ABEJA Advent Calendar 2019の15日目です
概要
こんにちは,ABEJAでデータサイエンティストをしているnakamichiです.といっても実はまだ転職して来て間もないヒヨッコなので,特に仕事とは関係なく気になっているデータサイエンスの話題を取り上げたいと思います.
先日のAWS re:Inventでは,SageMakerをはじめ,SageMaker関係の新機能がいくつか発表されました.本記事ではその中のSageMaker Debuggerを取り上げます.
SageMaker Debuggerを使うと,深層学習モデルのトレーニング中に重みのテンソルを保存したり,勾配消失のような望ましくないイベントが生じていないかを監視したりできるので,デバッグがはかどる......というのが概略的な説明なのですが,このDebugger,実は深層学習フレームワークだけでなくXGBoostに対しても使えるようです.XGBoostモデルのデバッグでは一体何ができるのか気になります.というわけで,公式に用意されているサンプルのノートブック(Debugging XGBoost Training Jobs with Amazon SageMaker Debugger Using Rules)を実際に動かして機能を確認してみます.
※以下,コードはすべてSageMakerのノートブックインスタンスで実行しています.
XGBoostでSageMaker Debuggerを使う
深層学習フレームワークにおけるSageMaker Debuggerの主な機能は,トレーニング中にテンソルを保存してそれを解析することですが,XGBoostは深層学習ではありません.それではXGBoostに対してDebuggerが何をしてくれるのかというと,テンソルではなく各種のモデル評価指標や変数重要度を追跡することができます.
まずは諸々の準備のためのおまじないを実行します.
# SageMaker Debuggerのインストール
!python -m pip install smdebug
import boto3
import sagemaker
from sagemaker.amazon.amazon_estimator import get_image_uri
# 実行中のnotebookのリージョンを取得
region = boto3.Session().region_name
# XGBoostでDebuggerが使えるバージョンのコンテナイメージを取得
container = get_image_uri(region, "xgboost", repo_version="0.90-2")
学習に用いるデータをS3にアップロードします.データはUCI Repositoryのabaloneデータセットで,アワビ(abalone)の年齢を色々な物理的測定値から予測するというタスクです.
from data_utils import load_abalone, upload_to_s3
train_file, validation_file = load_abalone()
bucket = sagemaker.Session().default_bucket()
prefix = "DEMO-smdebug-xgboost-abalone"
upload_to_s3(train_file, bucket, f"{prefix}/train/abalone.train.libsvm")
upload_to_s3(validation_file, bucket, f"{prefix}/validation/abalone.validation.libsvm")
さて,ここからがモデルとデバッガの設定になります.トレーニング用のコンテナやハイパーパラメータをを指定してEstimatorを定義するのは通常のSageMakerの使い方と同様ですが,SageMaker Debuggerを用いたデバッグのための設定がEstimatorの定義に加わります.Debuggerには,監視すべき評価指標等を指定するフックと,トレーニング中に特定の条件に合致したイベントを検出するためのルール(Rule)と呼ばれるオブジェクトを設定します.
from sagemaker import get_execution_role
from sagemaker.estimator import Estimator
from sagemaker.debugger import rule_configs, Rule, DebuggerHookConfig, CollectionConfig
base_job_name = "demo-smdebug-xgboost-regression"
role = get_execution_role()
bucket_path = 's3://{}'.format(bucket)
# フックの設定
save_interval = 5 # 評価指標等の保存間隔
debugger_hook_config = DebuggerHookConfig(
# 評価指標等の保存先
s3_output_path=bucket_path,
# 収集する対象を指定.ここでは評価指標,変数重要度,SHAP値を指定.
collection_configs=[
CollectionConfig(name="metrics",
parameters={"save_interval": str(save_interval)}),
CollectionConfig(name="feature_importance",
parameters={"save_interval": str(save_interval)}),
CollectionConfig(name="average_shap",
parameters={"save_interval": str(save_interval)}),
],
)
# ルールの設定
rule = Rule.sagemaker(
# ロスが減少しなくなったことを検出する設定
rule_configs.loss_not_decreasing(),
rule_parameters={
"collection_names": "metrics",
"num_steps": str(save_interval * 2)
},
)
# モデルの設定
## ハイパーパラメータ
hyperparameters={
"max_depth": "5",
"eta": "0.2",
"gamma": "4",
"min_child_weight": "6",
"subsample": "0.7",
"silent": "0",
"objective": "reg:squarederror",
"num_round": "51",
}
estimator = Estimator(
role=role,
base_job_name=base_job_name,
train_instance_count=1,
train_instance_type='ml.m5.xlarge',
image_name=container,
hyperparameters=hyperparameters,
train_max_run=1800,
# フックとルールの設定を渡す
debugger_hook_config=debugger_hook_config,
rules=[rule]
)
モデルとデバッガの設定が済んだので,トレーニングジョブを実行します.
from sagemaker.session import s3_input
train_s3_input = s3_input("s3://{}/{}/{}".format(bucket, prefix, "train"), content_type="libsvm")
validation_s3_input = s3_input( "s3://{}/{}/{}".format(bucket, prefix, "validation"), content_type="libsvm")
estimator.fit({"train": train_s3_input, "validation": validation_s3_input},
wait=False # ジョブをバックグラウンドで実行
)
下記のようにトレーニングやルールの実行状況をリアルタイムに監視することができます.
import time
for _ in range(360):
job_name = estimator.latest_training_job.name
client = estimator.sagemaker_session.sagemaker_client
description = client.describe_training_job(TrainingJobName=job_name)
training_job_status = description["TrainingJobStatus"]
rule_job_summary = estimator.latest_training_job.rule_job_summary()
rule_evaluation_status = rule_job_summary[0]["RuleEvaluationStatus"]
print(f"Training job status: {training_job_status}, Rule Evaluation Status: {rule_evaluation_status}")
if rule_evaluation_status in ["Stopped", "IssuesFound", "NoIssuesFound"]:
break
time.sleep(10)
Training job status: InProgress, Rule Evaluation Status: InProgress
Training job status: InProgress, Rule Evaluation Status: InProgress
Training job status: Completed, Rule Evaluation Status: InProgress
...(中略)...
Training job status: Completed, Rule Evaluation Status: IssuesFound
実行結果の要約を見るための関数も用意されています.
estimator.latest_training_job.rule_job_summary()
[{'RuleConfigurationName': 'LossNotDecreasing',
'RuleEvaluationJobArn': 'arn:aws:sagemaker:us-east-2:************:processing-job/demo-smdebug-xgboost-regre-lossnotdecreasing-********',
'RuleEvaluationStatus': 'IssuesFound',
'StatusDetails': 'RuleEvaluationConditionMet: Evaluation of the rule LossNotDecreasing at step 30 resulted in the condition being met\n',
'LastModifiedTime': datetime.datetime(2019, 12, 16, 5, 26, 22, 732000, tzinfo=tzlocal())}]
トレーニングの30ステップ目でロスが減らなくなったことがわかります.ちなみに,ルールに合致するイベントが起きなかった場合は,'RuleEvaluationStatus': 'NoIssuesFound'となります.
次は保存しておいた評価指標等の分析を行います.分析を行うためにTrialオブジェクトを作成します.
from smdebug.trials import create_trial
s3_output_path = estimator.latest_job_debugger_artifacts_path()
trial = create_trial(s3_output_path)
保存された評価指標等の一覧を見るにはtrial.tensor_names()メソッドを使います.メソッド名がtensorなのは主に深層学習フレームワークが想定されているからなので,あまり気にせずに.
trial.tensor_names()
['average_shap/f0',
...(中略)...
'average_shap/f8',
'feature_importance/cover/f1',
...(中略)...
'feature_importance/cover/f8',
'feature_importance/gain/f1',
...(中略)...
'feature_importance/gain/f8',
'feature_importance/total_cover/f1',
...(中略)...
'feature_importance/total_cover/f8',
'feature_importance/total_gain/f1',
...(中略)...
'feature_importance/total_gain/f8',
'feature_importance/weight/f1',
...(中略)...
'feature_importance/weight/f8',
'train-rmse',
'validation-rmse']
ここで表示されている名前をtrial.tensor()メソッドに渡せば,実際に保存されている評価指標等をTensorオブジェクトとして取得できます.
# トレーニングの10ステップ目におけるRMSEの値を取得
trial.tensor("train-rmse").value(10)
array([2.180568])
# 何ステップ目の値が保存されているかは`steps()`で確認可能
trial.tensor("train-rmse").steps()
[0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50]
あとは,これらの値を自由に用いて実験結果の解析とデバッグを行えばよいです.
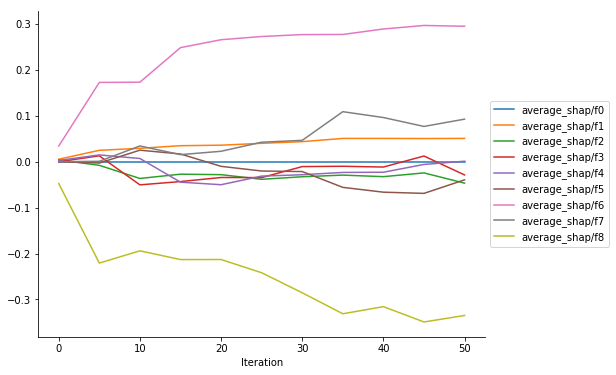
モデルの評価指標や変数重要度が取得できてもそれほど新味はないかもしれませんが,モデル解釈手法のひとつであるSHAP値を追跡できるのは,SageMaker Debuggerのひとつの特徴でしょう.最後にトレーニング中のSHAP値の変化を見てみます.
import matplotlib.pyplot as plt
import seaborn as sns
import re
def get_data(trial, tname):
tensor = trial.tensor(tname)
steps = tensor.steps()
vals = [tensor.value(s) for s in steps]
return steps, vals
def plot_collection(trial, collection_name, regex='.*', figsize=(8, 6)):
fig, ax = plt.subplots(figsize=figsize)
sns.despine()
tensors = trial.collection(collection_name).tensor_names
for tensor_name in sorted(tensors):
if re.match(regex, tensor_name):
steps, data = get_data(trial, tensor_name)
ax.plot(steps, data, label=tensor_name)
ax.legend(loc='center left', bbox_to_anchor=(1, 0.5))
ax.set_xlabel('Iteration')
plot_collection(trial, "average_shap")
まとめと感想
公式のサンプルノートブックに従い,XGBoostでSageMaker Debuggerを試してみました.Debuggerを使うことで,トレーニング中の評価指標,変数重要度,SHAP値等の推移を簡単に保存し解析することができました.本記事では取り上げませんでしたが,モデルそのものや,各データ点における予測値やSHAP値等,より詳細な情報を追跡することも可能です.
もともとXGBoostにせよ深層学習フレームワークにせよ個別のフレームワーク内でコールバック等を利用してデバッグに利用することはできましたが,SageMaker Debuggerではどのフレームワークでも統一的なAPIでフックやルールを書くことができるので,その点はメリットだと思います.フックやルールの便利な設定がデフォルトで色々用意されているのも良いです.
ですが,XGBoostを使うだけであれば,評価指標や変数重要度を見るためだけにわざわざSageMaker Debuggerを使うメリットは少ないかもしれません.ただ,LIMEやSHAPといったモデル解釈のための指標はよく使われるようになってきているものの,トレーニング中もこれらの指標を追いかけて分析まで行っている人はあまりいないのではないでしょうか.現時点ではこれらの指標を簡単に追跡できるのはSageMaker Debuggerだけだと思うので,この機能を使って新たにデバッグや精度改善,モデル解釈のテクニックを考えてみるのはおもしろそうです.