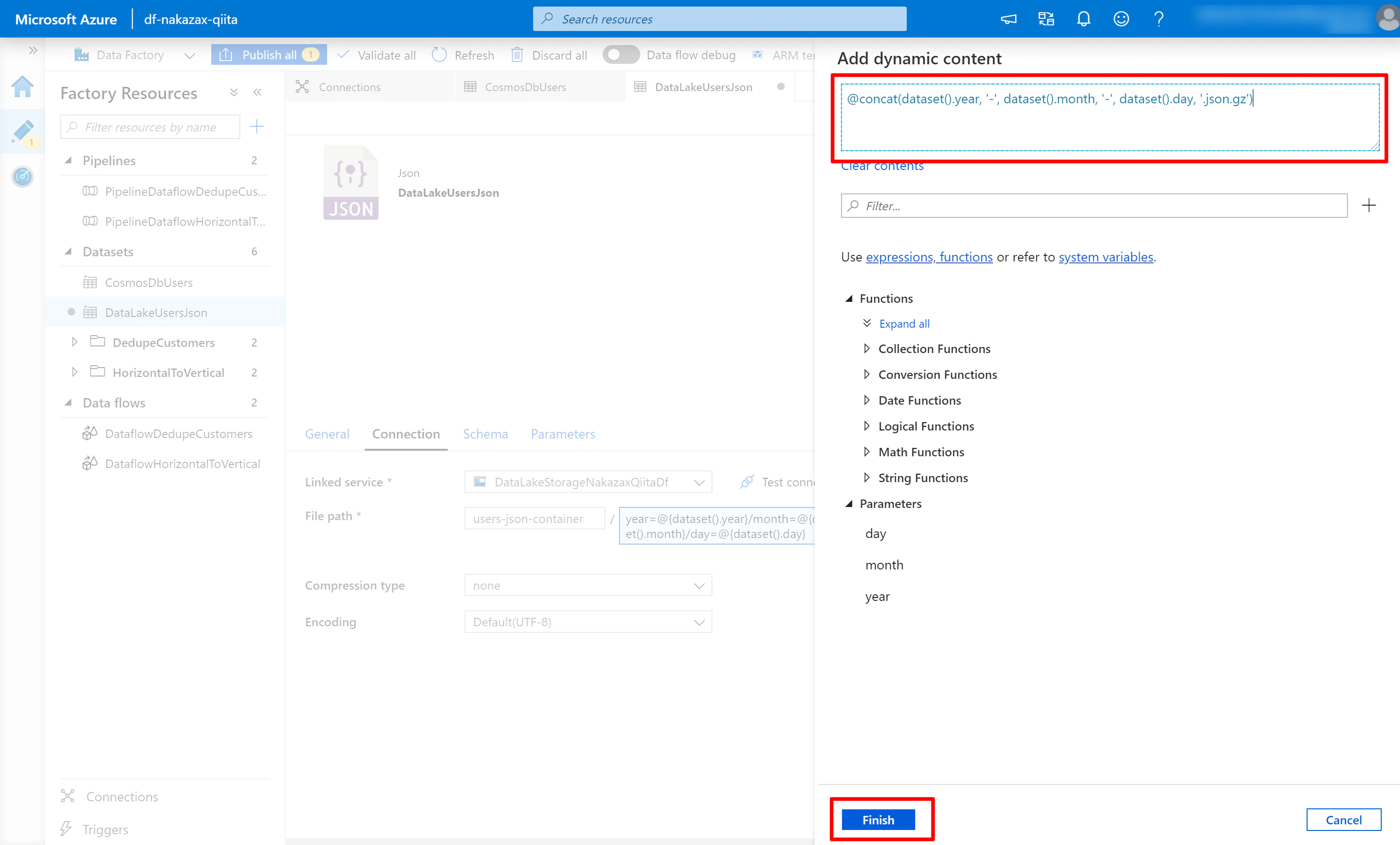
(6) 以下の内容を入力し [Finish] をクリックします。
@concat(dataset().year, '-', dataset().month, '-', dataset().day, '.json.gz')
(7) [Connection] タブの Compression type に [gzip] を選択します。
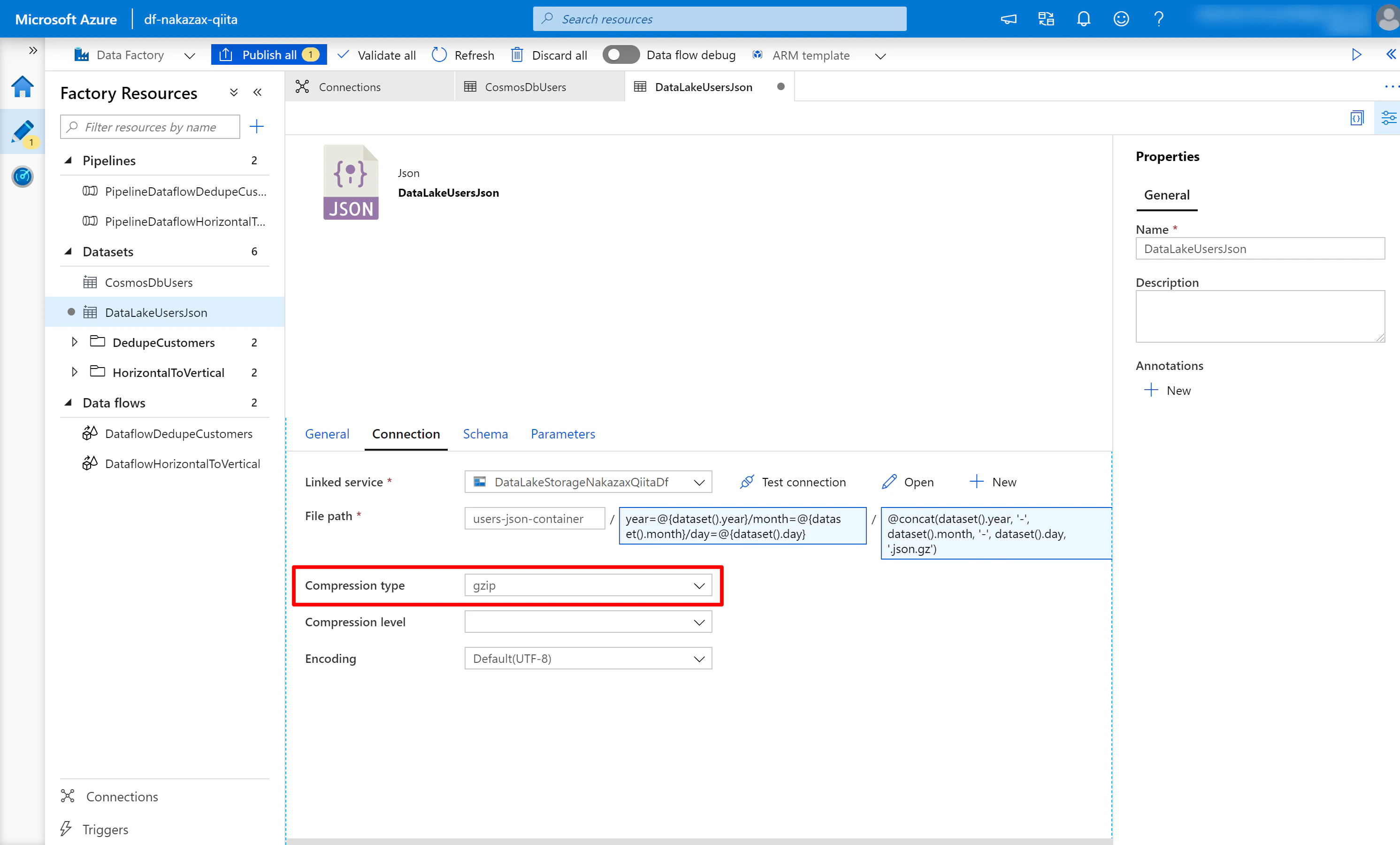
以上で Datasets の設定は完了です。
3. Pipelines
3-1. Pipeline 作成
(1) 画面左側の Pipelines にフォーカスを当てると [...] と表示されるので [New pipeline] をクリックします。
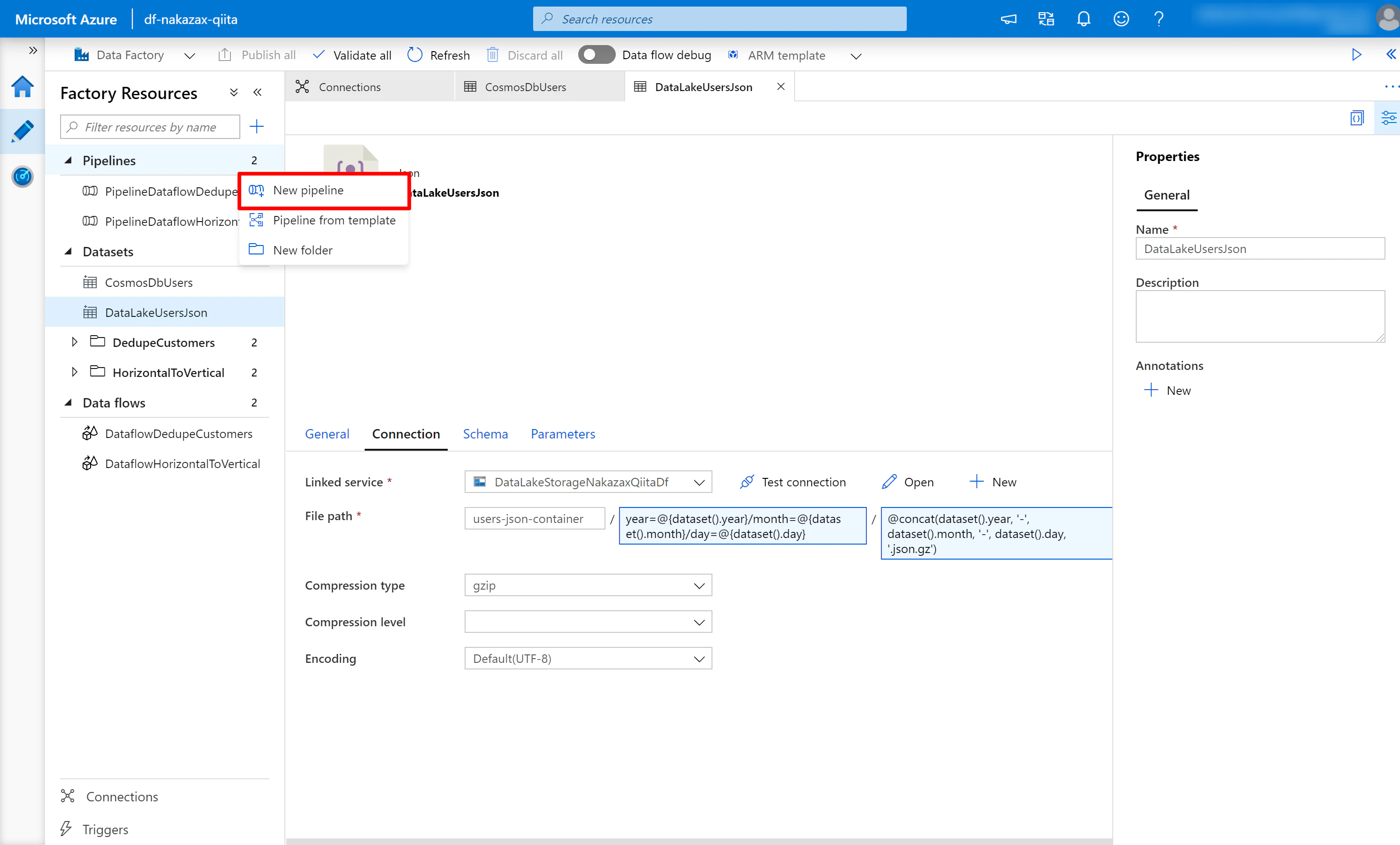
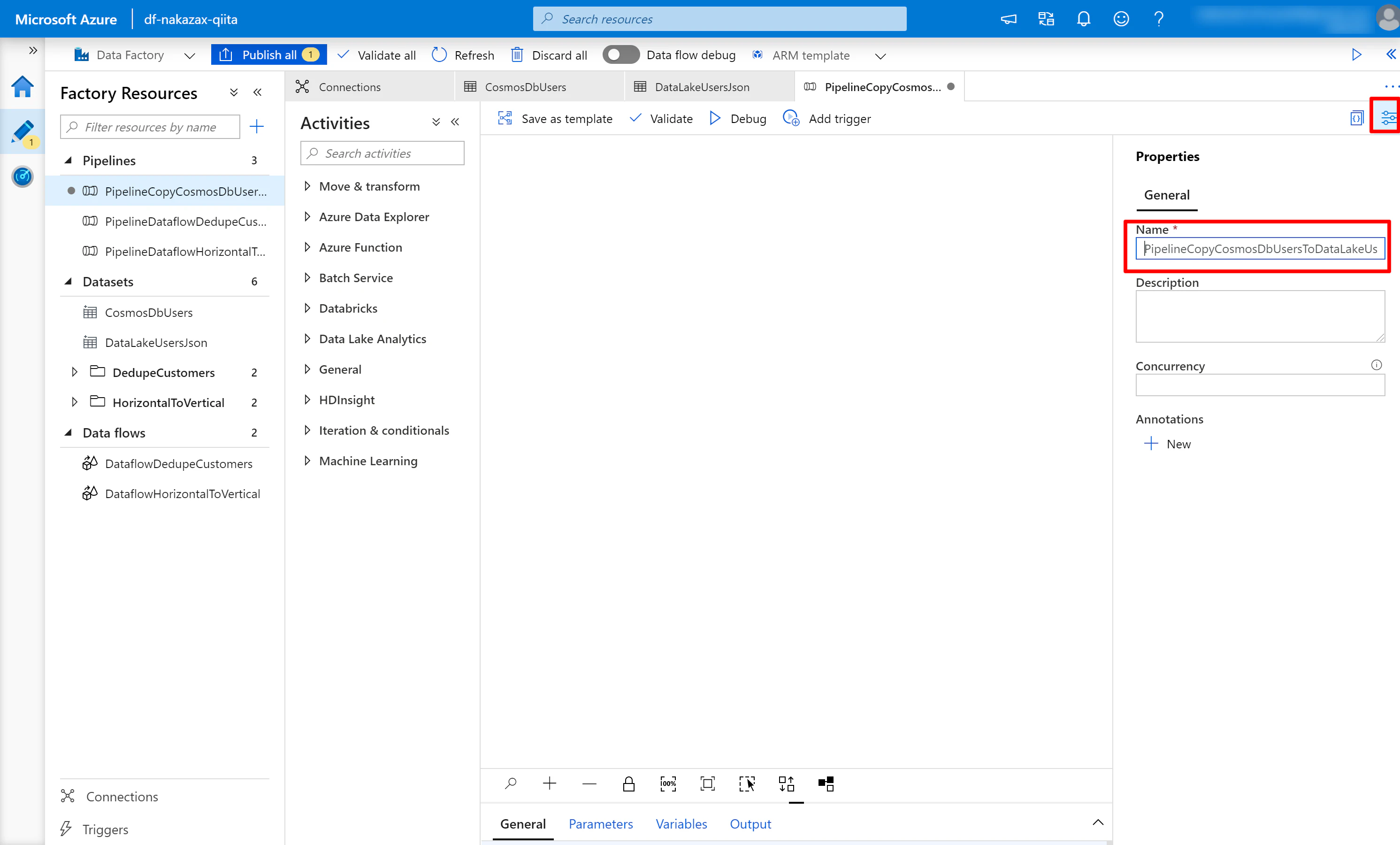
(2) Pipeline に分かりやすい名前を設定します。ここでは PipelineCopyCosmosDbUsersToDataLakeUsersJson という名前にしています。なお、赤枠で囲んだアイコンをクリックすると Properties の表示/非表示を切り替えられます。
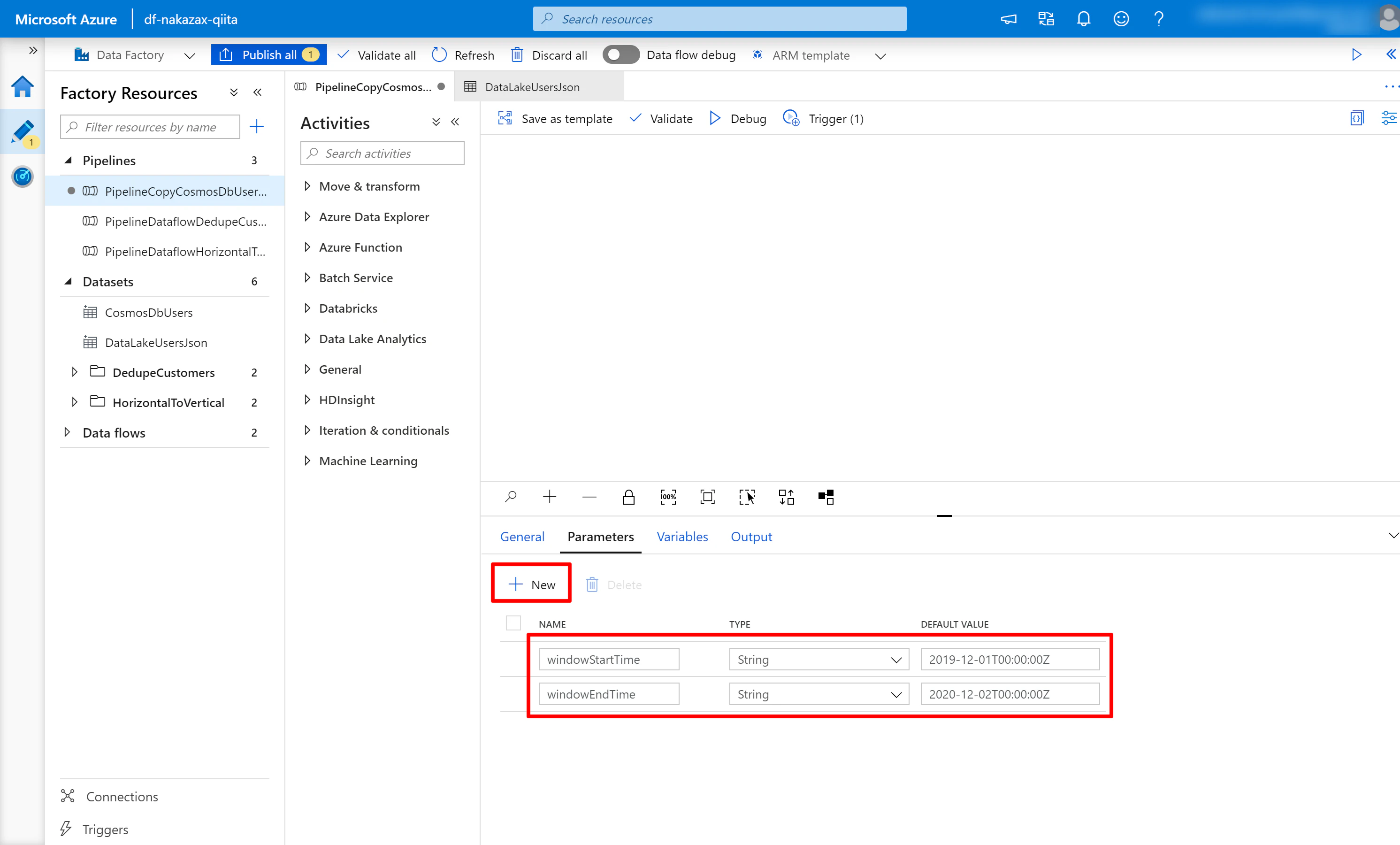
(3) [Paramters] タブを選択し [New] をクリックして以下のようにパラメーターを設定します。この2つのパラメーターは後ほど Cosmos DB へのクエリの WHERE 句で利用します。
3-2. Copy data アクティビティ 作成
(1) [Move & transform] を展開し [Copy data] を右側のスペースにドラッグ & ドロップします。
(2) Copy data アクティビティの [General] タブの Name に分かりやすい名前を設定します。ここでは CopyCosmosDbUsersToDataLakeUsersJson という名前にしています。
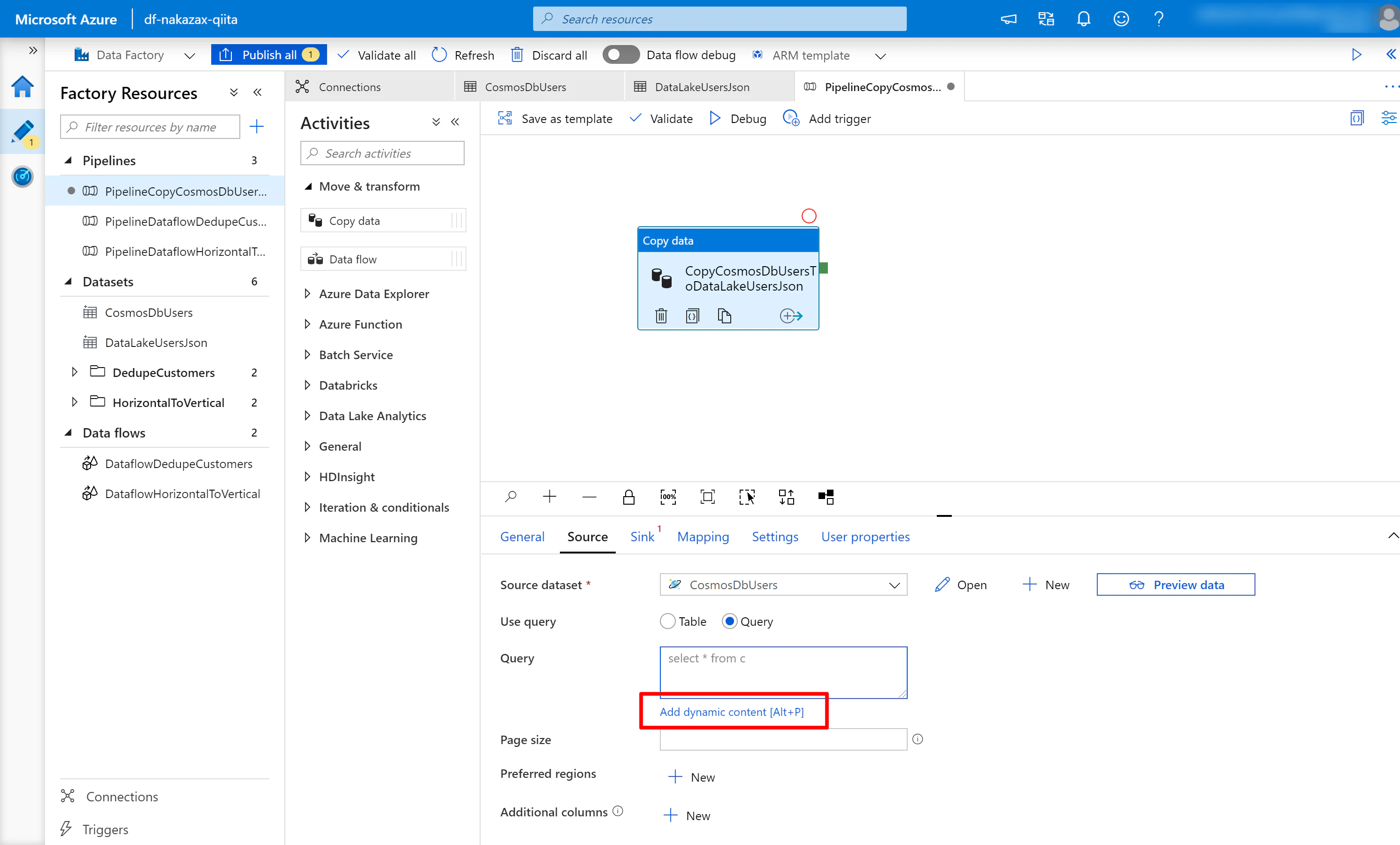
(3) [Source] タブの Query のテキストボックスの下の Add dynamic content をクリックします。
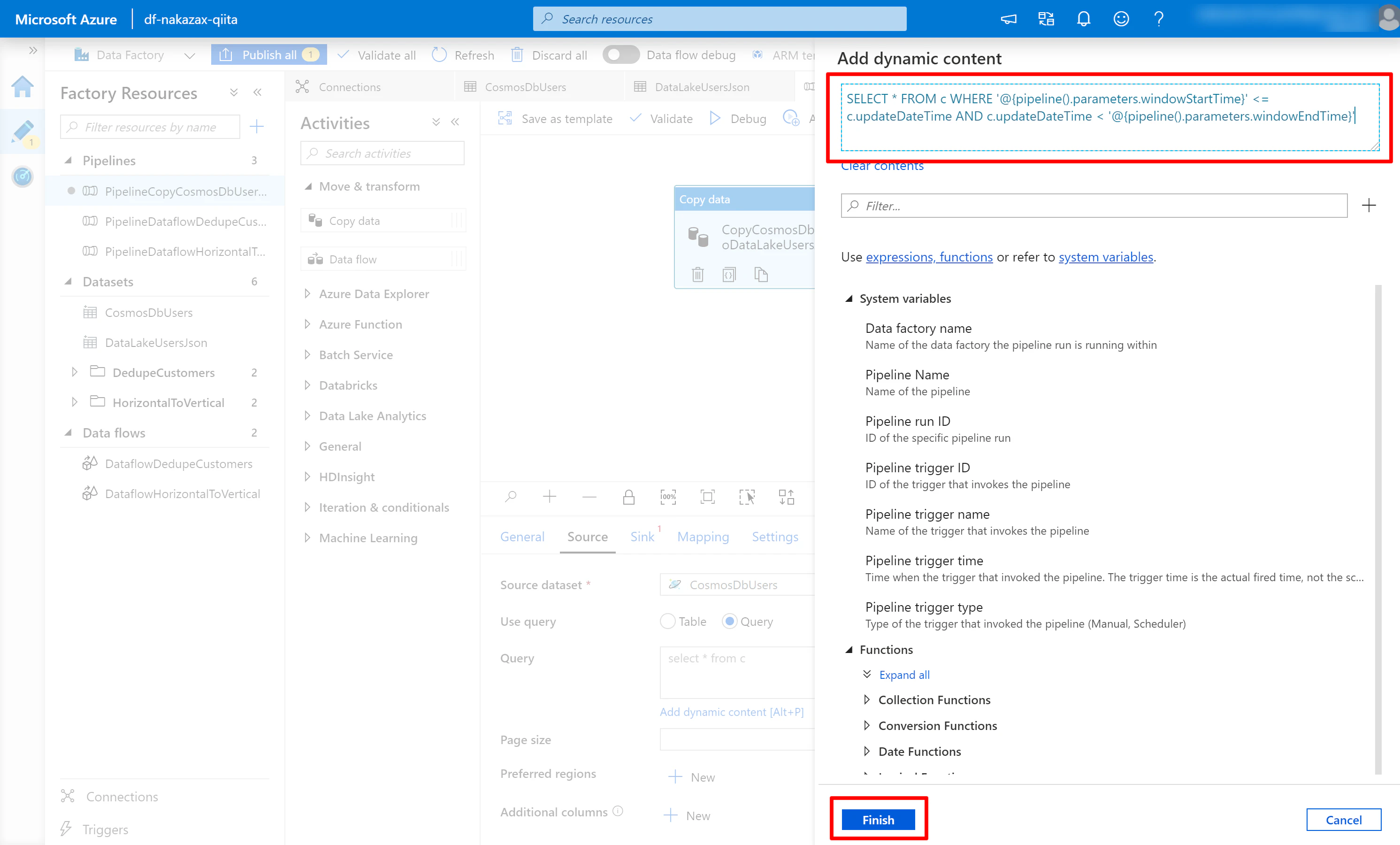
(4) 以下の内容を入力し [Finish] をクリックします。クエリの内容は Cosmos DB の項目に合わせて適宜修正ください。
SELECT * FROM c WHERE
'@{pipeline().parameters.windowStartTime}' <= c.updateDateTime
AND c.updateDateTime < '@{pipeline().parameters.windowEndTime}'
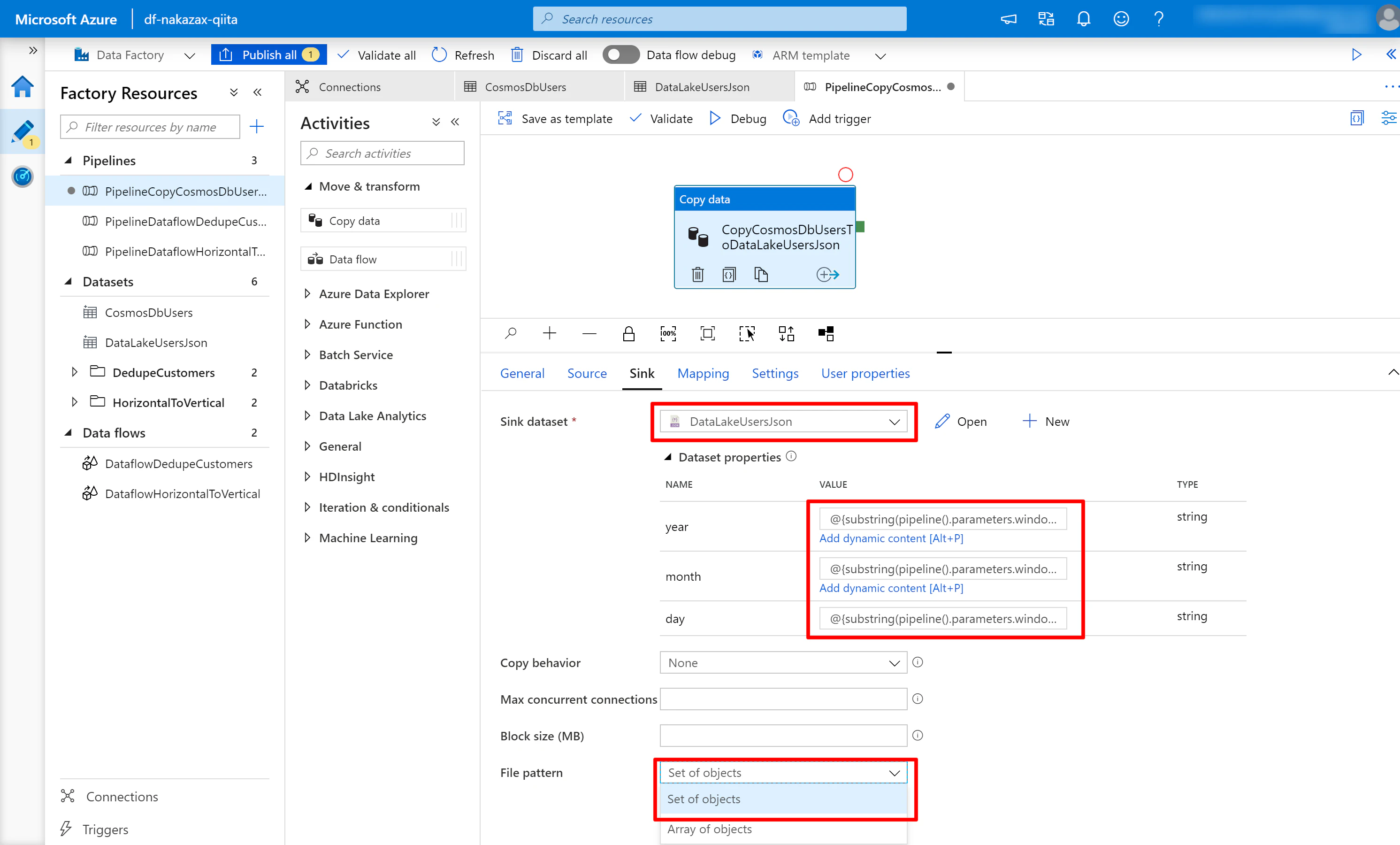
(5) [Sink] タブを以下のように設定します。
- Sink dataset に先に作成した Dataset
DataLakeUsersJsonを設定します - Dataset properties に以下の値を設定します
- year:
@{substring(pipeline().parameters.windowStartTime, 0, 4)} - month:
@{substring(pipeline().parameters.windowStartTime, 5, 2)} - day:
@{substring(pipeline().parameters.windowStartTime, 8, 2)}
- year:
- File pattern に
Set of objectsを指定します
上記のように指定することで、Pipeline のパラメーター windowsStartTime に 2019-12-01T00:00:00Z が指定された場合、year には 2019、month には 12、day には 01 が入ります。
また File pattern に Set of object を指定すると1行1JSONの形で出力されます。
以上で Pipeline の基本的な設定は完了です。
3-3. Debug 実行
Pipeline の設定が正しいかどうかを確認するためにパイプラインをデバッグ実行してみます。
(1) 赤枠の [Debug] をクリックします。
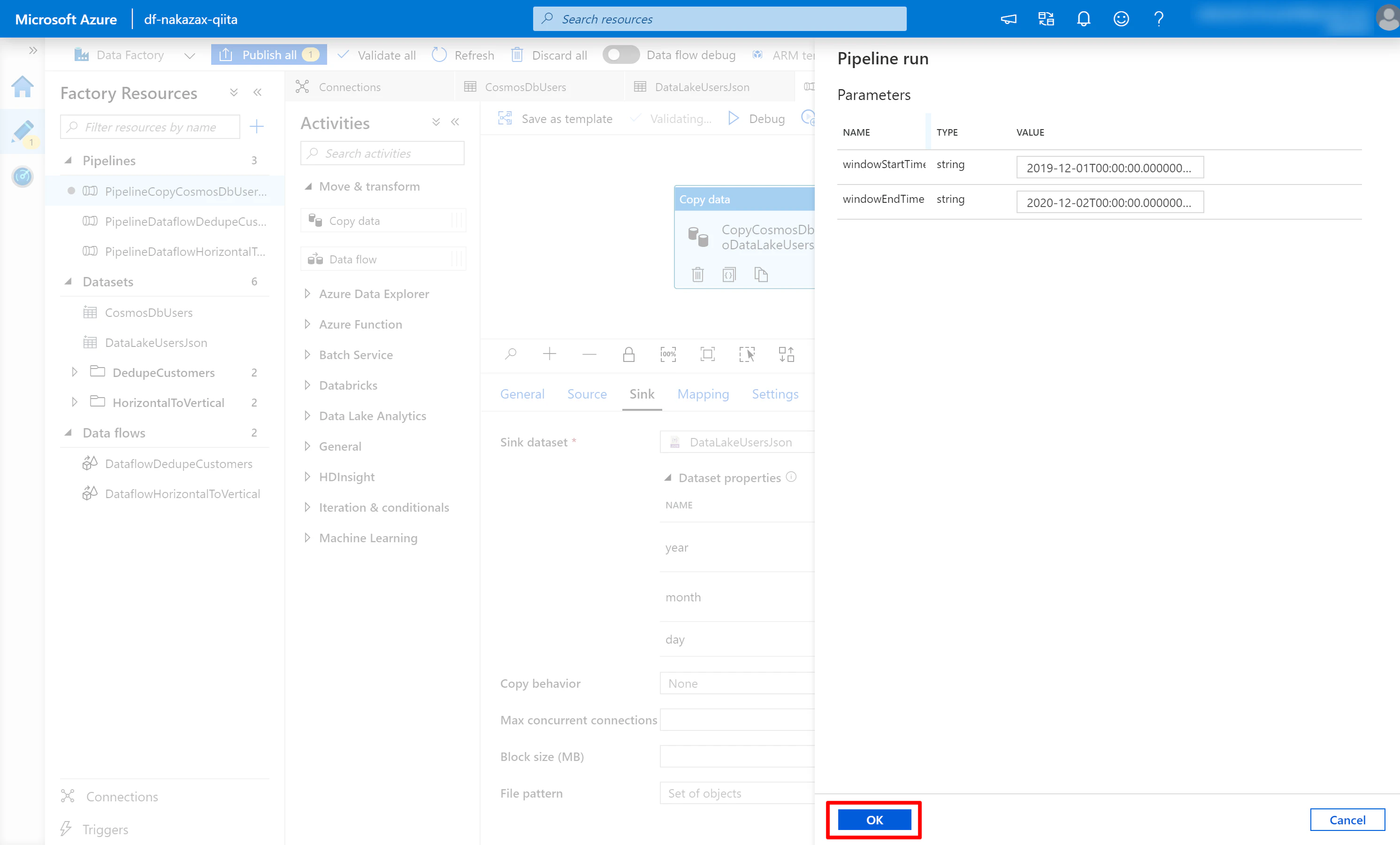
(2) Cosmos DB に存在する日付範囲をパラメーターに指定して [OK] をクリックします。これによりパイプラインのデバッグ実行が開始されます。
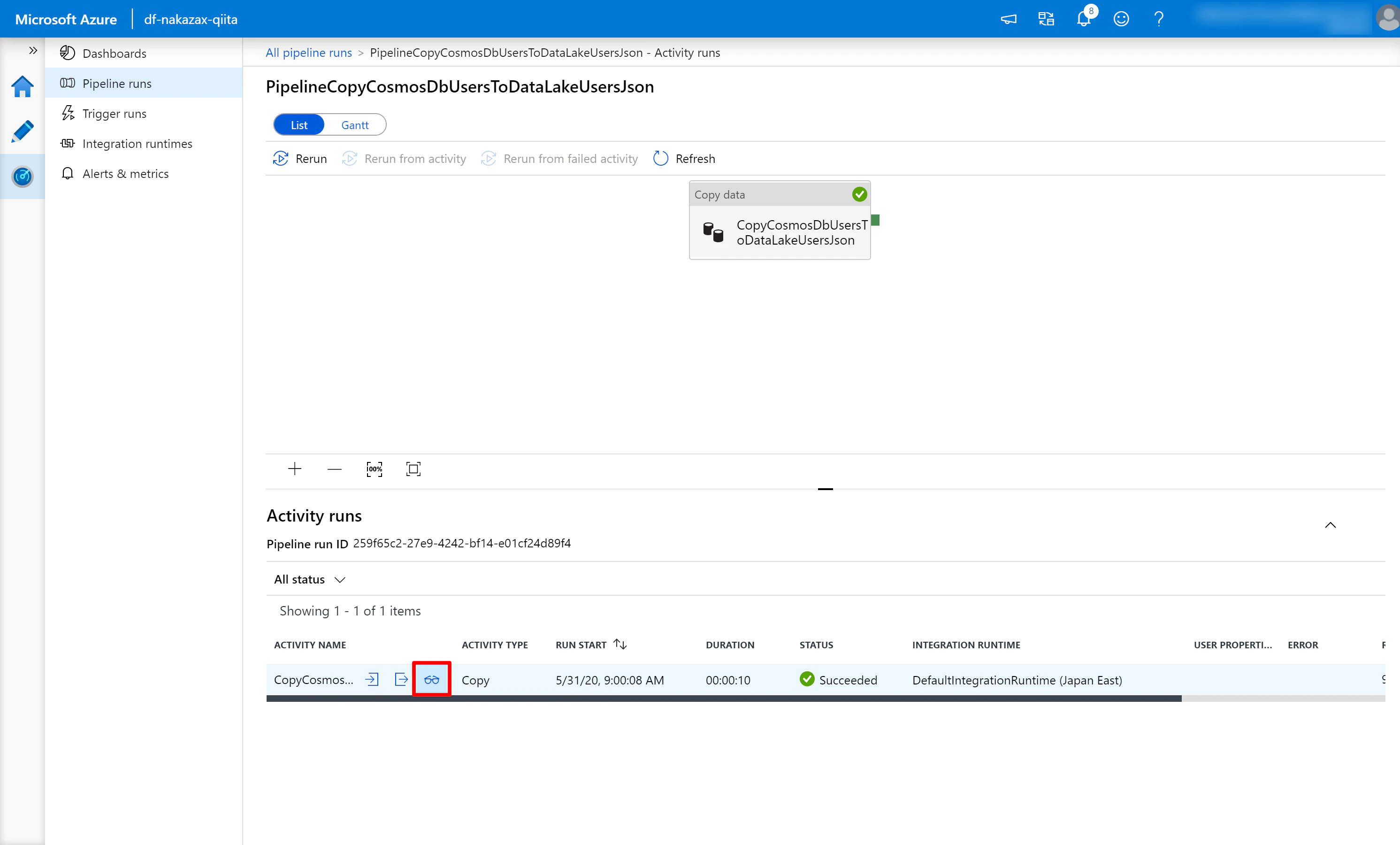
(3) 進捗状況を確認するため赤枠部分を適宜クリックします。
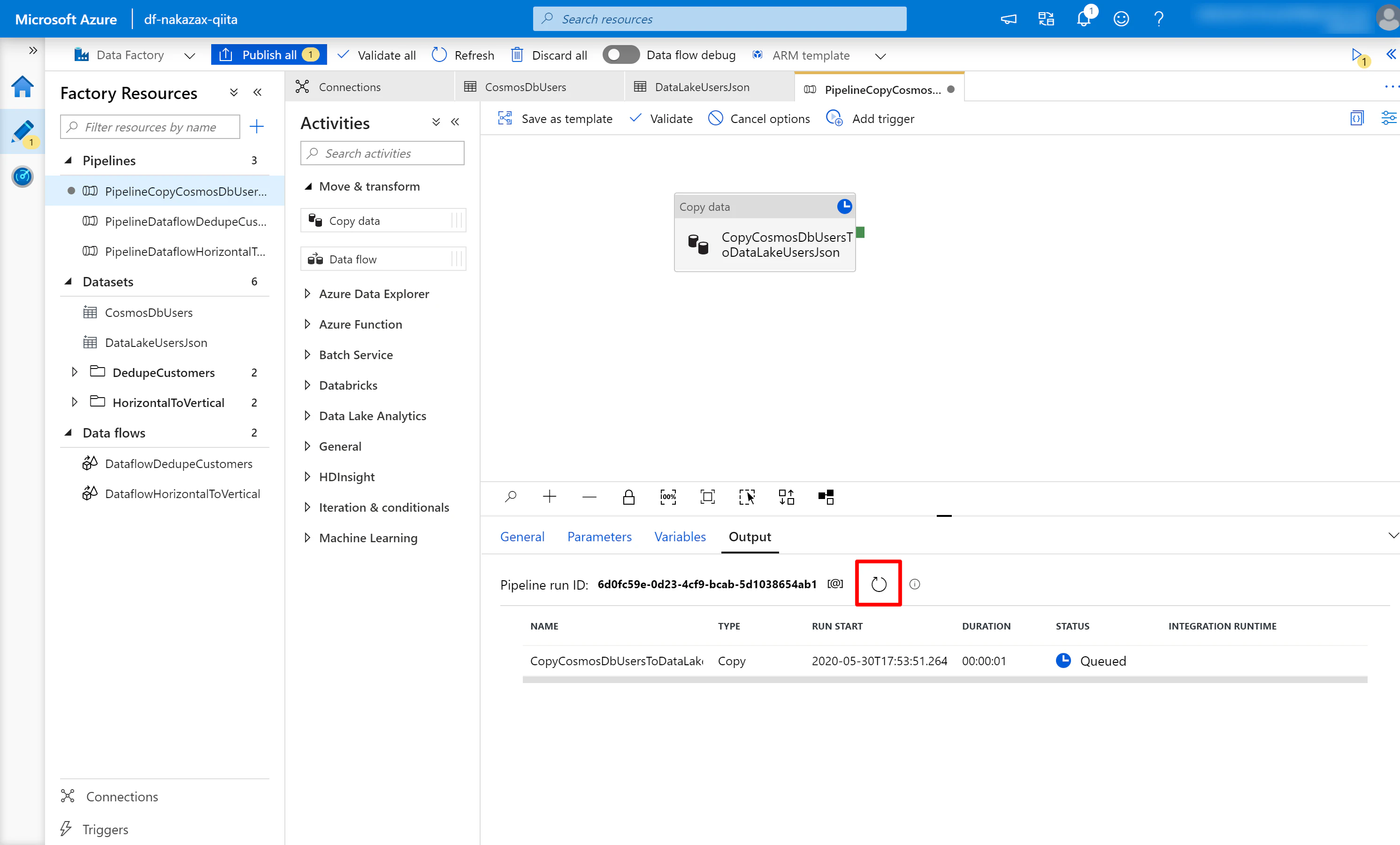
(4) STATUS が Succeeded になったら NAME にフォーカスを合わせて赤枠で囲んだ眼鏡マークをクリックします。
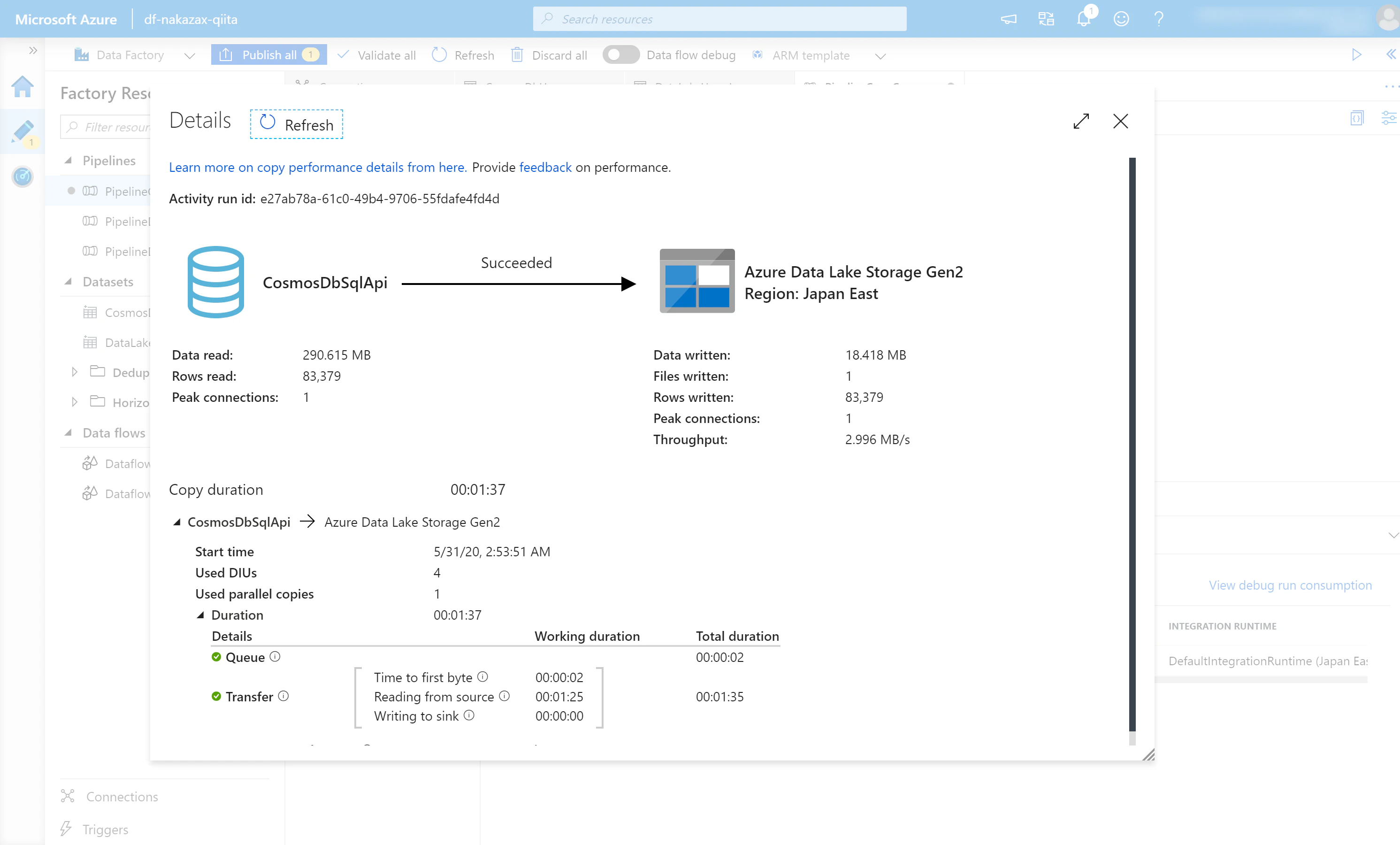
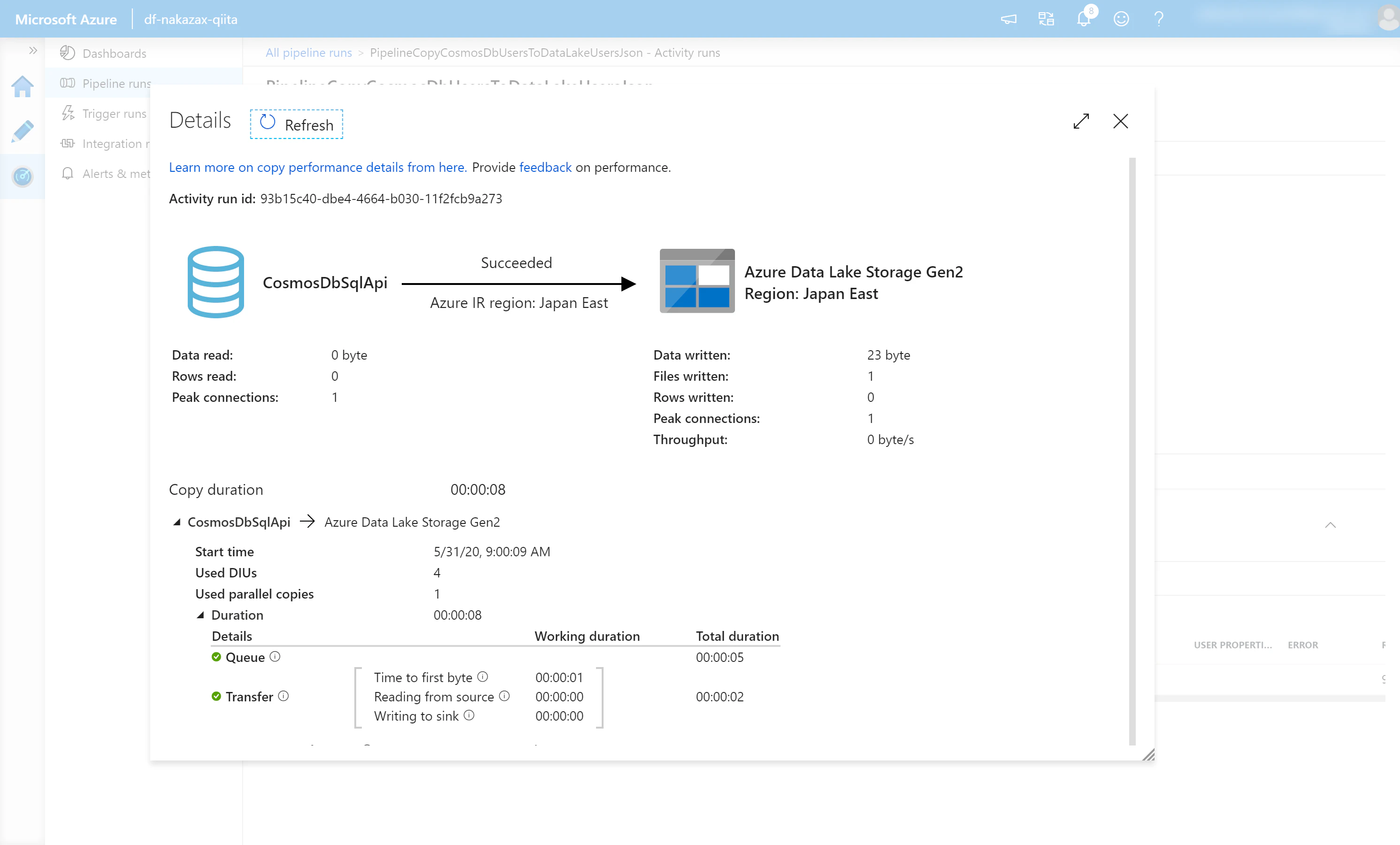
(5) デバッグ実行の詳細が表示されます。内容に問題ないかを確認します。
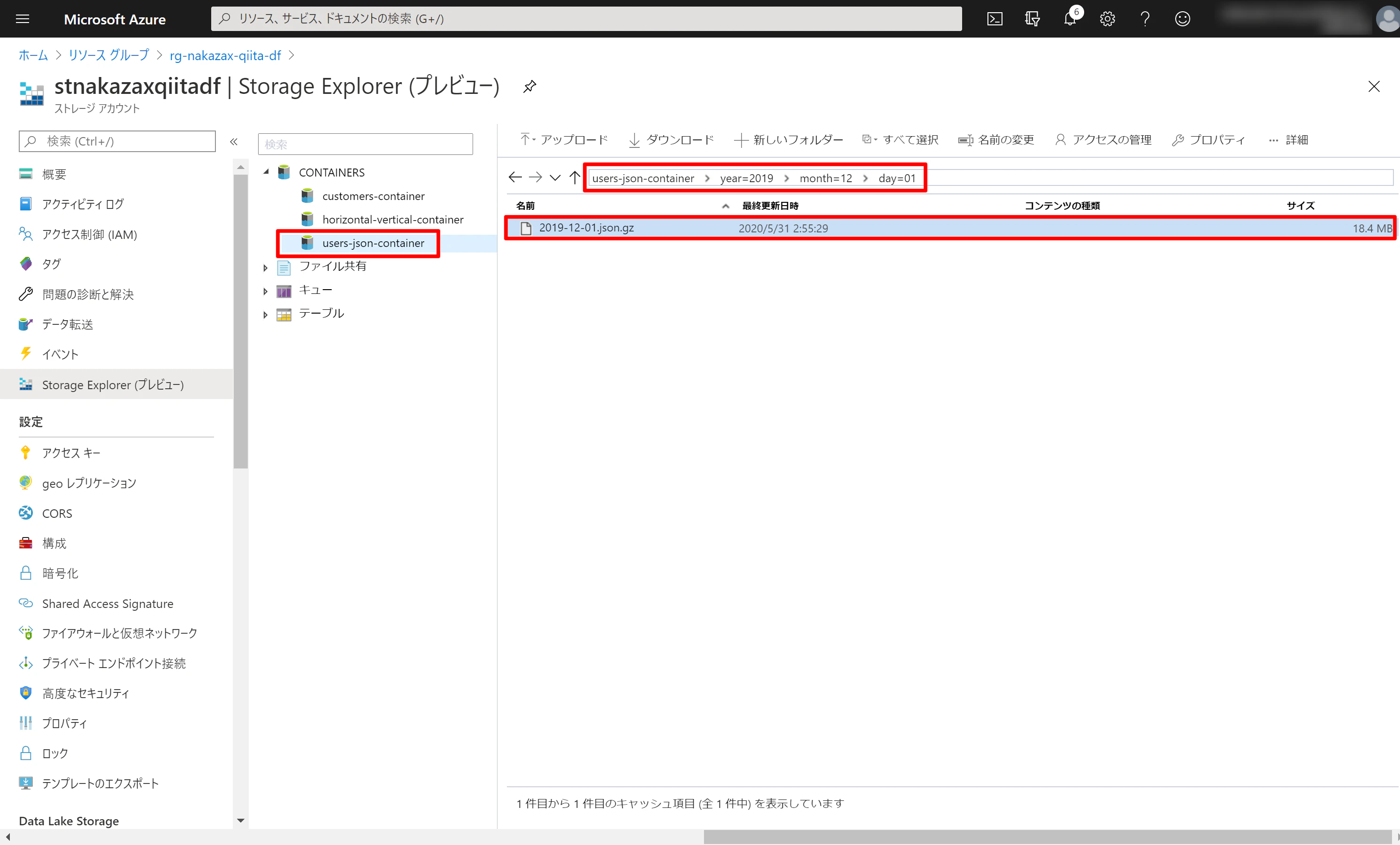
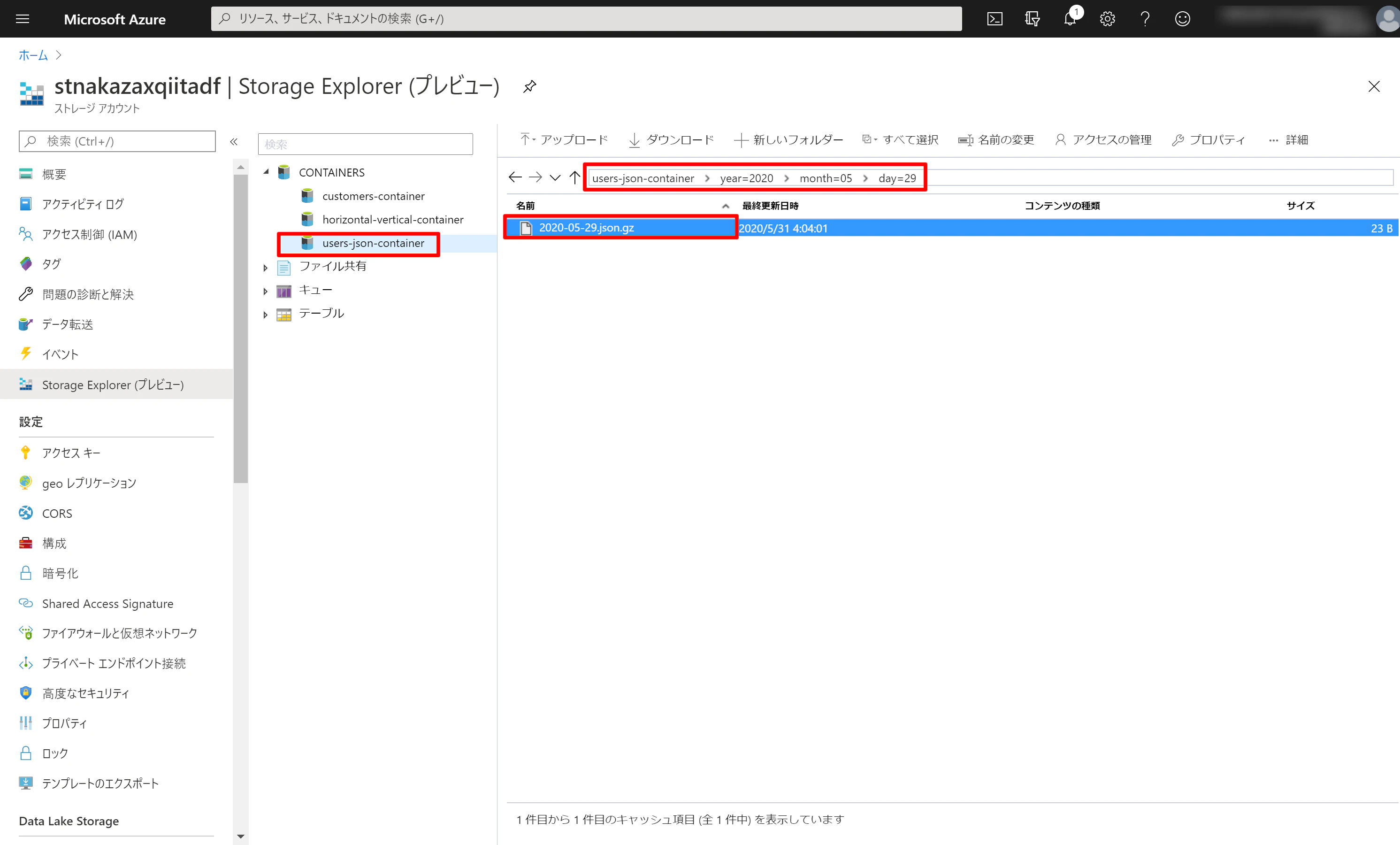
(6) Data Lake Storage を見てみると users-json-container/year=2019/month=12/day=01/2019-12-01.json.gz のファイルが出力されていることが確認できます。
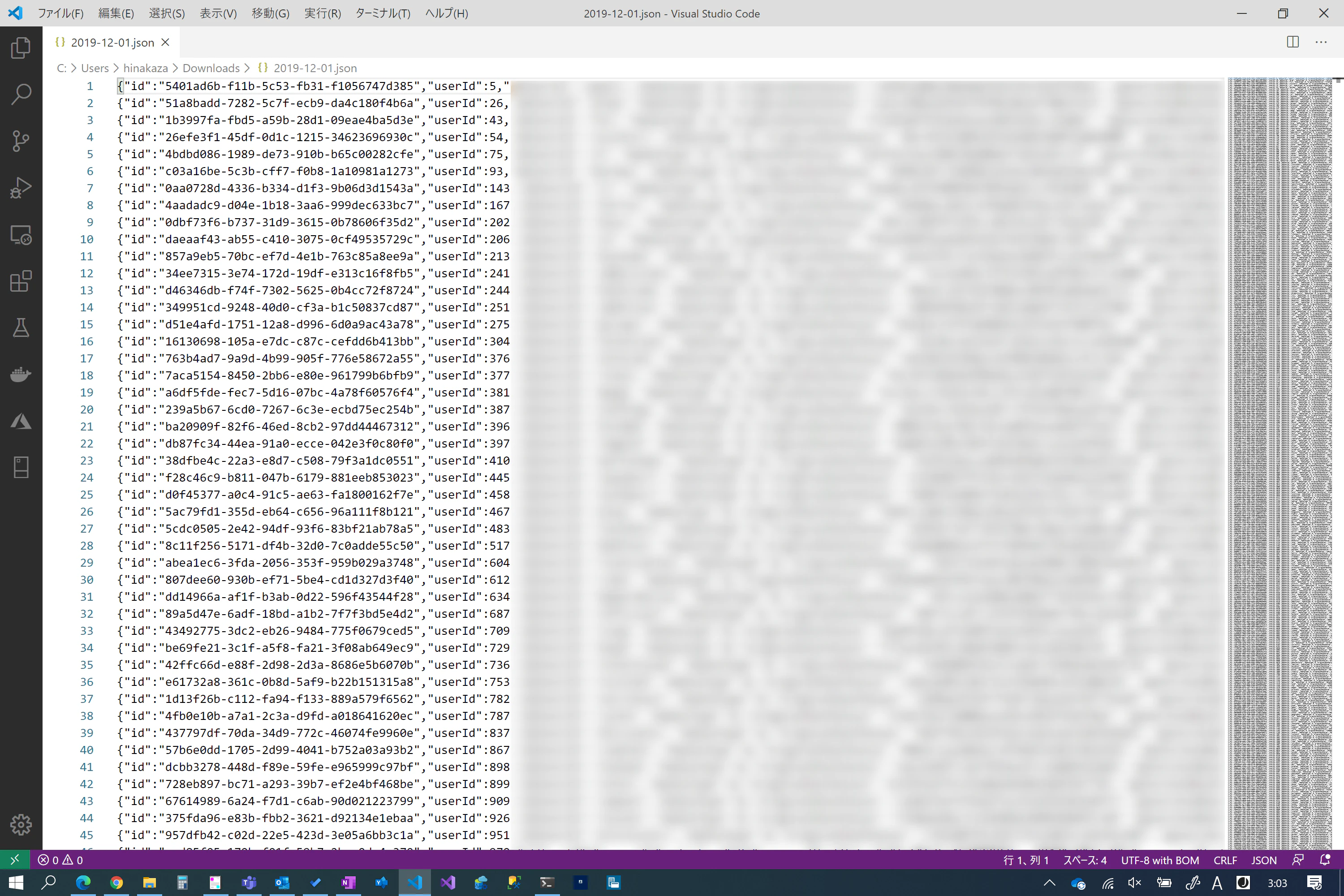
(7) Gzip ファイルをダウンロードし展開した結果、以下のように1行1JSON の形式で出力されていることが確認できます。
これで Pipeline & Copy data アクティビティの基本的な設定は完了です。
4. Triggers
Pipeline をスケジュール設定して実行するために Trigger を編集していきます。
4-1. Trigger 作成
(1) 画面左の鉛筆マークをクリック > Triggers > [New] をクリックします。
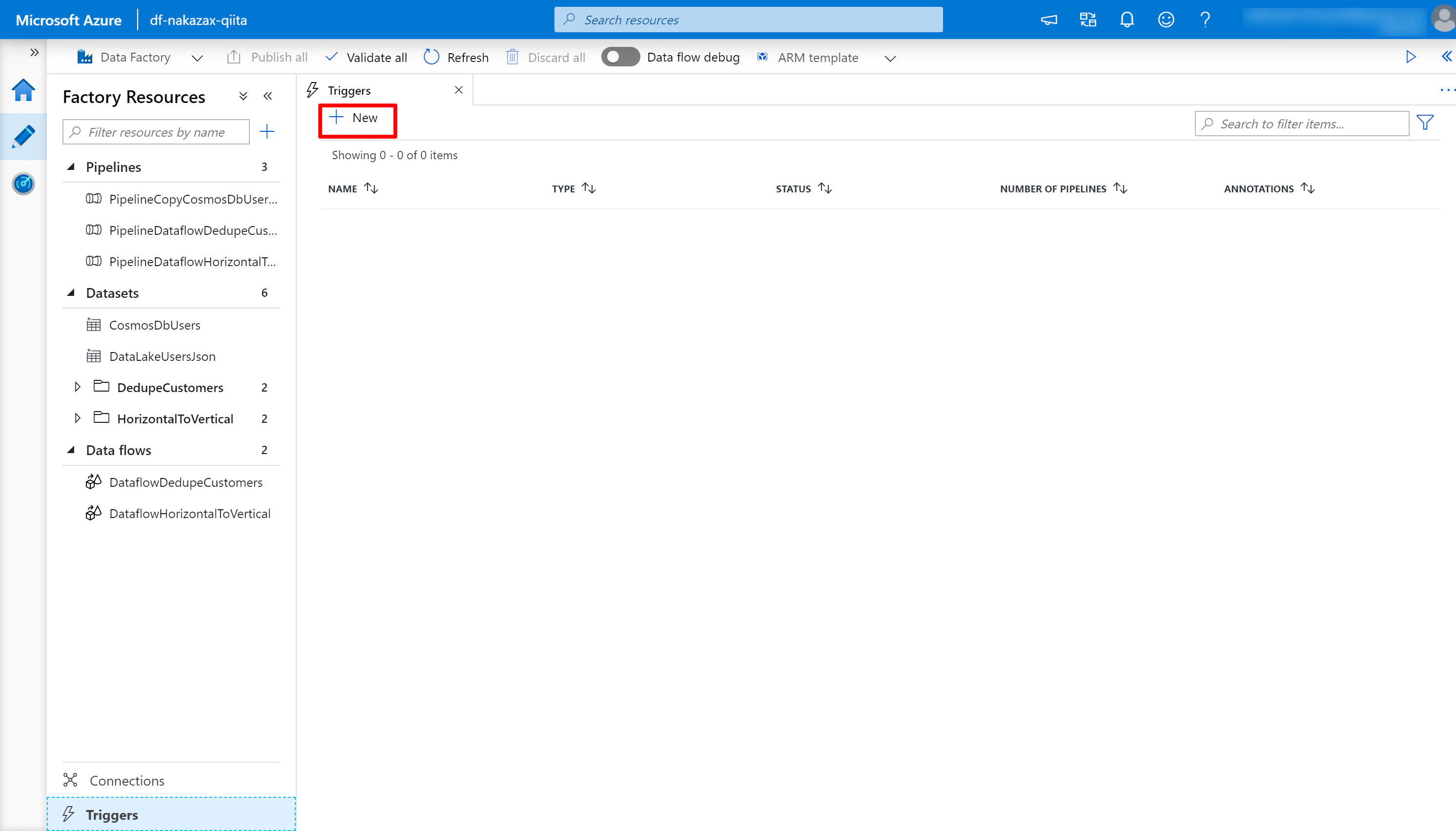
(2) 以下のように設定し [Advances] を展開します。
- Name には任意の名前を入力、ここでは
TriggerPipelineCopyCosmosDbUsersToDataLakeUsersJsonを使用します - Type に [Tumbling window] を指定します
- Start Date (UTC) に任意の日時を指定します (* 過去日時を指定した場合の挙動は後述)
- Recurrence に
24 Hoursを指定します - Activated に
Yesを指定します
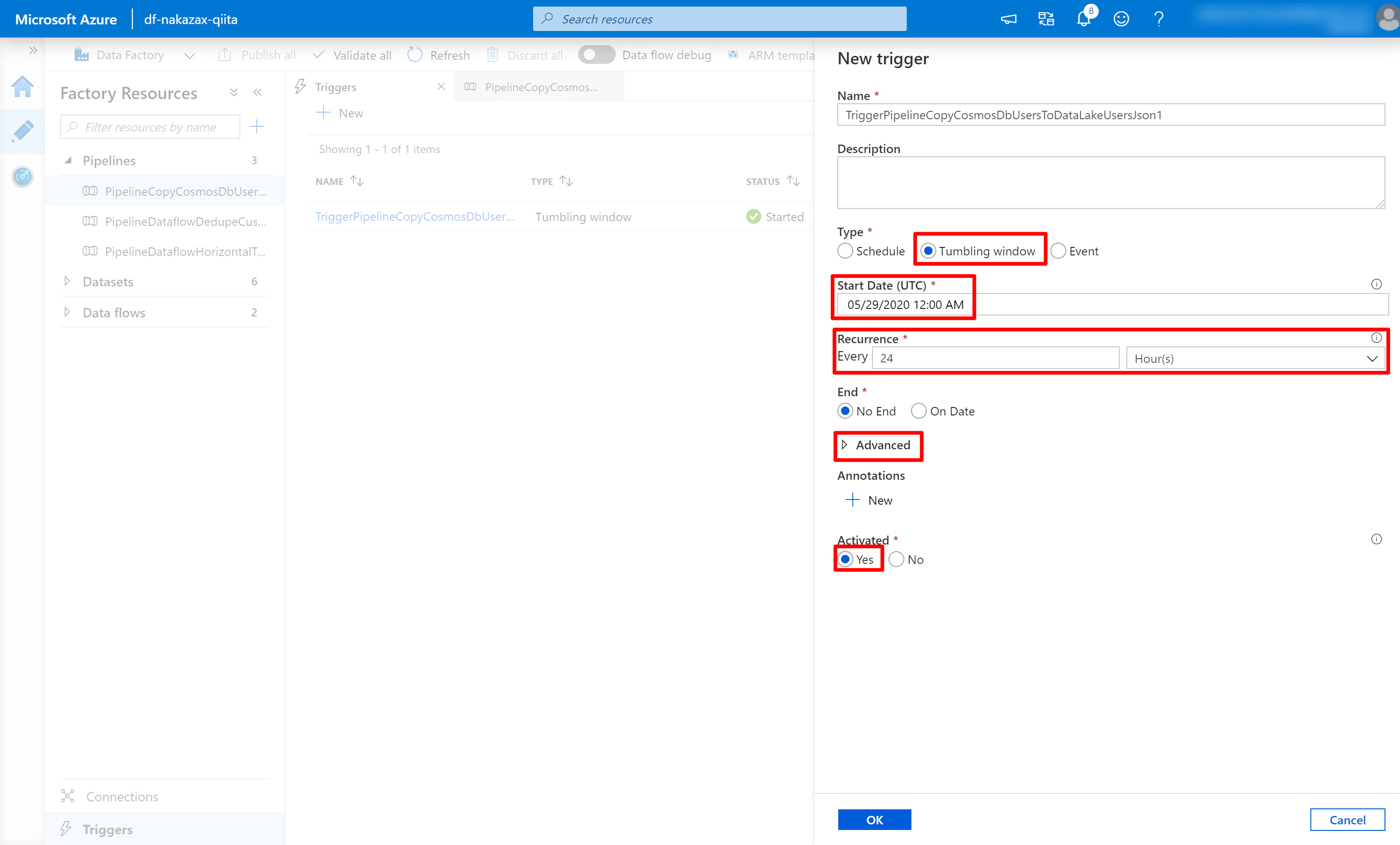
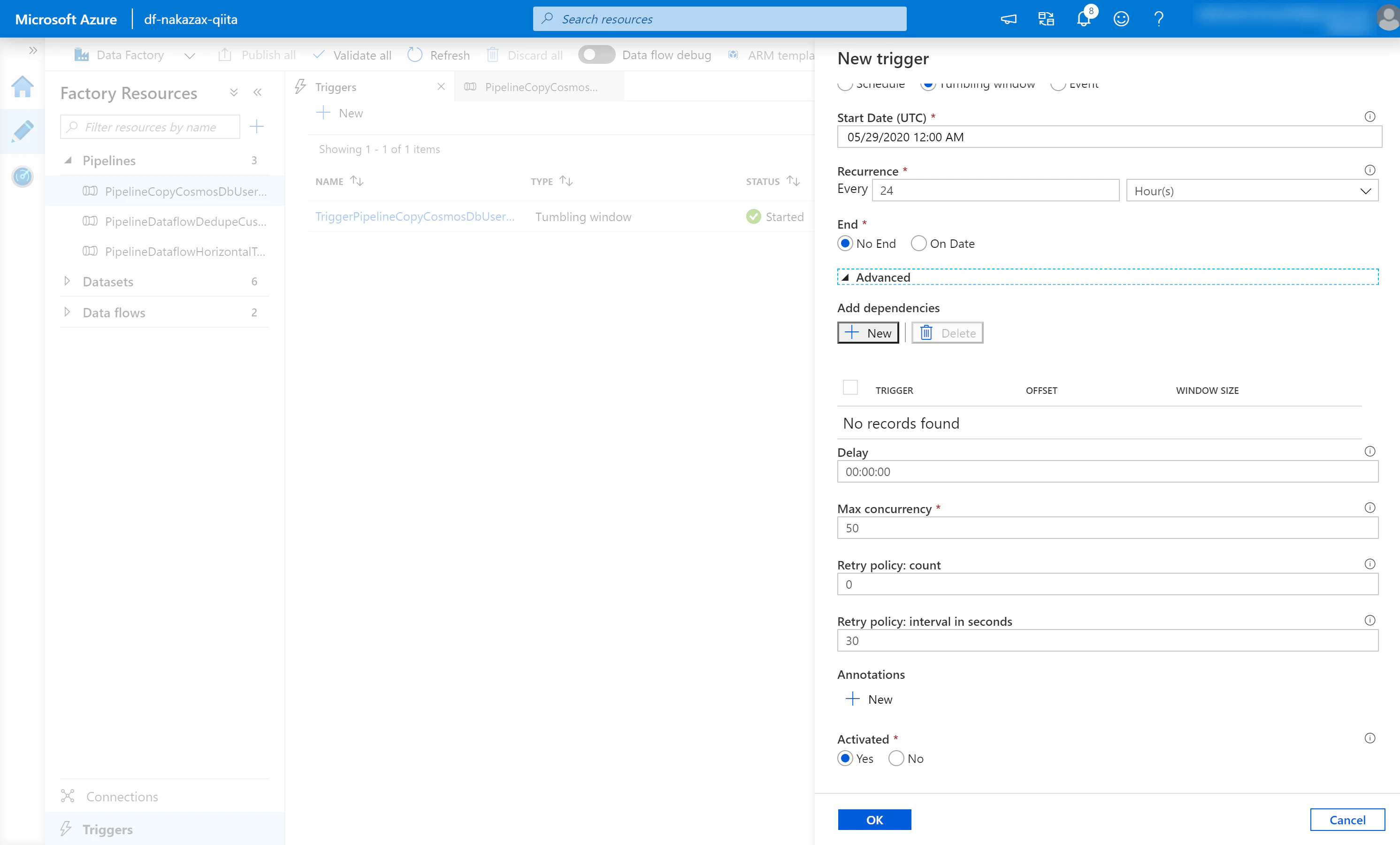
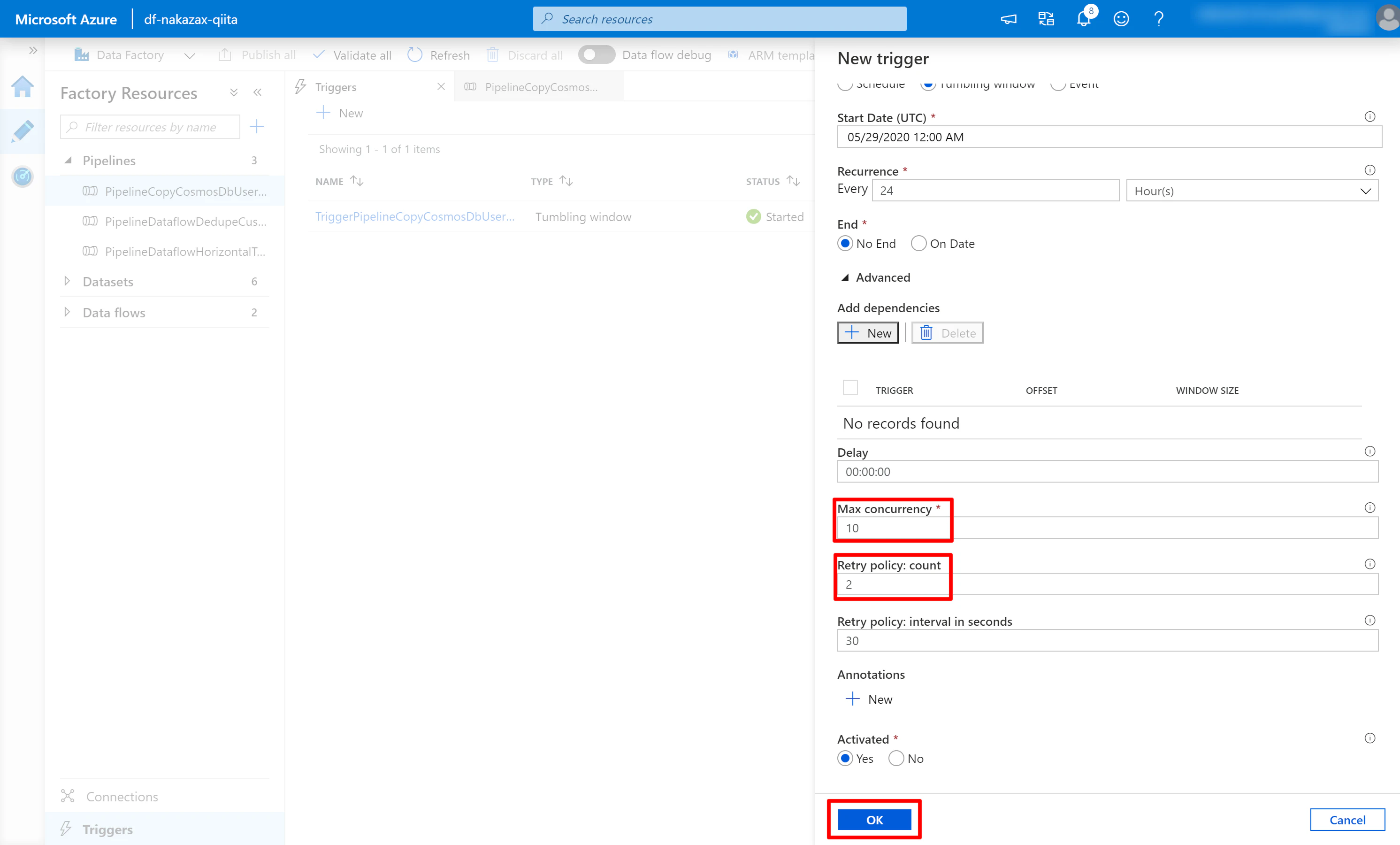
(3) [Advanced] のデフォルト値は以下のようになっています。これを赤枠のように編集して [OK] をクリックします。
(Tips) Trigger の種類について
Schedule と Tumbling window の違いなどについては以下のドキュメントをご覧ください。
(Tips) Start Date (UTC) による Pipeline の挙動
Start Date (UTC) について過去と未来の日時の両方を指定可能です。現在日時が 2020/05/30 19:00 (UTC) の場合、後述する Pipeline への関連付けと Publish を行った後にどのように Pipeline が起動されるかの例を記載します。
A. 過去日時指定 - Tumbling window & Start Date (UTC) 2020/05/28 00:00 & Recurrence 24 Hours を指定
- 以下2件の Pipeline が直ちに起動
- Pipeline 1
- windowStartTime:
2020-05-28T00:00:00Z - windowEndTime:
2020-05-29T00:00:00Z
- windowStartTime:
- Pipeline 2
- windowStartTime:
2020-05-29T00:00:00Z - windowEndTime:
2020-05-30T00:00:00Z
- windowStartTime:
- Pipeline 1
- 現在日時から5時間後 =
2020/05/31 00:00 (UTC)に以下の Pipeline が起動- windowStartTime:
2020-05-30T00:00:00Z - windowEndTime:
2020-05-31T00:00:00Z
- windowStartTime:
B. 未来日時指定 - Tumbling window & Start Date (UTC) 2020/05/31 00:00 & Recurrence 24 Hours を指定
- 現在日時から5時間後 =
2020/05/31 00:00 (UTC)に以下の Pipeline が起動- windowStartTime:
2020-05-30T00:00:00Z - windowEndTime:
2020-05-31T00:00:00Z
- windowStartTime:
C. 大幅な過去日時指定 - Tumbling window & Start Date (UTC) 2020/01/01 00:00 & Recurrence 24 Hours を指定
- 約150件の Pipeline が順次起動 (Advanced の Max concurrency に 10 を指定している場合、最大10件ずつ同時に実行される)
- Pipeline 1
- windowStartTime:
2020-01-01T00:00:00Z - windowEndTime:
2020-01-02T00:00:00Z
- windowStartTime:
- (途中省略)
- Pipeline 150
- windowStartTime:
2020-05-29T00:00:00Z - windowEndTime:
2020-05-30T00:00:00Z
- windowStartTime:
- Pipeline 1
- 現在日時から5時間後 =
2020/05/31 00:00 (UTC)に以下の Pipeline が起動- windowStartTime:
2020-05-30T00:00:00Z - windowEndTime:
2020-05-31T00:00:00Z
- windowStartTime:
大幅な過去日時を指定すると一気に Pipeline が起動されることになるため、Cosmos DB 側の RU が不足しないかなど注意が必要です。
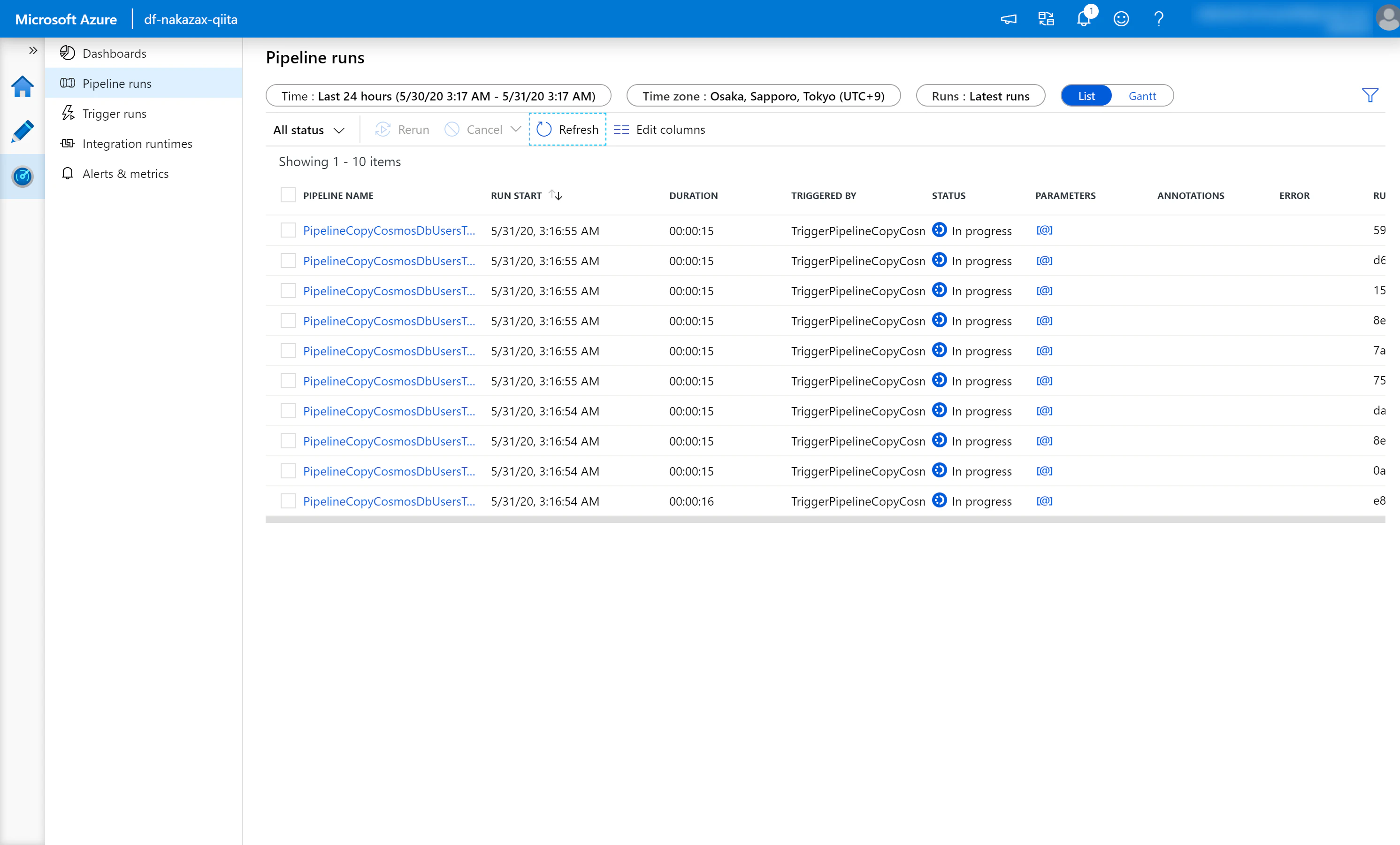
4-2. Pipeline への関連付け
(1) 先に作成した Pipeline を選択し [Add trigger] > [New/Edit] をクリックします。
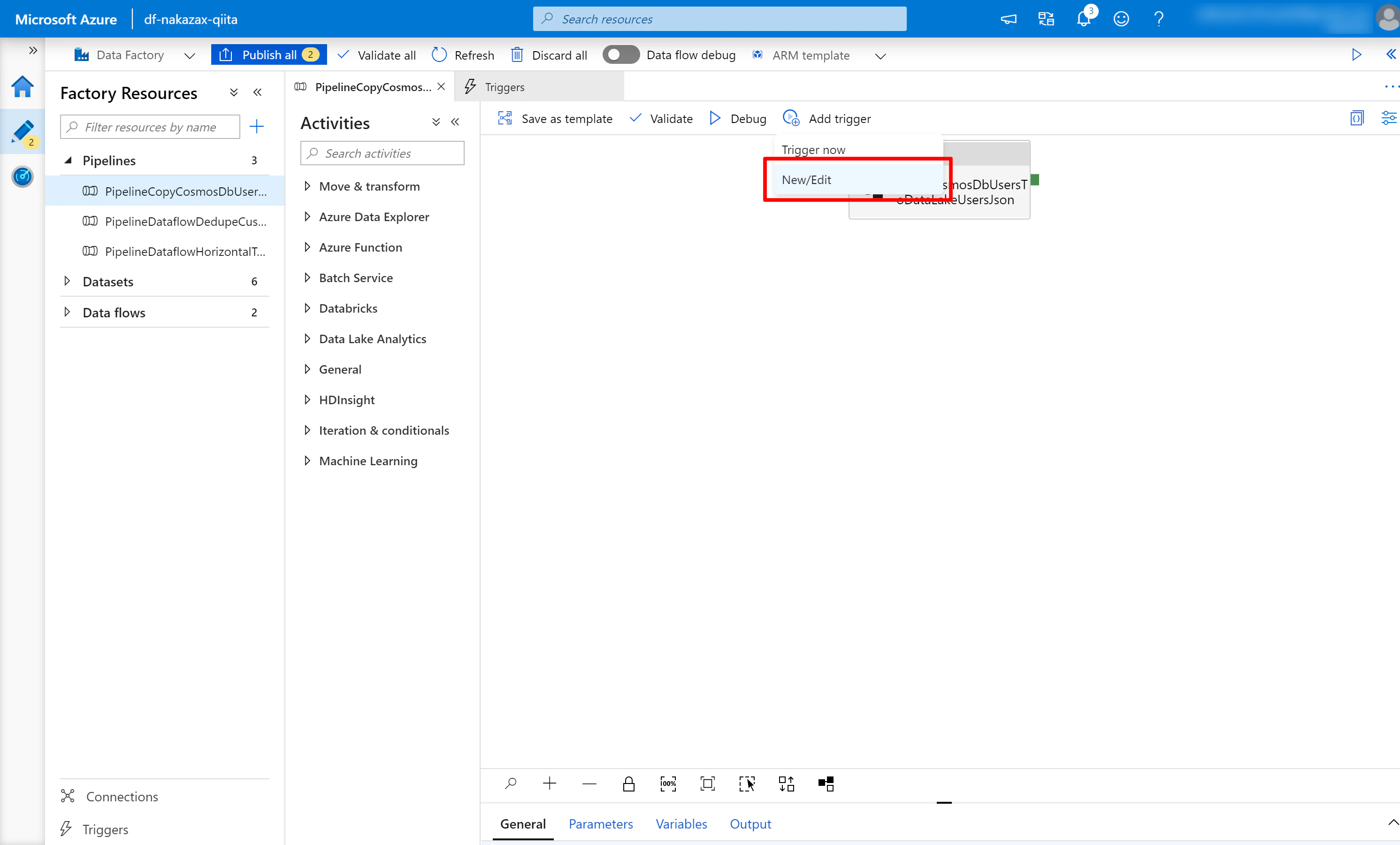
(2) 先に作成した Trigger を選択します。
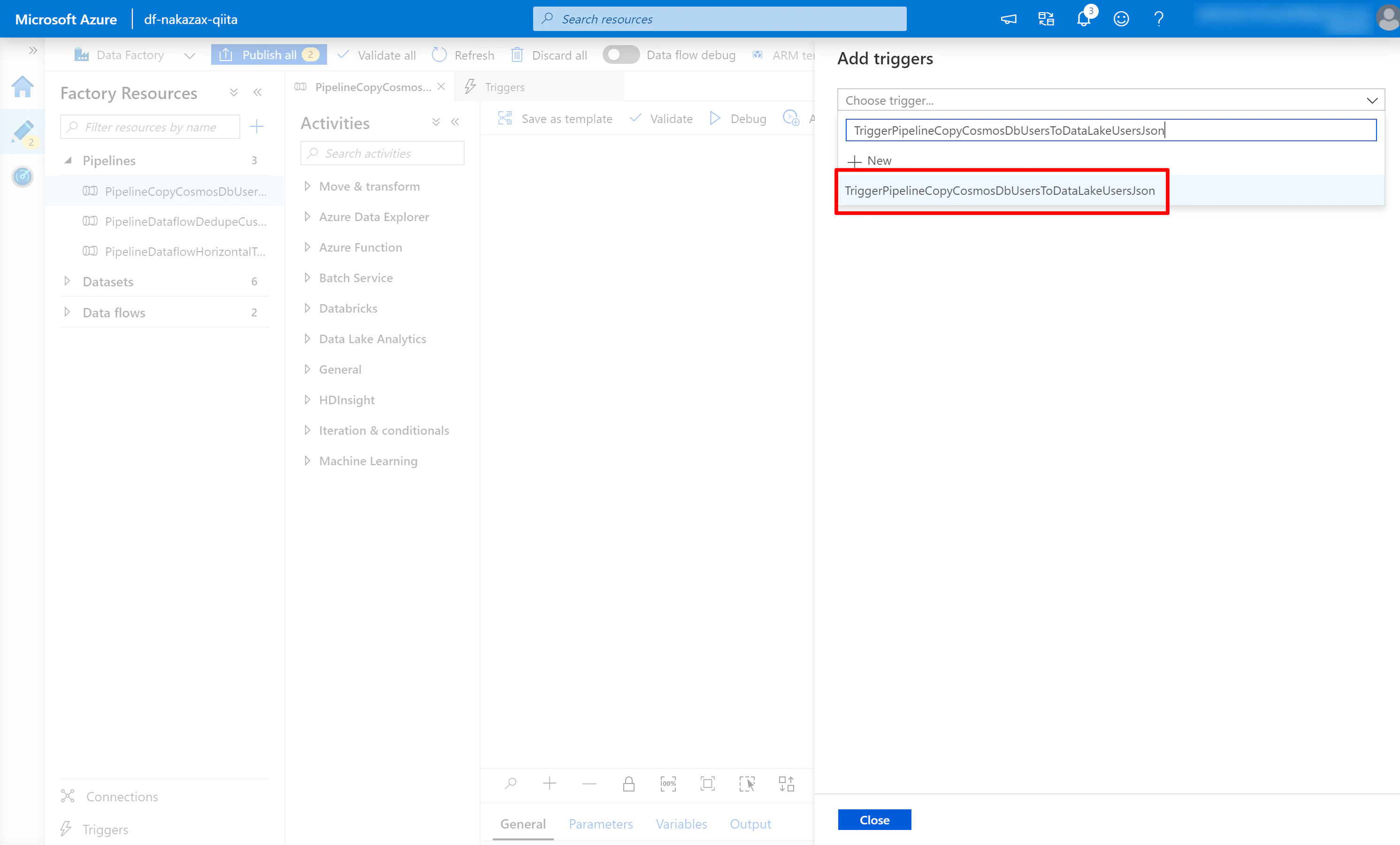
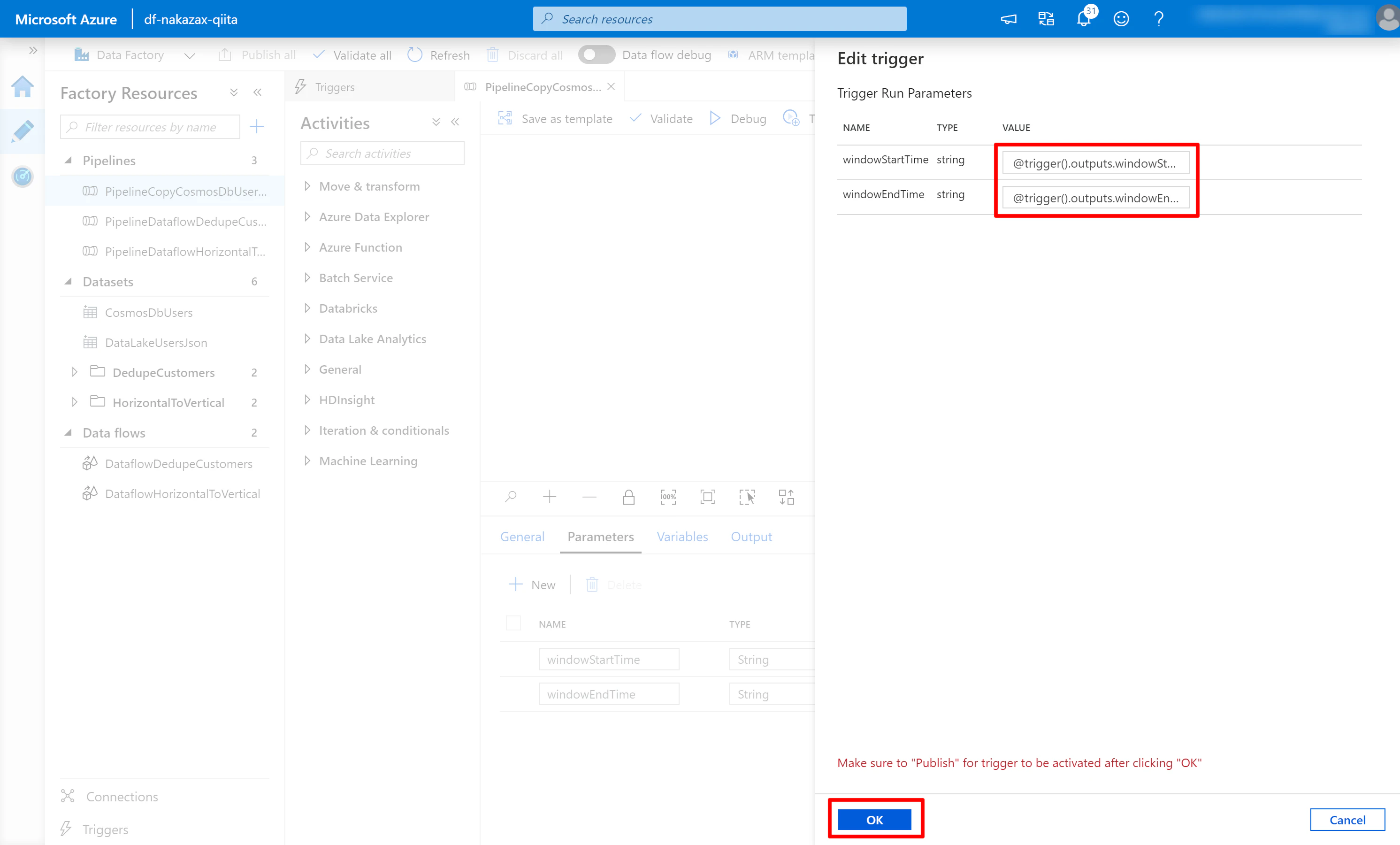
(3) すると Edit trigger が表示されます。先ほど必要な内容は編集済みですので [OK] をクリックします。
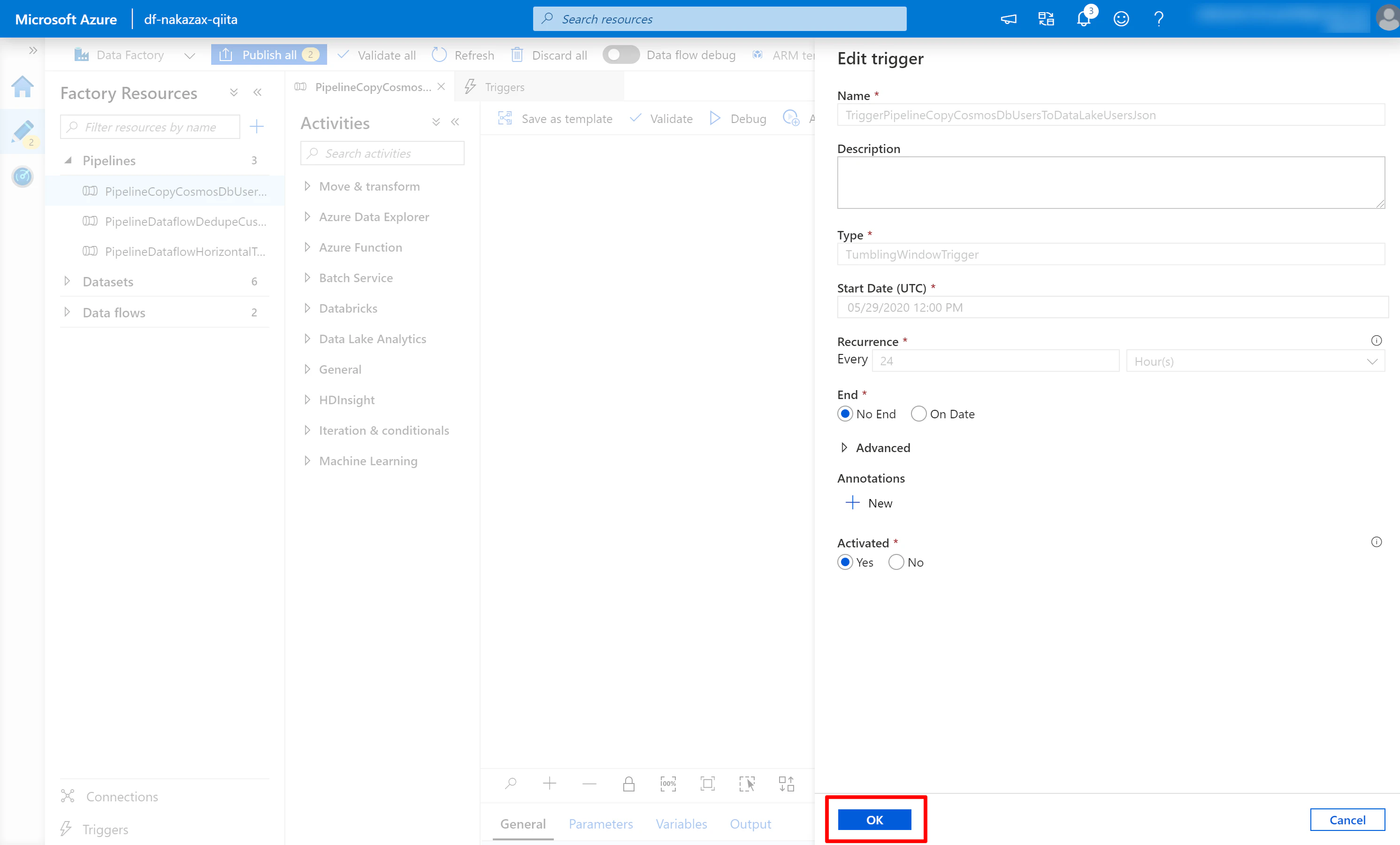
(4) パラメーターの VALUE を以下のように編集します。
- windowStartTime:
@trigger().outputs.windowStartTime - windowEndTime:
@trigger().outputs.windowEndTime
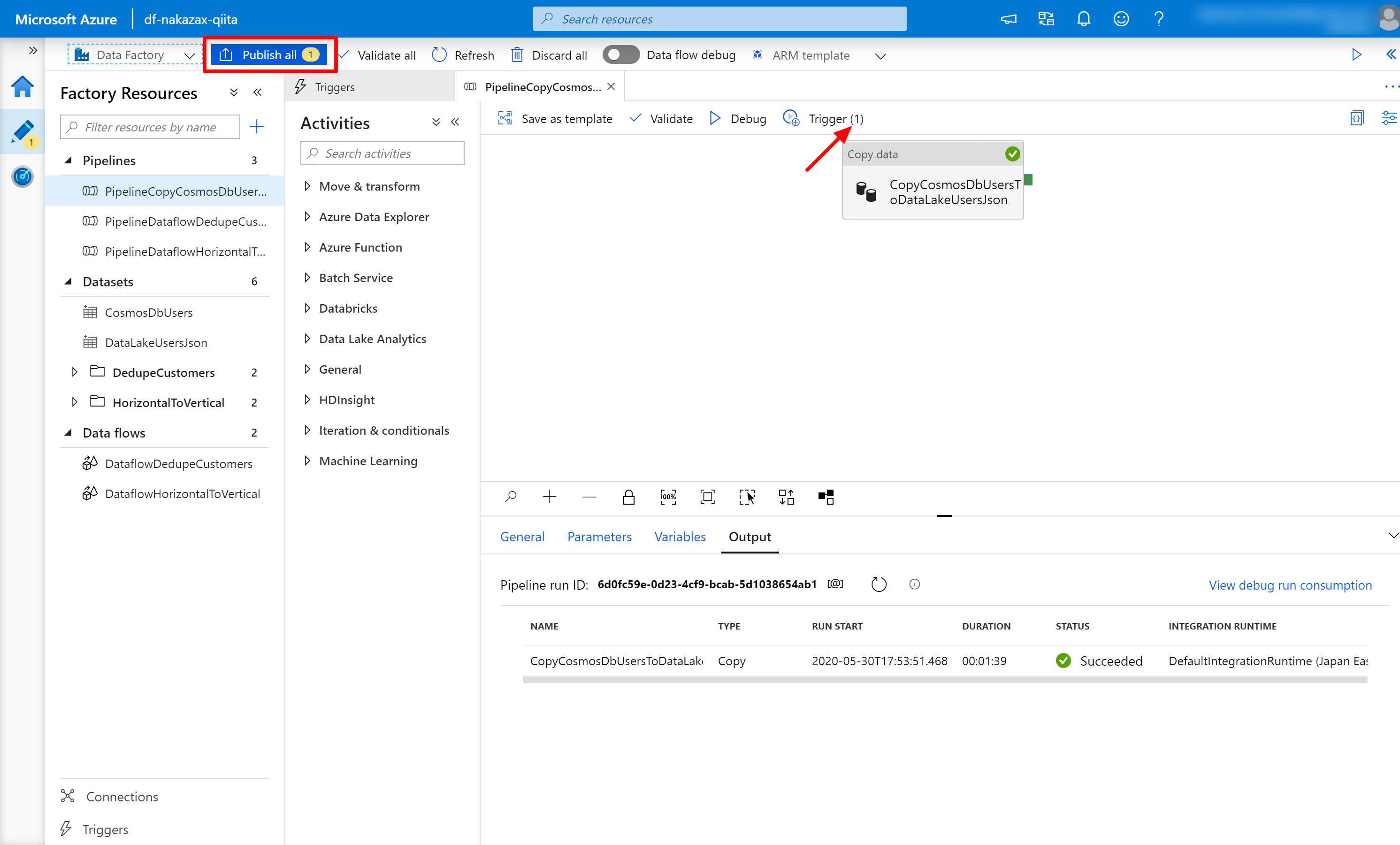
(5) Trigger (1) というように Pipeline に Trigger が関連付けられたことを確認したら [Publish] をクリックします。Publish を実施することで Trigger が有効になります。
4-3. Pipeline 実行確認
Trigger を Pipeline に関連付けて Publish することで Trigger が有効になります。前述の通り、Trigger に過去日時を指定した場合は Publish したら直ちに Pipeline が実行されます。未来日時を指定した場合、その日時になると Pipeline が実行されます。
Pipeline が実行されたら以下のようなキャプチャの流れで実行結果を確認すると良いでしょう。
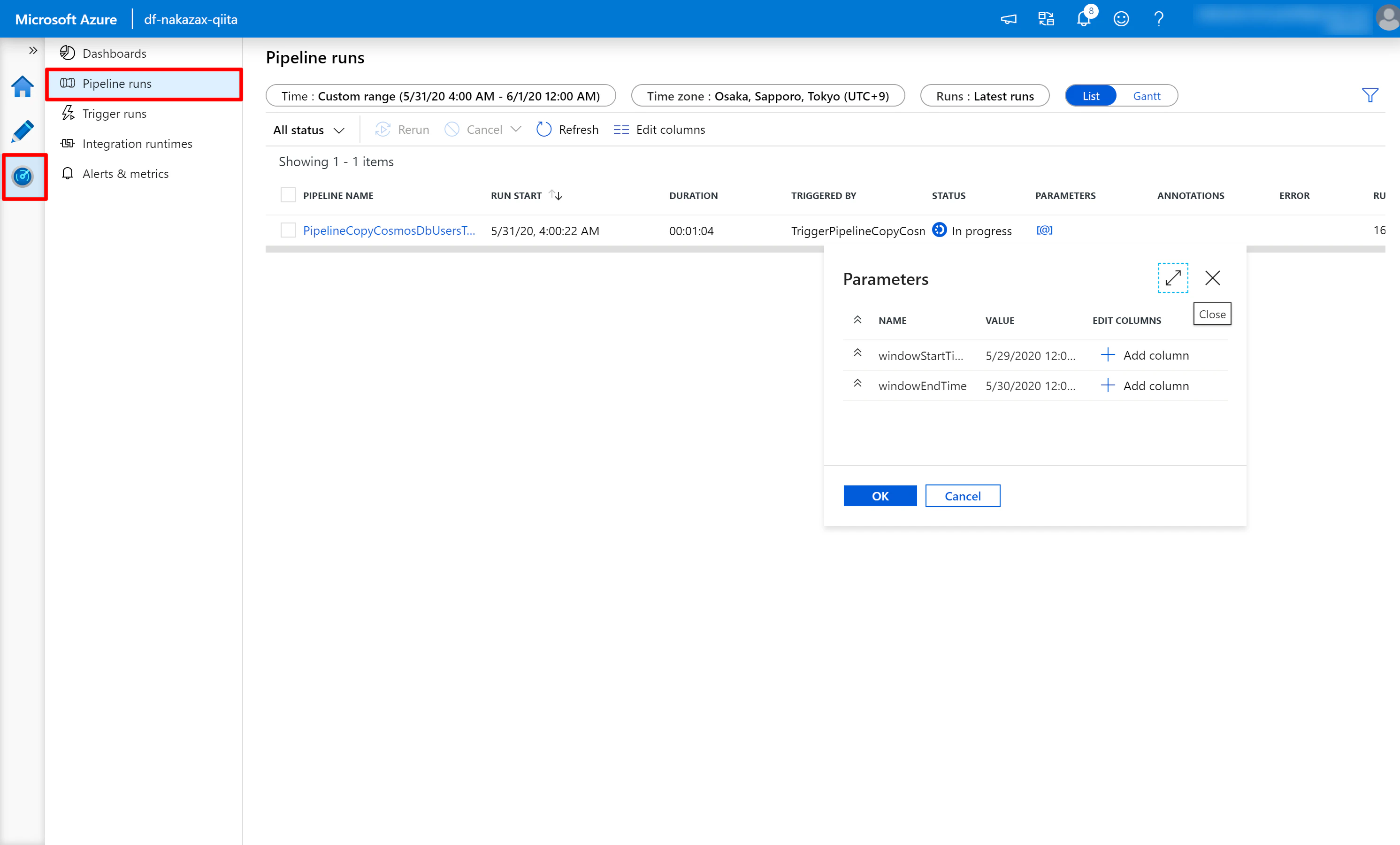
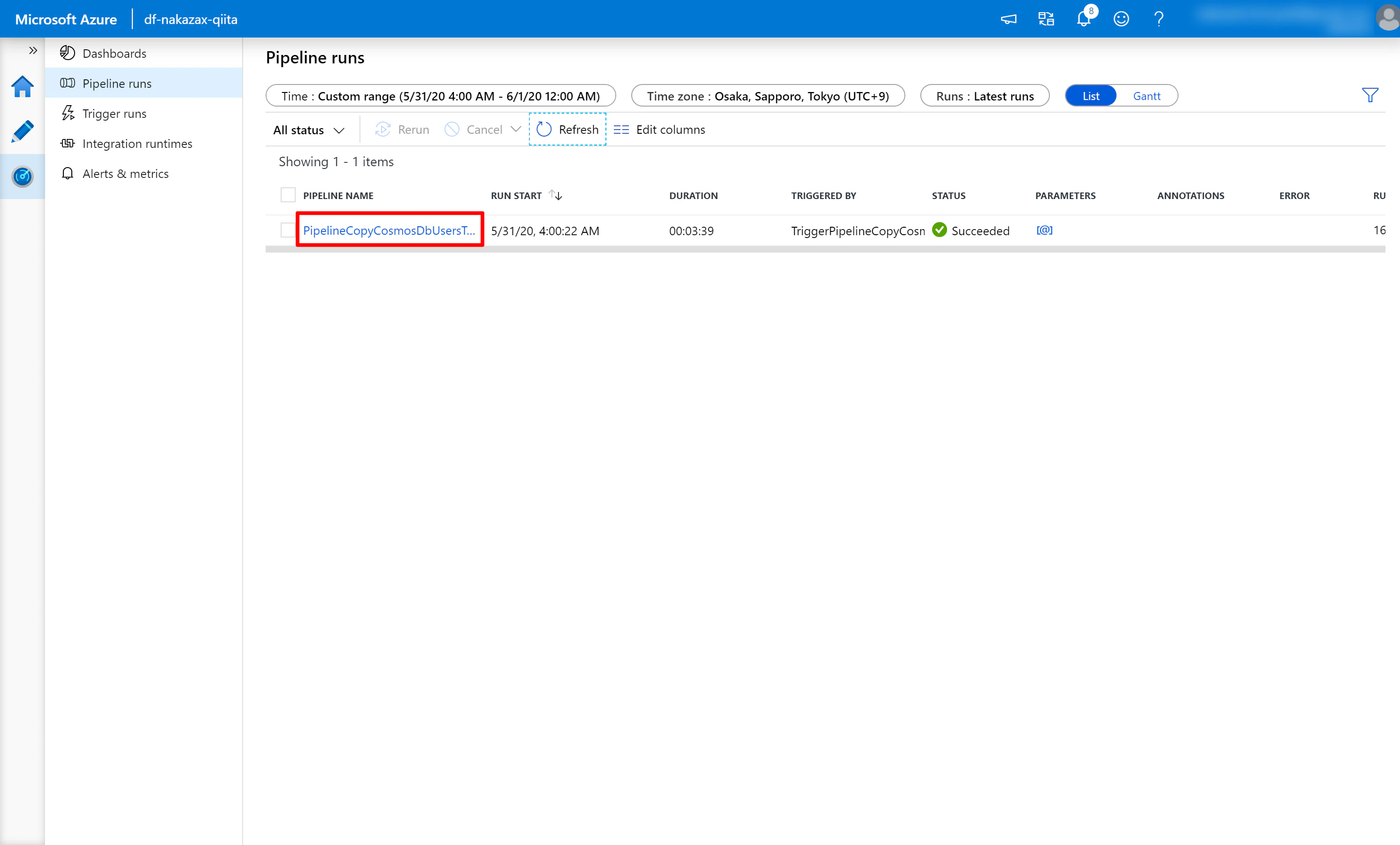
以上です。