概要
Vertex AI Agent Builder Media recommendationを使ってmovielensのレコメンドエンジンを試してみる。
内容は、Get started with media recommendationsの中身をやってみるものです。
まとめ
- VertexAI Agent Builderで簡単にRecommendationエンジンを作成できる✅
- Recommendation typesは
Others You May Like、Recommended for You、More Like This、Most Popularがあるのである程度カバーできている
- Recommendation typesは
- Data SourceはGCSやBQに対応している✅
- 必要な形への変換はBQのViewを使うことで簡単に利用可能
- 定期インポートがサポートされているので設定後の運用が楽
 (Import from BigQuery - Periodic ingestion)
(Import from BigQuery - Periodic ingestion)
- Searchも同様のデータソースを利用できるので、検索とレコメンデーションを高速に実装できる✅ → Searchはこちら
- Applicationはlibraryがあるので他のGoogle Service同様に簡単にクライアントで呼び出しができる✅
- Support されているmedia_typeは
movie, show, concert, event, live-event, broadcast, tv-series, episode, video-game, clip, vlog, audio, audio-book, music, album, articles, news, radio, podcast, book, and sports-game(ref)
Prepare BQ Dataset
https://qiita.com/nakamasato/items/295a2a3a4d5ed2aab2d5 ですでにデータを準備した人はSkip可
bqのdataset movielens作成
bq mk $PROJECT_ID:movielens
csvからmovies テーブルをload
bq load --skip_leading_rows=1 movielens.movies \
gs://cloud-samples-data/gen-app-builder/media-recommendations/movies.csv \
movieId:integer,title,genres
csvからratingテーブルをload
bq load --skip_leading_rows=1 movielens.ratings \
gs://cloud-samples-data/gen-app-builder/media-recommendations/ratings.csv \
userId:integer,movieId:integer,rating:float,time:timestamp
view movies_viewを作成
bq mk --project_id=$PROJECT_ID \
--use_legacy_sql=false \
--view "
WITH t AS (
SELECT
CAST(movieId AS string) AS id,
SUBSTR(title, 0, 128) AS title,
SPLIT(genres, \"|\") AS categories
FROM \`$PROJECT_ID.movielens.movies\`)
SELECT
id, \"default_schema\" as schemaId, null as parentDocumentId,
TO_JSON_STRING(STRUCT(title as title, categories as categories,
CONCAT(\"http://mytestdomain.movie/content/\", id) as uri,
\"2023-01-01T00:00:00Z\" as available_time,
\"2033-01-01T00:00:00Z\" as expire_time,
\"movie\" as media_type)) as jsonData
FROM t;" \
$PROJECT_ID:movielens.movies_view

view user_events_for_search (user_events is already used in https://qiita.com/nakamasato/items/012ea7159d3e3fc8e30e)
bq mk --project_id=$PROJECT_ID \
--use_legacy_sql=false \
--view "
WITH t AS (
SELECT
MIN(UNIX_SECONDS(time)) AS old_start,
MAX(UNIX_SECONDS(time)) AS old_end,
UNIX_SECONDS(TIMESTAMP_SUB(
CURRENT_TIMESTAMP(), INTERVAL 90 DAY)) AS new_start,
UNIX_SECONDS(CURRENT_TIMESTAMP()) AS new_end
FROM \`$PROJECT_ID.movielens.ratings\`)
SELECT
CAST(userId AS STRING) AS userPseudoId,
\"view-item\" AS eventType,
FORMAT_TIMESTAMP(\"%Y-%m-%dT%X%Ez\",
TIMESTAMP_SECONDS(CAST(
(t.new_start + (UNIX_SECONDS(time) - t.old_start) *
(t.new_end - t.new_start) / (t.old_end - t.old_start))
AS int64))) AS eventTime,
[STRUCT(movieId AS id, null AS name)] AS documents,
FROM \`$PROJECT_ID.movielens.ratings\`, t
WHERE rating >= 4;" \
$PROJECT_ID:movielens.user_events_for_search
document nameは常にnullが入り、document idにはmovie idが入っている

Create a recommendation app
Agent Builder AppからRecommendationを選択してappを作成。
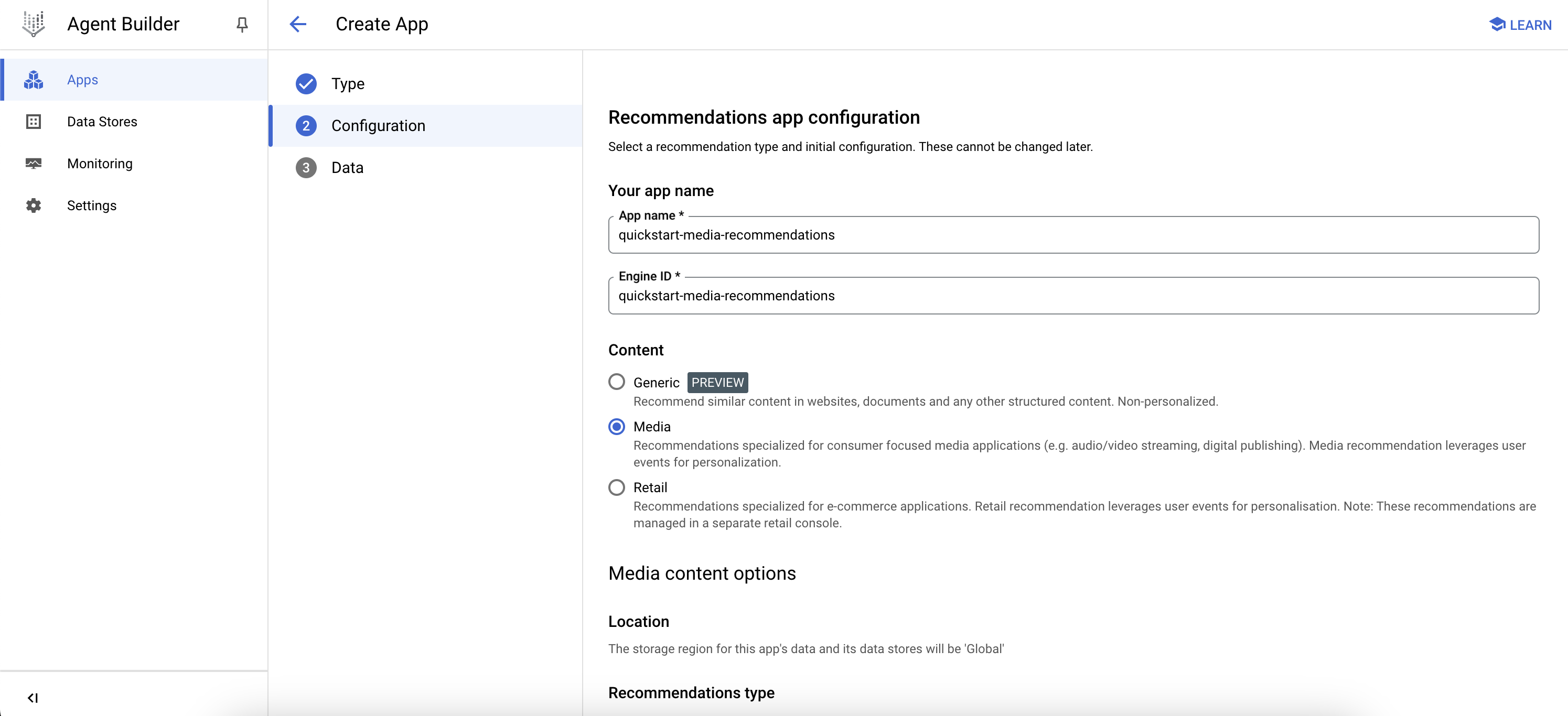
- app name:
quickstart-media-recommendations - Content:
Media - Recommendation type:
Others you may like(詳細画面などで出すような推薦タイプ) - Business Objective:
Click-through rate (CTR)
Configuration:
すでに https://qiita.com/nakamasato/items/295a2a3a4d5ed2aab2d5 データを作成済みの場合は、流用すれば良い

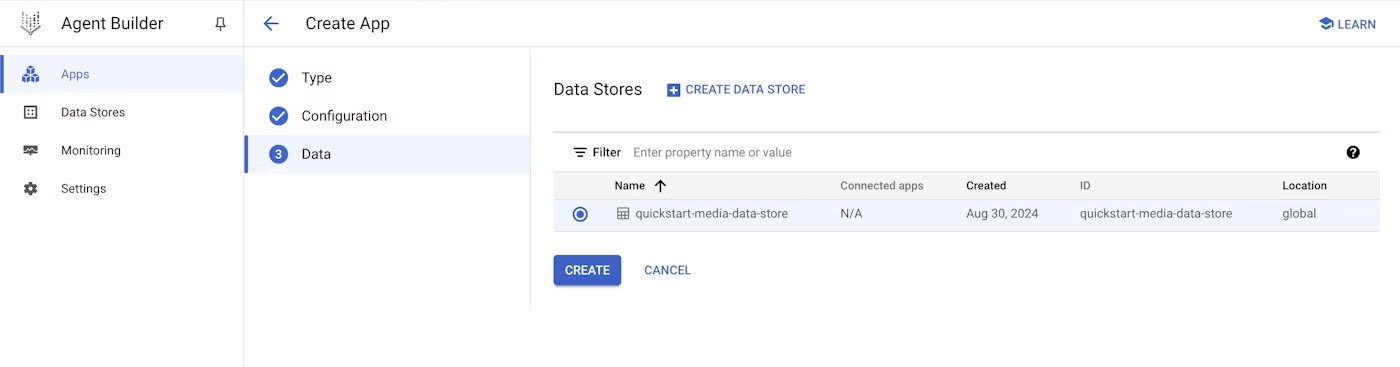
Data storeの作成

作成したdata sourceを選択してappの作成を完了
データのインポート
Documentのインポート
https://qiita.com/nakamasato/items/295a2a3a4d5ed2aab2d5 ですでにインポートの場合はSkipしてください
BigQueryまたはCloud Storageが選択できるので、今回はbigqueryを選択
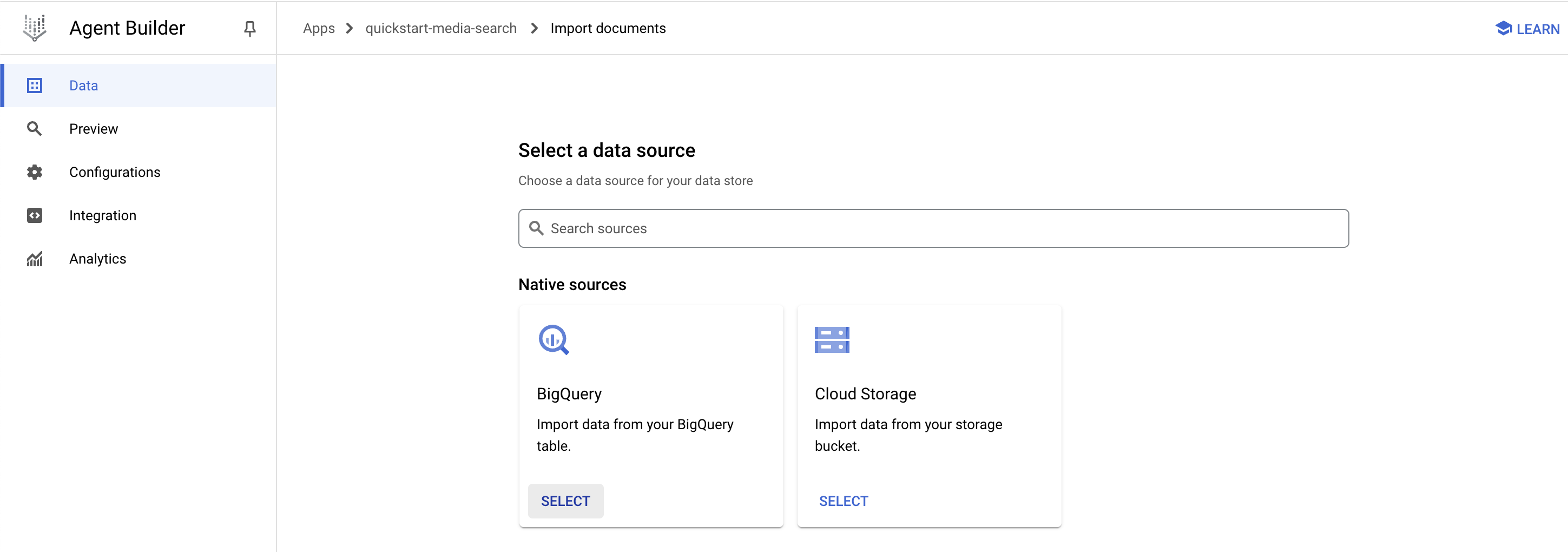
Datasetを選択
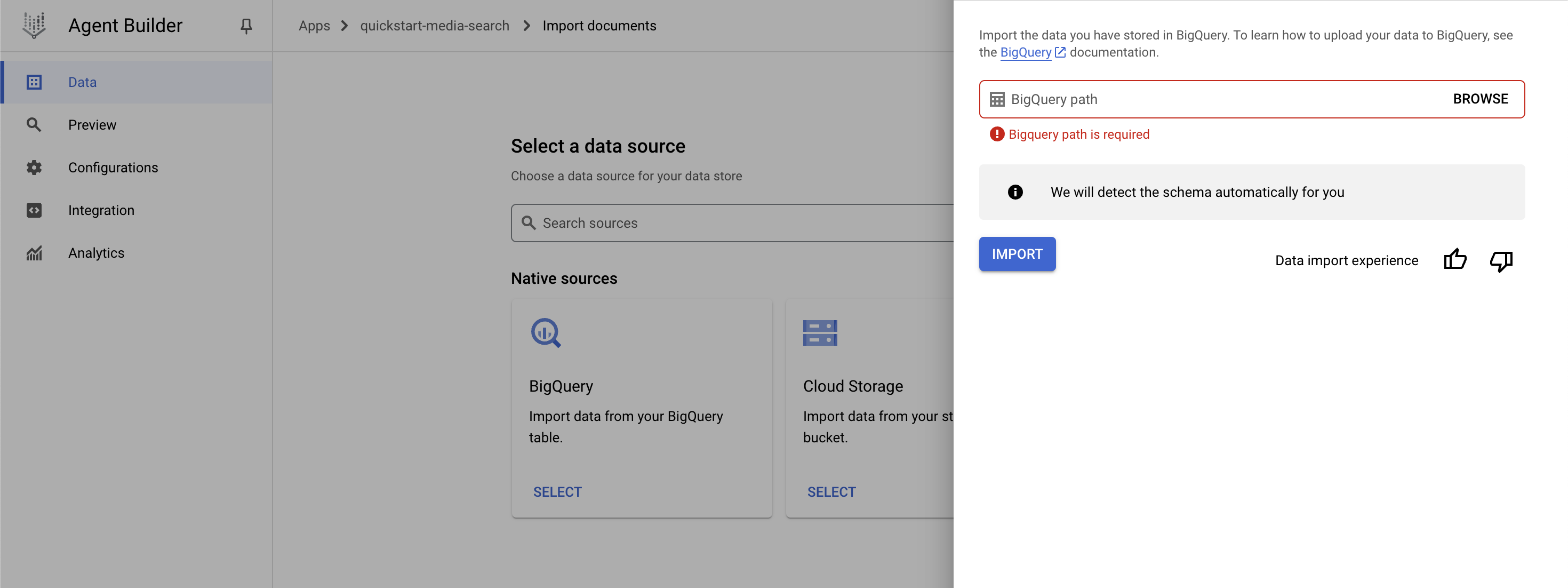
先ほど作成したmovielensのmovies_view を選択してimportする

importには15分くらいかかるので完了を待つ

86,537 documents importされる
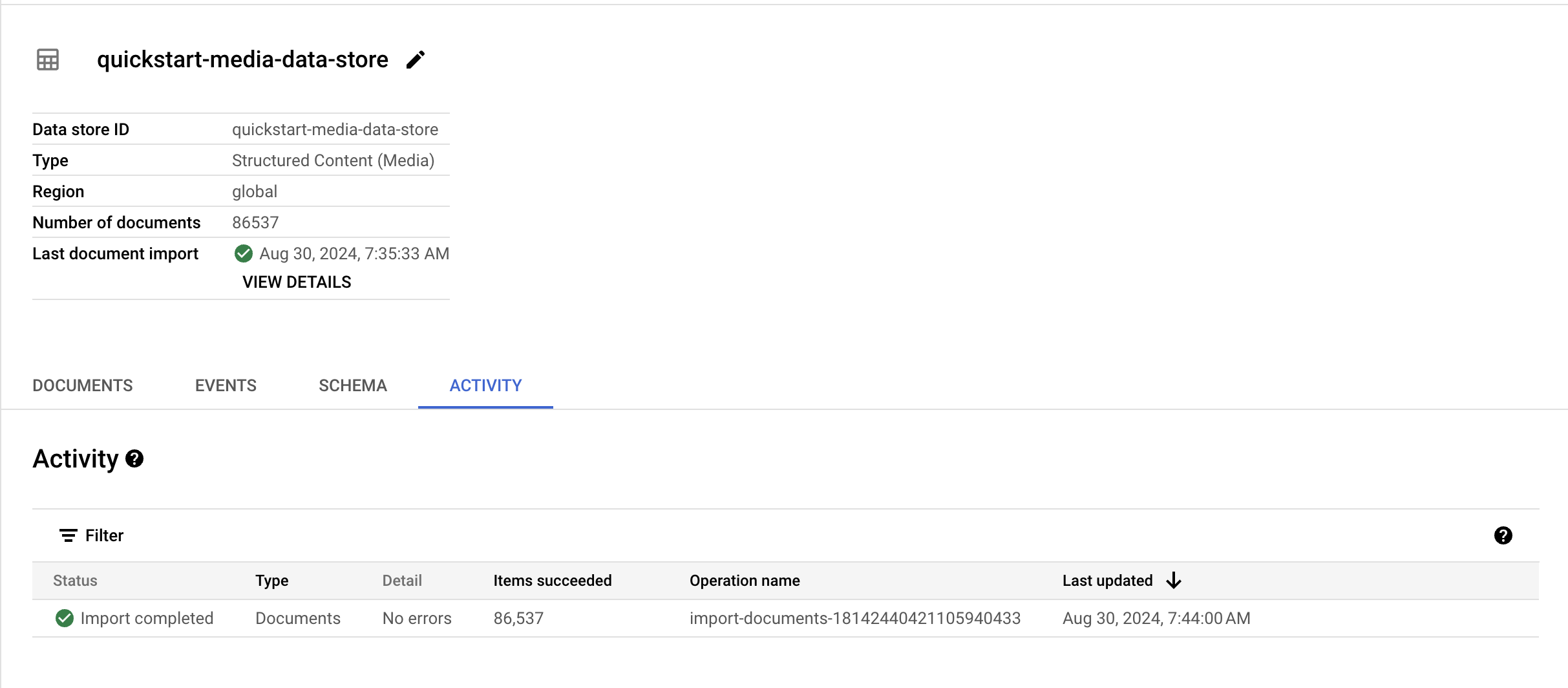
User Dataのインポート
ここではuser_events_for_searchとなっているのは、https://qiita.com/nakamasato/items/295a2a3a4d5ed2aab2d5 ですでにインポート済みのデータを利用しているため
次にEventタブから Import Eventsをクリックする

同様にBigQueryを選択して、user_events_for_search (上でインポートしたテーブル)を指定して、インポート

完了

モデルの学習 (~24 hours)

- Recommendation demotion: 今まで見たコンテンツや古いコンテンツの順位を下げるかどうか
- Result Diversification: 多様性をData-Driven or Rule-Basedを選べる
これで学習を開始できる。
TrainingタブからStatusを確認することができる

完了 ✅
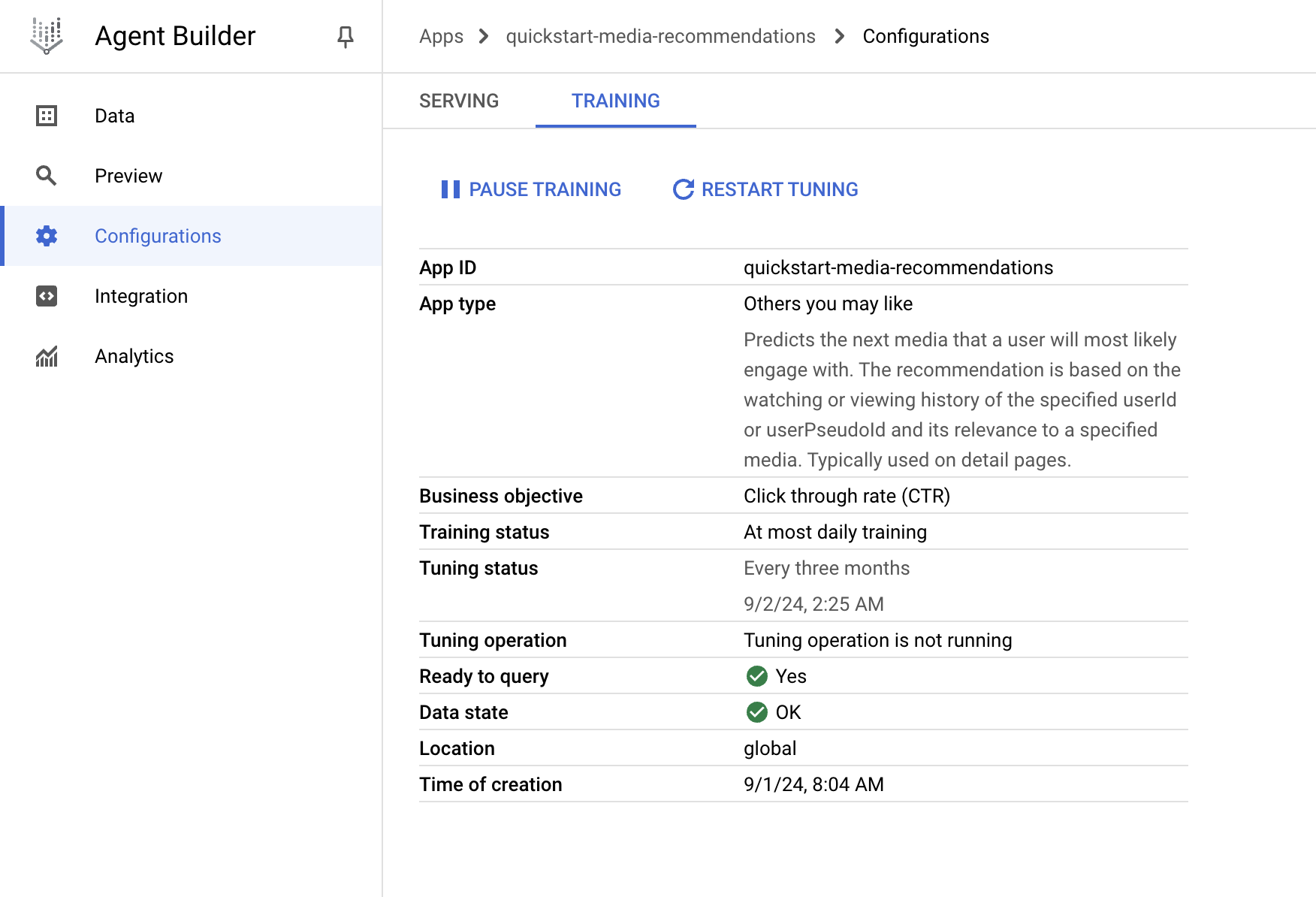
結果の確認
Preview tabで、Document IDに 4993 ("The Lord of the Rings: The Fellowship of the Ring (2001)") を入れてGet Recommendationをしてみる

Applicationに組み込む
こちらを参考にADCと一緒にClientを実装するとできる
package main
import (
"context"
"fmt"
"log"
"os"
discoveryengine "cloud.google.com/go/discoveryengine/apiv1beta"
discoveryenginepb "cloud.google.com/go/discoveryengine/apiv1beta/discoveryenginepb"
)
func main() {
ctx := context.Background()
// This snippet has been automatically generated and should be regarded as a code template only.
// It will require modifications to work:
// - It may require correct/in-range values for request initialization.
// - It may require specifying regional endpoints when creating the service client as shown in:
// https://pkg.go.dev/cloud.google.com/go#hdr-Client_Options
c, err := discoveryengine.NewRecommendationClient(ctx)
if err != nil {
os.Exit(1)
}
defer c.Close()
// {"params":{"returnDocument":true},"userEvent":{"eventType":"view-item","userPseudoId":"b60dd0af-a09f-9b7b-46dd-6219ee3a817f","documents":[{"id":"1"}]},"useLatestServingConfig":true}
projectNumber := os.Getenv("PROJECT_NUMBER")
engine := os.Getenv("ENGINE")
servingConfig := os.Getenv("SERVING_CONFIG")
req := &discoveryenginepb.RecommendRequest{
ServingConfig: fmt.Sprintf("projects/%s/locations/global/collections/default_collection/engines/%s/servingConfigs/%s", projectNumber, engine, servingConfig),
UserEvent: &discoveryenginepb.UserEvent{
EventType: "view-item",
UserPseudoId: "user123",
Documents: []*discoveryenginepb.DocumentInfo{
{
DocumentDescriptor: &discoveryenginepb.DocumentInfo_Id{
Id: "2",
},
},
},
},
}
resp, err := c.Recommend(ctx, req)
if err != nil {
log.Fatal(err)
}
fmt.Println(resp)
}
export PROJECT_NUMBER=xxx
export ENGINE=quickstart-media-recommendations
export SERVING_CONFIG=quickstart-media-recommendations
go run main.go
results:{id:"79132"} results:{id:"1367"} results:{id:"260"} results:{id:"480"} results:{id:"586"} results:{id:"50872"} results:{id:"58559"} results:{id:"356"} results:{id:"837"} results:{id:"166528"} results:{id:"858"} results:{id:"4306"} results:{id:"1"} results:{id:"318"} results:{id:"5952"} results:{id:"780"} results:{id:"527"} results:{id:"1544"} results:{id:"1196"} results:{id:"4993"} attribution_token:"xxxx"
go run main.go
results:{id:"356"} results:{id:"586"} results:{id:"1367"} results:{id:"79132"} results:{id:"480"} results:{id:"158"} results:{id:"8961"} results:{id:"837"} results:{id:"736"} results:{id:"277"} results:{id:"260"} results:{id:"485"} results:{id:"4306"} results:{id:"58559"} results:{id:"1544"} results:{id:"588"} results:{id:"780"} results:{id:"594"} results:{id:"318"} results:{id:"364"} attribution_token:"xxxx"
DataのImport
Import from BigQuery、Import from Cloud Storageでは Periodic ingestion (Public Preview) がサポートされているので、定期的にデータを更新することも可能 (1,3,5日に1回のどれか)
Periodic ingestion: You import data from one or more BigQuery tables, and you set a sync frequency that determines how often the data stores are updated with the most recent data from the BigQuery dataset.
Data updates automatically every 1, 3, or 5 days. Data cannot be manually refreshed.
詳細は、Create a search data store
Ref
- Get started with media recommendations: 今回の内容
- Get Recommendations: APIなどを使ってRecommendationを取得する部分 (推論を利用する)
- Filter Recommendations: まだ見てないが
- About media app recommendations types
- movielens search with Vertex AI Agent Builder Media search: Recommendationとは別に同じData Sourceを使ってSearch機能も提供できるのでこちらも参考に