この文書は Dmitriy Selivanov によるRパッケージtext2vec (version 0.3.0) のビネット "Analyzing Texts with the text2vec Package" の日本語訳です.
ただし文中の注は全て訳者によるものです1.
License: MIT
関連文書
- text2vec vignette: text2vecパッケージによるテキスト分析
- text2vec vignette: GloVeによる単語埋め込み
- text2vec vignette: 発展的な話題
特徴
text2vec はRによるテキスト分析と自然言語処理のための,簡潔なAPIを備えたフレームワークを提供します.
このパッケージはC++によって注意深く書かれているため効率的で,メモリにも優しいです.箇所によっては優れたRcppParallelパッケージによって完全に並列化されており,GloVeによる単語埋め込みの訓練はその一例です.つまり,OS XでもLinuxでもWindowsでもSolaris(x86)でも,余計なチューニングをしたり技巧を凝らすことなしに単語埋め込みが並列に計算されます.また,ストリーミングAPIがあるのでユーザは全てのデータをRAMに読み込む必要がありません.
このビネットではtext2vecを使い,任意のnグラムの語彙か素性ハッシングを用いてテキストをベクトル化する方法を説明します.最先端のGloVe単語埋め込みをこのパッケージで使う方法の解説についてはgloveビネットを見てください.
テキストのベクトル化
テキストマイニングや自然言語処理の大抵のモデリングではbag-of-wordsかbag-of-n-gramsという方法が使われます2.これらのモデルは単純であるにもかかわらず,テキストの分類タスクにおいて通常は高い性能を発揮します.ですが,その理論的な単純さと実用的な効率性とは対照的に,bag-of-wordsモデルの構築は技術的には難問です.Rの場合はコピー時修正(copy-on-modify)セマンティクスがあるので特に難しいです.
テキスト分析のパイプライン
典型的なテキスト分析と分析のパイプラインの細部について,簡単に振り返ってみましょう.
- 研究者は通常,入力文書から文書ターム行列(document-term matrix,DTM)を構築することから始めます.言いかえると,最初のステップは単語やnグラムをベクトル空間に写像して文書をベクトル化することです.
- 研究者はモデルをDTMにフィッティングします.モデルはテキスト分類器かもしれませんし,トピックモデルや単語埋め込みかもしれません.モデルのフィッティングにはモデルのチューニングや検証も含みます.
- 最後に,研究者はモデルを新しいデータに適用します.
このビネットでは主に1番目の段階について議論します.テキストそれ自体は大量のメモリを消費することがありますが,ベクトル化されたテキストは疎行列として保存されるので,普通はあまりメモリを消費しません.Rにはコピー時修正セマンティクスがあるので,反復的にDTMを大きくしていくことが容易ではありません.それゆえ,小さな文書集合であってもDTMの構築が分析者や研究者にとっての深刻なボトルネックとなり得ます.RでDTMを構築するには文書集合の全体をRAMに読み込んで単一のベクトルとして処理する必要がありますが,そうするとメモリ使用量が容易に2~4倍まで増大してしまいます.text2vecパッケージはより優れた方法で文書ターム行列を構築することでこの問題を解決しています.
例:IMDB映画レビューデータセットのセンチメント分析
text2vecパッケージはmovie_reviewデータセットを提供します.このデータは5000件の映画レビューからなっており,それぞれのレビューがポジティブなものかネガティブなものか印が付けてあります.
library(text2vec)
data("movie_review")
set.seed(42L)
文書をベクトル空間で表現するには,まずタームにタームIDを対応させる必要があります.単語ではなくタームと呼ぶのは,タームは1語とは限らず任意のnグラムでよいからです.それから文書集合を疎行列で表現し,各行が1つの文書に,各列が1つのタームに対応するものとします.これにはやり方が2通りあります.語彙そのものを使うか,素性ハッシングを使うかです.
語彙に基づくベクトル化
まず語彙に基づくDTMの方を作りましょう.全ての文書からタームを重複なく集め,vocabulary()関数を使って各タームに一意のIDを割り当てます.語彙の作成にはイテレータを使います.
it <- itoken(movie_review$review,
preprocess_function = tolower,
tokenizer = word_tokenizer,
ids = movie_review$id)
sw <- c("i", "me", "my", "myself", "we", "our", "ours", "ourselves", "you", "your", "yours")
vocab <- create_vocabulary(it, stopwords = sw)
あるいは,データがRAMに収まるのであれば,トークンのリストを一度作っておいてそれを以降のステップで使いまわすこともできます.
# リストの各要素が文書を表す
tokens <- movie_review$review %>%
tolower() %>%
word_tokenizer()
it <- itoken(tokens, ids = movie_review$id)
vocab <- create_vocabulary(it, stopwords = sw)
語彙ができたので,文書ターム行列を構築することができます(代わりにcreate_corpus()とget_dtm()を使うこともできるでしょう).
it <- itoken(tokens, ids = movie_review$id)
# Or
# it <- itoken(movie_review$review, tolower, word_tokenizer, ids = movie_review$id)
vectorizer <- vocab_vectorizer(vocab)
dtm <- create_dtm(it, vectorizer)
DTMを作ったので,行列の次元を確認できます.
str(dtm)
## Formal class 'dgCMatrix' [package "Matrix"] with 6 slots
## ..@ i : int [1:706047] 4999 4999 4999 4999 4999 4999 4998 4998 4998 49..
## ..@ p : int [1:42642] 0 1 2 3 4 5 6 7 8 9 ...
## ..@ Dim : int [1:2] 5000 42641
## ..@ Dimnames:List of 2
## .. ..$ : chr [1:5000] "5814_8" "2381_9" "7759_3" "3630_4" ...
## .. ..$ : chr [1:42641] "decent.the" "nudity.i" "nowadays.i" "fantastic.it" ...
## ..@ x : num [1:706047] 1 1 1 1 1 1 1 1 1 1 ...
## ..@ factors : list()
identical(rownames(dtm), movie_review$id)
## [1] TRUE
見ての通りDTMの行数は5000であり,文書の数に等しいです.また列数は5000で,ユニークなタームの数に等しいです.
さて最初のモデルをフィッティングする準備ができました.ここではglmnetパッケージを使い,L1罰則付きのロジスティック回帰モデルをフィットさせてみます.
library(glmnet)
fit <- cv.glmnet(x = dtm, y = movie_review[['sentiment']],
family = 'binomial',
# lasso 罰則
alpha = 1,
# 精度はROC曲線下の面積で評価
type.measure = "auc",
# 5重クロスバリデーション
nfolds = 5,
# 値を大きくすると精度は下がるが訓練が速くなる
thresh = 1e-3,
# こっちも反復回数を減らすと訓練が速くなる
maxit = 1e3)
plot(fit)
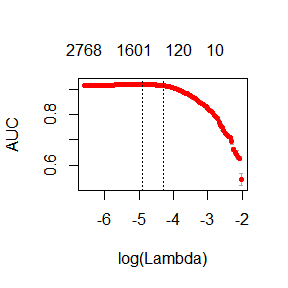
print(paste("max AUC =", round(max(fit$cvm), 4)))
## [1] "max AUC = 0.9186"
うまくDTMにモデルをフィットさせることができました.
余分な語彙を取り除く
しかし,モデルの訓練時間がかなり長かったことに気付きます.余分な語彙を取り除けば,精度を大きく向上させつつ訓練時間を短くすることが可能です.
たとえば,"a"や"the"や"in"といった単語はほとんど全ての文書で見つかりますが,これらの単語はあまり有用な情報を提供してはいません.普通,これらの単語はストップワード(stop words)と呼ばれています.他方,コーパスにはほんの数個の文書にしか出現しないような非常に稀なタームも含まれています.これらのタームも,十分な数のデータがないために有用性が低いものです.ここでは非常に多く出現するタームと非常に稀なタームの両方を取り除くことにします.
pruned_vocab <- prune_vocabulary(vocab, term_count_min = 10,
doc_proportion_max = 0.5, doc_proportion_min = 0.001)
it <- itoken(tokens, ids = movie_review$id)
vectorizer <- vocab_vectorizer(pruned_vocab)
dtm <- create_dtm(it, vectorizer)
dim(dtm)
## [1] 5000 7656
新しいDTMはもとのDTMより列数がずっと少なくなっていることに注目してください.
TF-IDF
DTMに対してTF-IDF変換を利用することもできます(し,普通は利用するべきです!).TF-IDFは少数の文書に特有なタームの重みを大きくし,多くの文書で使われているタームの重みは減らします.
dtm <- dtm %>% transform_tfidf()
## idf scaling matrix not provided, calculating it form input matrix
さて,もう一度モデルをフィットさせてみましょう.
t1 <- Sys.time()
fit <- cv.glmnet(x = dtm, y = movie_review[['sentiment']],
family = 'binomial',
alpha = 1,
type.measure = "auc",
nfolds = 5,
thresh = 1e-3,
maxit = 1e3)
print(difftime(Sys.time(), t1, units = 'sec'))
## Time difference of 4.092234 secs
plot(fit)
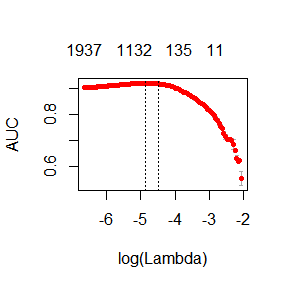
print(paste("max AUC =", round(max(fit$cvm), 4)))
## [1] "max AUC = 0.9199"
モデルをより速く訓練することができ,AUCの値も大きくなりました.
さらにモデルを改善できるか?
単語ではなくnグラムを使うことでモデルを改善できるか試してみることもできます.3グラムまで使うことにします.
it <- itoken(tokens, ids = movie_review$id)
vocab <- create_vocabulary(it, ngram = c(1L, 3L)) %>%
prune_vocabulary(term_count_min = 10,
doc_proportion_max = 0.5,
doc_proportion_min = 0.001)
vectorizer <- vocab_vectorizer(vocab)
dtm <- tokens %>%
itoken() %>%
create_dtm(vectorizer) %>%
transform_tfidf()
## idf scaling matrix not provided, calculating it form input matrix
dim(dtm)
## [1] 5000 27226
fit <- cv.glmnet(x = dtm, y = movie_review[['sentiment']],
family = 'binomial',
alpha = 1,
type.measure = "auc",
nfolds = 5,
thresh = 1e-3,
maxit = 1e3)
plot(fit)
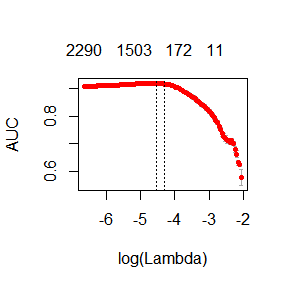
print(paste("max AUC =", round(max(fit$cvm), 4)))
## [1] "max AUC = 0.9193"
nグラムを使うことでモデルがもう少し改善しました.さらなるチューニングは読者に委ねます.
素性ハッシング
もし素性ハッシング(いわゆるハッシングトリック(hashing trick))になじみがなければ,ウィキペディアの記事をまず読んでから,Yahoo!の研究チームによる原論文を読むのがよいでしょう.このテクニックは連想配列上での検索を行う必要がないため,非常に高速です.もう一つの利点として,任意の個数の素性をずっとコンパクトな空間へと写像できるので,メモリの使用量も非常に少なくなります.この手法はYahoo!のおかげで普及し,Vowpal Wabbitにおいて広範に利用されています.
text2vecで素性ハッシングを使うには以下のようにします.
it <- itoken(tokens, ids = movie_review$id)
vectorizer <- hash_vectorizer(hash_size = 2 ^ 16, ngram = c(1L, 3L))
dtm <- create_dtm(it, vectorizer) %>%
transform_tfidf()
## idf scaling matrix not provided, calculating it form input matrix
fit <- cv.glmnet(x = dtm, y = movie_review[['sentiment']],
family = 'binomial',
alpha = 1,
type.measure = "auc",
nfolds = 5,
thresh = 1e-3,
maxit = 1e3)
plot(fit)
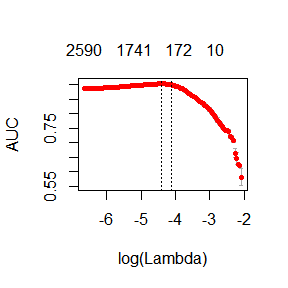
print(paste("max AUC =", round(max(fit$cvm), 4)))
## [1] "max AUC = 0.9027"
見ての通りAUCは少し悪化していますが,DTMの構築にかかる時間はかなり短くなりました.これは巨大な文書集合に対しては大きなメリットになり得ます.
-
訳者の環境を示しておく.
devtools::session_info()## Session info -------------------------------------------------------------------## setting value ## version R version 3.3.1 (2016-06-21) ## system x86_64, mingw32 ## ui RTerm ## language (EN) ## collate Japanese_Japan.932 ## tz Asia/Tokyo ## date 2016-09-03## Packages -----------------------------------------------------------------------↩## package * version date source ## chron 2.3-47 2015-06-24 CRAN (R 3.3.1) ## codetools 0.2-14 2015-07-15 CRAN (R 3.3.1) ## data.table 1.9.6 2015-09-19 CRAN (R 3.3.1) ## devtools 1.12.0 2016-06-24 CRAN (R 3.3.1) ## digest 0.6.10 2016-08-02 CRAN (R 3.3.1) ## evaluate 0.9 2016-04-29 CRAN (R 3.3.1) ## foreach * 1.4.3 2015-10-13 CRAN (R 3.2.2) ## formatR 1.4 2016-05-09 CRAN (R 3.3.1) ## glmnet * 2.0-5 2016-03-17 CRAN (R 3.3.1) ## htmltools 0.3.5 2016-03-21 CRAN (R 3.3.1) ## iterators 1.0.8 2015-10-13 CRAN (R 3.2.2) ## knitr 1.14 2016-08-13 CRAN (R 3.3.1) ## lattice 0.20-33 2015-07-14 CRAN (R 3.3.1) ## magrittr 1.5 2014-11-22 CRAN (R 3.3.1) ## Matrix * 1.2-6 2016-05-02 CRAN (R 3.3.1) ## memoise 1.0.0 2016-01-29 CRAN (R 3.3.1) ## Rcpp 0.12.6 2016-07-19 CRAN (R 3.3.1) ## RcppParallel 4.3.20 2016-08-16 CRAN (R 3.3.1) ## RevoUtils 10.0.1 2016-08-24 local ## RevoUtilsMath * 8.0.3 2016-04-13 local ## rmarkdown 1.0 2016-07-08 CRAN (R 3.3.1) ## stringi 1.1.1 2016-05-27 CRAN (R 3.3.0) ## stringr 1.1.0 2016-08-19 CRAN (R 3.3.1) ## text2vec * 0.3.0 2016-03-31 CRAN (R 3.3.1) ## withr 1.0.2 2016-06-20 CRAN (R 3.3.1) ## yaml 2.1.13 2014-06-12 CRAN (R 3.3.1) -
bag-of-wordsもn-gramも日本語ウィキペディアでは項目がないため英語版へのリンクのままとした.以下でも日本語ウィキペディアの項目が存在する場合にはそちらへのリンク,ない場合には英語版へのリンクとしている. ↩