Josh Kaufman氏によると、正しく学習を行えば20時間で新たなスキルを身につけることができるそうです。
今回は氏の学習方法を参考に、「全文検索」について20時間学習を行ってみたので、その結果をまとめたいと思います。なおこの記事は学習ノートとしての側面の方が強いので注意してください。
はじめに
学習前の知識や技術
Elasticsearchという検索エンジンで全文検索が実装できるらしい。Dockerイメージが提供されていたので、以前から気になっていた。
他にも全文検索が実装できるオープンソースのソフトウェアがあるらしいが名前までは知らない。(後にApache Solrだと判明しました)
これらのソフトウェアはMySQLなどと比較すると読み込みに優れているらしい。反面、書き込みは劣るとのことなのでMySQLなど書き込み用データストアと同期させる形で利用するらしい。
MySQLなどのデータベースでも似たような全文検索を実装できるらしいが、詳しいことは何もわからない。
そもそも全文検索の仕組みを正しく理解していない。
学習目標
全文検索を学習するにあたり、スキルを知識と技術に分け、以下の学習目標を立てました。
- 全文検索について理解する
- Elasticsearch, Apache Solrのドキュメントを読んで概要を理解する
- ElasticsearchとApache Solrの比較ができる
- データベース検索との比較ができる
- 簡単なサンプルプロジェクトで動作させることができる
全文検索とは
全文検索(Full-Text Search)とは、複数のファイルや膨大な文章から特定のキーワードに関連するものを効率的に検索する技術です。
全文検索技術は主にgrep型と索引(インデックス)型の2つに分類でき、それぞれ異なる特徴を持っています。
今回利用するElasticsearchやApache Solrは索引型の検索エンジンで、grep型と比較して大量のデータに対しても高速な検索が可能となっています。逆に、インデックスの管理が必要になるため、データの追加や更新は注意して行う必要があります。
インデックスを作成する代表的な手法として、形態素解析とn-gramがあります。
形態素解析は文章を意味のある最小単位に分割する技術です。日本語における全文検索でもっとも使われているとのことです。
n-gramは逆に文字単位で分割を行います。オートコンプリート機能を実装できますが、文字単位で分割するという性質上、検索ノイズの発生やインデックスサイズの肥大化が発生してしまうという欠点があります。
どちらの手法にも長所と短所がありますが、形態素解析とn-gramを併用して使うハイブリッド法と呼ばれる手法もあります。しかしその手法にも、併用して使うため動作が重くなってしまうという欠点があります。
要件に応じて適切に使い分ける必要がありそうです。
Elasticsearchとは
Elasticsearch(エラスティックサーチ)は、Apache Luceneをベースに開発された分析・検索エンジンです。
かつてはApache 2.0ライセンスでしたが、現在はSSPLとElastic Licenseのデュアルライセンスに移行しました。どちらのライセンスでも無料でElasticsearchの機能を使用することができます。
有償のサブスクリプションも提供されており、購入することで無料機能に加え、セキュリティ面のより強力なサポートや機械学習機能などを使用することができるようになります。
Elasticsearchは幅広いプログラミング言語をサポートしており、オフィシャルクライアントが提供されています。
例えばJavaScriptでは@elastic/elasticsearchというパッケージが提供されており、npmやyarnを通じてインストールすることができます。
以下のドキュメントから各プログラミング言語のクライアントドキュメントにアクセスすることができます。
Apache Solrとは
Apache Solr(ソーラー)はElasticsearchと同様に、
Apache Luceneをベースに開発されたエンタープライズ検索プラットフォームです。Apache License上で構築されています。
SolrはRESTライクなAPIを提供しています。また、オートコンプリートやスペルチェックなど高度な機能を備えています。
また、豊富なプラグインが同梱されており、PDFやWordなどリッチコンテンツを対象とした検索を行うこともできます。
Solrのオフィシャルクライアントを探してみたのですが見つけることはできませんでした。
JavaScriptではsolr-clientというパッケージを見つけましたが、最新版のバージョン9にはまだ完全には対応していないようで、想定外の挙動をする可能性があります。
サンプルコード
今回はDockerでElasticsearch(とKibana), Apache Solr, MySQLの環境を構築し、ts-nodeでサンプルコードを実行しました。
今回使用したdocker-compose.ymlとElasticsearch用のDockerfileです。
version: '3'
services:
# initializer
initializer:
image: alpine
container_name: solr-initializer
restart: "no"
entrypoint: |
/bin/sh -c "chown 8983:8983 /solr"
volumes:
- ./services/solr:/solr
# solr
solr:
depends_on:
- initializer
image: solr:9.2.0
ports:
- 8983:8983
volumes:
- ./services/solr:/var/solr
command:
- solr-precreate
- posts
# elastic
elastic:
build: ./services/elastic
ports:
- 9200:9200
environment:
- discovery.type=single-node
- xpack.security.enabled=false
- ES_JAVA_OPTS=-Xms400m -Xmx400m
ulimits:
memlock:
soft: -1
hard: -1
# kibana
kibana:
image: docker.elastic.co/kibana/kibana:8.7.0
ports:
- 5601:5601
environment:
- ELASTICSEARCH_HOSTS=http://elastic:9200
depends_on:
- elastic
# mysql
mysql:
image: mysql:8.0-debian
ports:
- 3306:3306
environment:
MYSQL_ROOT_PASSWORD: root
MYSQL_DATABASE: my_database
MYSQL_USER: user
MYSQL_PASSWORD: password
TZ: "Asia/Tokyo"
volumes:
- ./services/mysql/data:/var/lib/mysql
- ./services/mysql/sql
FROM docker.elastic.co/elasticsearch/elasticsearch:8.7.0
RUN elasticsearch-plugin install analysis-kuromoji
そして今回、全文検索用の文字列として以下を用意しました。正直、量がかなり少ないですね...
[
"今日は何もないすばらしい一日でした",
"隣の客はよく柿食う客だ",
"ふとんが吹っ飛んだ",
"HTML/CSSは楽しい",
"これはテスト投稿です。キャプションはありません",
"今日はテストがあります"
]
Elasticsearchで全文検索
Elasticsearchへのアクセスは上述の@elastic/elasticsearchを使用しました。
import { Client } from "@elastic/elasticsearch";
(async () => {
const client = new Client({
node: process.env.ELASTICSEARCH_URL || 'http://localhost:9200',
});
const index = "posts";
// インデックスが存在するか確認
const isExists = await client.indices.exists({
index
});
if (!isExists) {
// インデックスの作成
await client.indices.create({
index,
mappings: {
properties: {
id: { type: 'keyword' },
caption: { type: 'text' },
createdAt: { type: 'date' }
}
}
});
}
// 検索の実行
const result = client.search({
index,
body: {
min_score: 0.5,
query: {
match: {
caption: "今日は"
}
},
},
});
console.log(result); // [今日はテストがあります, 今日は何もないすばらしい一日でした]
})();
以下の部分ではインデックスの存在確認と、存在しない場合はインデックスの新規作成を行っています。なおElasticsearchはスキーマレスに対応しているため、作成していなくても検索することは可能です。
// インデックスが存在するか確認
const isExists = await client.indices.exists({
index
});
if (!isExists) {
// インデックスの作成
await client.indices.create({
index,
mappings: {
properties: {
id: { type: 'keyword' },
caption: { type: 'text' },
createdAt: { type: 'date' }
}
}
});
}
そして以下の部分でドキュメントの検索を行っています。
body.min_scoreに0.5を指定していますが、これは取得する最小一致度を設定するオプションです。これを指定しないと、文章中に「○○は」が含まれている文章も一緒に取得してしまいます。
// 検索の実行
const result = client.search({
index,
body: {
min_score: 0.5,
query: {
match: {
caption: "今日は"
}
},
},
});
最後に、Kibana上で同様の検索を行ってみました。
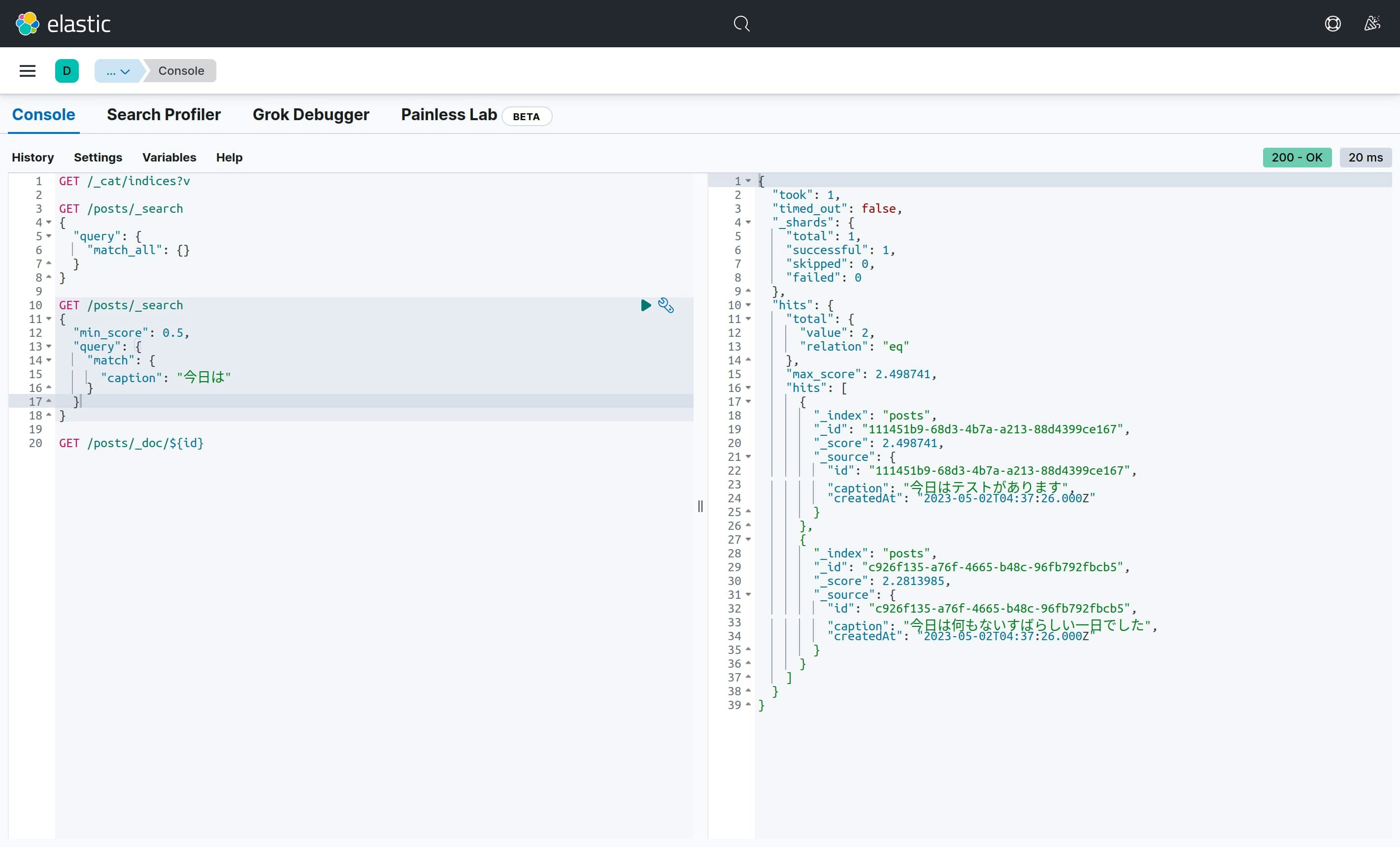
無事、期待通りの検索結果を取得することができました。
Apache Solrで全文検索
Apache Solrの公式クライアントパッケージを見つけることができなかったため、fetch()を使用しました。
docker-compose.ymlファイルに記述したpre-createコマンドでpostsというコアが作成されているので、このコアに対して検索を行います。
(async () => {
const url = process.env.SOLR_URL || "http://localhost:8983";
const response = await fetch(url + "/solr/posts/select?q=caption:今日は");
const result = await response.json();
console.log(result); // [今日はテストがあります, 今日は何もないすばらしい一日でした, これはテスト投稿です。キャプションはありません, HTML/CSSは楽しい, 隣の客はよく柿食う客だ]
})();
ドキュメントの検索は、url/solr/コア名/selectで実行することができます。
Elasticsearchのmin_scoreにあたるオプションが分からなかったため、「○○は」という文章も一緒に取得してしまっています。
最後に、Solrアドミン上で同様の検索を行ってみました。
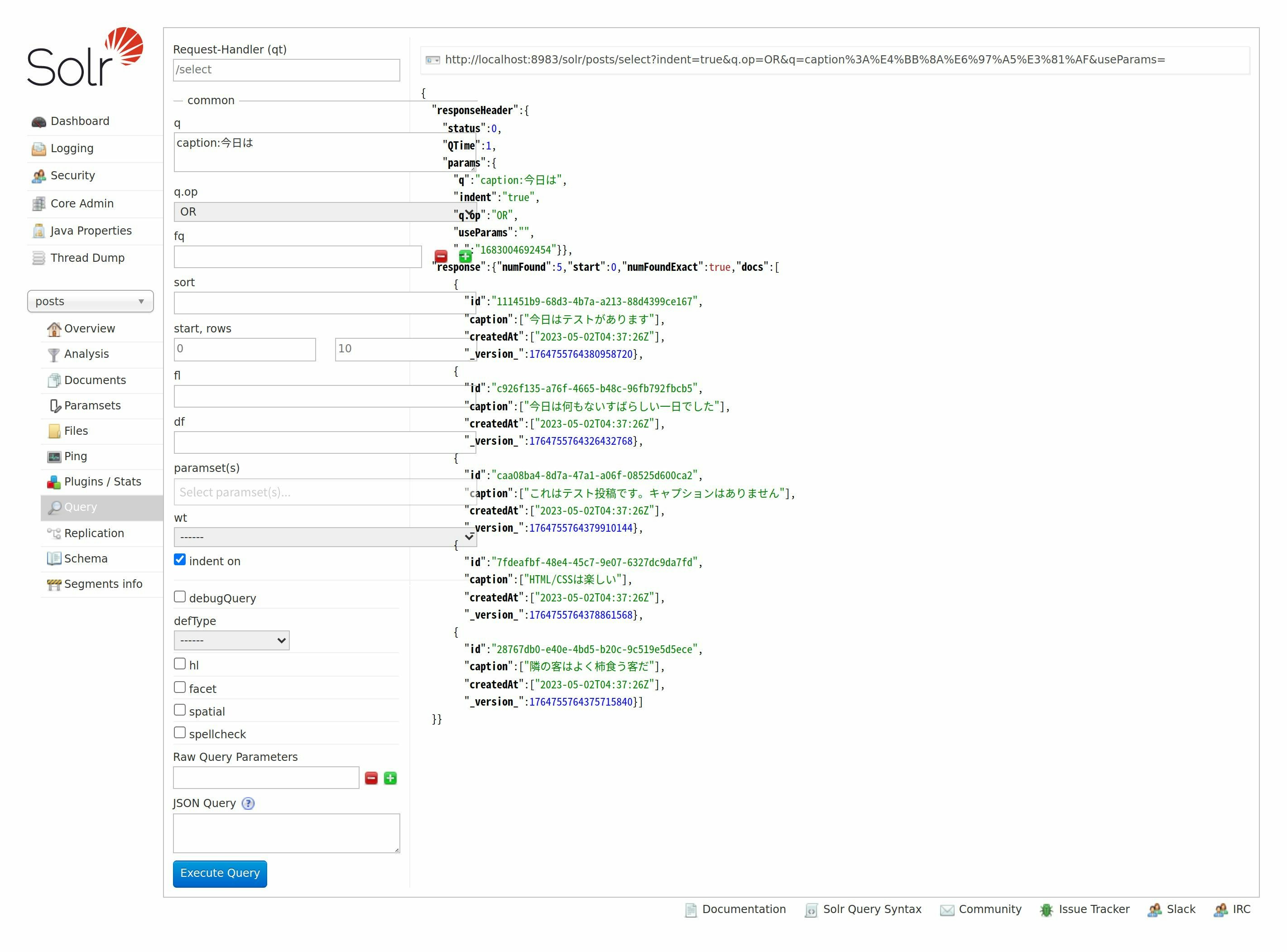
無事、期待通りの検索結果を取得することができました。
MySQLで全文検索
以下が今回サンプル用に使用したpostsテーブルのテーブル定義です。
CREATE TABLE posts (
id CHAR(36) NOT NULL,
caption TEXT NOT NULL,
created_at TIMESTAMP NOT NULL,
PRIMARY KEY (id),
FULLTEXT KEY `FT_CAPTION` (`caption`) WITH PARSER ngram
) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
captionカラムに対して全文検索インデックスを付けています。またパーサーには日本語に対応しているngramを指定しています。このngramは最新のMySQLの場合、余計なインストールなしで利用することができます。
上記のテーブルに対して全文検索を行います。
MySQLにおいて全文検索はMATCH () ... AGAINST構文で実行することができます。
今回実行したSQL文は以下の通りです。
SELECT * FROM posts WHERE MATCH (caption) AGAINST ('今日は' IN NATURAL LANGUAGE MODE);
全文インデックスが付いているcaptionカラムをMATCH ()部分に指定しています。AGAINSTには検索したい文字列を指定しています。
実際に動かしてみて
ElasticsearchとKibanaはかなりメモリ使用量が多いのか、docker-compose.ymlにメモリに関する設定を追加しなければエラーが発生して動作しませんでした。
Apache Solrはそのような問題は発生しませんでした。
とはいえドキュメントが豊富な点、公式のクライアントパッケージが提供されている点などを考慮すると、個人的にはElasticsearchの方が好みかもしれません。
メモリ上の不安がない時はElasticsearch、ある場合はApache Solrのように使い分けたいと思います。
データベースでの全文検索との比較に関しては、性能比較まで行えなかったため、あまり違いが分かりませんでした。データ数を増やしてみるとわかりやすくなるのかもしれません。
まとめ
今回は全文検索についての学習を20時間行ってみて、その結果をまとめてみました。
全文検索についての概要やElasticsearchなどの知識、実際に動かした経験を積むことができ、良い経験になりました。
反省点としてはElasticsearchとApache Solrの2つ同時に手を出してしまったことです。20時間は思いのほか短かったため、どちらかに絞り、片方は比較程度で済ますべきでした。
次回の20時間学習では、Docker・kubernetes、CI/CDツールなど興味のあるスキルか、ネットワークやデータベースなど基礎を固めるスキルを対象にしようと思います。
今回の反省点を活かして上手く学習しようと思います。