クローラーとは
まずクローリングとは、スクレイピングとセットで扱われ、自動的にインターネットを巡回し、
様々なWebサイトからコンテンツを収集・保存していく処理
それを行うソフトウェアをクローラーと呼ぶ
スクレイピング
webページから取得したコンテンツから必要な情報を抜き出したり、整形したりすることを指す
クローリング
ソフトウェアが自動的にWebコンテンツを収集・保存していくことを指す
コンテンツ内のハイパーリンクを次々辿っていったりもできる
Scrapy
役割的にはRequests、BeautifulSoupと同じ
コンテンツのダウンロード、解析、保存をより簡単にできる、かつ多機能なのがScrapy(先に言ってよ...w)
scrapyのプロジェクトを作る必要があるみたい
$ pip install scrapy
いつも通りインストール なんかちょっと長かった
- Create new Scrapy Project
$ scrapy startproject sample
なるほど〜
Spider
- spiderというクラスを定義してscrapyコマンドを実行するだけでクローリングしてくれる(ずいぶん簡単に言いますな)
import scrapy
class SampleSpider(scrapy.Spider):
name = 'sample' # このクローラーの名前
allowed_domains = ['google.com'] # クローリングを許可するドメイン
start_urls = ['https://www.google.com/?hl=ja'] # 起点となるURL(もちろん許可されたドメインでないとNG)
def parse(self, response):
print(response.text)
上記のようにいくつか設定値があるみたい
starts_urls・・・ 順不同で実行される
parseメソッド ・・・ コンテンツ取得後のコールバックとして実行される、つまりHTML取ってきたあとはここが動く
HTMLを取得してみる
あとは実行するだけでHTMLを取得して表示してくれるとのこと、、、ほんまかいな、、前より簡単すぎぃ
(どうでもいいけど allow を アロウ って発音されると気になって一瞬思考停止する)
$ scrapy crawl sample
...
2019-05-29 14:40:16 [scrapy.core.engine] INFO: Spider opened
2019-05-29 14:40:16 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2019-05-29 14:40:16 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2019-05-29 14:40:16 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.google.com/robots.txt> (referer: None)
2019-05-29 14:40:16 [scrapy.downloadermiddlewares.robotstxt] DEBUG: Forbidden by robots.txt: <GET https://www.google.com/?hl=ja>
2019-05-29 14:40:16 [scrapy.core.engine] INFO: Closing spider (finished)
...
おー?なんかSpiderがopenしてcloseしてるし、crawledでURLが表示されてる!!
でも Forbidden が出てる... うまくはいってないっぽい
robots.txtに設定が足りてないってこと?robots.txtないけど。。。httpsも許可する設定とかがあるのかしら。
今は置いておいて
# (略)
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/page/1/'] # Scrapy公式チュートリアルで使われてたサンプルURL
# (略)
こう変えたらゴチャゴチャ返ってくる中にHTMLが!!
...
2019-05-29 20:26:02 [scrapy.core.engine] INFO: Spider opened
2019-05-29 20:26:02 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2019-05-29 20:26:02 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2019-05-29 20:26:03 [scrapy.core.engine] DEBUG: Crawled (404) <GET http://quotes.toscrape.com/robots.txt> (referer: None)
2019-05-29 20:26:03 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://quotes.toscrape.com/page/1/> (referer: None)
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Quotes to Scrape</title>
...
</footer>
</body>
</html>
2019-05-29 20:26:03 [scrapy.core.engine] INFO: Closing spider (finished)
2019-05-29 20:26:03 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 453,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
'downloader/response_bytes': 2701,
'downloader/response_count': 2,
'downloader/response_status_count/200': 1,
'downloader/response_status_count/404': 1,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2019, 5, 29, 11, 26, 3, 683008),
'log_count/DEBUG': 2,
'log_count/INFO': 9,
'memusage/max': 49848320,
'memusage/startup': 49848320,
'response_received_count': 2,
'robotstxt/request_count': 1,
'robotstxt/response_count': 1,
'robotstxt/response_status_count/404': 1,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2019, 5, 29, 11, 26, 2, 333924)}
2019-05-29 20:26:03 [scrapy.core.engine] INFO: Spider closed (finished)
いい感じ!! 成功したから長めに結果を載せちゃう
取得したHTMLを解析、保存してみる
より実戦で使えそうな感じにするため、上記の方法で取得したHTMLから必要な情報だけ抜き出して、CSVに出してみる
さっきのチュートリアルのサイトは、名言?とその主がダーっと載っているので、名言&主CSVを出す
さっきprintしてたコールバックの部分でやりくりすれば良さそうよね
import scrapy
class SampleSpider(scrapy.Spider):
name = 'sample'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/page/1/']
def parse(self, response):
result_list = []
div_quotes = response.css('div.quote')
for div_quote in div_quotes:
span_text = div_quote.css('span.text::text').extract_first() # css同様class指定だと複数取れるため1件目
quote = span_text.strip()
author = div_quote.css('small.author::text').extract_first().strip()
# 属性で抜きたい場合は ::attr(href) とかできるので覚えといたほうがよさそう
result_list.append({
'quote': quote,
'author': author
})
print(result_list)
- ポイント1:必要なデータのlistを作ることを目指す 各要素は辞書にしておく
- ポイント2:
response.css('~~~')のようにするとCSSセレクターを利用して欲しい情報まで辿れる
[
{
'quote': '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”',
'author': 'Albert Einstein'
},
{
'quote': '“It is our choices, Harry, that show what we truly are, far more than our abilities.”',
'author': 'J.K. Rowling'
},
...
]
1発でうまくいってちょっと感動!
さてここまでくればもう簡単、printではなくcsvに出すぞ
printの箇所をreturnに変える
# (略)
return result_list
そして実行するコマンドを以下のようにする
$ scrapy crawl sample -o quates_list.csv

おおおおおおででで出てきた!!
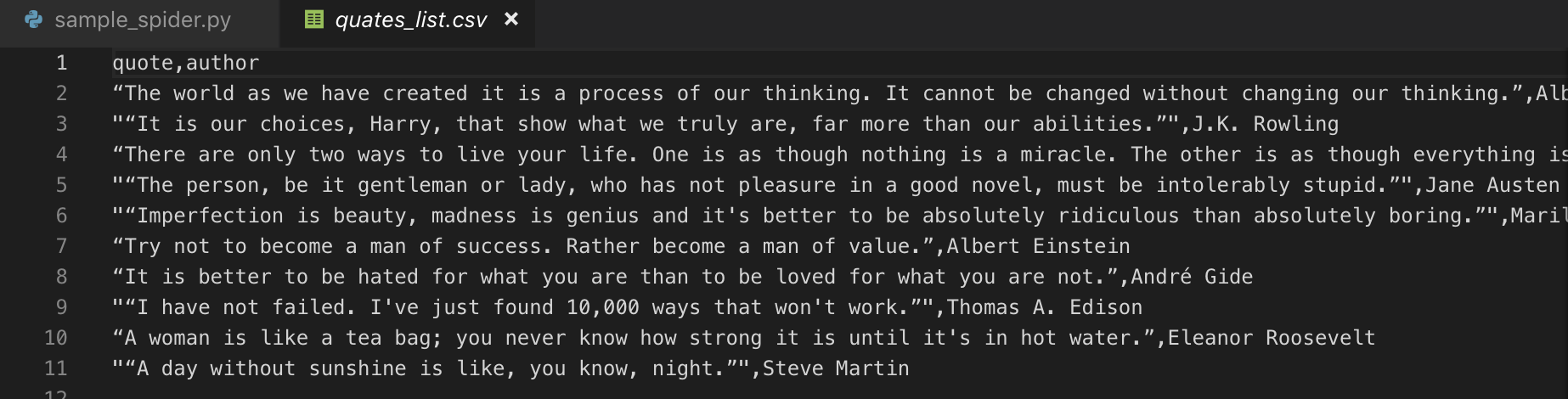
完璧すぎる
そう、
辞書のlistにしておくだけで、ファイル種類(今回はcsv)に合わせて良しなに出してくれる
という涙級の優しさ
なのでコマンドを変えるだけでjsonにもなる(泣)

もっと深掘り:リンクを辿ってクローリング
さっきのサイトのAboutリンクの先のお誕生日まで抜いてきちゃおう
はじめにポイント
- 別のページを取得するには
scrapy.Request()を使う - その別のページ取得後に実行したいcallbackを引数で渡す
def parse(self, response):
result_list = []
div_quotes = response.css('div.quote')
for div_quote in div_quotes:
span_text = div_quote.css('span.text::text').extract_first()
quote = span_text.strip()
author = div_quote.css('small.author::text').extract_first().strip()
about_link = div_quote.css('a::attr(href)').extract_first().strip()
# 初めはこう書いてたけど・・・
# yield scrapy.Request(f'http://quotes.toscrape.com{about_link}', callback=self.parse_about_page)
# 公式に倣えばもっとスマートに書けた urljoin() でURL調整
# yield scrapy.Request(response.urljoin(about_link), callback=self.parse_about_page)
# もっともっとスマートに follow() を使えばurljoinすら要らない
yield response.follow(about_link, callback=self.parse_about_page)
result_list.append({
'quote': quote,
'author': author,
})
return result_list
def parse_about_page(self, response):
birthday = response.css('span.author-born-date::text').extract_first().strip()
return { 'birthday':birthday }
```
一応詳細ページのクローリングには成功したけど、一覧と詳細を組み合わせることはできなかった・・・
(quote, author, birthday のCSVが出したかった)
`yield`、`return`を書いた時点でそこで結果が出力されてしまう
イメージ的にはこういうことがしたかったのにな〜 やりたいことは伝わるはずw
```image.py
# ここでクローリングして解析してきた結果を変数に保持して
birthday = yield response.follow(about_link, callback=self.parse_about_page)
# 一緒に出す
result_list.append({
'quote': quote,
'author': author,
'birthday': birthday
})
return result_list
def parse_about_page(self, response):
birthday = response.css('span.author-born-date::text').extract_first().strip()
return { 'birthday':birthday }
```
一旦別々に出力しておいて、あとでうまいことすれば結果的には同じことできなくはないけど、
もっとスマートにできそう。。。一旦断念
# 感想
色々やり方、機能があるみたいだけど、基本的なことするだけなら超お手軽
一覧で取得したデータと詳細のデータを組み合わせてってのができそうでできなかったけど、これらを活かして自分用のクローラーとか作ってみたいな〜
うまくいかなかったのはもう少し調べてみる
わかったら更新します