hadoop入門
ゼロからはじめる人のために!
番外編 超基本コマンド集
| command | 意味 |
|---|---|
| hadoop version | 情報をチェック |
| hadoop fs -cat hdfsファイル | catの部分は ls, rm などにも変更して、LinuxCommand的なのが使える |
| hadoop job -kill job_番号 | ミスしたとわかったときにJobをKillする |
| hadoop jar /path/to/hadoop-streaming.jar -input /path/to/input -output /path/to/output -mapper “python mr_test.py mapper” -reducer “python mr_test.py reducer” -file mr_test.py | streamingを使ってMRJobを実行 |
ステップ1: 言葉の説明
- hadoopとは:MapperとReducerという2つの部分を書くだけでたくさんのデータを分散処理できるすごいもの(Mapper ReducerはMRと呼ばれたりする)
- MR: Mapper=解析に不要なものを捨てる。Reducer=集計(この時点でよくわからなくても大丈夫)
- hadoop-streaming: Java以外の言語のMRを実行する方法
- スタンドアローンモード:デーモンを一切動作せず、単一のJavaプロセスとして、非分散モードで実行する(分散モードとは複数のマシーンに処理をさせること)
ステップ2: インストールして試してみる
これもすでにやっている人がいるので、それを参考にする!
こちらの記事MacにHadoop入れてPHPでMapReduce書いてみるがとても役に立つ!
簡略化すると
- インストール
2. mac:brew install hadoop
3. ubuntu: ちょっと面倒なので別で記載 - wordcount
4.mkdir input
5.echo "a a a b b c" > input/test1.txt
6.echo "a b c" > input/test2.txt
7. テスト
8. Mac:hadoop jar /usr/local/opt/hadoop/libexec/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount input output
9. Ubuntu:hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount input output(インストールしたバージョンが違くなってますが適宜自分のバージョンに変更してください) - hadoop-streaming (php)
- 疑似分散モード(ローカルホストを使ってローカルホストにSSHでログインするようにして疑似分散モードを試す)
5. core-site.yml
6. hdfs-site.yml
7. hdfs format
8. 起動
9. 試し
と言った感じです。僕自身は少し自分なりに変更して、Pythonを使ったりして試しました。
補足
更に上のQiitaページの参照元(Macでhadoopをちょっとだけ動かしてみる)[http://qiita.com/ysk_1031/items/26752b5da1629c9db8f7]を見ると以下の点もあった。
疑似分散モードで起動したときに、http://localhost:50070/にアクセスすると以下のようなダッシュボードで確認することができる!
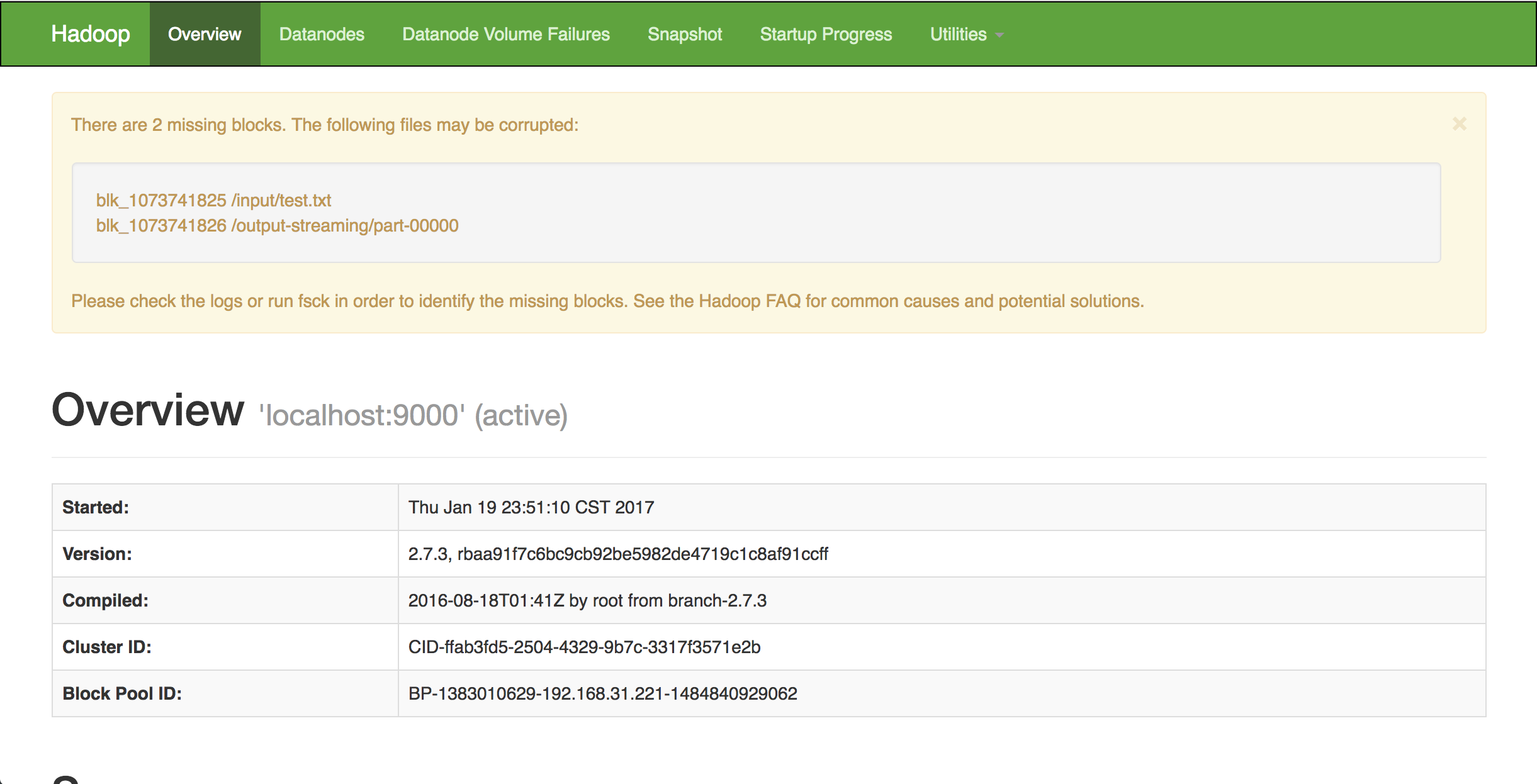
さらに (Yarn)[http://qiita.com/ysk_1031/items/26752b5da1629c9db8f7#yarn] についても記述があるので、チェックしたい人は軽くチェック。
Yarnを起動すると、うえのプロセスに加え、ResourceManager, NodeManagerが起動するよう。