はじめに
「プロジェクトAにあるBigQueryのデータをプロジェクトBに週次で同期を取ってほしい」という要望が発生しました。
手作業で毎週行うのはキツいため、自動化できないか検証を行いこのデータ移行アプリを作成しました。
本記事では備忘も兼ねて、対応した内容・ハマったポイントなどを記載します。
事前に知っておけば調査の手間が減る内容もあるため、参考になればと思います。
本記事で主に扱うGCPサービス
- BigQuery
- Google Cloud Storage(GCS)
- Google App Engine(GAE)
本記事ではGoogle App Engine(GAE)についてがメインになります。
その他サービスでの対応内容
他のサービスで対応した内容については、以下の記事にまとめています。
異なるプロジェクト間のBigQueryデータ同期アプリ構築時のハマりポイントまとめ 【BigQuery・GCS編】
要件
- プロジェクトAのBigQueryテーブルデータをプロジェクトBに定期的に同期したい
- 対象のテーブル数は30弱
プロジェクトAには外部システムから数分間隔でファイル連携され、毎日大量のデータが新しくBigQueryに取り込まれる仕様でした。
「プロジェクトBでプロジェクトAと同等のデータを扱いたい」という要望がありこのような仕組みが必要になりました。
ただし、プロジェクトAほどリアルタイム性は求められないため、週次での更新としました。
制約
- プロジェクトAとプロジェクトBではVPCが異なるため、直接テーブルのコピー操作はできない
- 新規に専用インスタンスは立てられない
BigQueryにはGCPコンソールの操作でテーブルをコピーする機能があるのですが、VPCが異なる場合はエラーとなりました。
おそらくアクセス権限周りの制御により発生するエラーだと思います。
また、案件都合で専用のGCEインスタンスの作成にはNGが出たため、今回は新規GCEインスタンスを作らずに実現する必要がありました。
これらの問題を突破しつつ、テーブルデータを移行しなければいけませんでした。
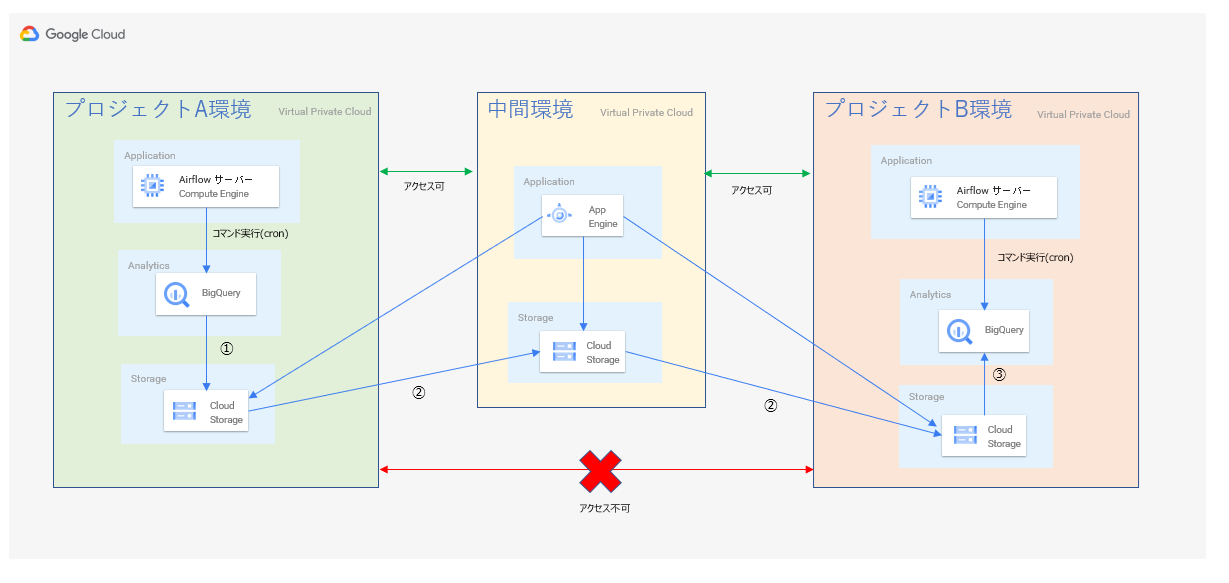
できあがった構成
プロジェクトAとB両方にアクセスできる中間環境を用意して、最終的には下記のような構成と処理になりました。
処理内容
- プロジェクトAのAirflowサーバー内シェルでbq extractコマンドを実行(cron実行)
- 中間環境のGAEでファイル移動処理を実行(GAEのcron実行)
- プロジェクトBのAirflowサーバー内シェルでbq load処理を実行(cron実行)
<アーキ図>
GAEでの対応内容・注意点
GAEでアプリを実装
今回の構成ではファイル移動の処理のみを受け持っています。pythonで実装しています。
<コードサンプル ファイル移動API>
from flask import Flask,render_template, request
import datetime
from google.cloud import storage, bigquery
import logging
import const
import json
import time
app = Flask(__name__)
# project A
project_id_a = "project-a"
bucket_name_a = "project-a-bucket"
# project B
project_id_b = "project-b"
bucket_name_b = "project-b-bucket"
# com
project_id_com = "project-com"
bucket_name_com = "project-com-bucket"
bucket_name_com_const = "project-com-bucket-const"
@app.route('/test', methods=['GET'])
def request_test():
# gcsからTBLリストファイルを取得
file_blob = get_gcs_file(const.table_list_file)
table_list = json.loads(file_blob.download_as_string())
for target_table_data in table_list:
export_table_id = target_table_data[0]
copy_blob(export_table_id)
return "success test"
# copy mthod
def copy_blob(table_id):
print('cp start ')
# A to com
storage_client = storage.Client()
source_bucket = storage_client.bucket(project_id_a)
destination_bucket = storage_client.bucket(bucket_name_com)
file_list = source_bucket.list_blobs(prefix= table_id + "/")
for file in file_list:
source_blob = source_bucket.blob(file.name)
blob_copy = source_bucket.copy_blob(
source_blob, destination_bucket, file.name
)
# com to B
b_storage_client = storage.Client()
b_source_bucket = b_storage_client.bucket(bucket_name_com)
b_destination_bucket = b_storage_client.bucket(bucket_name_b)
com_file_list = source_bucket.list_blobs(prefix= table_id + "/")
for com_file in com_file_list:
b_source_blob = b_source_bucket.blob(com_file.name)
b_blob_copy = b_source_bucket.copy_blob(
b_source_blob, b_destination_bucket, com_file.name
)
print('cp end')
def get_gcs_file(target_file):
storage_client = storage.Client()
test_bucket = storage_client.get_bucket(bucket_name_com_const)
file_blob = test_bucket.blob(target_file)
return file_blob
if __name__ == '__main__':
app.run(host='127.0.0.1', port=8080, debug=True)
BigQueryへの操作でエラー発生(検証の結果採用できず)
元々目指した形はサーバレス構成で、ファイル移動に加えてBigQueryのインポート/エクスポートもGAEの処理で実現する予定でした。
<コードサンプル Bigquery操作>
※設定ファイルについては割愛しています
# bigquery export
def bq_export(export_dataset_id, export_table_id):
print('start db_export')
bq_client = bigquery.Client(project=project_id_a)
destination_uri = "gs://{}/{}/{}_*.csv.gz".format(bucket_name_a, export_table_id, export_table_id)
dataset_ref = bq_client.dataset(export_dataset_id, project=project_id_a)
table_ref = dataset_ref.table(export_table_id)
job_config = bigquery.job.ExtractJobConfig()
# 圧縮の設定
job_config.compression = bigquery.Compression.GZIP
job_config.destination_format = (bigquery.job.DestinationFormat.CSV)
print('export start')
extract_job = bq_client.extract_table(
table_ref,
destination_uri,
job_config=job_config
)
extract_job.result() # Waits for job to complete.
print(
"Exported {}:{}.{} to {}".format(project_id_a, export_dataset_id, export_table_id, destination_uri)
)
print('export end')
# bigquery import
def bq_import(export_table_id, import_dataset_id ,import_table_id, schema_file):
print(import_table_id)
bq_client_test = bigquery.Client(project=project_id_b)
# get file list
storage_client = storage.Client()
test_file_list = storage_client.list_blobs(bucket_name_test , prefix= export_table_id + "/")
dataset_ref = bq_client_test.dataset(import_dataset_id, project=project_id_b)
table_ref = dataset_ref.table(import_table_id)
# export config
job_config = bigquery.LoadJobConfig()
# 動的にshema定義変更
test_bucket = storage_client.get_bucket(bucket_name_com)
file_blob = test_bucket.blob("schema/" + schema_file)
schema_data = json.loads(file_blob.download_as_string())
# スキーマ指定
job_config.schema = schema_data
job_config.source_format = bigquery.SourceFormat.CSV
job_config.autodetect = True
job_config.skip_leading_rows = 1
print('import start')
first_import_flag = False
for test_file in test_file_list:
# 最初の1回のみ WRITE_TRUNCATE オプションを付与
if first_import_flag == False:
job_config.write_disposition = "WRITE_TRUNCATE"
first_import_flag = True
else :
job_config.write_disposition = "WRITE_APPEND"
# 403 Exceededエラー対策でsleep
time.sleep(2)
print('import:' + test_file.name)
load_job = bq_client_test.load_table_from_uri(
source_uris="gs://{}/{}".format(bucket_name_b, test_file.name),
destination=table_ref,
job_config=job_config)
load_job.result()
print('success')
print('import end')
これを実行してみたしたところ、BigQueryのインポート処理中にBigQueryへのリクエスト上限エラーに引っかかりエラー終了となってしまうことが判明しました。
発生エラー:Forbidden: 403 Exceeded rate limits
テーブルによってはエクスポートされたファイル数が1000を超える場合もあり、
億単位のレコード数をもつものも含まれていたのが要因と思われます。
なにより完了までに数時間かかる見込みと、処理時間がとても長いのが問題でした。
止むを得ず、GAEでのBigQuery操作は見切りをつけることにしました。
フレキシブル版を採用
GAEはフレキシブル版を利用しました。
スタンダード版だとリクエストのタイムアウトが短く(60秒)それを長くするためと、スペックを上げて検証するためにという理由です。
以下のようなapp.yamlを作成しデプロイしました。
<GAE用設定yaml>
service: service_name
runtime: python
env: flex
entrypoint: gunicorn -t 86400 -b :$PORT main:app
runtime_config:
python_version: 3
manual_scaling:
instances: 2
resources:
cpu: 2
memory_gb: 4
disk_size_gb: 30
handlers:
- url: /.*
script: auto
GAE処理のcron設定
ファイル移動処理はGAEに作ったAPIをcron実行させています。
下記のようなcron.yamlファイルをapp.yamlとは別にデプロイする必要があります。
<GAE用cron設定yaml>
cron:
- description: cp data
url: /test
schedule: every sunday 13:00
timezone: Asia/Tokyo
target: service_name
最後に
GAEのデプロイやGAEで書いたコードからのGCS、BigQueryの操作の実装などの面ではいい経験になりました。
とはいえ、スマートな構成ではなかったのでもっといい形にはできなかったかなとも思いました。
GCPについては日本語の記事が少ないなと感じるので、この記事が少しでもGCPについて困っている方の役にたてば幸いです。