普段、GraphQLを用いてAPI開発をしているのですが、正規化されていないデータベースからレコードを取り出し、それを編集して綺麗なスキーマに載せ替えるようなAPIを作成することが度々あります。
このようなケースを取り扱う場合、各Resolverにどこまでの責務をもたせるべきかについて、混乱が生じることも多いと感じます。そこで今回は、具体的なケース例を取り上げつつ、自分なりの考え方を整理してみようと思います。
前提
データベースはこちら。都道府県、市区町村ごとの住民テーブルですが、正規化されていません。
| prefectureId | prefectureName | cityId | cityName | residentId | residentName |
|---|---|---|---|---|---|
| p001 | Tokyo | c001 | Shinjuku | r001 | Taro Yamada |
| p001 | Tokyo | c001 | Shinjuku | r002 | Hanako Suzuki |
| p001 | Tokyo | c002 | Shibuya | r003 | Kenji Tanaka |
| p002 | Osaka | c003 | Umeda | r004 | Mika Sato |
データ型はこちら。
export interface EntityModelResident {
residentId: string;
residentName: string;
cityId: string;
cityName: string;
prefectureId: string;
prefectureName: string;
}
これを次のGraphQLスキーマに載せ替えます。
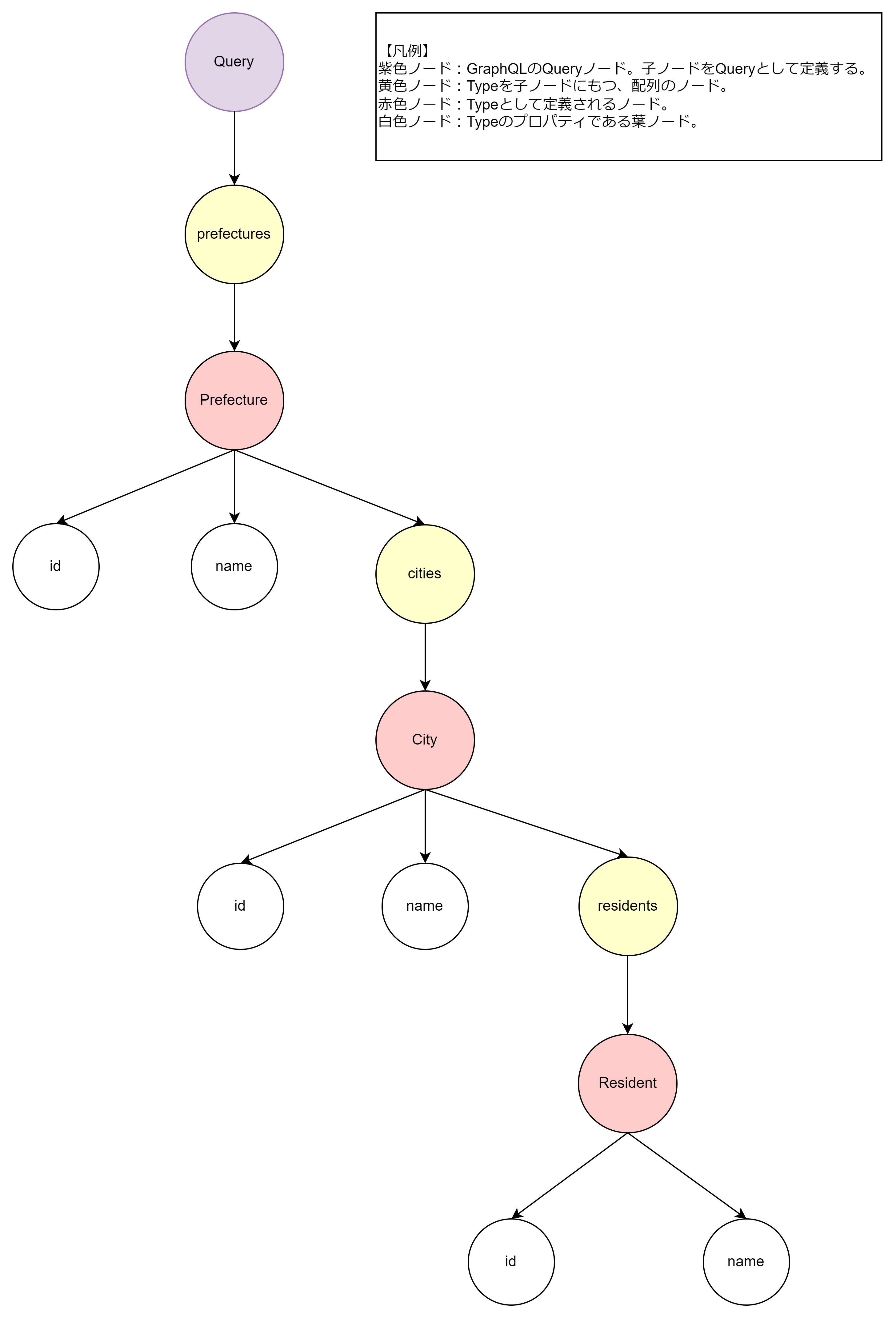
スキーマファイルはこちら。
type Resident {
"""住民ID"""
id: String!
"""住民名"""
name: String!
}
type City {
"""市区町村ID"""
id: String!
"""市区町村名"""
name: String!
"""住民"""
residents: [Resident!]!
}
type Prefecture {
"""都道府県ID"""
id: String!
"""都道府県名"""
name: String!
"""市区町村"""
cities: [City!]!
}
type Query {
prefectures(userId: String): [Prefecture!]!
}
設計方針
では、上記の前提をもとに、各Resolverで何をどこまで実装するべきかを検討していきましょう。Resolverは各TypeとQuery/Mutationに紐づいて作成されるため、今回は以下の4つとなります。
| Type | 作成するResolver |
|---|---|
| Query (prefectures) | PrefecturesResolver |
| Prefecture | PrefectureResolver |
| City | CityResolver |
| Resident | ResidentResolver |
Resolver設計のポイントは、各Resolverが、自分よりも下位のResolverの仕事を奪ってしまわないようにすることです。
例えば、極端な設計を考えると、最上位のPrefecturesResolverでPrefecture、City、Residentという3つのノード全てを完成させることもできます。しかしその場合は、
query {
prefectures(userId: "admin"){
id
name
}
}
このようなQueryがリクエストされた際に、不要であるはずの処理(例えば「住民単位で元データをグループ化する」処理など)が動いてしまうことになり、パフォーマンスが最適化されません。
したがって、様々なリクエストのパターンに応じて、最適なパフォーマンスを発揮することを重視するのであれば、各Resolverはできるだけ下位のResolverに処理を委譲すべきです。
それを実現するために、各Resolverがやるべきことは
- 担当するTypeの子ノードが、葉ノード(子ノードをもたないノード)であれば、最後まで完成させる
- 担当するTypeの子ノードが、内部ノード(子ノードをもつノード)であれば、子ノードをキーごとに区切る
の2つです。逆に言うと内部ノードを完成させるのは責任超過ということになります。
上記のアイデアに基づいて、今回作成するResolverとその責務を以下にまとめました。
| Resolver | 責務 |
|---|---|
| ResidentResolver | Residentノードに紐づく葉ノード(id, name)を完成させる。 |
| CityResolver | Cityノードに紐づく葉ノード(id, name)を完成させる。住民IDごとに元データ EntityModelResident[] をグループ化する。 |
| PrefectureResolver | Prefectureノードに紐づく葉ノード(id, name)を完成させる。市区町村IDごとに元データ EntityModelResident[] をグループ化する。 |
| PrefecturesResolver | 正規化されていないテーブルからデータを取得する。都道府県IDごとに元データ EntityModelResident[] をグループ化する。 |
この考え方は、テーブルが正規化されている場合にも当てはまります。正規化されている場合、各Resolverの責務は次のようになります。
| Resolver | 責務 |
|---|---|
| ResidentResolver | Residentノードに紐づく葉ノード(id, name)を完成させる。 |
| CityResolver | Cityノードに紐づく葉ノード(id, name)を完成させる。住民テーブルからデータを取得する。 |
| PrefectureResolver | Prefectureノードに紐づく葉ノード(id, name)を完成させる。市区町村テーブルからデータを取得する。 |
| PrefecturesResolver | 都道府県テーブルからデータを取得する。 |
正規化されていれば、データを取得した時点で当然「子ノードがキーごとに区切られている」状態になるので、やっていることは同じです。
逆に言うと、正規化されていない場合も、正規化されている場合と同じタイミングでグループ化すればいいだけと考えると、混乱しなくてよいかもしれません。
実装のポイント
では、上記の設計方針に基づいて、各Resolverを作成していきます。
まず、PrefecturesResolverを作成します。
Prefecturesの子ノードは、Prefectureです。Prefectureは中間ノードなので、キーであるprefectureId単位でデータをグルーピングしてあげます。
import { Query, Resolver } from '@nestjs/graphql';
import { Prefecture } from '../prefecture/models/prefecture.model';
import { EntityModelResident } from './models/entityModelResident';
import { map, Observable, of } from 'rxjs';
@Resolver(() => [Prefecture])
export class PrefecturesResolver {
@Query(() => [Prefecture])
public prefectures(): Observable<Prefecture[]> {
return this.fetchMockData().pipe(
map((residents) => {
// 都道府県単位でデータをグループ化
// key: prefectureId, value: PrefectureのMapを作成
const prefectureMap = new Map<string, Prefecture>();
residents.forEach((resident) => {
const prefectureId = resident.prefectureId;
// 都道府県をマップに追加(初回のみ)
if (!prefectureMap.has(prefectureId)) {
prefectureMap.set(prefectureId, {
id: prefectureId,
name: resident.prefectureName,
cities: residents.filter((resident) => resident.prefectureId === prefectureId) // ここではcitiesを解決しない(PrefectureResolverの責務)
});
}
})
return Array.from(prefectureMap.values());
})
);
}
/**
* Backend APIを呼び出すメソッドのモック
* @returns 居住する都道府県、市区町村の情報をもった住民の一覧
*/
private fetchMockData(): Observable<EntityModelResident[]> {
return of([
//前提に記載したモックデータ
]);
}
}
次に、PrefectureResolverを作成します。
Prefectureの子ノードは、id, name, citiesです。idとnameは葉ノードなので完成させる必要がありますが、parentから渡ってきた同名のプロパティをセットするだけなので、省略可能です。
citiesは中間ノードなので、先ほど同様にキーであるcityId単位でデータをグルーピングしてあげます。
import { Parent, ResolveField, Resolver } from '@nestjs/graphql';
import { Prefecture } from './models/prefecture.model';
import { City } from '../city/models/city.model';
@Resolver(() => Prefecture)
export class PrefectureResolver {
@ResolveField(() => [City])
public cities(@Parent() parent: Prefecture): City[] {
const cities = parent.cities;
// 市区町村単位でデータをグループ化
// key: cityId, value: CityのMapを作成
const cityMap = new Map<string, City>();
cities.forEach((city) => {
const cityId = city.cityId;
// 市区町村をマップに追加(初回のみ)
if (!cityMap.has(cityId)) {
cityMap.set(cityId, {
id: cityId,
name: city.cityName,
residents: cities.filter((city) => city.cityId === cityId) // ここではresidentsを解決しない(CityResolverの責務)
});
}
})
return Array.from(cityMap.values());
}
}
ちなみに、idとnameを省略しない場合は、このように書きます。
// 同名のプロパティをセットするだけなので、省略可能
@ResolveField(() => String, { description: '都道府県ID', nullable: false })
public id(@Parent() parent: Prefecture): string {
return parent.id;
}
// 同名のプロパティをセットするだけなので、省略可能
@ResolveField(() => String, { description: '都道府県名', nullable: false })
public name(@Parent() parent: Prefecture): string {
return parent.id;
}
次に、CityResolverを作成します。ここまでくれば、こなれたものです。
Cityの子ノードは、id, name, residentsです。idとnameは葉ノードなので完成させる必要がありますが、parentから渡ってきた同名のプロパティをセットするだけなので、省略可能です。
residentsは中間ノードなので、先ほど同様にキーであるresidentId単位でデータをグルーピングしてあげます。
import { Parent, ResolveField, Resolver } from '@nestjs/graphql';
import { City } from './models/city.model';
import { Resident } from '../resident/models/resident.model';
@Resolver(() => City)
export class CityResolver {
@ResolveField(() => [Resident])
public residents(@Parent() parent: City): Resident[] {
const residents = parent.residents
// 住民単位でデータをグループ化
// key: residentId, value: ResidentのMapを作成
const residentMap = new Map<string, Resident>();
residents.forEach((resident) => {
const residentId = resident.residentId;
// 住民をマップに追加(初回のみ)
if (!residentMap.has(residentId)) {
residentMap.set(residentId, {
id: residentId,
name: resident.residentName,
});
}
})
return Array.from(residentMap.values());
}
}
最後に、ResidentResolverを作成します。
Residentの子ノードは、id, nameです。idとnameは葉ノードなので完成させる必要がありますが、parentから渡ってきた同名のプロパティをセットするだけなので、省略可能です。
import { Resolver } from '@nestjs/graphql';
import { Resident } from './models/resident.model';
@Resolver(() => Resident)
export class ResidentResolver { }
以上で、完成です。
↓それでは、サーバを起動してリクエストを投げてみましょう。
query {
prefectures{
id
name
cities {
id
name
residents {
id
name
}
}
}
}
↓すると、きちんとグルーピングされて返ってきました。
{
"data": {
"prefectures": [
{
"id": "p001",
"name": "p001",
"cities": [
{
"id": "c001",
"name": "Shinjuku",
"residents": [
{
"id": "r001",
"name": "Taro Yamada"
},
{
"id": "r002",
"name": "Hanako Suzuki"
}
]
},
{
"id": "c002",
"name": "Shibuya",
"residents": [
{
"id": "r003",
"name": "Kenji Tanaka"
}
]
}
]
},
{
"id": "p002",
"name": "p002",
"cities": [
{
"id": "c003",
"name": "Umeda",
"residents": [
{
"id": "r004",
"name": "Mika Sato"
}
]
}
]
}
]
}
}
以上、正規化されていないデータベースからレコードを取り出し、それを編集して綺麗なスキーマに載せ替えるケースにおける、各Resolverの責務の考え方でした。
実装例
詳細なソースコードを見たい方は、こちらをどうぞ。