目次
1.はじめに
2.本記事の概要
3.どのような信号処理フィルター
通常のフィルター
今回の深層学習フィルターの狙い
4.作成したプログラム
学習データの生成
オートエンコーダ手法を使用
学習過程
5.結果
今回の深層学習フィルターの出力
学習済データの出力
未学習データの出力
今回の深層学習フィルターの欠点
周波数成分が大きく変化する
振幅の変化率が一定でない
6.終わりに
1.はじめに
初めまして、ソフトウエア設計者のnakarinrinと申します。
ソフトウエア設計を組込/PCアプリ中心に30年程携わり、その後10年近く管理職と
なっていました。退職を機にソフトウエア設計に再び関わりたいと思っていますが
あらたな技術を習得すべく、アイデミーさんのAI講座を受講しています。
その中で受講の成果として、成果物に関する記事を作成する必要があり、今回
稚拙な内容ですが投稿させていただきます。
なお、本記事記載の開発は
Spyder 4.2.5
にて以下を使用して行いました。
Python 3.8.8
numpy 1.22.3
matplotlib 3.5.1
tensorflow 2.9.1
scikit-learn 1.1.1
2.本記事の概要
深層学習の手法の一つであるオートエンコーダ(Autoencode)を信号の振幅等に反応する
特殊なフィルタに利用した適用例と欠点を記載してしています。
残念ながら実用的に利用できるフィルターとなっておりませんので、まだまだ改善が必要
な例です。深層学習の信号処理への適用のヒント/限界の一例としてお読みいただければ
幸いです。
3.どのような信号処理フィルター
信号処理の中でも今回対象とするのはノイズ除去のための信号処理です。
先ず通常のノイズ除去の為の信号処理フィルター(以下フィルターと略)を説明し、
次に今回の深層学習フィルターの狙いを記載します。
通常のフィルター
下図のように1Hzの信号が有った場合、信号の受信までに至る外乱等からの
ノイズが付加された観測データがフィルターの対象となります。
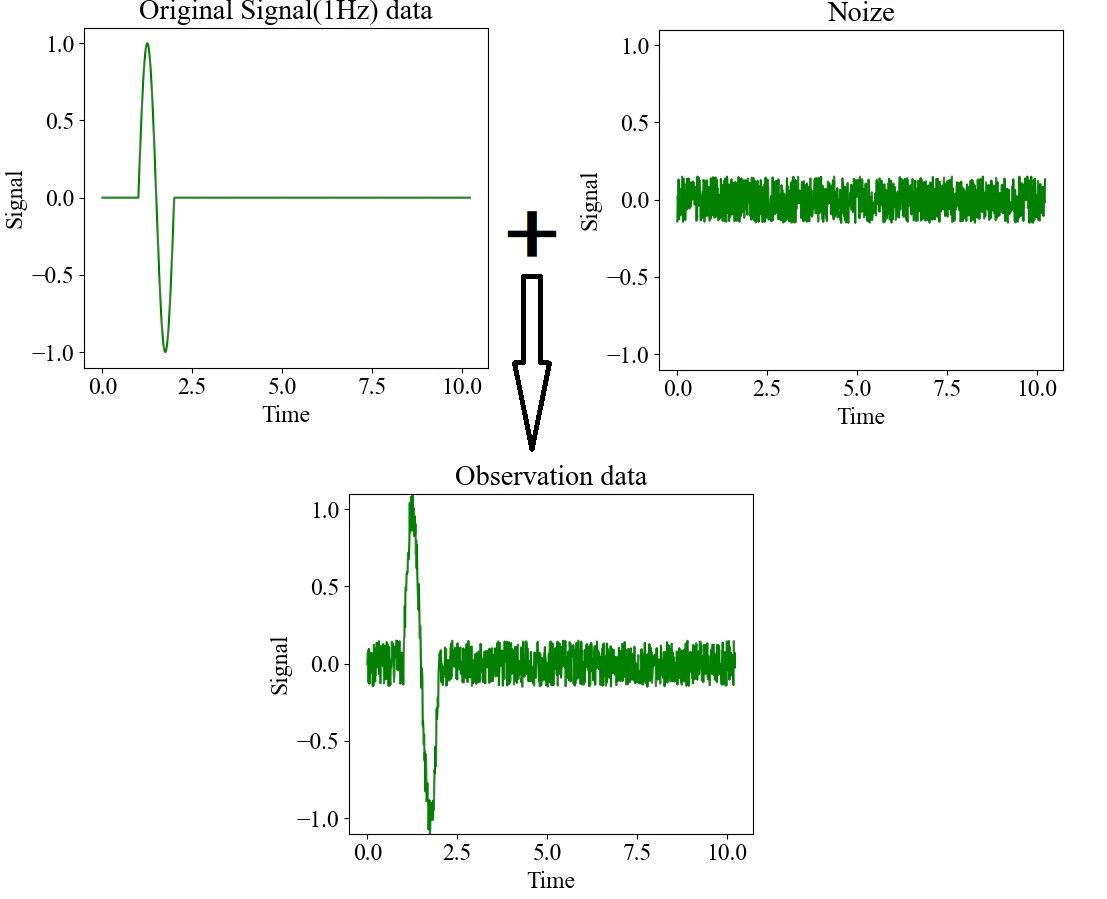
この観測データに対して通常のフィルターは、観測データを周波数成分として捉え
周波数成分の中で本来の信号に特有な成分近傍のみ取り出し、本来の信号に近づける
処理を行います。
例えば下図は観測データをFFTという周波数解析を行い、本来の信号の周波数成分近傍
(下図では5Hz以下)のみを取り出しデータを再構成することで、ノイズを低減させ
本来の信号に近づけます。

今回の深層学習フィルターの狙い
前述の周波数成分に着目したフィルターはnumpyのFFT関数とiFFT関数等で容易に
実現できるで、これらフィルターが不得意な信号処理に深層学習が適用できないか?
と考えたのが発端です。
前述フィルターは周波数成分の違いで本来の信号とノイズを分別しているので、
不得意なものとして、何らかの理由で信号とノイズがデータの振れの幅
(振幅と呼びます)は異なるものの、同じ周波数成分で重なりあっている
下図観測データを仮定します。
(実際にはこのような現象と分別の需要はほとんど無いとは思いますが...)
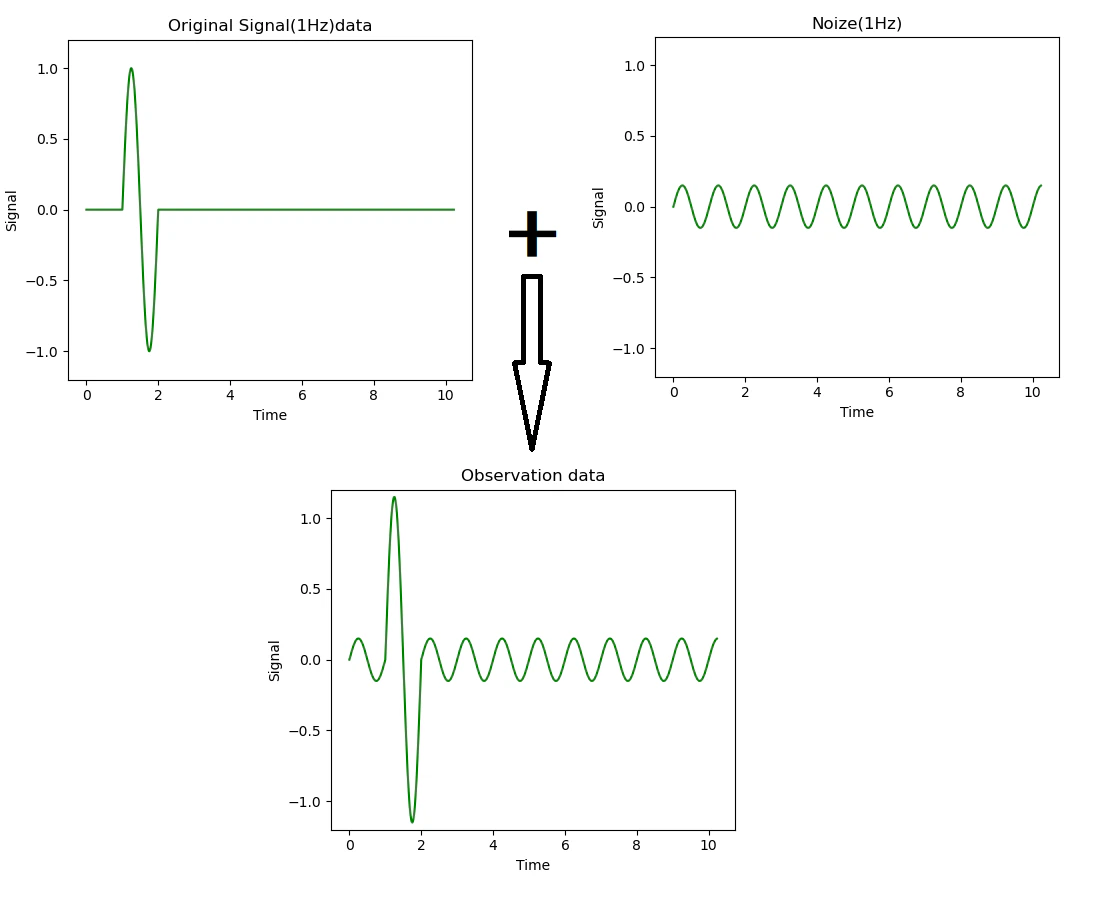
上図の様な観測データの場合、前述の周波数解析とそこからの再構成をしても、
ノイズと本来の信号の周波数成分の差がなくノイズの低減ができません。
(下図は前述と同様に5Hz以下のみ取り出した場合)
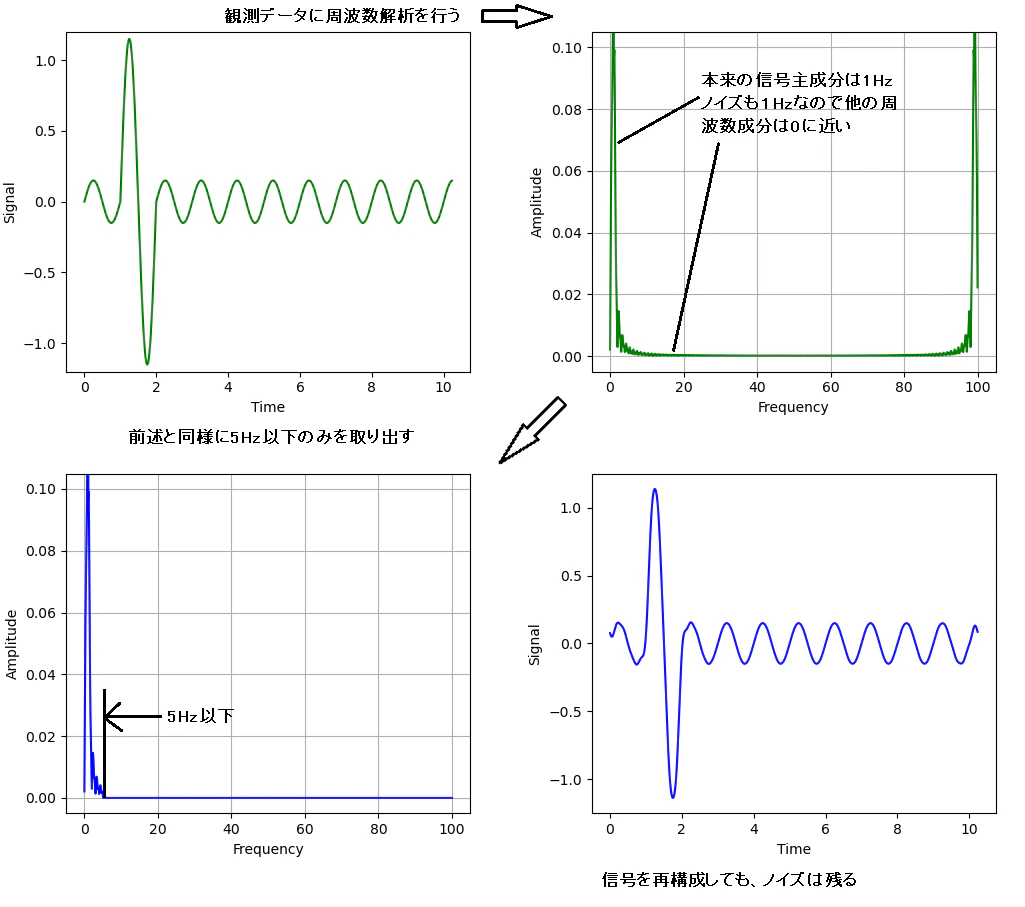
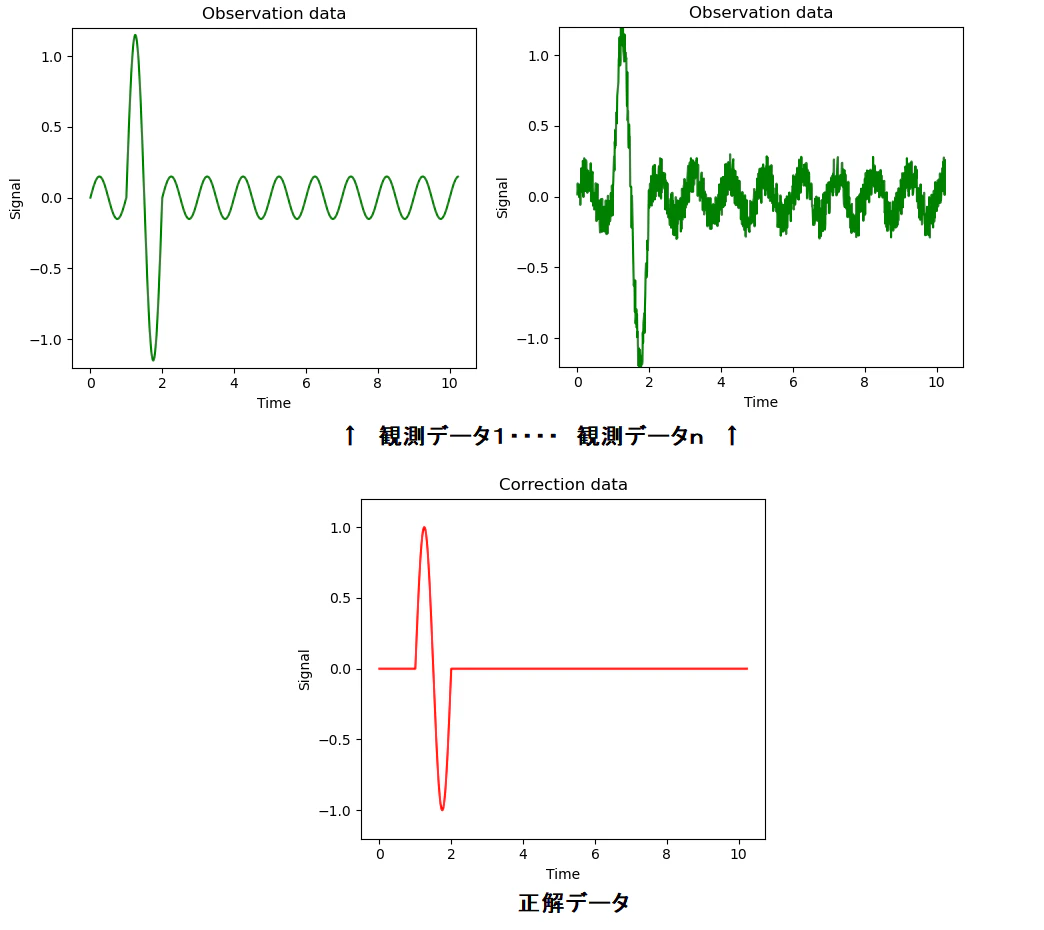
今回はこのような信号とノイズが同じ周波数で重なりあっている下図のような
観測データと正解データを多数与え、深層学習を行うことにより観測データ中の
本来の信号の振幅等の特徴から、本来の信号とノイズを判別することで、
信号とノイズが同じ周波数で重なりあっているデータのノイズを低減する
深層学習フィルターを作成することを狙いとしました。
4.作成したプログラム
プログラムソース
# -*- coding: utf-8 -*-
"""
Created on Sat Jul 16 18:45:59 2022
@author: nakatani
"""
import os
import numpy as np
import matplotlib.pyplot as plt
import itertools
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import losses
from tensorflow.keras.models import Model
from tensorflow.keras.models import load_model
from tensorflow.keras.callbacks import EarlyStopping
from sklearn.model_selection import KFold
"""
CNNオートエンコーダ
オートエンコーダクラス
https://www.tensorflow.org/tutorials/generative/autoencoder
の2番目の例:画像のノイズ除去 を参考に作成
上記例では最終出力の活性化関数をsigmoidにしているが、sigmoidではマイナス値の出力がされない
(オフセットの加算、減算での値調整も試みたがやはりマイナス値の出力はされない)
ので活性化関数をlinearにしている(linearのlayerでの追加方法が和からなったため、文字列指定としている)
波形は同周期ノイズ/ホワイトノイズを加えてもらしい形となったが、振幅のずれが有り波形がなまったり、先鋭化して信号周波数に対して、大きく周波数が分散するように
なってしまった。信号処理としては戴けないかも
"""
# データのパラメータ
data_n=1024 #観測データ及び理想データの1組のデータ長
dt = 0.01 # サンプリング間隔[s]
time = np.arange(0, data_n*dt, dt) # データ長とサンプリング間隔から時間データ作成
def make_data(signal_fqs,sig_st_poss,sig_lens,conf_gains,white_noize_gains):
"""
観測データスムージング課題の学習・検証データ群を引数に従ってその組み合わせで作成する
signal_fqs:信号周波数リスト[Hz]
sig_st_poss:信号のスタート位置リスト[点数]
sig_lens:信号の長さ[点数]
sig_st_poss(の一つの要素)で指定された点からsig_lens(の一つの要素)でしてされた点数分
signal_fqs(の一つの要素)で指定されたで周波数で信号が作成される
=0なら信号無し
conf_gains:信号と同周波数の重畳するノイズの信号に対するGainのリスト
signal_fqs~sig_lens指定された信号に対し
signal_fqs(の一つの要素)で指定されたで周波数と同周波数のノイズを
conf_gains(の一つの要素)で指定されたゲイン(0~1.0,=0はノイズなし)
でデータ全域に付加する
white_noize_gains:信号に重畳するホワイトノイズの信号に対するGainのリスト
作成された指定された信号に対し ホワイトノイズを
white_noize_gains(の一つの要素)で指定されたゲイン(0~1.0,=0はノイズなし)
でデータ全域に付加する
また以下のグローバル変数にも従う
data_n:データ長[点数]
dt:サンプリング間隔[s]
time:時間データ配列[s]
戻り値:ndarray 観測データ[データ組数,data_n],ndarray 理想データ[データ組数,data_n
"""
#戻りndarrayの作成
X=np.empty([0,data_n]) #空の観測データ配列生成
y=np.empty([0,data_n]) #空の理想データ配列生成
for white_noize_gain in white_noize_gains:
for conflict_gain in conf_gains:
for signal_fq in signal_fqs:
for signal_len in sig_lens:
make_len_data=False
for signal_st in sig_st_poss:
#信号無しデータが多数作成され、それに引きずられ過ぎないように信号無しデータの生成数を制限する
if (signal_len==0)and (make_len_data==True):
continue
#信号を出力制御SW配列 =0の時出力しない =1出力する
signal_sw=np.zeros(data_n)
signal_end=signal_st+signal_len
if (signal_end>data_n):
#有意箇所発生位置と長さの関係がデータ長をはみ出さないように上限設定
signal_end=data_n
signal_sw[signal_st:signal_end]=1
# 信号(signal_st分開始点がずれた周波数signal_fq正弦波)の生成(signal_sw[]が1のところだけ)
sig = np.sin(2*np.pi*signal_fq*(time-time[signal_st]))*signal_sw
y=np.vstack([y,sig.reshape(1,data_n)])
#信号を理想データ配列に追加
# 信号と同周波数で重畳するノイズの付加
observe_sig = sig+ np.sin(2*np.pi*signal_fq*time)*conflict_gain
# 信号重畳するホワイトノイズの付加
#(np.random.rand()の戻り値0~1.0を-1.0から1.0に変換してからwhite_noize_gainを乗ずる)
observe_sig = observe_sig+(np.random.rand(data_n)-0.5)*2.0*white_noize_gain
X=np.vstack([X,observe_sig.reshape(1,data_n)])
#ノイズが付加された信号を観測データ配列に追加
make_len_data=True
return (X,y)
signal_fqs=[1.0,2.0,3.0,5.0,7.0,10.0] #信号周波数[Hz]
sig_st_poss=np.arange(0,1000,150) #信号有意箇所の発生位置[サンプリング数]
sig_lens=[100,0,200,500,data_n] #信号有意箇所の長さ[サンプリング数]
# 長さを0として信号なしを作る
conf_gains=[0.0,0.05,0.1] #信号と同周波数の重畳するノイズの信号に対するGain
white_noize_gains=[0.0,0.05,0.1] #信号に重畳するホワイトノイズの信号に対するGain
X,y=make_data(signal_fqs,sig_st_poss,sig_lens,conf_gains,white_noize_gains)
def plot_Xy_properly(pridict_y):
"""
作成された観測データと理想データと(予測データ)を確認用に適当に表示する
pridict_y:予測データ yと同じ形状とする必要あり
"""
fig_n=9 #図を9枚表示
data_no_float=0.0
data_no_step=float(X.shape[0])/float(9*fig_n)
for i in range(fig_n):
fig ,axes = plt.subplots(figsize=(12,12),ncols=3,nrows=3) #9個の新しいグラフ
for axis in itertools.chain.from_iterable(axes):
data_no_int=round(data_no_float)
data_no_float+=data_no_step
if X.shape[0]>data_no_int :
"""
一つの観測データと理想データの組を指定された表示領域に表示する
data_no:観測データX 理想データy配列上の要素番号
axis:表示領域
"""
axis.set_xlabel("Time")
axis.set_ylim(-1.2,1.2)
axis.plot(time,X[data_no_int],color="g",label="Observation data",alpha=0.5)
axis.plot(time,y[data_no_int],color="r",label="Correction data",alpha=0.5)
if not(pridict_y is None) :
axis.plot(time,pridict_y[data_no_int],color="b",label="Prediction data",alpha=0.5)
#Figで共通な凡例を表示
lines, labels = axis.get_legend_handles_labels()
fig.legend(lines, labels, loc = 'upper center',borderaxespad=0)
plt.show()
#plot_Xy_properly(None) #作成データ確認用
def adj_1d_data_for_Conv1D(data):
"""
numpyの1次元データをKerasのConv1D()用に調整する
・(オリジナル保持のために)データのコピーを作成し
・コピーされたデータに次元を追加
keras ConvXDはデータ配列として(データ組数、1組のデータ長、パラメータ数)を必要とするので
それに合わせる
戻り値:KerasのConv1D用データ
"""
#keras ConvXD用のデータ調整(コピー)
data_cnn=data.copy()
#keras ConvXD用のデータ調整(次元付加)
# keras ConvXDはデータ配列として(データ組数、1組のデータ長、パラメータ数)を要求するので次元を追加
data_cnn=np.expand_dims(data_cnn,-1)
return data_cnn
#keras ConvXD用データ用意
X_cnn=adj_1d_data_for_Conv1D(X)
y_cnn=adj_1d_data_for_Conv1D(y)
class cnn_autoencoder(Model):
"""
オートエンコーダクラス
https://www.tensorflow.org/tutorials/generative/autoencoder
を参照して作成
"""
def __init__(self):
super(cnn_autoencoder, self).__init__()
self.encoder = tf.keras.Sequential(
[
layers.Conv1D(512, 3, input_shape=(data_n, 1), padding='same'),
layers.ReLU(),
layers.Conv1D(256, 3, padding='same'),
layers.ReLU(),
layers.Conv1D(128, 3, padding='same'),
layers.ReLU()
]
)
self.decoder = tf.keras.Sequential(
[
layers.Conv1DTranspose(128, 3, padding='same'),
layers.ReLU(),
layers.Conv1DTranspose(256, 3, padding='same'),
layers.ReLU(),
layers.Conv1DTranspose(512, 3, padding='same'),
layers.ReLU(),
layers.Conv1D(1, 3, activation='linear', padding='same')
]
)
def call(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
def get_fitted_model():
"""
学習済 信号スムーサモデルを取得する
カレントディレクトリに"SignalSmoother"というディレクトリを確認し、
・"SignalSmoother"が存在するならばそれコンパイル済、学習済モデルとして読み込み
・ディレクトリが存在しなければ"OrgSignalSmoother"というディレクトリを確認し、
+"OrgSignalSmoother"が存在するならばそれコンパイル済、学習済モデルとして読み込み
ここで設定された学習データにて追加学習をおこない"SignalSmoother"といディレクトリに保存する
+"OrgSignalSmoother"が存在しなければモデルを生成・コンパイルし、学習を行い、
"SignalSmoother"といディレクトリに保存する
戻り値:学習済 信号スムーサモデル
"""
def fit_by_5Fold(model):
"""
5分割の交差検証で学習を行う
model:学習を行うモデル
"""
kf = KFold(n_splits=5, random_state=0, shuffle=True)
train_mae_list=[] #学習過程記録用
val_mae_list=[] #学習過程記録用
#学習停止用コールバック val_lossを監視して、自動推測で停止、1回だけ追加試行する
early_stopping =EarlyStopping(monitor='val_loss',patience=1,mode='auto')
# K-分割交差検証での学習ループ
for i ,(trn_index, val_index) in enumerate(kf.split(X_cnn, y_cnn)):
X_train ,X_val = X_cnn[trn_index], X_cnn[val_index]
y_train ,y_val = y_cnn[trn_index], y_cnn[val_index]
model.fit(
x=X_train,
y=y_train,
epochs=10,
validation_data=(X_val, y_val),
verbose=1,
callbacks=[early_stopping]
)
y_pred = model.predict(X_train)
train_mae =losses.mean_absolute_error(y_train,y_pred)
train_mae_list.append(np.mean(train_mae))
y_pred_val = model.predict(X_val)
val_mae =losses.mean_absolute_error(y_val,y_pred_val)
val_mae_list.append(np.mean(val_mae))
print('-'*10 + 'Result' +'-'*10)
print('Train_mae : {0} , Ave : {1}'.format(train_mae_list,np.mean(train_mae_list)))
print('Valid_mae : {0} , Ave : {1}'.format(val_mae_list,np.mean(val_mae_list)))
#ディレクトリ確認
model_dir_name="SignalSmoother"
if os.path.exists(model_dir_name) :
#コンパイル済、学習済モデルとして読み込み
model=load_model(model_dir_name)
else:
#Orgディレクトリ確認
org_model_dir_name="Org"+model_dir_name
if not os.path.exists(org_model_dir_name) :
#Orgディレクトリなければモデルの生成・コンパイル
model = cnn_autoencoder()
model.compile(optimizer='adam', loss='mse')
else:
#Orgディレクトリ有ればコンパイル済、学習済モデルとして読み込み
model=load_model(org_model_dir_name)
print(org_model_dir_name+" Load")
#モデルの学習(Orgディレクトリ有った場合は追加学習)
# K-分割交差検証(5分割)で学習
fit_by_5Fold(model)
#学習済 信号スムーサモデルを保存
model.save(model_dir_name)
return model #学習済 信号スムーサモデルを返す
#学習済 信号スムーサモデル取得
model=get_fitted_model()
#全データの適用確認
y_pred= model.predict(X_cnn)
plot_Xy_properly(y_pred)
#特定データの適用確認
#特定データ作成
signal_fqs=[1]
sig_st_poss=[200] #信号有意箇所の発生位置[サンプリング数]
sig_lens=[500] #信号有意箇所の長さ[サンプリング数]
#長さを0として信号なしを作る
conf_gains=[0] #信号と同周波数の重畳するノイズの信号に対するGain
white_noize_gains=[0] #信号に重畳するホワイトノイズの信号に対するGain
roi_X,roi_y=make_data(signal_fqs,sig_st_poss,sig_lens,conf_gains,white_noize_gains)
roi_X_cnn=adj_1d_data_for_Conv1D(roi_X)
if(len(roi_X_cnn)>0):
roi_y_pred=model.predict(roi_X_cnn)
def plot_one_Xy(roi_X,roi_y,roi_pridict_y,data_no,add_fft):
"""
指定されたX,y,pridict_y配列の要素番号のデータを確認用に適当に表示する
roi_X:表示したい元データデータ配列
roi_y:表示したい正解データデータ配列
pridict_y:表示したい予測データ配列
roi_X,roi_y,pridict_y全て同じ形状とする必要あり
data_no:要素番号
add_fft:周波数解析を追加するか? =True 追加する =False 追加しない
"""
axis_rows=2
if add_fft==True :
axis_cols=2
else:
axis_cols=1
axis_no=1
fig =plt.figure(figsize=(12,12)) #新しいグラフ
fig.subplots_adjust(wspace=0.3,hspace=0.3)
#観測データグラフ
axis =fig.add_subplot(axis_rows,axis_cols,axis_no)
axis.set_xlabel("Time")
axis.set_ylabel("Signal")
axis.set_ylim(-1.2,1.2)
axis.set_title("Observation data")
axis.plot(time,roi_X[data_no],color="g",alpha=0.5)
#観測データ周波数解析
if add_fft==True :
freq = np.linspace(0, 1.0/dt, data_n) # FFTにおける周波数
fft_roi_X = np.fft.fft(roi_X[data_no])
fft_roi_X = fft_roi_X/(data_n/2)
fft_roi_X[0] = fft_roi_X[0]/2
#観測データ周波数解析グラフ
axis_no+=1
axis =fig.add_subplot(axis_rows,axis_cols,axis_no)
axis.set_xlabel("Frequency")
axis.set_ylabel("Amplitude")
axis.set_ylim(-0.005,0.105)
axis.set_title("FFT(Observation data)")
axis.grid(visible=True)
axis.plot(freq, np.abs(fft_roi_X),color="g",alpha=0.5)
#目標データと予測データグラフ
axis_no+=1
axis =fig.add_subplot(axis_rows,axis_cols,axis_no)
axis.set_xlabel("Time")
axis.set_ylabel("Signal")
axis.set_ylim(-1.2,1.2)
axis.set_title("Correction/Prediction data")
axis.plot(time,roi_y[data_no],color="r",label="Correction",alpha=0.5)
if not(roi_pridict_y is None) :
axis.plot(time,roi_pridict_y[data_no],color="b",label="Prediction",alpha=0.5)
axis.legend()
if add_fft==True :
#予測データ周波数解析グラフ
fft_roi_pridict_y = np.fft.fft(roi_pridict_y[data_no])
fft_roi_pridict_y = fft_roi_pridict_y/(data_n/2)
fft_roi_pridict_y[0] =fft_roi_pridict_y[0]/2
#予測データ周波数解析グラフ
axis_no+=1
axis =fig.add_subplot(axis_rows,axis_cols,axis_no)
axis.set_xlabel("Frequency")
axis.set_ylabel("Amplitude")
axis.set_ylim(-0.005,0.105)
axis.set_title("FFT(Prediction data)")
axis.grid(visible=True)
axis.plot(freq, np.abs(fft_roi_pridict_y),color="b",alpha=0.5)
plt.show()
#特定データの適用結果表示
for data_no in range(0,len(roi_X)) :
plot_one_Xy(roi_X,roi_y,roi_y_pred,data_no,True)
上記折りたたみ表示してある上記が今回作成したプログラムのソースコード
となっています。作成にあたってのポイントを下記に記載します。
学習データの生成
今回仮定した、信号とノイズが同じ周波数成分で重なりあっている観測データは、
自然現象では希で既存のデータリポジトリ等での存在は期待できないため、
このプログラムの中で生成を行っています。
10秒間のデータを0.01秒の間隔で取得した1024点のデータを観測データ
(学習における説明変数)とし、下記属性を複数設定し多数の学習データ
を生成しています。
1.信号周波数[Hz]:信号と重なり合っているノイズの周波数
2.信号の開始位置[点数]:何点目から信号を生成させるか
3.信号の長さ[点数]: 何点間から信号を継続させるか =0は信号が無い場合
4.信号と同周波数のノイズの振幅比:
信号の振幅を1.0とした時の対する同周波数のノイズの振幅比
=0なら 信号と同周波数のノイズなし
5.ホワイトノイズの振幅比:
信号と同周波数のノイズ以外の一般的なノイズとされるホワイトノイズの
信号の振幅を1.0とした時の対する振幅比
=0なら ホワイトノイズノイズなし
観測データの生成と同時に上記属性の4.と5.を0としたノイズがないデータを
正解データ(学習における目標変数として)として生成します。
今回は属性の設定を
1.信号周波数1.0,2.0,3.0,5.0,7.0,10.0Hz の6種
2.信号の開始位置 0,150,300,450,600,750,900点の7種
3.信号の長さ 100,0,200,500,1024点の5種
4.信号と同周波数のノイズの振幅比 0,0.05,0.1の3種
5.ホワイトノイズの振幅比 0.0,0.05,0.1の3種
としました。
通常ですと6x7x5x3x3=1890組の組み合わせとなるところですが、この中で
信号無しのデータが(正解データが0の直線となる)に学習が引きずられない
過ぎないように信号無しのデータを減らした
1566組を生成し、学習データとしています。
なお、属性値の設定にあたり、
・1.の信号周波数は倍数波とならないよう素数の波数を主体とし、
さらに後述オートエンコーダでの目的である圧縮(今回は1/10)の確認
のためにデータ間隔の1/10となる0.1秒周期の10Hzを付加しています。
・4.の信号と同周波数のノイズの振幅比と5.ホワイトノイズの振幅比は
学習の判別の核=信号がノイズに対し際立って大きい とするため
2つのノイズの合計比が信号に対して0.2以下となるようにしています。
上記の考えで生成した学習データの例を下図に記載します。
(図中 緑線が観測データ 赤線が正解データ となります)

参考に下記に学習データ生成部分のコード抜粋を記載します。
学習データ生成
# データのパラメータ
data_n=1024 #観測データ及び理想データの1組のデータ長
dt = 0.01 # サンプリング間隔[s]
time = np.arange(0, data_n*dt, dt) # データ長とサンプリング間隔から時間データ作成
def make_data(signal_fqs,sig_st_poss,sig_lens,conf_gains,white_noize_gains):
"""
観測データスムージング課題の学習・検証データ群を引数に従ってその組み合わせで作成する
signal_fqs:信号周波数リスト[Hz]
sig_st_poss:信号のスタート位置リスト[点数]
sig_lens:信号の長さ[点数]
sig_st_poss(の一つの要素)で指定された点からsig_lens(の一つの要素)でしてされた点数分
signal_fqs(の一つの要素)で指定されたで周波数で信号が作成される
=0なら信号無し
conf_gains:信号と同周波数の重畳するノイズの信号に対するGainのリスト
signal_fqs~sig_lens指定された信号に対し
signal_fqs(の一つの要素)で指定されたで周波数と同周波数のノイズを
conf_gains(の一つの要素)で指定されたゲイン(0~1.0,=0はノイズなし)
でデータ全域に付加する
white_noize_gains:信号に重畳するホワイトノイズの信号に対するGainのリスト
作成された指定された信号に対し ホワイトノイズを
white_noize_gains(の一つの要素)で指定されたゲイン(0~1.0,=0はノイズなし)
でデータ全域に付加する
また以下のグローバル変数にも従う
data_n:データ長[点数]
dt:サンプリング間隔[s]
time:時間データ配列[s]
戻り値:ndarray 観測データ[データ組数,data_n],ndarray 理想データ[データ組数,data_n
"""
#戻りndarrayの作成
X=np.empty([0,data_n]) #空の観測データ配列生成
y=np.empty([0,data_n]) #空の理想データ配列生成
for white_noize_gain in white_noize_gains:
for conflict_gain in conf_gains:
for signal_fq in signal_fqs:
for signal_len in sig_lens:
make_len_data=False
for signal_st in sig_st_poss:
#信号無しデータが多数作成され、それに引きずられ過ぎないように信号無しデータの生成数を制限する
if (signal_len==0)and (make_len_data==True):
continue
#信号を出力制御SW配列 =0の時出力しない =1出力する
signal_sw=np.zeros(data_n)
signal_end=signal_st+signal_len
if (signal_end>data_n):
#有意箇所発生位置と長さの関係がデータ長をはみ出さないように上限設定
signal_end=data_n
signal_sw[signal_st:signal_end]=1
# 信号(signal_st分開始点がずれた周波数signal_fq正弦波)の生成(signal_sw[]が1のところだけ)
sig = np.sin(2*np.pi*signal_fq*(time-time[signal_st]))*signal_sw
y=np.vstack([y,sig.reshape(1,data_n)])
#信号を理想データ配列に追加
# 信号と同周波数で重畳するノイズの付加
observe_sig = sig+ np.sin(2*np.pi*signal_fq*time)*conflict_gain
# 信号重畳するホワイトノイズの付加
#(np.random.rand()の戻り値0~1.0を-1.0から1.0に変換してからwhite_noize_gainを乗ずる)
observe_sig = observe_sig+(np.random.rand(data_n)-0.5)*2.0*white_noize_gain
X=np.vstack([X,observe_sig.reshape(1,data_n)])
#ノイズが付加された信号を観測データ配列に追加
make_len_data=True
return (X,y)
signal_fqs=[1.0,2.0,3.0,5.0,7.0,10.0] #信号周波数[Hz]
sig_st_poss=np.arange(0,1000,150) #信号有意箇所の発生位置[サンプリング数]
sig_lens=[100,0,200,500,data_n] #信号有意箇所の長さ[サンプリング数]
# 長さを0として信号なしを作る
conf_gains=[0.0,0.05,0.1] #信号と同周波数の重畳するノイズの信号に対するGain
white_noize_gains=[0.0,0.05,0.1] #信号に重畳するホワイトノイズの信号に対するGain
X,y=make_data(signal_fqs,sig_st_poss,sig_lens,conf_gains,white_noize_gains)
オートエンコーダ手法を使用
どのような深層学習手法が信号処理フィルタ―に使用できるか探し始めた中、
アイデミーさんからオートエンコーダという手法がノイズ除去に使われている事例が
有ると教えていただいたので、TensorFlowチュートリアルの2番目の例を参考に
実装することにしました。
実装にあたり例に対し以下を変更しました。
・入力データの次元が2次元から1次元へとなるに伴い、レイヤー関数を
Conv2D()→Conv1D(),Conv2DTranspose()→Conv1DTranspose() へ変更。
・圧縮(/伸張)をレイヤーごとに1/2(/2倍)とすることは継承し、
入力データ点数に対しておおよそ1/10まで圧縮した信号周波数を
判別する学習器とするために圧縮(/伸張)レイヤー数をそれぞれ3層に設定。
・最終出力層の活性化関数を負値出力できるようにするために、
sigmoidからlinear へ変更。
・(細かい所で)信号を確実に拾うためstridesを1(デフォールト)に変更。
参考に下記にレイヤー生成を行うオートエンコーダクラスのコードを記載します。
オートエンコーダクラス
class cnn_autoencoder(Model):
"""
オートエンコーダクラス
https://www.tensorflow.org/tutorials/generative/autoencoder
を参照して作成
"""
def __init__(self):
super(cnn_autoencoder, self).__init__()
self.encoder = tf.keras.Sequential(
[
layers.Conv1D(512, 3, input_shape=(data_n, 1), padding='same'),
layers.ReLU(),
layers.Conv1D(256, 3, padding='same'),
layers.ReLU(),
layers.Conv1D(128, 3, padding='same'),
layers.ReLU()
]
)
self.decoder = tf.keras.Sequential(
[
layers.Conv1DTranspose(128, 3, padding='same'),
layers.ReLU(),
layers.Conv1DTranspose(256, 3, padding='same'),
layers.ReLU(),
layers.Conv1DTranspose(512, 3, padding='same'),
layers.ReLU(),
layers.Conv1D(1, 3, activation='linear', padding='same')
]
)
def call(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
学習過程
今回は訓練データと学習データを明確に分離せず、生成した学習データ
全体を5分割の交差検証法にて学習し、生成データ全体への適合を図り、
その他以下の設定で行いました。
・適正学習回数が不明であったため、コールバック関数として
EarlyStopping()をAutoモードで設定。
・正解データに対する外れ値へのペナルティを大きくするために
損失関数としてMSEを選択。
学習時の損失値経過を下図に記載します。
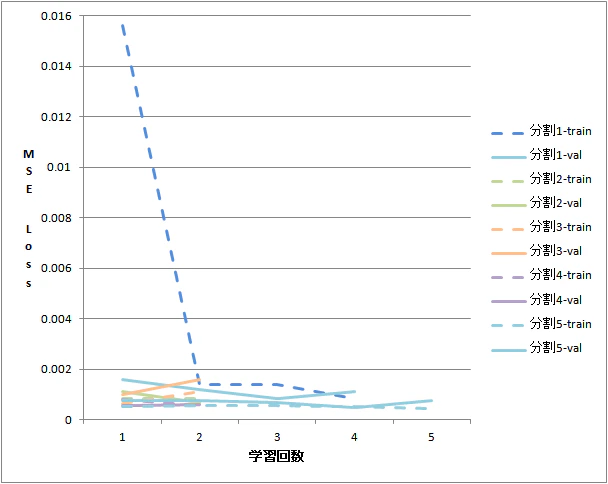
分割1の初回学習後は、訓練時/検証時のLossは最大で0.0016と低く抑えられ、
各分割の学習数は、10回に設定したepochsに対し検証Lossが乖離しない2~5回に
で終了しているため。EarlyStopping()のAutoモードも有効に機能しています。
1~5分割全体のLoss平均は
訓練時:0.01398
検証時:0.01399
と過学習なしに適切な学習レベルに達していると判断しました。
なお、学習は6~8時間と長時間かかるため、学習したモデルの保存と
読み込みが可能とし、追加学習/データへの適用を確認しやすいようにしました。
参考にモデルの生成/保尊/読み込みと学習を行う部分のコードを記載します。
モデルの生成/保尊/読み込みと学習
def get_fitted_model():
"""
学習済 信号スムーサモデルを取得する
カレントディレクトリに"SignalSmoother"というディレクトリを確認し、
・"SignalSmoother"が存在するならばそれコンパイル済、学習済モデルとして読み込み
・ディレクトリが存在しなければ"OrgSignalSmoother"というディレクトリを確認し、
+"OrgSignalSmoother"が存在するならばそれコンパイル済、学習済モデルとして読み込み
ここで設定された学習データにて追加学習をおこない"SignalSmoother"といディレクトリに保存する
+"OrgSignalSmoother"が存在しなければモデルを生成・コンパイルし、学習を行い、
"SignalSmoother"といディレクトリに保存する
戻り値:学習済 信号スムーサモデル
"""
def fit_by_5Fold(model):
"""
5分割の交差検証で学習を行う
model:学習を行うモデル
"""
kf = KFold(n_splits=5, random_state=0, shuffle=True)
train_mae_list=[] #学習過程記録用
val_mae_list=[] #学習過程記録用
#学習停止用コールバック val_lossを監視して、自動推測で停止、1回だけ追加試行する
early_stopping =EarlyStopping(monitor='val_loss',patience=1,mode='auto')
# K-分割交差検証での学習ループ
for i ,(trn_index, val_index) in enumerate(kf.split(X_cnn, y_cnn)):
X_train ,X_val = X_cnn[trn_index], X_cnn[val_index]
y_train ,y_val = y_cnn[trn_index], y_cnn[val_index]
model.fit(
x=X_train,
y=y_train,
epochs=10,
validation_data=(X_val, y_val),
verbose=1,
callbacks=[early_stopping]
)
y_pred = model.predict(X_train)
train_mae =losses.mean_absolute_error(y_train,y_pred)
train_mae_list.append(np.mean(train_mae))
y_pred_val = model.predict(X_val)
val_mae =losses.mean_absolute_error(y_val,y_pred_val)
val_mae_list.append(np.mean(val_mae))
print('-'*10 + 'Result' +'-'*10)
print('Train_mae : {0} , Ave : {1}'.format(train_mae_list,np.mean(train_mae_list)))
print('Valid_mae : {0} , Ave : {1}'.format(val_mae_list,np.mean(val_mae_list)))
#ディレクトリ確認
model_dir_name="SignalSmoother"
if os.path.exists(model_dir_name) :
#コンパイル済、学習済モデルとして読み込み
model=load_model(model_dir_name)
else:
#Orgディレクトリ確認
org_model_dir_name="Org"+model_dir_name
if not os.path.exists(org_model_dir_name) :
#Orgディレクトリなければモデルの生成・コンパイル
model = cnn_autoencoder()
model.compile(optimizer='adam', loss='mse')
else:
#Orgディレクトリ有ればコンパイル済、学習済モデルとして読み込み
model=load_model(org_model_dir_name)
print(org_model_dir_name+" Load")
#モデルの学習(Orgディレクトリ有った場合は追加学習)
# K-分割交差検証(5分割)で学習
fit_by_5Fold(model)
#学習済 信号スムーサモデルを保存
model.save(model_dir_name)
return model #学習済 信号スムーサモデルを返す
5.結果
今回の深層学習フィルターの出力
先ず前述 ”学習データの生成”で記載した 学習データの例に対して
今回の深層学習フィルターを適用して得られた出力データ(以下予測データ)
を記載します。
(図中 薄緑線が観測データ、薄赤線が正解データ、薄青線が予測データ)
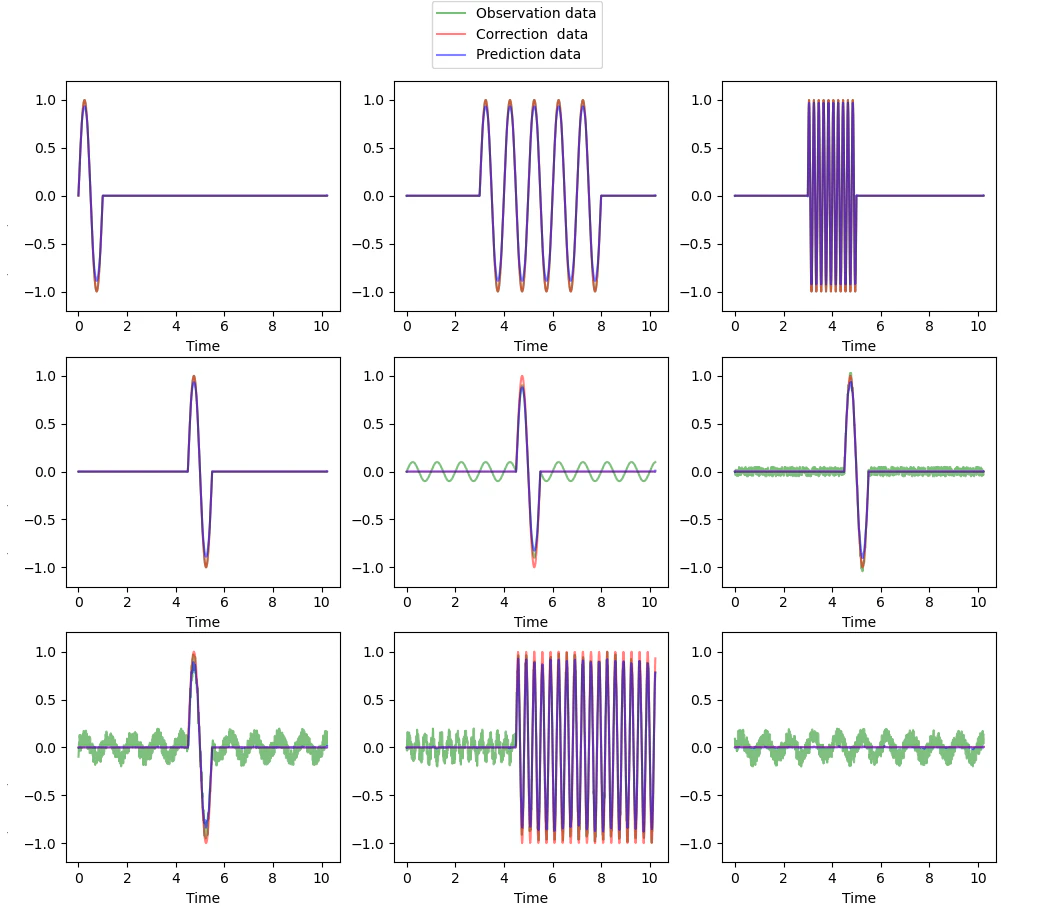
一見、薄青の予測データがと薄赤の正解データに重なり紫に見える箇所が多く
予測データが正解データにそれなりに追従し、信号が無い箇所はノイズのみが除去
されており、狙いとした信号とノイズが同じ周波数で重なりあっているデータの
ノイズを低減することが、ある程度達成しているように見えます。
以下いくつかのデータを拡大等ピックアップして記載します。
学習済データの出力
下記学習したノイズが無い観測データに対する予測データの信号の振幅は、
正解データに対し小さくなっていますが、予測データの信号開始位置と終了位置は
正解とほぼ同じで、信号が無い区間は正解データと同じく直線となっています。
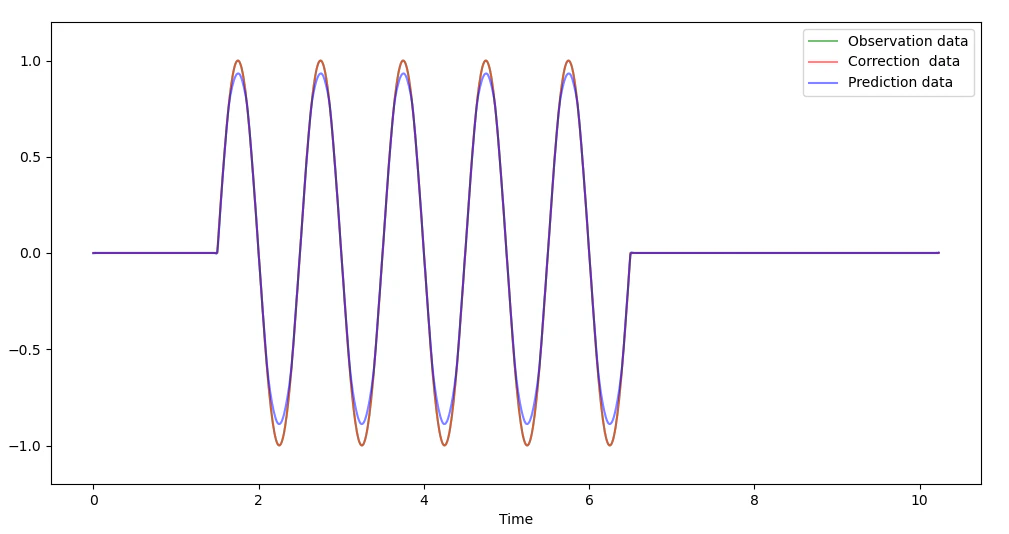
下記 信号と同周波数のノイズが重なりあっているデータは同周波数のノイズは
除去されていますが、上記と同様に信号の振幅は小さくなっています。
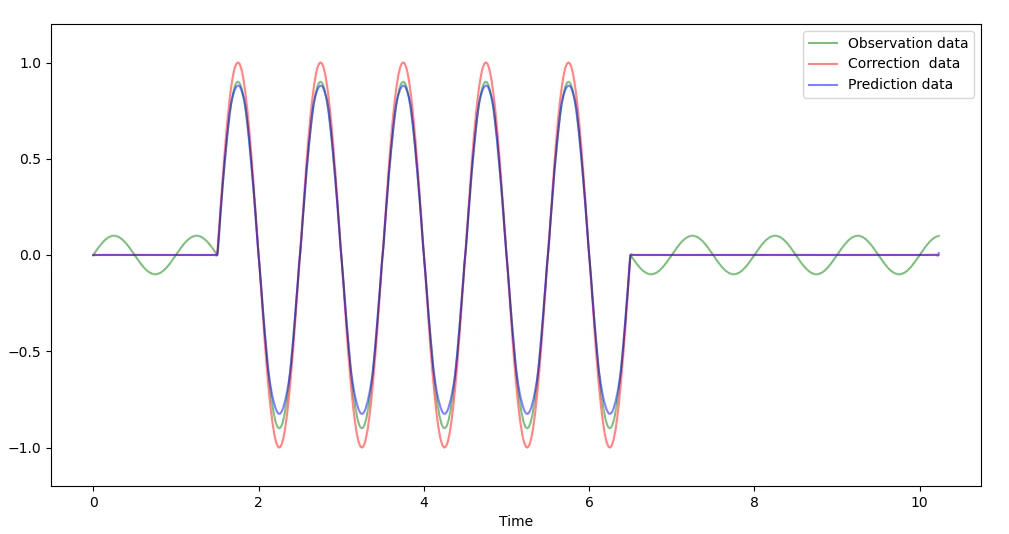
上記に更にホワイトノイズを重ねた下図データでも、
同周波数のノイズは除去されており、ホワイトノイズは信号部分と信号のない部分の
一部にはある程度残ってはいますが、かなり低減されています。
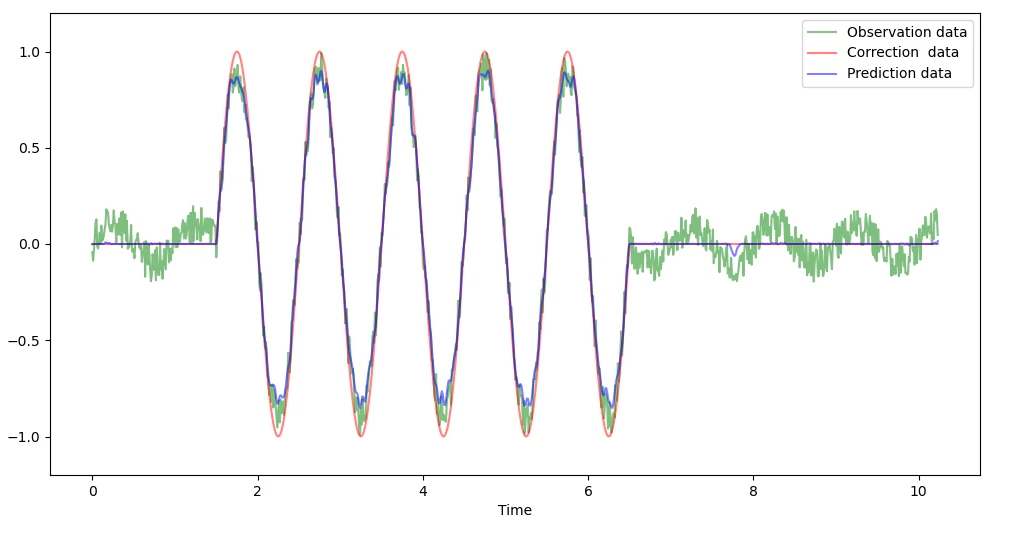
(下図はホワイトノイズ残存部分の拡大)
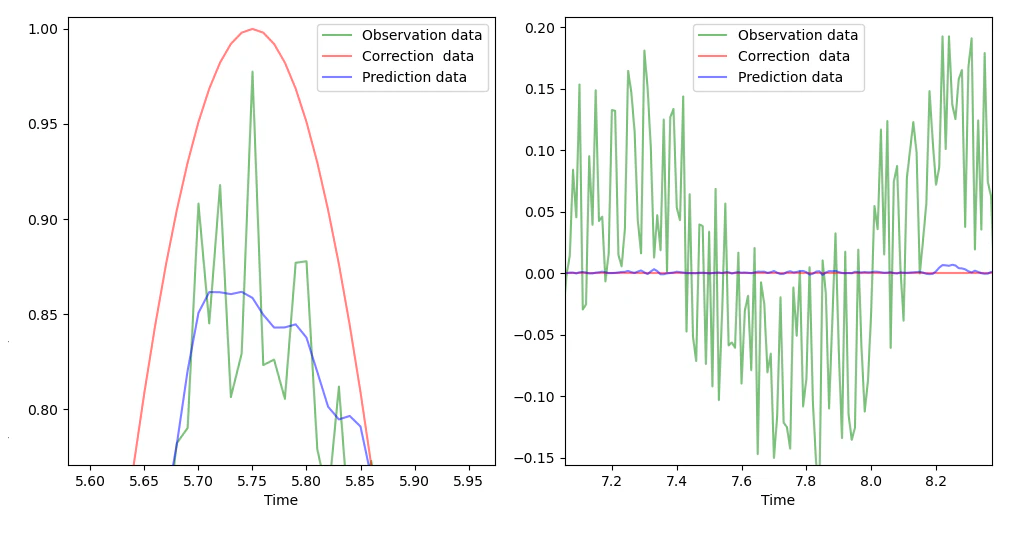
未学習データの出力
次に学習したデータ以外への今回の深層学習フィルターの適用を試しました。
下記は信号周波数として学習していない0.35Hzのデータですが、
同周波数ノイズやホワイトノイズも付加した悪条件ですが、
信号の無い部分のノイズは低減され、正解データに予測データがそれなりに
追従しています。
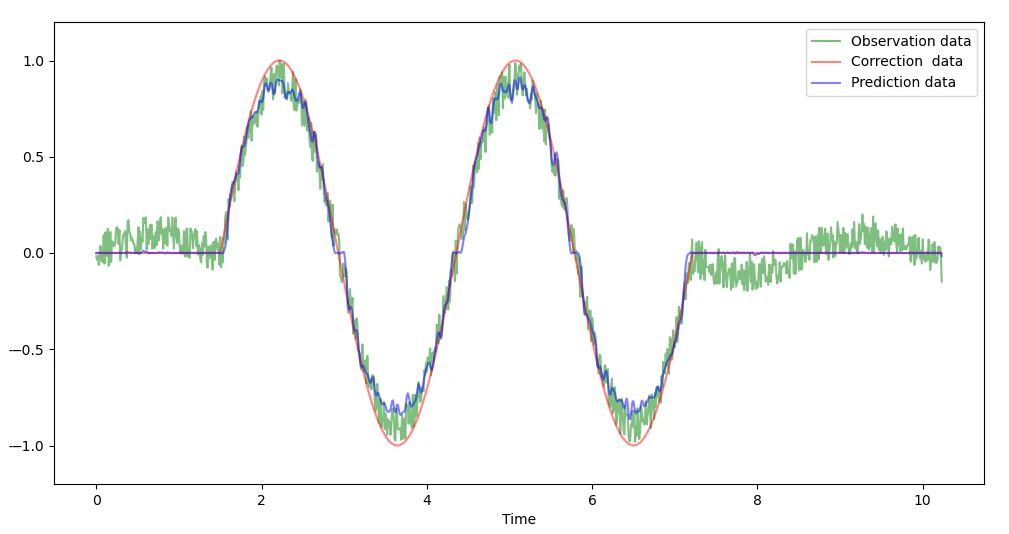
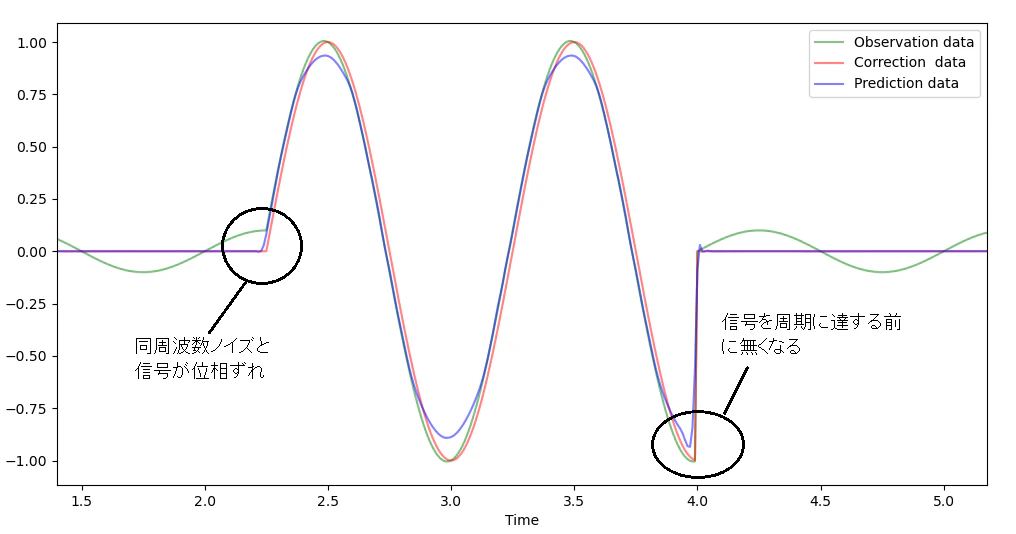
学習データは信号と同周波数のノイズは同位相が多く、信号の継続期間も
周期の区切れであることが多かっため、下図に同周波数ノイズの位相をずらし、
信号周期の途中で信号が途切れるという未学習データへの適用例を記載します。
周期の途中切れで信号の歪が発生していますが、同周波数ノイズの除去
はされています。
学習データは”信号がノイズに対し際立って大きい”ことを教え込むことを
主眼に生成したため、ノイズに対するロバスト性も確認しました。
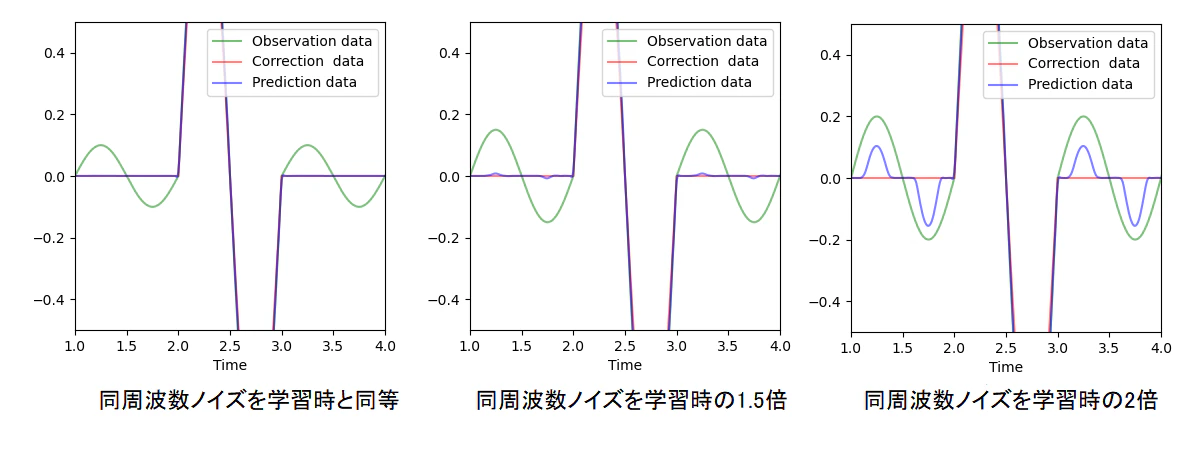
学習時以上の同周波数ノイズを与えた下図結果を記載します。
学習時の1.5倍程度のノイはそれなりに除去されていますが、
2倍程度のノイズとなると除去されていません。ノイズの大きさに対しては、
ある程度のロバスト性はあるものの、学習時とのノイズ比には留意が必要な
結果となっています。
(ホワイトノイズにおいても同様な傾向があります)
今回の深層学習フィルターの欠点
以上様に観測データ中の本来の信号の振幅等の特徴から、
本来の信号とノイズを判別することで、信号とノイズが同じ周波数で重なりあって
いるデータのノイズを低減するという今回の深層学習フィルターの狙いをある程度の
ロバスト性を持って実現できました。が、
しかし、同時に以下に記すフィルターとしての欠点も存在しています。
周波数成分が大きく変化する
下図は周波数1Hzの信号にノイズを全く加えない観測データと
予測データのそれぞれに前述のFFTによる周波数解析を行った結果です。
下図下段左のように予測データは正解データにそれなりに追従してますが、
上段右の観測データの周波数解析グラフに信号の周波数主成分の1Hzのピーク
が大きく存在しているのに対し、下段右の予測データの周波数解析グラフでは
1Hzのピークが無くなり、その代わりに20Hz以上の周波数に
分散された小さなピークが現れています。

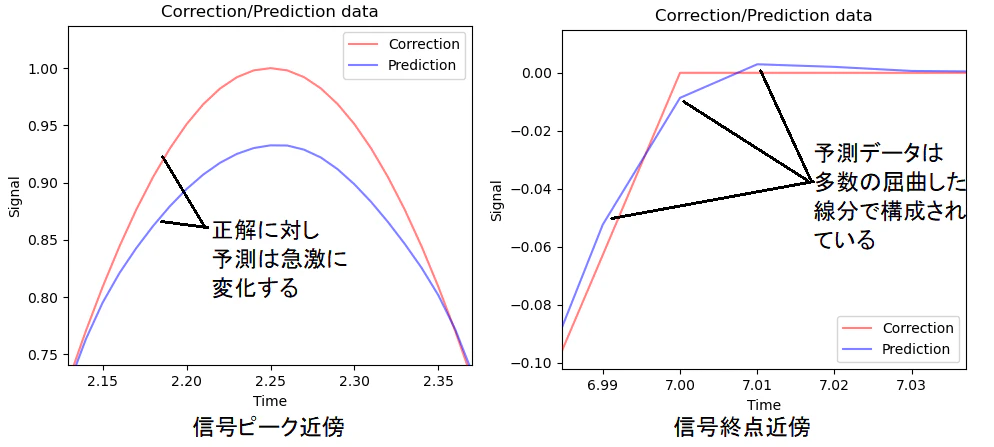
一見正解に追従している予測データですが、下図信号のピークや終点位置
を拡大すると、正解データに比べ急激/細かい変化となっている部分が多く、
これらが信号周波数の1Hzの主成分を20Hz以上の高周波側へシフトする
要因となっていると考えます。
このような、周波数成分の大きな変化は周波数解析を重視する信号処理では
受け入れがたい変化である事が多いかと思います。
振幅の変化率が一定でない
観測データ及び正解データの振幅に対し、予測データの振幅は同じでは無く
0.8~1.2倍の範囲となります。その変化率が一定にならないため、一定の係数
での補正などが難しく、そのため振幅を重視する信号処理では適用が
難しいことがあります。
6.終わりに
これまでの信号処理フィルターが不得意な事に深層学習が適用できないかという
テーマに関して取り組みましたが、結果 前述欠点に記載したように信号処理として
実用化が難しいものでした。
しかし、深層学習の可能性、特に畳み込みニューラルネットワークの柔軟性の
高さ(※)は今後幅広い適用が期待できることを実感しました。
今後は、信号処理等測定計測分野を中心に幅広いテーマでの機械学習の適用の
と自分の技術の深化にチャレンジしていきたいと思います。
※)記載しませんでしたが、当初レイヤー構成を畳み込みニューラルネットワーク
ではなく全結合ニューラルネットワークで試みましたが、
予測データは正解データに全く追従しませんでした。