Amazonの注文レポートから売れる曜日と売れる時間帯を割り出しました。
パラメータを変えれば実店舗にも他のネットショップでも対応できます。
必要な環境
Pythonを使えればOKです。
必要なライブラリ
- matplotlib
- pandas
入っていない場合は
terminal
pip install matplotlib
pip install pandas
pandas バージョン注意:
pandasのバージョンによってはread_tableで読み込む際、9時間ずれてしまいますので、できるだけ新しいもので。
Pythonで見つけるショップの定休日
まずはデータを集めます。
下記のようなデータがあればamazon以外のネットショップにも対応できます。
| purchase-date | quantity |
|---|---|
| 2019-04-01T12:34:56+09:00 | 1 |
| 2019-04-02T12:44:56+09:00 | 2 |
| 2019-04-03T12:54:56+09:00 | 1 |
| 2019-04-04T12:04:56+09:00 | 4 |
| 2019-04-05T12:14:56+09:00 | 6 |
Amazonやヤフオク!など、ECモールの場合、管理画面からダウンロードできます。
実店舗でもデータ化された売上表がある場合はパラメーターを変えるだけで対応できます。
作成できるグラフ
下記グラフはamazonからダウンロードできる__全注文レポート__をから作成したグラフです。
曜日別のグラフ
- 横軸は曜日で、0が月曜日、6が日曜日となっています。
- 縦軸は数量です。

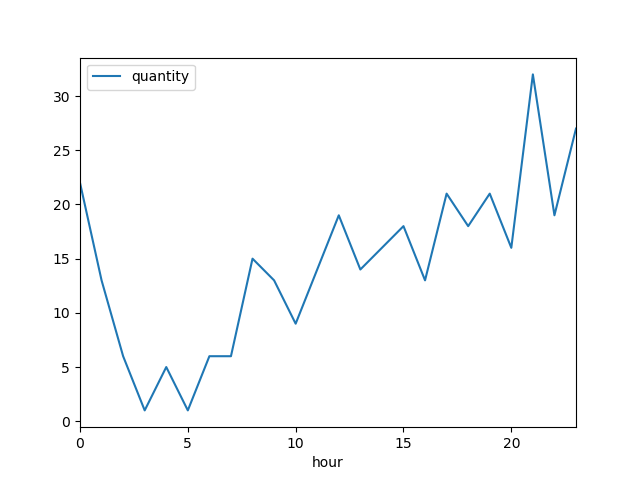
時間別のグラフ
- 横軸は時間
- 縦軸は数量
グラフ化してわかること(取り扱いジャンルによって変わると思うので注意)
曜日別
うちの場合、3の木曜日の売上が最小で、6の日曜日が最大となっている。
その差は2倍以上。アルバイトを雇っているような店舗の場合、__シフトを考える__際にも役に立つかと思います。
だいたいどの期間をとっても同じような形となるので、うちの場合は__木曜日が定休日__にしやすいです。飲みに行くなら水曜日の夜。
時間別グラフでわかること
昼型人間が自由に動ける時間帯に注文が多い。
キャンペーンやセールの時間帯、お知らせの時間帯は工夫した方が良い。
pythonコード
import matplotlib.pyplot as plt
import pandas as pd
sales_data = 'ここに読み込みたいファイルのパス'
df = pd.read_csv(sales_data, sep='\t', index_col=['purchase-date'],
usecols=['purchase-date', 'quantity'],
parse_dates=True, encoding="shift-jis")
df = df.set_index([df.index.hour, df.index.weekday, df.index])
df.index.names = ['hour', 'weekday', 'day']
# weekday
df_weekday = df.sum(level='weekday')
df_weekday = df_weekday.sort_index(axis=0)
plt.figure()
df_weekday.plot()
plt.savefig("image_weekday.png")
# hour
df_hour = df.sum(level='hour')
df_hour = df_hour.sort_index(axis=0)
plt.figure()
df_hour.plot()
plt.savefig("image_hour.png")
これを実行するとグラフの.pngが出来上がります。
- weekday.pngと言う名の曜日別数量グラフ
- hour.pngと言う名の時間別数量グラフ
Amazon__の場合、'ここに読み込みたいファイルのパス'を変更すれば__コピペするだけで実行できます。
実店舗や他のECモールに対応させる場合
df = pd.read_csv(sales_data, sep='\t', index_col=['purchase-date'],
usecols=['purchase-date', 'quantity'],
parse_dates=True, encoding="shift-jis")
ここら辺のsep='\t'やカラム名をいじってやると対応できます。
ヤフオクの月間落札明細に対応させる場合
df = pd.read_csv(file_auction, sep=',', index_col=['終了日時'],
usecols=['終了日時', '落札個数'],
parse_dates=True, encoding="お使いの文字コード")
文字コードだけ指定してください。
最後に
最後まで見ていただきありがとうございます。
カラム名などを変更すれば、いろんなショップに対応できるので、自分のショップでチャレンジしてみてください。