まず始めに
モノリスアプリケーションをいかに安全に分解していくかのパターンを整理したものです。
「マイクロサービスは銀の弾丸ではない」
というのは各所で言われてますが、この記事も
「どうやってマイクロサービス化しようか」
を説明した記事ではなく、
「カオスになってしまったモノリスをどのように安全な状態にできるか」
に主眼を置いています。
さらに深い洞察を得たい方は以下の書籍が参考になるかと思います。
サービス境界を決める
一番最初にやらなければいけないことは、分割する単位(論理的な境界線)を決めることです。
.NET のマイクロサービス設計や DDD など参考にできるものは多々ありますが、この記事では割愛します。
(マイクロサービスとは?の復習は こちら)
アプリケーションの分割
「分割」といった時にアプリケーションコードの分割とインフラレベル(主にデータベース)の分割を考えます。
一般的にインフラレベルでの分割は難易度が高いので、まずはコードを疎結合にするというアプローチを取ります。
ストラングラーパターン
- ドメインに基づいてサービス境界を定義し、新サービスを段階的にリリースしていく方法
- モノリスを稼働したまま新サービスをデプロイし、部分的に呼び出しをスイッチする
- 以下のステップで実行される
- 移行対象を識別し、プロキシを差し込む(既にプロキシがあれば省略可能)
- 移行対象の機能をマイクロサービスで実装する
- 呼び出しをマイクロサービス にリダイレクトする
- 移行が完了したことが分かればモノリスの旧機能を削除する
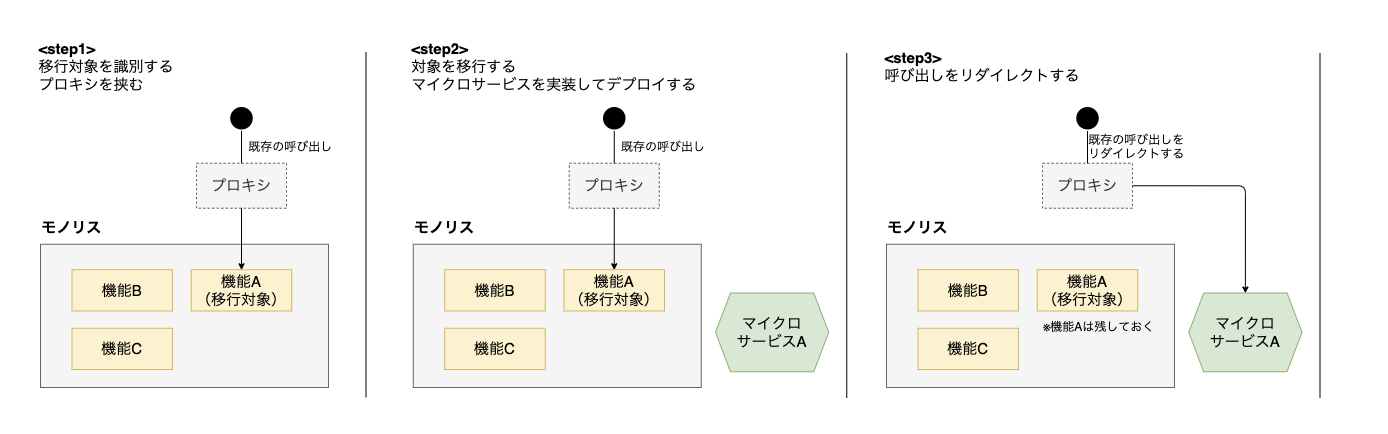
- 既存機能はそのまま残しておくことで簡単にフォールバックができる
- プロキシのターゲットを切り替えるだけ
- 呼び出しのスイッチングには HTTP リバースプロキシが利用できる
- プロキシがない場合は、新しくプロキシを差し込むが、レイテンシの悪化が看過できない場合は一旦立ち止まって検討する
- プロキシには nginx のような専用のプロキシサーバーを使ったり、ロードバランサー がパスベースルーティングに対応していればそれを使うこともできる
- デプロイとリリースを独立させておく
- プロキシが呼び出しを行わなければ、マイクロサービスを本番環境にデプロイしたからといって、それがユーザーにリリースされたとはならない
- 本番環境へのデプロイプロセスに慣れ、本番環境のランタイムでのテストも可能になる
- 同時実行やカナリアリリースなどを使って安全に切り替えができる
- プロキシ自体がファットにならないように注意する
- スマートエンドポイント、ダムパイプ
- 例えばプロキシが通信プロトコルの変換までやりだすと、対象のサービスが増えていったときに、プロキシで行う作業が肥大化していく
- 複数のチームが変更を管理する共有プロキシ層を作ってしまうと開発の独立性が失われる
- プロトコルマッピングなどはプロキシで行うのではなく、サービスの中で行うことで独立性を保つことができる
- 冗長にはなるかもしれないが、サービス単位で同じ機能を異なるコンシューマーに異なる方法で公開するといったことも可能
- サービスメッシュという考え方を取り入れるのも手段の一つ
UI合成パターン
ページ合成
- web ブラウザ画面のレンダリングをメインで行うようなアプリケーションの場合、ページ単位で切り出していくという方法が取れる
- ページ単位でリクエストをリダイレクトし、新しいサービスがページを生成して返す
ウィジェット合成
- サーバー側ではなくユーザーインターフェースにおいても、分割の手法は使える
- 画面を構成する要素を分解して、セクションごとに違うサービスで要素を生成できるようにする
- サーバーサイドでやる場合は、Appach の ENI 機能などを使って app サーバーが返した HTML や XML を、 web サーバーで合成して返すなどの手法が取れる
- クライアントサイドが(web ブラウザなど)モダンであれば、一つの画面の描画に際して複数の http エンドポイントから情報を取得することで、一部が欠けてもページ全体が表示できなくなることを回避できる
抽象化によるブランチパターン
- 移行したい機能のインターフェースを定義して、抽象に依存しようという話
- ストラングラーパターンを使うには、モノリスの外側で呼び出しを傍受できなければならない
- 抽出したい機能がモノリスの奥深くにある場合には、抽象化によるブランチが使える
- 例えば複数のモジュールから呼び出される通知サービスなど
- 一般的に、コードベースに手を加える場合はブランチを切って作業を行うが、長い間ブランチを分岐させておくのはコンフリクトのリスクが高い
- かといって徐々に細かくマージしていっては、その機能に依存する他のモジュールからの呼び出しに対する挙動を担保できないリスクがある
- そこで使えるのがコードの抽象化
- 抽象化によるブランチは次の5つのステップで実行される
- 置き換える機能の抽象を作る
- 作成した機能を使用するように既存機能のクライアントを変更する
- 機能を改良した抽象の実装を新たに作る
- 新しい実装を使用するように抽象を切り替える
- 抽象を後始末し、古い実装を削除する

- 抽象の実装を切り替える際はフィーチャーフラグなどなんらかの設定値を使って切り替えれば、切り戻すのも簡単にできる
- 移行する際に依存モジュールに手を加えなくて済む
- 失敗が許されず即時リカバリが必要な場合は、新旧の実装の手前にスイッチを置き、新を呼び出してエラーであれば旧をを呼び出す、というような状態にしておくこともできる
- ただし実装がかなり複雑になるし、各実装は自分の他に実装がいることを期待してないはずなのでデータの整合性には注意を払わなければならない
同時実行パターン
- 古い実装と新しい実装の両方を実行して結果を比較することで、それらが同等かを確認する
- 二つの異なるシステムを比較する場合も、同じシステム内で二つの機能を比較する場合も同じく有効
- 正確にはモノリスの分解というよりも、秘伝のタレマシマシの危険なアルゴリズムをなるべく安全にリプレースするというイメージ

- プログレッシブデリバリーの一種ではあるが、カナリアリリースやダークローンチと違って使うシチュエーションは限定的
- 複雑な計算アルゴリズムを要する機能などは、同時に新旧を動作させて、結果を比較することでアルゴリズムの正当性を担保できる
- 例えば、給与計算や帳簿作成など、あるインプットに対して特定の結果を計算して算出するような機能が考えられる
- アウトプットの比較に関しては人力でやってもいいのだけど、真面目にある程度の期間、結果を比較したいのであれば、比較用の機能を作って自動化した方が良い
- 冪等性が担保できない機能や、二重で処理されたくない機能(例えば通知など)は新サービスの方でその処理をスタブ化するなどの工夫が必要になる
デコレーティングコラボレーターパターン
- デコレーターがモノリスへの通信を傍受し、それに基づいてマイクロサービスを呼び出す
- モノリス内部の挙動に基づいて動作をトリガーしたいが、モノリス自体を変更できない場合に利用できる
- 例えば、注文に基づいてポイントを付与するポイントプログラムを作りたいが、注文サービスがレガシーすぎて手を加えられない時など
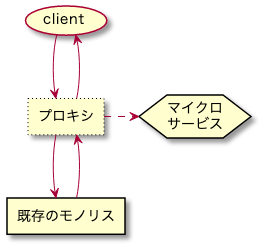
- デコレーターのスマートさを保つことを心がける
- デコレーターにコードを追加すればするほど、それ自体がマイクロサービスになってしまい、分散モノリスによる技術的な課題がそこに発生することになる
- また、既存のモノリスのレスポンスから十分なデータが取得できない場合は、マイクロサービスがモノリスを呼び出して、処理に必要な情報を取得する必要があるかもしれない
変更データキャプチャパターン
- モノリスへの通信を傍受するのではなく、モノリスのデータストアで行われた変更に反応するパターン
- このパターンではモノリスのデータストアと密結合することは避けられない

- 変更データをキャプチャするにはいくつかの手法がある
- データベーストリガー
- データベースに備わるカスタムトリガーを利用する
- ストアドプロシージャと同様、使いすぎるとシステムが実際にどのように動作するのかの見通しが悪くなる
- データベースに備わるカスタムトリガーを利用する
- トランザクションログ監視
- なんらかの監視ツールでログファイルを監視し、マイクロサービスを呼び出す
- メッセージに変換してメッセージブローカーに流してもいい
- もっともスッキリした手法で、結合や競合に関する懸念が少なくなる
- なんらかの監視ツールでログファイルを監視し、マイクロサービスを呼び出す
- バッチによる差分コピー
- データベーストリガー
データベースの分割
共有データベース
- 複数の異なるサービスが同一のデータベースを利用するのはリスクが高い
- ビジネスロジックの凝集度が低い場合、複数のビジネスロジックが同じテーブルを参照している場合もあり、その場合データ構造の変更を含む改修は全てのビジネスロジックに波及する
- 論理的な集まりとしてスキーマを定義しているかもしれないが、それが暗黙的であり、理解を難しくする
- ただし以下のような場合には有効かもしれない
- 安定したデータの参照に使う場合
- 国の通貨コードや郵便番号マスタなど
- 複数のコンシューマが参照するのを前提で設計、管理された定義済みエンドポイントとして、サービスがデータベースを直接公開している場合
- 安定したデータの参照に使う場合
データベースビュー
- ビューを使うと、サービスは元のスキーマの限定的な射影をスキーマとして提示でき、外部サービスに影響を与えることなく元のスキーマに手を加えることが可能になる
- 一般的にビューはクエリの結果から生成され、リードオンリーになるため、これ自体が有用性の制限となる
- また全てのデータベース製品がビューをサポートしているわけではない
- サポートしていたとしても、ソーススキーマとビューを同じデータベースエンジンに入れなければならない場合、デプロイ時結合を増やし、障害点をうむ可能性がある
- ビューの管理者(メンテナンス者)が誰であるかを決めておく必要がある
- 既存のモノリシックスキーマを分解することが現実的でない場合には有効だが、最終的なゴールがサービス間インターフェースを介してデータをやり取りすることであれば、やはりモノリシックスキーマを分割せざるを得ない
データベースをラップするサービス
- データベースを薄いラッパーとして機能するサービスの後ろに隠し、データベースへの依存関係をサービスへの依存関係に移動する
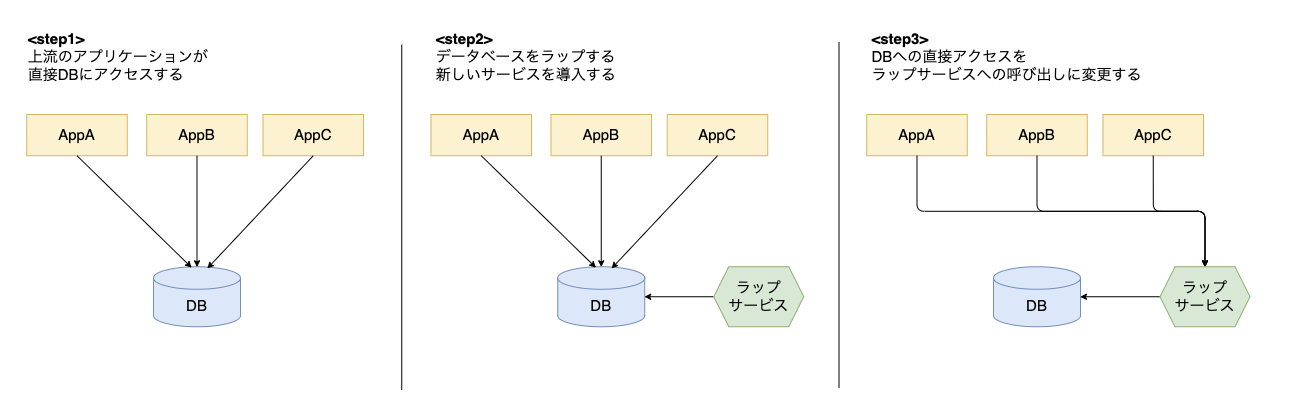
- データスキーマへの直接的な参照を剥がすことで、スキーマを分解する足がかりになる
- 上流のアプリケーションにとって、下流のスキーマをどのように利用しているかの理解の手助けとなる
- データベースビューと比べて以下のような利点がある
- ラッパーサービスに依頼すればデータの書き込みも行える
- ラッピングサービスにコードを記述することで、より洗練された射影を提示することができる
サービスのインターフェースとしてのデータベース
- クライアントが読み取り専用のデータベースを必要としている場合は、サービス内部用のデータベースとは異なる公開用のデータベースを提供する方法がある
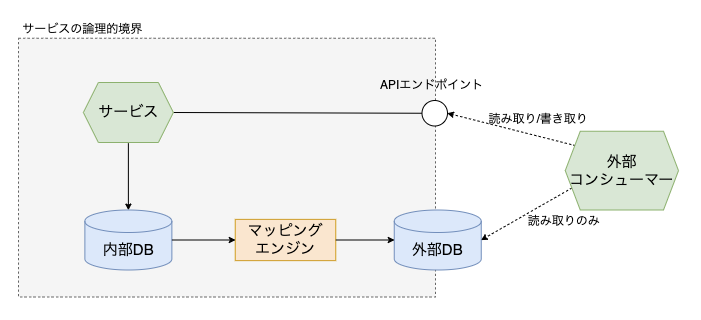
- マッピングエンジンを作って、内部用のデータベースへの変更を読み取り用の公開データベースに反映させる
- マッピングエンジンは内部と外部の間の抽象レイヤーであり、内部データベースのスキーマが変更された場合、外部データベースが一貫性を保てるように修正されなければならない
- 実装の仕方にもよるが、外部データベースへの変更は遅延を伴うので、外部のコンシューマーは自分が取得したデータが最新のものかに気を遣う必要がある
- マッピングエンジンの実装選択肢
- 変更データキャプチャパターンを使う
- バッチで処理する
- Debezium など専用の変換ツールを使う
- データベースビューとは違い特定の技術スタックに縛られにくい
- 例えばビューの場合は内部データベースが Oracle の場合、ビューも同じ Oracle データベース内に作成しなければならないが、マッピングエンジンを挟めば内部と外部で全く違ったデータベースを利用できる
所有権を移す
データ所有権の変更
- モノリスにあるデータが、新たに抽出したサービスに管理されるべきデータの場合、データの所有権を移動する必要がある
- 例えば請求書サービスを考えた場合、以下のように請求書データを移行し、モノリスは請求書サービスのエンドポイントを呼び出して、データの読み書きを行う

データ同期
ストラングラーパターンなどコードレベルで分割を進める過程で、どのようにデータの整合性を保つかという問題がある。
ここからはデータを移行する際の手法を説明する
アプリケーションでのデータ同期
- step1. データを一括で同期する
- step2. データを小刻みに同期する
- step3. 新サービスをデプロイし、同期のために両方に書き込み、古いスキーマから読み取る
- step4. 同期のために両方に書き込み、新しいスキーマから読み取る
- step5. 新サービス × 新 DB が安定したら、古い DB を削除する

- 両方のデータベースに書き込みを行うのはフォールバックの可能性を残すため
- コードを分割する前にスキーマを分割したい場合には、有効な手段である
- カナリアリリースなど、旧サービスと新サービスの両方がデータの書き込みを行う場合、どちらかが間違うと致命的なのでオススメできない
トレーサー書き込み
- データの真の情報源を段階的に移行する
- 移行中には真の情報源が2箇所に分散することを許容することで、段階的な移行を可能にする
- モノリスの持っているデータを同期し、徐々に読み取りをサービスに向けていく

- この例では、モノリスを含め全てのコンシューマーが請求書サービスを使用して請求書データにアクセスするようになること
- データの同期は一般的には遅延するので、どれぐらいの遅延が許容できるかは先に検討しておかなければならない
データベースを分割する
データベースの分離にはと論理的な分離と物理的な分離がある
論理的な分離
- 論理的な分離はデータスキーマの境界を定義すること
- 独立した変更と情報隠蔽を容易にする

物理的な分離
- 物理的な分離は異なるデータベースエンジンを利用すること
- 堅牢性を向上させ、リソースの競合を排除してスループットとレイテンシを改善する
- ただし、多くのデータベースサービスはマルチプライマリデータベースやウォームスタンバイなどの障害耐性機能を提供しているため、堅牢性の観点ではかけた時間やコストに見合うリターンは生まれにくいかもしれない

データベースを最初に分割するパターン
- 最初にスキーマを分割することで、パフォーマンスとトランザクション整合性に関する問題を早期に発見できる可能性がある
- 依然としてモノリシックなコードのデプロイが残るので短期的にはあまり利益が得られない
- モノリス自体が商用ソフトウェアのようなブラックボックスシステムの場合は、この手法は取れない
コードを最初に分割するパターン
- 多くのチームがこのアプローチを取る
- サービスの境界を考えることで、新しいサービスがどのようなデータを必要としているのかが理解しやすくなる
- 独立してデプロイ可能なコード成果物が早い段階で手に入る
- サービスを切り出した段階でデータベースの分離を諦めてしまうと、新しい混沌を生むことになる
データベースとコードを一緒に分割するパターン
- ビッグバンリライトは新たなビッグバンを生むだけなので、できればこの方法は避けたい
スキーマを分割する
テーブルの分割
- 誰が、どのデータを所有すべきかを判断する
- 様々なデータを複合的に管理しているテーブルを所有権に則って分割する
- 一つのカラムを複数の機能が参照/更新している場合は、所有権に則ってテーブルを分割した上で、所有権を持たないサービスはそのデータを所有しているサービスを呼び出す必要がある
外部キー
- データスキーマを分割すると、今まで外部キー制約を張ることで保たれていたデータの一貫性が担保できなくなる
- まずは、一つであるべき物を二つ以上に分解しようとしていないかを確認する
- 外部キーの概念をコードに移動する必要がある
- 一方のデータスキーマでデータが削除された場合に一貫性を保てなくなるが、それには以下の方法で対処する
- 削除前にチェックする
- 削除する前に削除対象のデータを参照していないかを他のサービスに問い合わせる
- この方法はテーブルのロックを強制する
- 参照される側が参照する側に問い合わせるという事実上の逆依存が発生する
- 削除されることがあるという前提のもと振る舞う
- データがない場合の挙動を定義しておく
- 参照される側は 410 を返して以前はデータがあったことを表明する
- 削除を許可しない
- 論理削除することでデータが削除されるという事象自体を回避する
- 削除前にチェックする
共有静的データ
- 例えば国コードや通過コードなど、更新頻度は低く、複数のサービスが共通で参照したいデータの扱い
- 静的参照データを複製する
- 個々のサービスにデータをコピーして持たせる
- 専用の参照データスキーマを作る
- データフォーマットを変更する場合、参照する全てのサービスに影響が出る
- 静的参照データ用のライブラリを作る
- データが単純かつ少ない場合、静的な列挙型に収まる
- 技術スタックが混在している場合、単一のライブラリを使い回せない可能性がある
- バージョン管理の必要性が出てくるので、サービス間でのデータの一貫性は保証しづらい
- 静的参照データ用のサービスを作る
- データが少ない場合、インメモリに格納したものをそのまま返せるのでレイテンシの悪化は気にならないかもしれない
- レイテンシが厳しい場合、各サービスがデータをキャッシュすることが考えられるが、静的データ参照サービスが更新のイベントをパブリッシュし個々のサービスがそれをサブスクライブすることで随時キャッシュをアップデートできる
- 静的参照データを複製する
- 全てのサービスで常にデータが一貫している必要がない場合は共有ライブラリで実現するのが楽
- データが複雑であったり大規模なデータの場合、各サービスのローカルデータベースに入れてしまう方が良さそう
- サービス間でデータの一貫性を持たせる必要がある場合、専用のサービスを作ることを検討する
トランザクション
- データスキーマを分割した時の一番の問題は、複数サービスにまたがるデータのトランザクション整合性をどのように保つかということ
- サーガパターンや結果整合性など複雑なアーキテクチャを用いる必要がある