pandasとは?
Pandas公式ドキュメント
Pythonで作られた強力なデータ分析のためのツール(ライブラリ)
つまりデータの読み込み、集計、加工、絞り込みができるし、
ディープラーニング等にかける前のデータの前処理にも役立つ
DataFrameとは?
pandasの機能の一部であるDataFrameを使うことで、2次元の表形式のデータを簡単に操作できる
(DataFrame以外にも1次元のデータを扱うSeriesというものもある)
- 簡単に操作できるってなんやねん?
- 表形式のデータに対して、SQLチックに抽出、追加、加工、結合とかができちゃう
- ファイルやDBなどからデータを読み込んでDataFrameに変換、出力とかできちゃう
- pythonオンリーでやるとfor分でループして...ってなるけどもっとスマートにできちゃう
実際に触ってみよう
まずはシンプルに
# 名前、身長、体重の入った2次元のリスト
sample_data = [['佐藤', 170, 60], ['田中', 160, 50], ['鈴木', 165, 58]]
これをテストデータとして表を作ってみる
ジャーン

なにこれすごく簡単・・・
columnsオプションで項目名を設定できるんやなー わかりやすい
表を作るだけだったらたったこれだけ!操作の方も見ていこう!
特定のデータを取り出す
列を抽出

でかでかとタイトルつけたけど、あっけない...w
さっきcolumnsで指定したカラム名を指定するだけで抽出できる
簡単だ! RubyのHashにアクセスする感じと似てる
列内の◯◯値
では、その抽出した列から最大(or最小)の値を取り出してみよう〜 MAX関数的な!

うん、max関数だった ちなみに最小は当たり前のごとくminで取れる
さらにちなんでおくと、平均値を出すには mean で出せる(heights.mean())
合計はsumとか色々あるみたいだけど、全部は覚えられないから都度調べよう
Pandas公式: http://pandas.pydata.org/pandas-docs/stable/
CSVからデータを読み込んでみる
表作成
使うメソッドは pandas.read_csv()
pandasのこのようなread_XXXメソッドを使えば、データを読み込んでDataFrameに変換までやってくれる優しさ
Name,Price,Date
ボールペン,150,20210514
ノート,150,20210514
のり,100,20210514
のり,120,20210514
こんな感じの文房具リストをサンプルデータとすると

やば
長くなるから端折ったけど、めっちゃ行のあるcsvだと圧巻 爆速
csv読むときのおきまりの呪文であるencodingの指定も忘れないようにしないとね
項目ごとにカウントする
じゃあ上の表から文房具名ごとの個数を表示しようってなったとき、
pythonでやるとfor文で回して、dictionary型の変数をカウントアップしていってってやるかな〜
pandasだと?

むせた
え、マジで。(わかりやすいようにサンプルデータ適当に増やしてます)
group集計する
文房具ごとの値段の合計とかするやつ
同じくfor文でやるとカウントアップの代わりにprice足していくんだろうけど
DataFrame.groupby()を使うと超お手軽
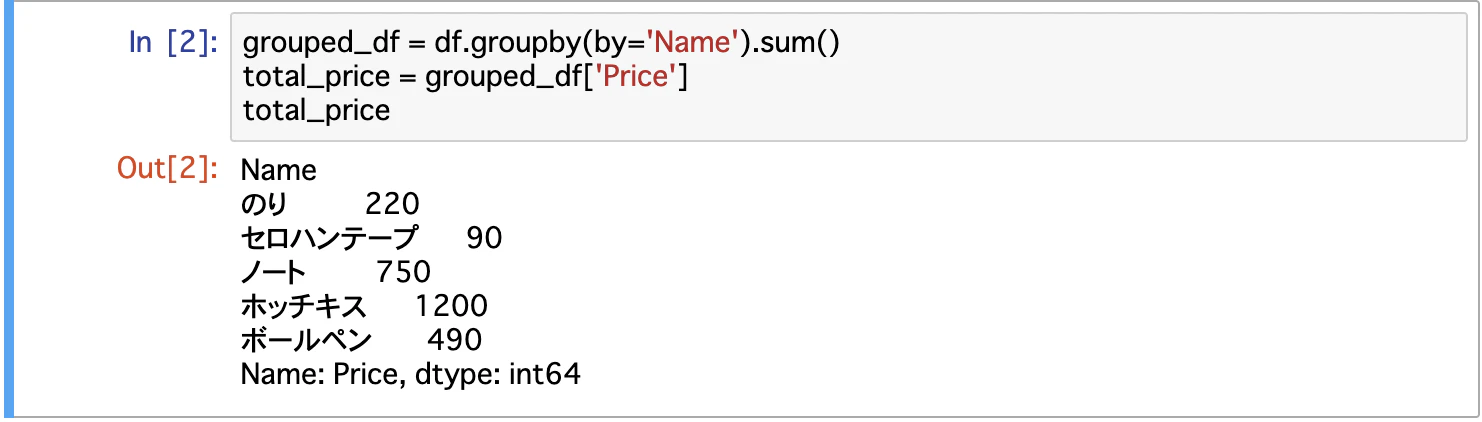
なるほど〜 groupbyでキーを指定して、それに対してsumするのはわかるんだけども
これDateはどうなってるんだろう

うんw 数値として足されてるだけだったw
まあsumでは使わない値だから関係ないけど!
列を追加する
csvから読んだデータから新しい列を動的に挿入する
これループでやろうと思ったら結構嫌やな〜w
Name,Height,Weight
佐藤,172,53
田中,160,50
鈴木,165,58
長谷川,160,65
このデータでいく
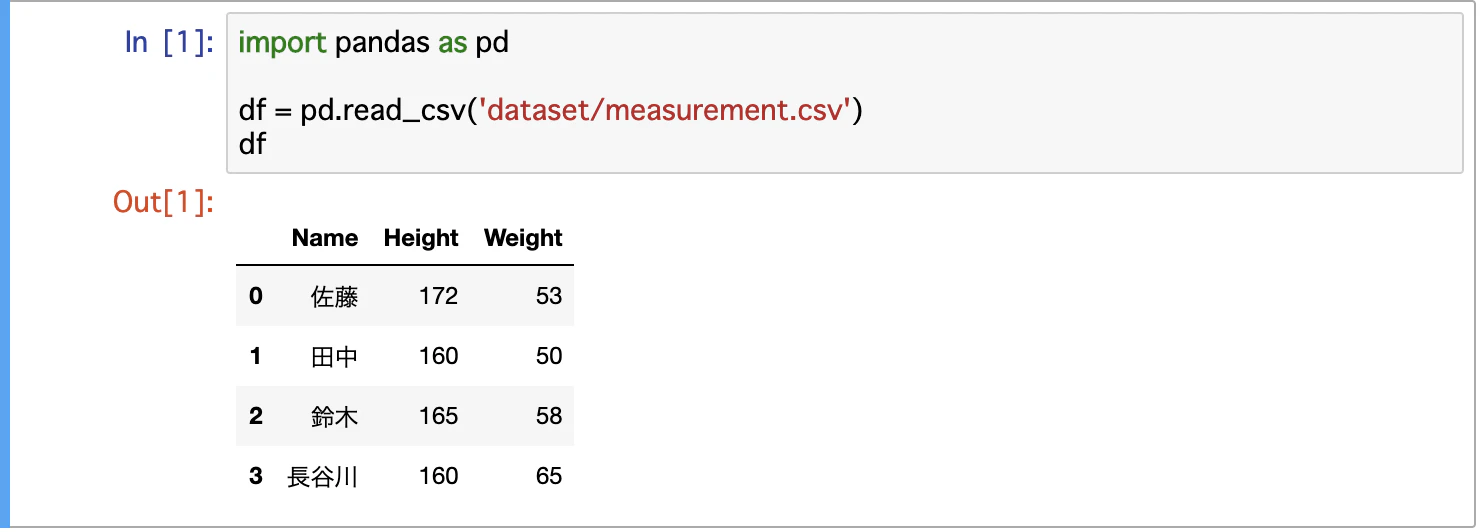
これにHeightのメートル表記の列を追加してみよう

マジかよ
(df['Age'] = 18とかやると前列同じ値で挿入される)
条件付きで絞り込み
こちらも単純でdf[条件式]で絞り込める
上の表を以下の通り表示すると
df[df['Weight'] >= 55]

この2件だけに絞り込める
条件複数指定: df[(df['Weight'] >= 55) | (df['Height'] <= 160)]
※論理演算式がPythonみたいにand, orじゃないので気をつける! &: and, |: or, ~: not
感想
めっちゃ行数少ないぃぃ
個人的に感動したのは読み込んでから変換してくれるところ
これをサササッと使えこなせたらいい感じですねえ