はじめに
この記事ではLangChainでBedrockのモデルを呼び出す方法について紹介します。
LangChainを使用することでLLMモデルやプロンプトの管理を効率的に行うことができます。
Amazon SageMakerのNotebookを使用します。
初めて触る方向けに画像多めで説明していきます。
この記事を読むことで、Bedrockのモデルの呼び出し方法の他、
Jupyterの基本操作についても知ることができます。
記事の構成は以下になります。
1.使用するもののリンク紹介
- Amazon SageMaker
- Amazon Bedrock
- LangChain
2.実際に呼び出しを行う
- 事前準備
- Jupyter基本操作
- 実行
3.まとめ
使用するものの概要説明
Amazon Bedrock
いろいろな生成AIモデルを簡単に使えるようにしたプラットフォームです。
インフラ管理が不要で、必要なときに使いたいモデルを選んで利用できます。
Amazon SageMaker
Amazon SageMakerは、AWSが提供する機械学習プラットフォームで、データ準備、モデル構築、トレーニング、デプロイまでを簡単に行えるツールです。
今回は、SageMaker上でJupyter Notebookを使い、Amazon Bedrockのモデルを呼び出す部分にフォーカスします。
LangChain
言語モデル(LLM)の活用をより簡単かつ強力にするためのPythonライブラリです。
複雑なタスクを構築可能なモジュール化された設計が特徴で、プロンプト作成やモデルとの対話を効率化します。
事前準備
本記事では、東京リージョンで作成していきます。
Bedrockモデルの選択
最初に使用したいモデルを有効にします。
今回はClaudeのモデルだけ有効化したいので、特定のモデルを有効にするを選択します。
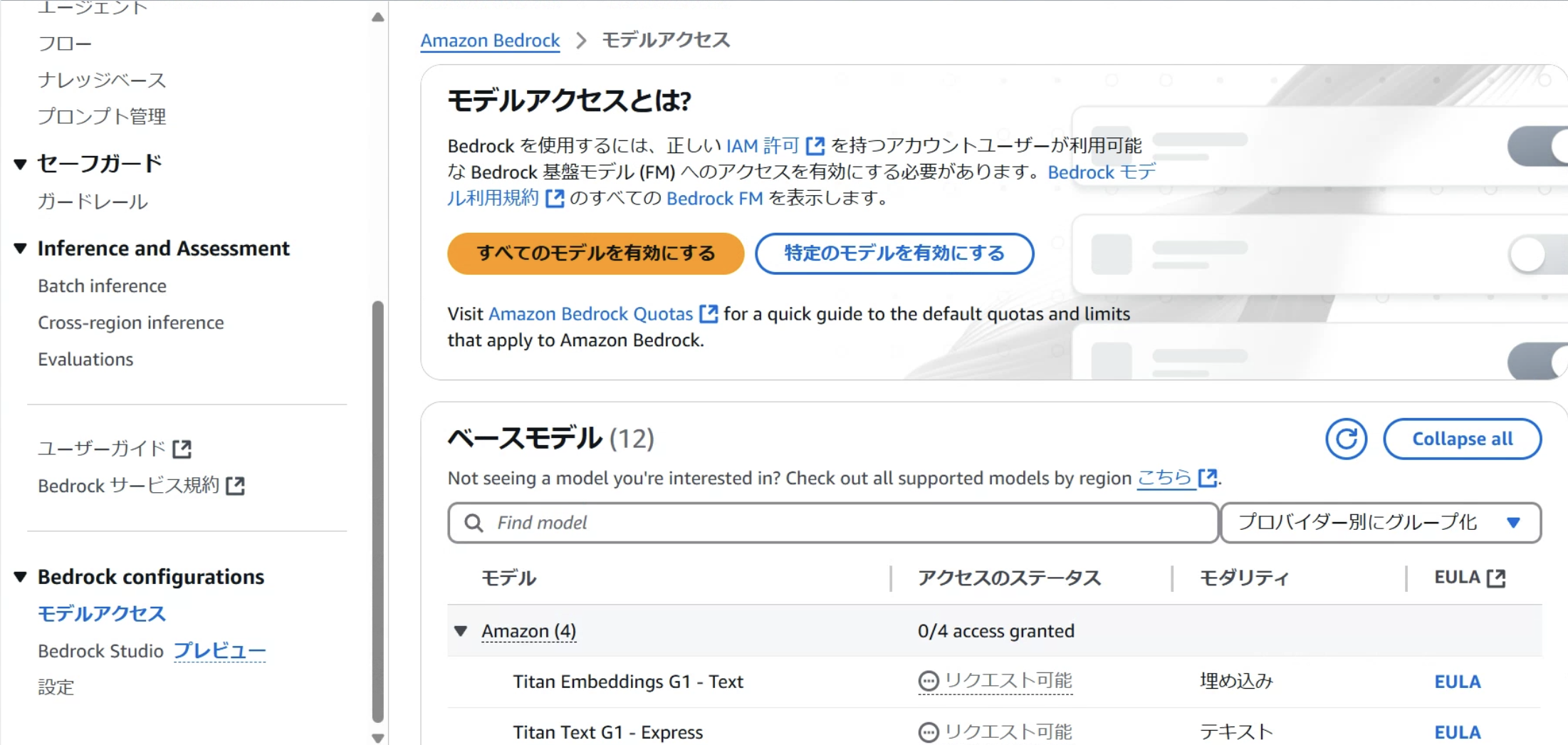
画像のようにモデルを選択し、次へ
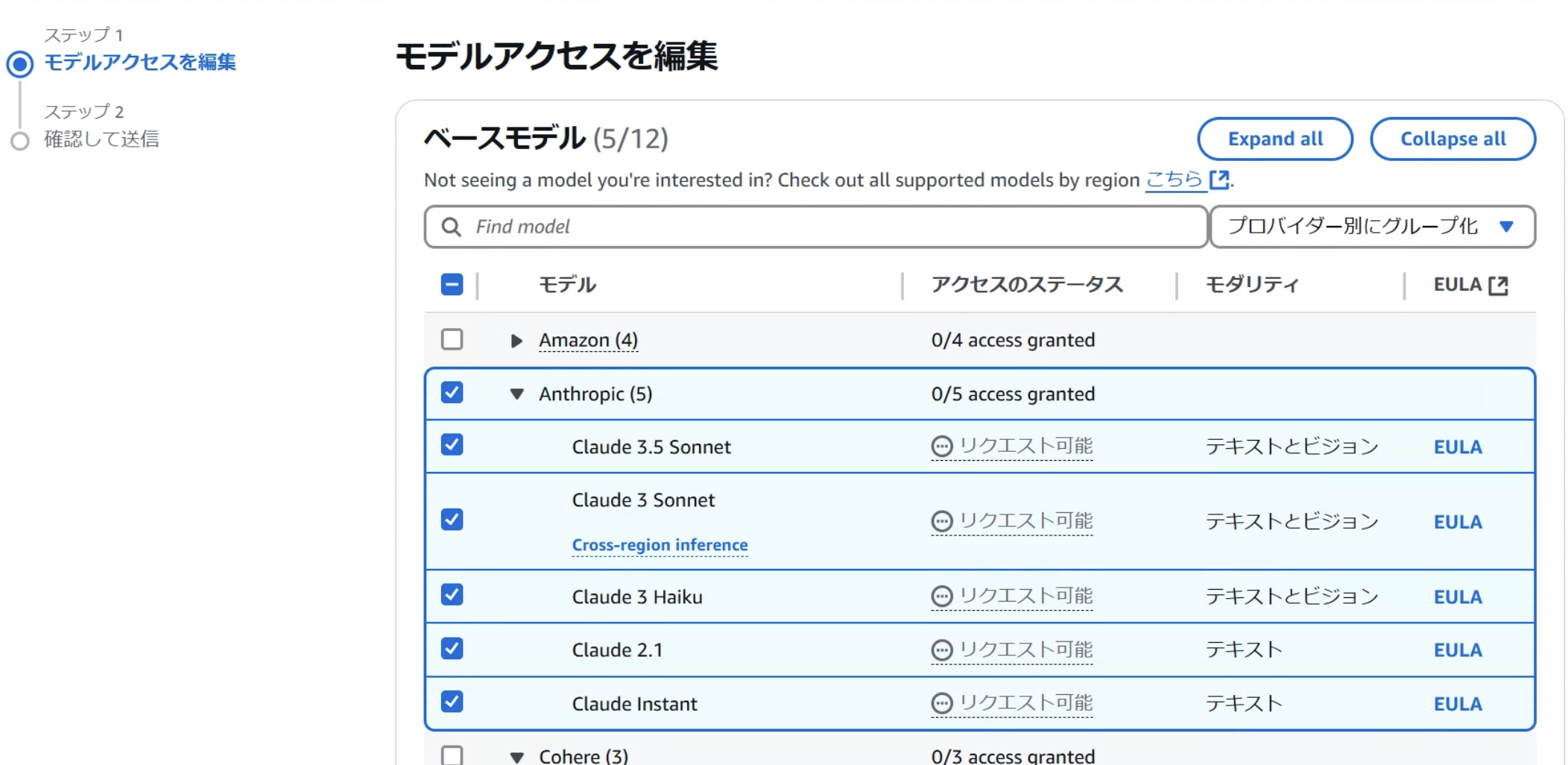
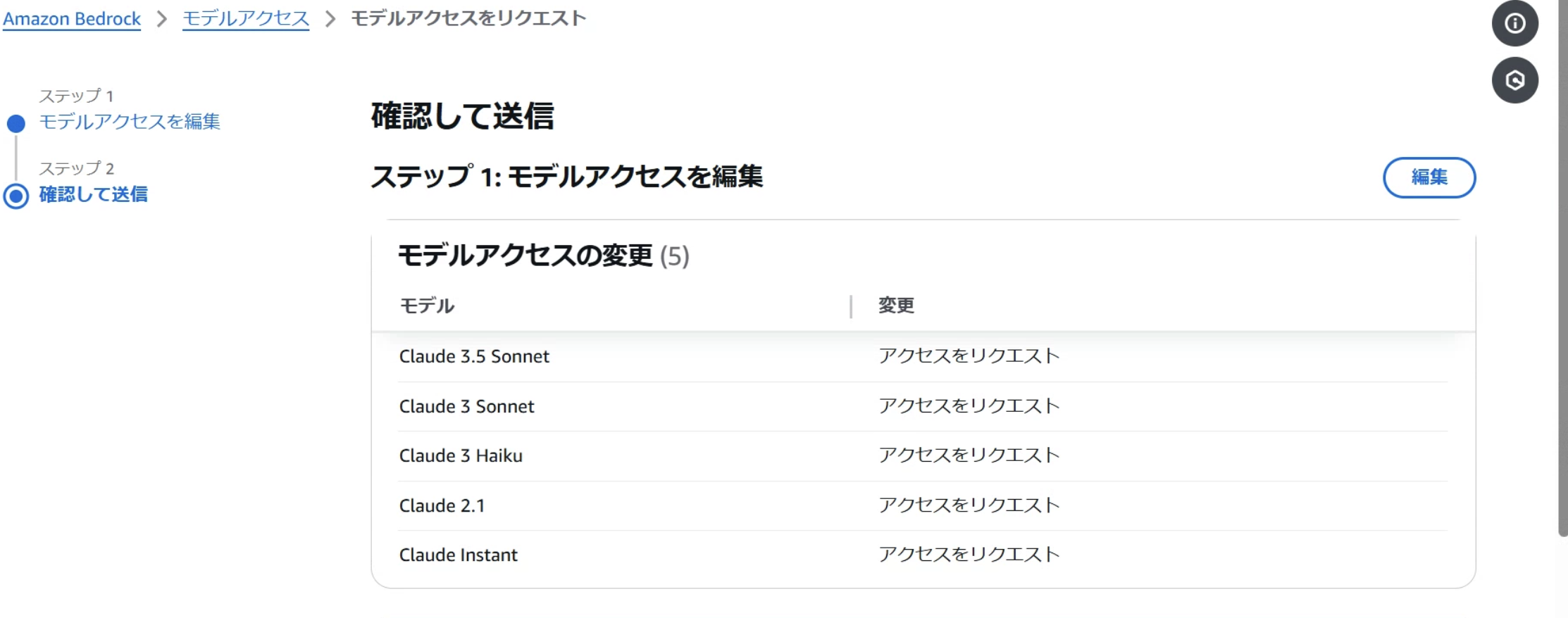
選択したモデルを確認したら、送信します。
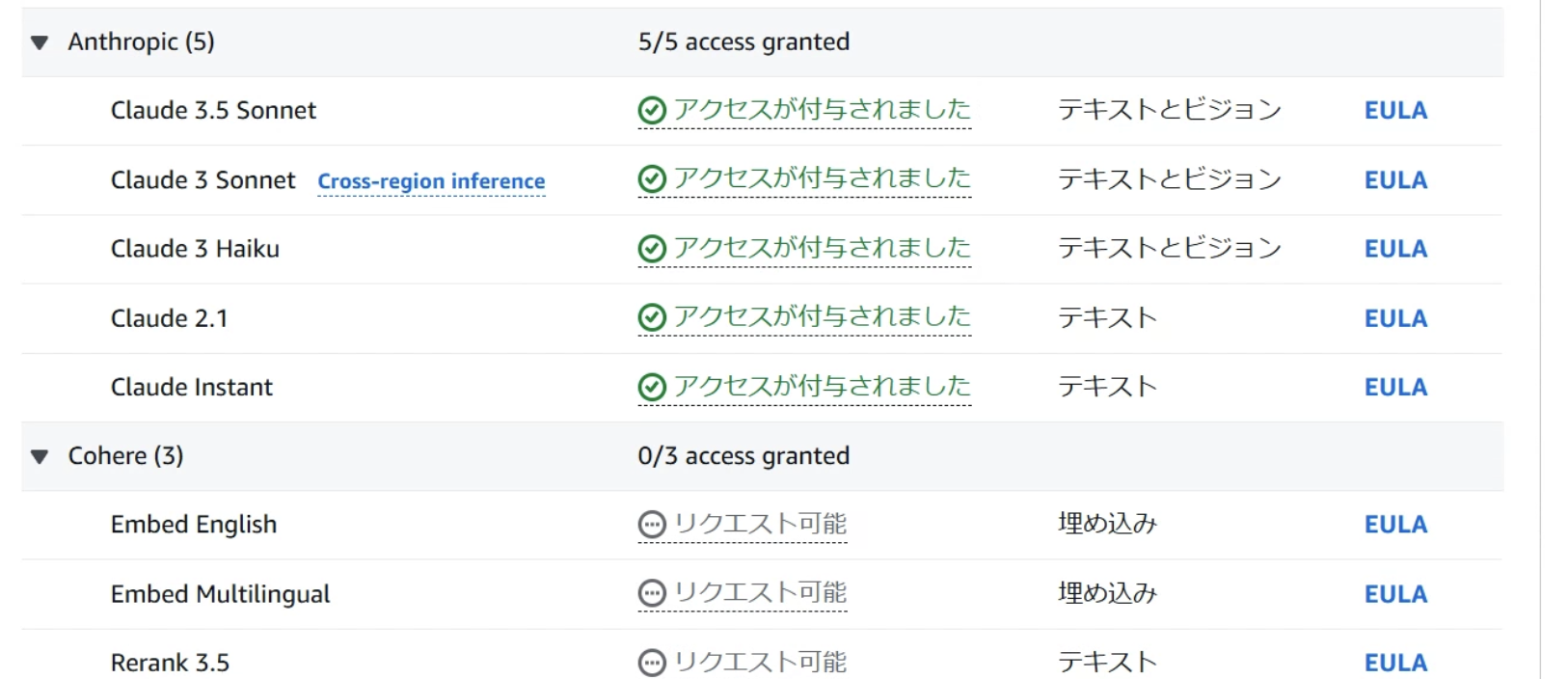
アクセスが付与されたのを確認したらBedrockのモデル選択は完了です。
※時間差でAWS Marketplaceからアクセス許可のオファーが受け入れられた旨のメールが来ます。
IAMの準備
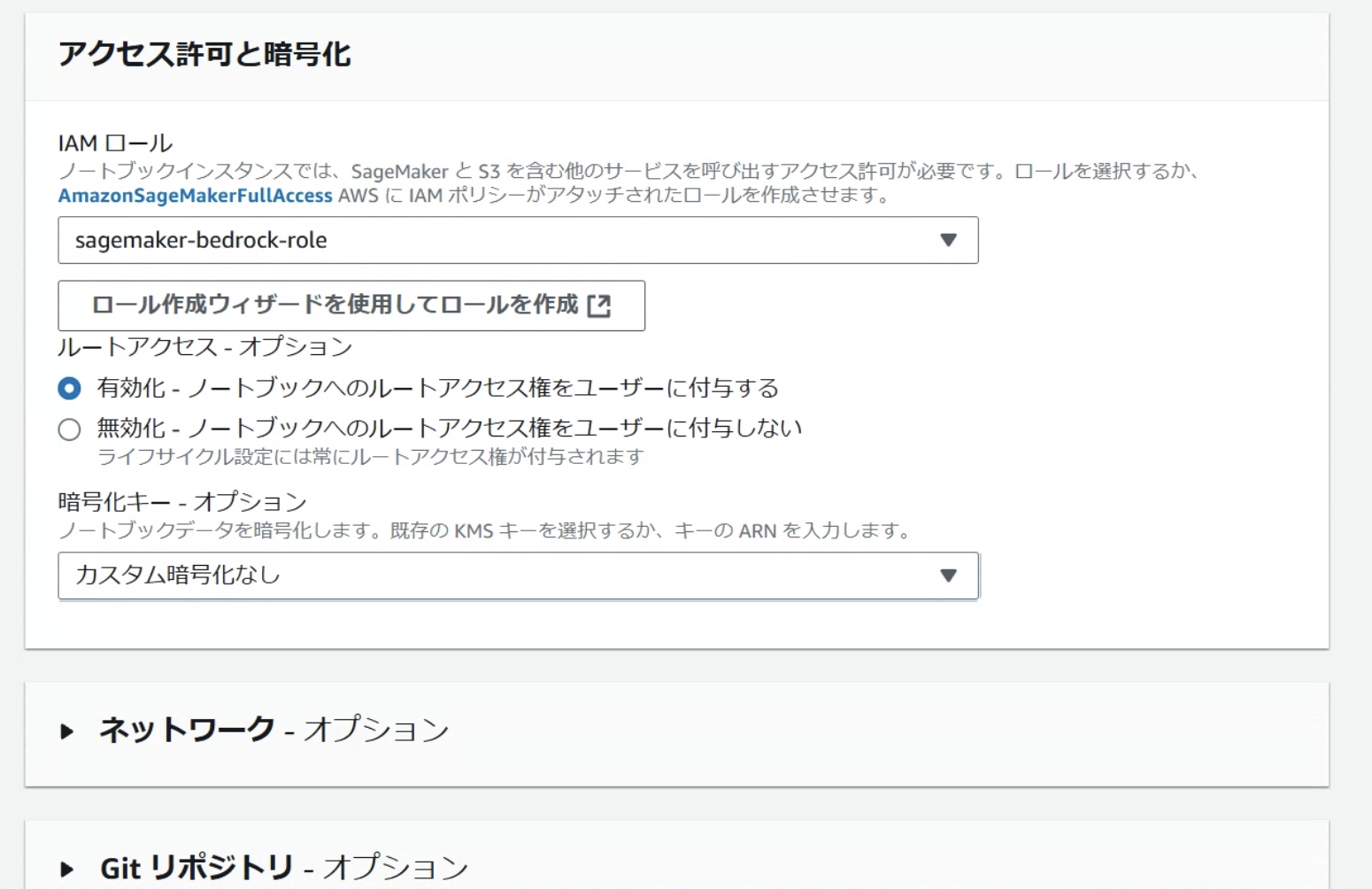
SageMakerでNotebookインスタンスを作成する前に、アタッチするIAMロールを作成しておきます。
IAMポリシーの準備
今回ロールにアタッチするのポリシーは以下の二つです。
- AmazonSageMakerFullAccess(検証用の為フルアクセスを選択)
- Bedrockのカスタムポリシー
Bedrockのポリシーはカスタムポリシーになるため先に作成しておきましょう。
Bedrockのモデルを呼び出しの許可と、使用できるLLMのリストを取得できるポリシーになります。
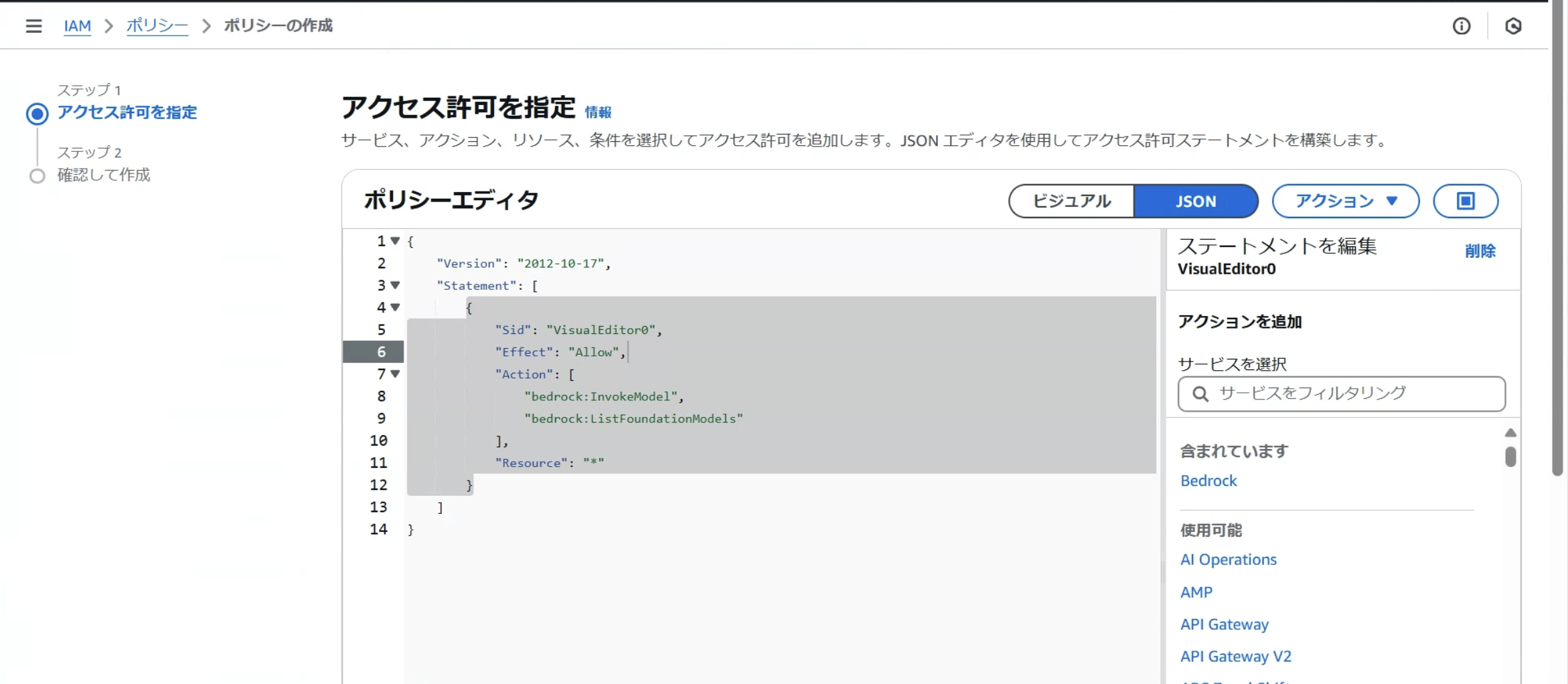
以下のコードをコピーして、IAMのポリシー作成画面からJSONを貼り付けます。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"bedrock:InvokeModel",
"bedrock:ListFoundationModels"
],
"Resource": "*"
}
]
}
IAMポリシーの作成画面をビジュアル→JSONに切り替えて、上記のコードをコピペし次へ進みます。
今回は「bedrock-policy」という名前でポリシーを作成しましょう。
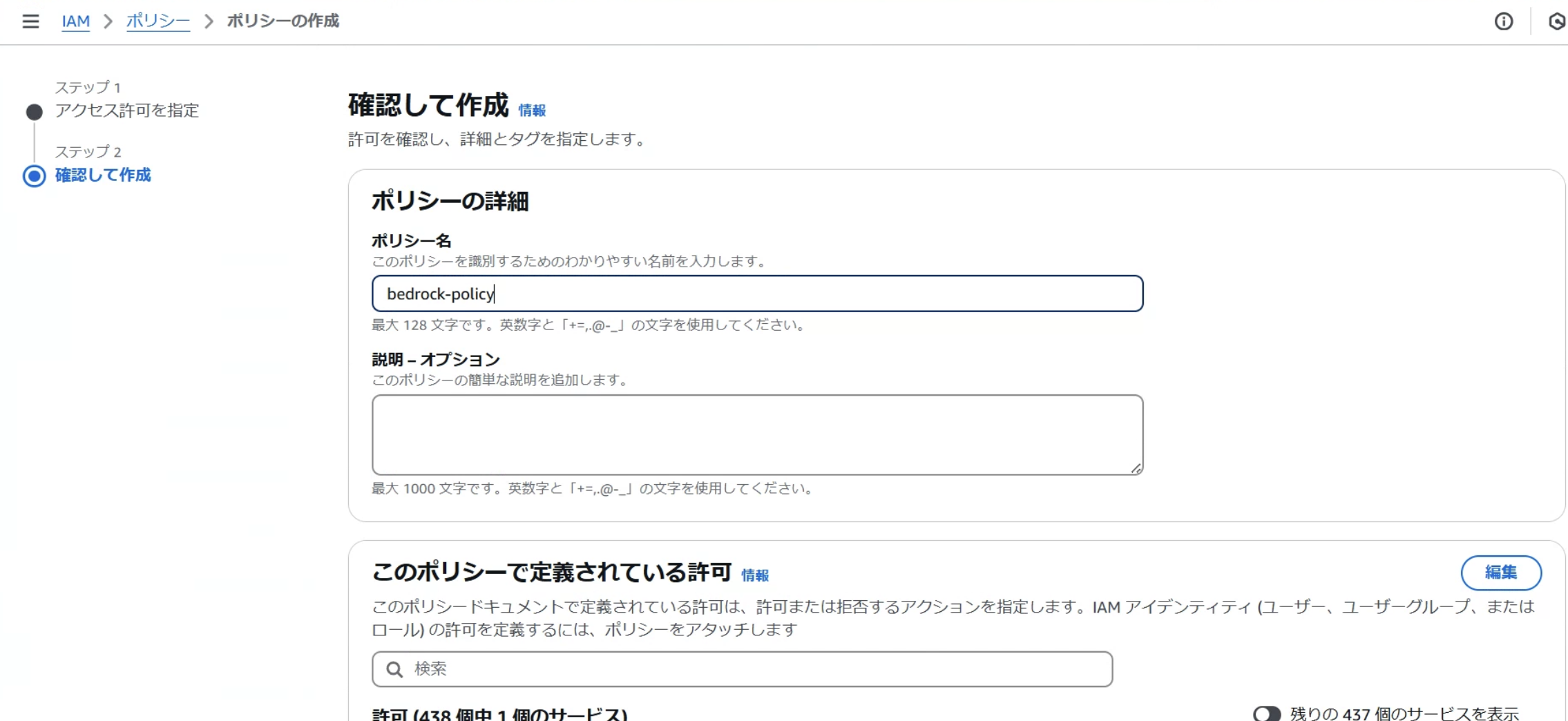
これで本記事で使用するBedrock用のIAMポリシーの作成は完了です。
続いてIAMロールの作成を行なっていきます。
IAMロールの準備
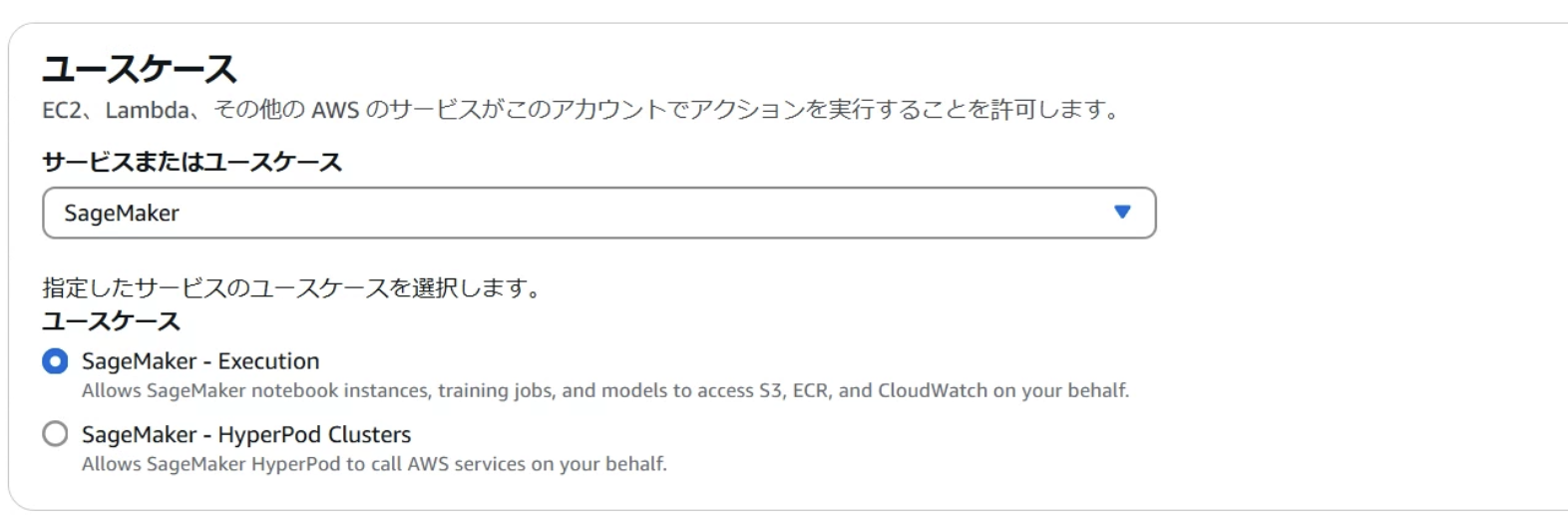
IAMロールの画面から新しいロールの作成をクリックし、ユースケースはSageMakerを選びます。
IAMロール名は「sagemaker-bedrock-role」とします。
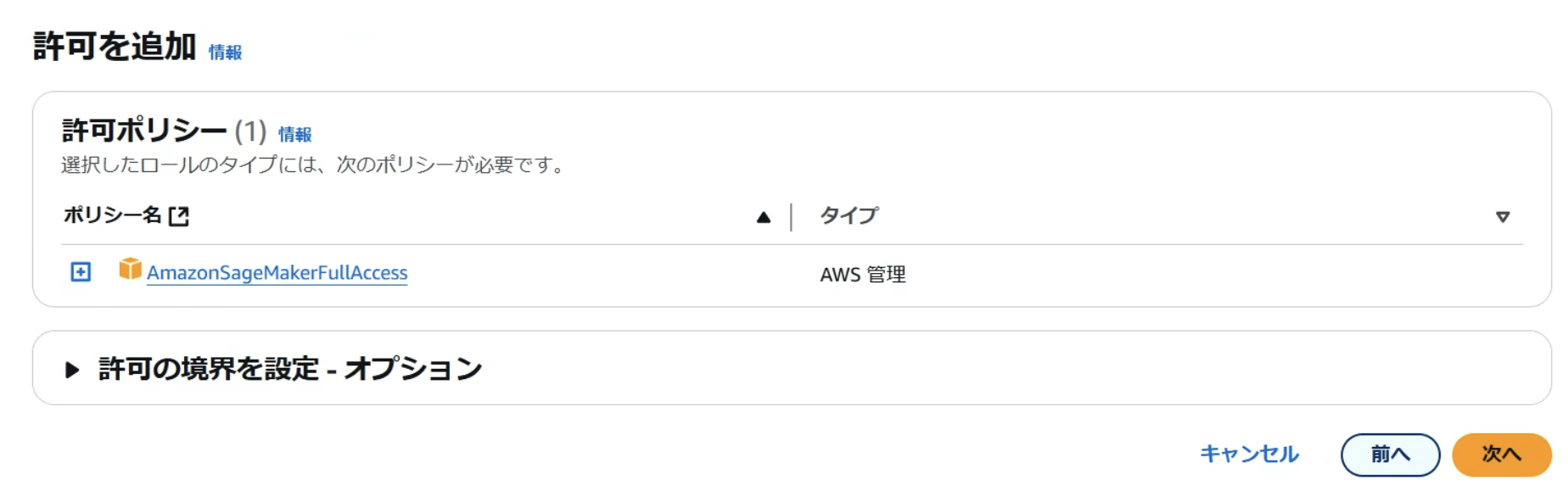
まずはAmazonSageMakerFullAccessのみをアタッチして作成します。
IAMロール一覧から「sagemaker-bedrock-role」を選択し、
許可タブから許可を追加→ポリシーをアタッチをクリックします。
事前に作成しておいた「bedrock-policy」を選択し、許可を追加します。
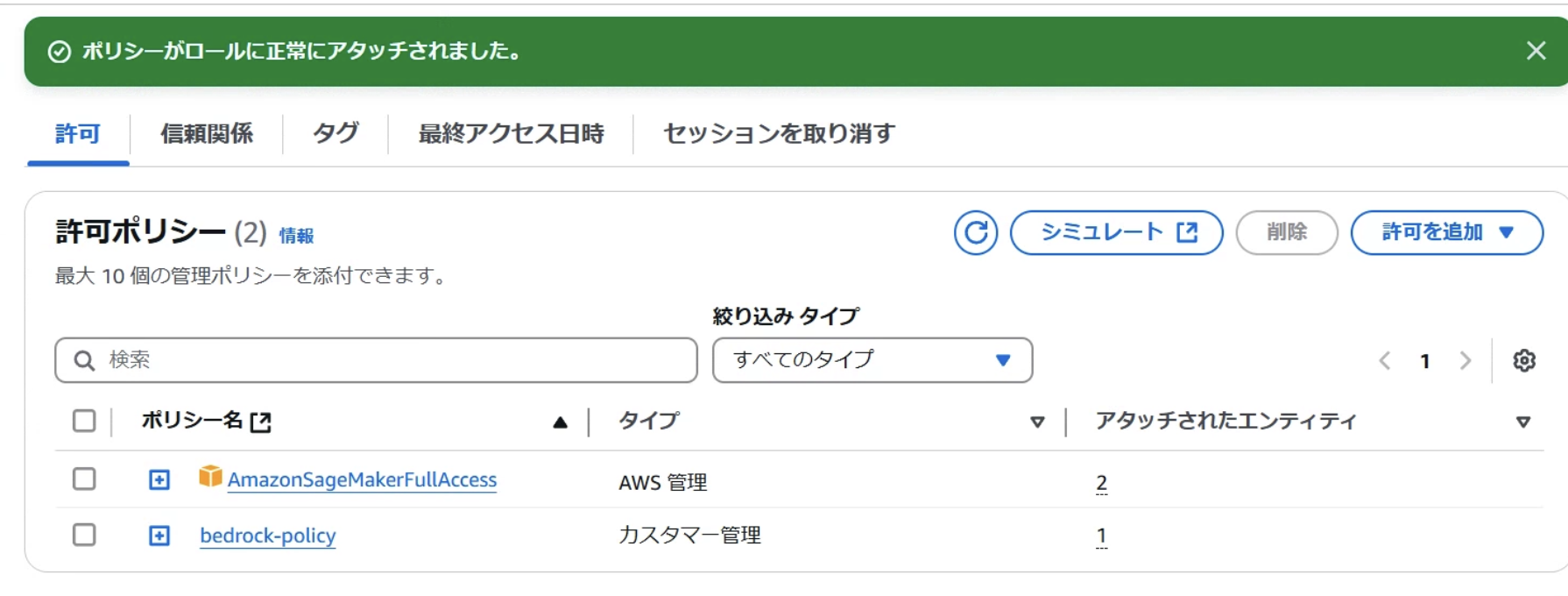
二つのポリシーがアタッチされたことを確認できたらIAMの準備は完了です。
Notebookインスタンスの設定
SageMakerのページからNotebooksをクリックしノートブックインスタンスの作成を行います。
インスタンスの設定について、今回は画像のように設定します。
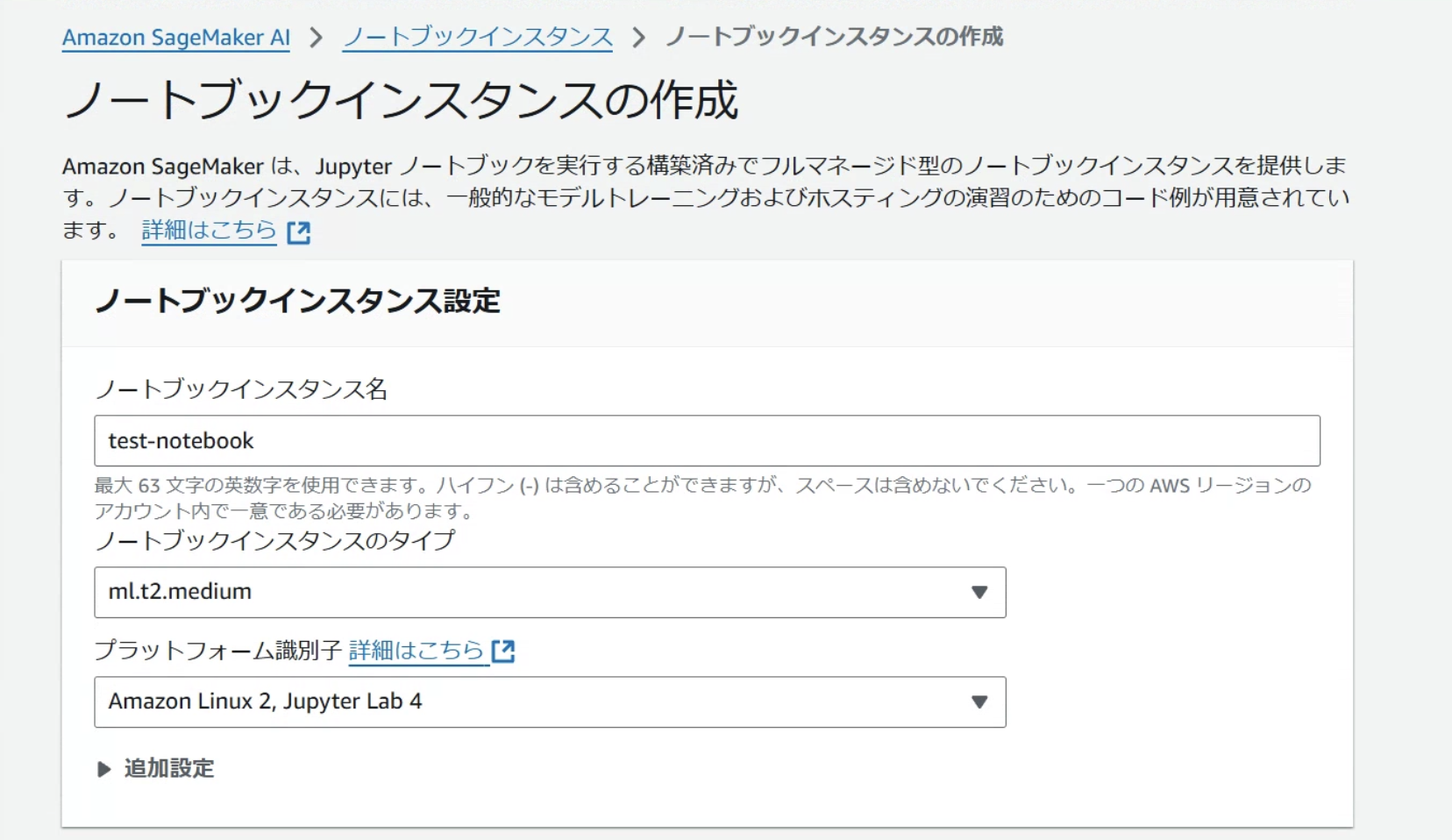
IAMロールは先ほど作成したロールを選択します。
他の項目は今回変更せずに作成します。
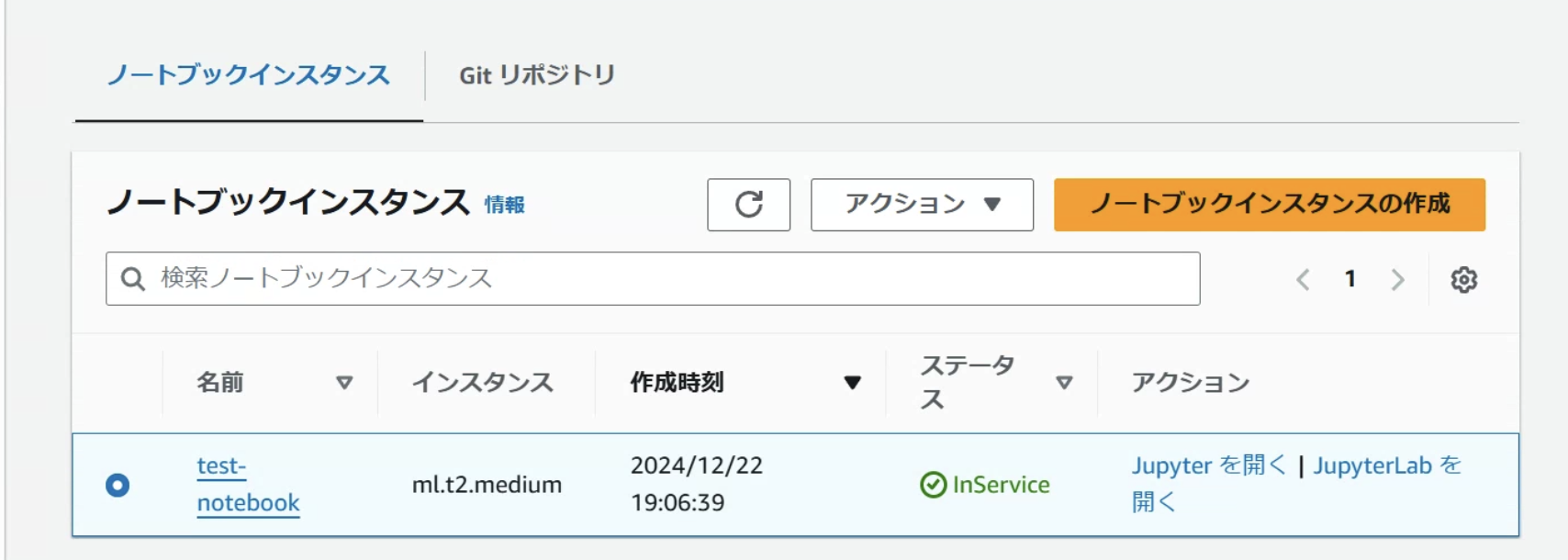
ステータスが緑になり、起動を確認したら、Jupyterを開きます。
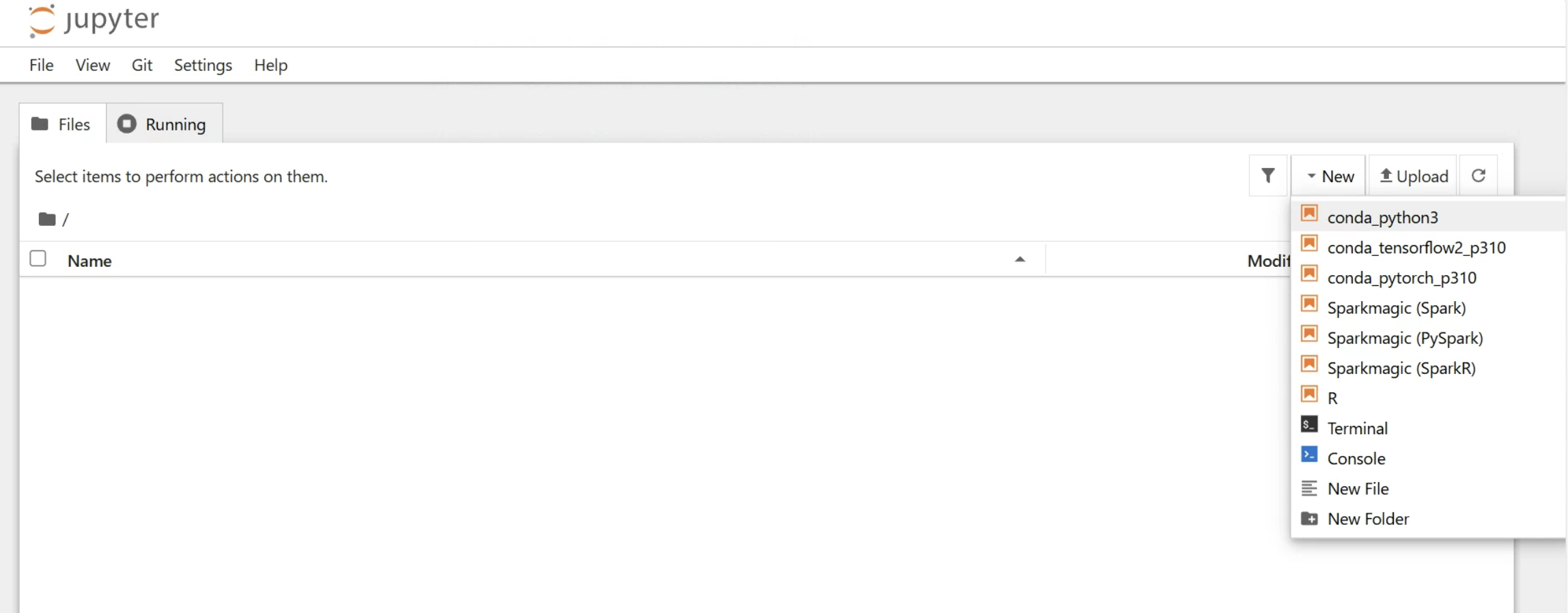
Jupyter操作
基本操作の説明を行います。
不要な場合はスキップしてください。
- ファイル作成
- ファイル名の編集
- セルの説明
- セルのマークダウン
ファイルの作成
Newから新しいファイルを作成できます。
今回はconda_python3を選択します。
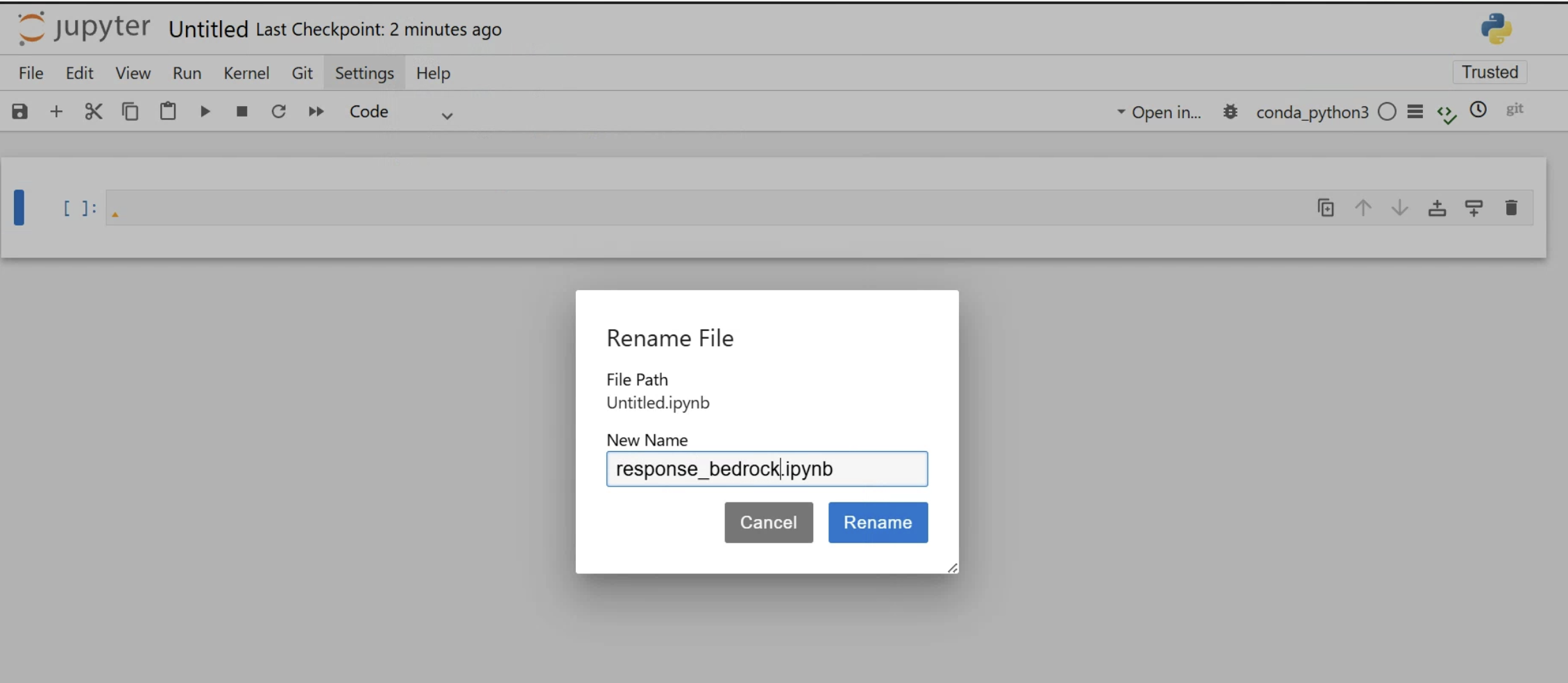
ファイル名の編集
Untitledをクリックすると編集できるので、変更してみましょう。
※名前の変更時、拡張子を削除しないように注意してください。
無いと表示がjson形式になってしまいます。
セルの説明
青く囲われている箇所が現在選択している「セル」と呼ばれるものです。
このセルにコードを記述していきます。
Shift + Enterで選択しているセルのコードを実行することが出来ます。
Jupyterの特徴の一つとして、コードの実行をセル単位で行うことができる点が挙げられます。

セルの端にあるアイコンは左から以下のような意味があります。
複製、セルを上に移動、セルを下に移動、上にセルを追加、下にセルを追加、削除
セルを折りたたむこともできます。
対象のセルを選択して、横の太い線をクリックすると折りたたむことができます。
長いコードや出力結果がある際に、使用しない時は折り畳んでおくことでノートブックのスクロールがしやすくなります。
折りたたむ前
折りたたんだ後

セルのマークダウン
また、Notebookにマークダウンをつけることもできます。
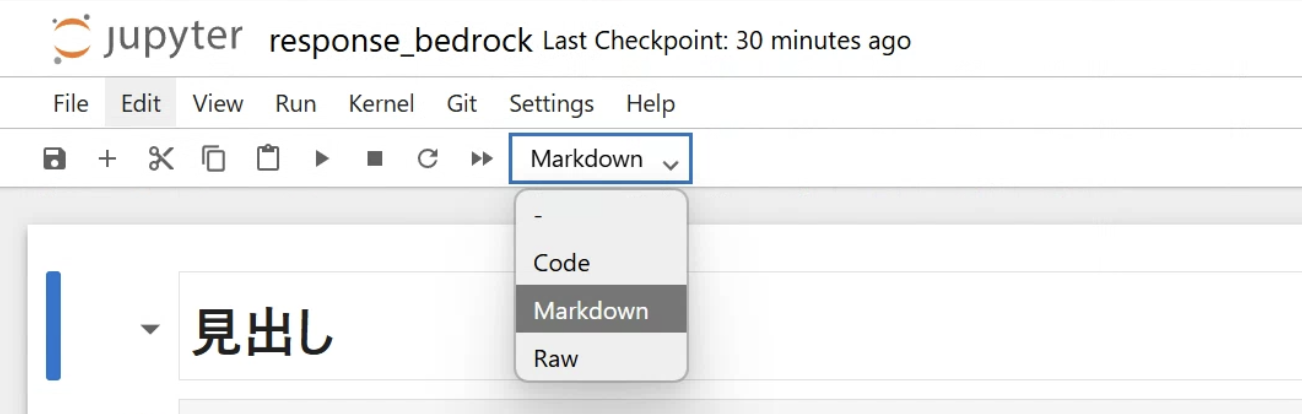
セルを選択して、codeからMarkdownを選択します。
画像は「# 見出し」と入力して、Shift + Enterを叩いた例になります。
実行
必要なライブラリなどのインストール・設定
画像のように各コードを実行していきます。
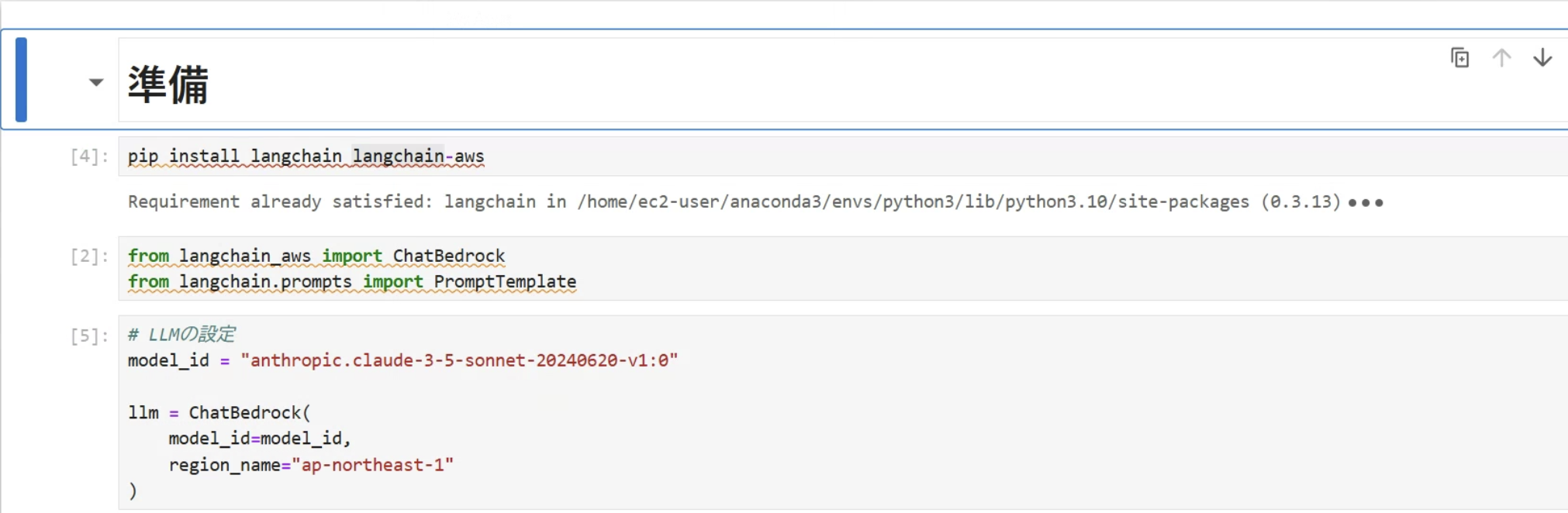
# ライブラリのインストール
pip install langchain langchain-aws
# クラスのインポート
from langchain_aws import ChatBedrock
from langchain.prompts import PromptTemplate
# LLMの設定
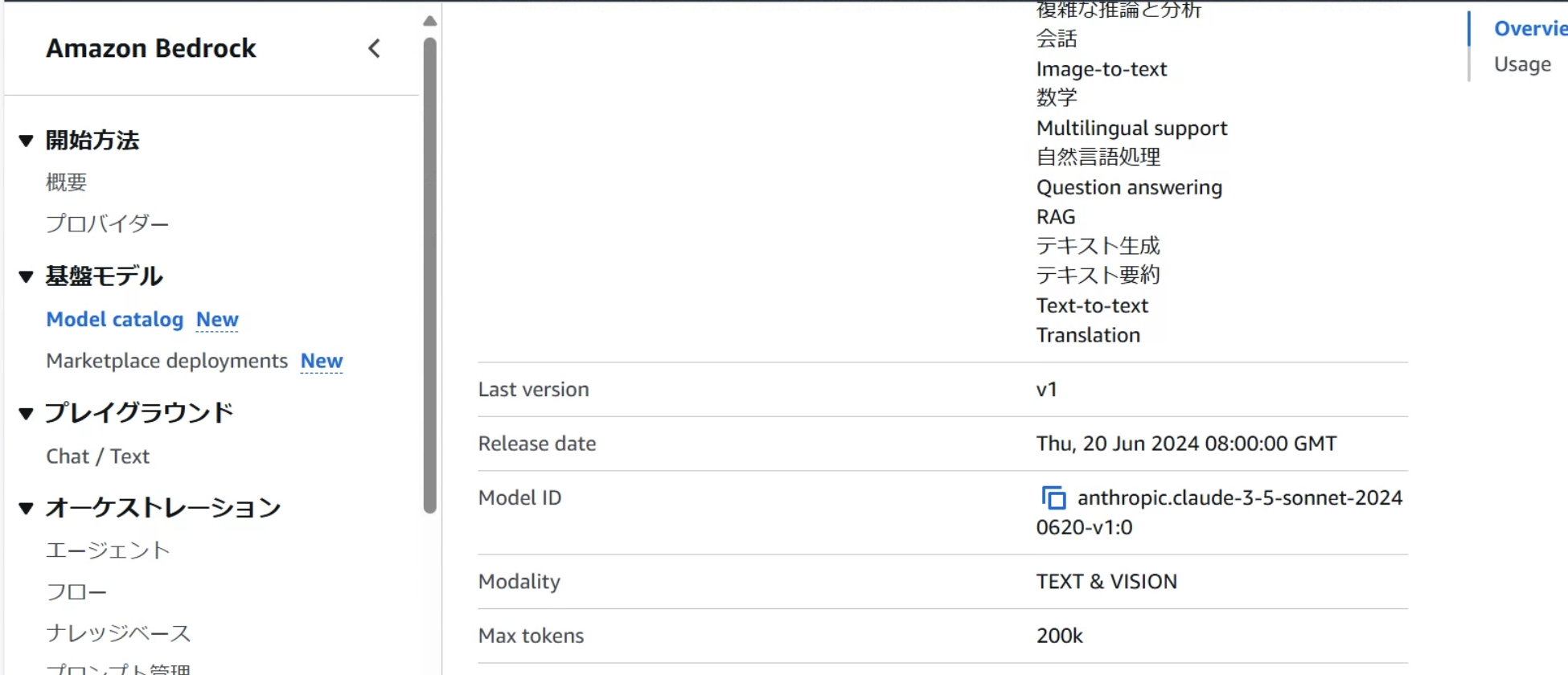
model_id = "anthropic.claude-3-5-sonnet-20240620-v1:0"
llm = ChatBedrock(
model_id=model_id,
region_name="ap-northeast-1"
)
region_nameの値は東京リージョンでの例です。使用するリージョンに応じて変更してください。
Model IDはBedrockのModel catalogから確認することができます。
使用したいモデルのページを参照してください。
システムプロンプトの設定
templateにシステムプロンプトを設定します。
ここで、回答のフォーマットを事前に指定したり、回答生成の際に使用する事前情報を設定ことができます。
今回は語尾が「ナレ」になるように設定してみます。
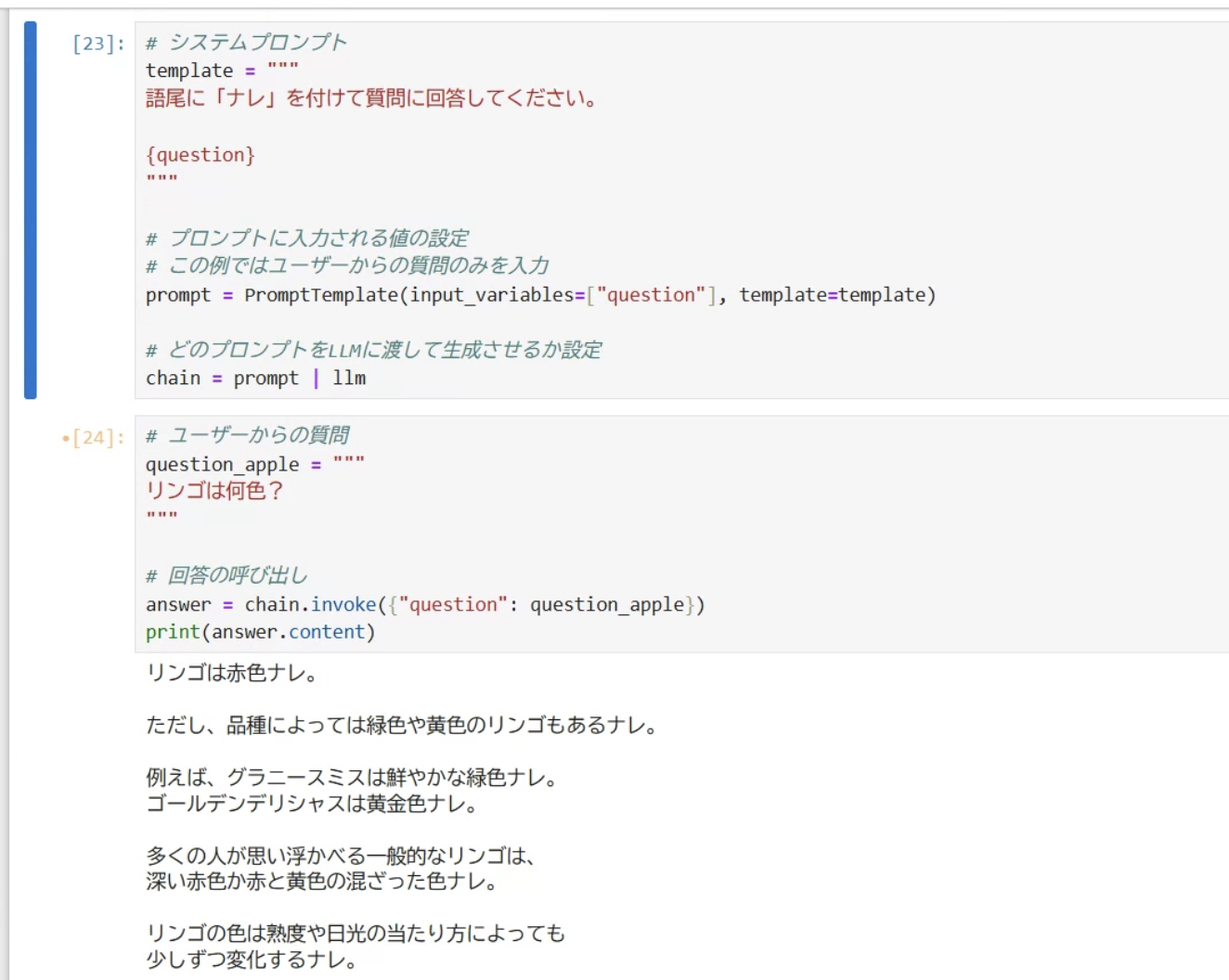
# システムプロンプト
template = """
語尾に「ナレ」を付けて質問に回答してください。
{question}
"""
# プロンプトに入力される値の設定
# この例ではユーザーからの質問のみを入力
prompt = PromptTemplate(input_variables=["question"], template=template)
# どのプロンプトをLLMに渡して生成させるか設定
chain = prompt | llm
ユーザープロンプトの設定
# ユーザーからの質問
question_apple = """
リンゴは何色?
"""
# 回答の呼び出し
answer = chain.invoke({"question": question_apple})
print(answer.content)
まとめ
この記事ではLangChainを使用してBedrockのClaude 3.5 Sonnetモデルの呼び出しを行いました。
システムプロンプトには、出力フォーマットの定義や情報の追加など、いろいろ設定することが出来ます。
LangChainを使用することで、語尾を「ナレ」にするプロンプト以外も個別に作成して管理しやすくなり効率的にLLMを実行することができます。
先月のre:Inventで発表されたAmazonの新しい基盤モデル「Nova」など、Bedrockでは様々なモデルを使用することができるのでぜひ試してみてください。