Motivation
Some time ago when I asked one of my colleagues, what whas his main motivation for becoming a programmer. He then replied in a sense that he wants his code be part of a software which can be useful for many years.
Since my colleague worked as a Web Developer at that time, I was pretty skeptical of this answer. In my previous experience, the front-end part of an average project tends to be rewritten every three months or so, so this is not a very good place to look for "stable" and "unchanging" code.
Later, however, I became more curious and decided to check, how long on average the line of code lives in our company's repository. The additional benefit was that I got myself a great excuse to play around with GitPython package during my work time!
If you have not heard this name before, GitPython provides a Python-interface to git. Since we will use it heavily below, the basic familiarity is assumed and welcomed. I will also use pandas below pretty much as well.
Finally, one last word before we embark on a journey. While working on this, I made myself an explicit goal to NOT to use anything except GitPython and pandas (remember, one of my goals was to learn the former). However, if you look for something more user-friendly, there are other packages built on top of GitPython, which provide much more rich and friendly interface. In particular, PyDriller popped out during my searches. But perhaps, plenty of others exist too.
Main work
Ok, so here we go. First, we initialize Repo object which will represent our repository. Make sure you have downloaded the repository and checked out the newest version. Replace PATH_TO_REPO below with path to your git repository on your disk.
from git import Repo
PATH_TO_REPO = "/Users/nailbiter/Documents/datawise/dtws-rdemo"
repo = Repo("/Users/nailbiter/Documents/datawise/dtws-rdemo")
assert not repo.bare
Next, we check out the branch we want to investigate (see the variable BRANCH below). In your case it probably will be master, but our main branch is called development for some reasons.
import pandas as pd
BRANCH = "development"
head = repo.commit(f"origin/{BRANCH}")
from IPython.display import HTML
def head_to_record(head):
return {"sha":head.hexsha[:7],
"parent(s)":[sha.hexsha[:7] for sha in head.parents],
"name":head.message.strip(),
"commit_obj":head
}
records = []
while head.parents:
# print(f"parent(s) of {head.hexsha} is/are {[h.hexsha for h in head.parents]}")
records.append(head_to_record(head))
head = head.parents[0]
records.append(head_to_record(head))
pd.DataFrame(records)
| sha | parent(s) | name | commit_obj | |
|---|---|---|---|---|
| 0 | 31ad850 | [c77bfb0] | docs | 31ad850b08014bbf299e534e28cdfee32be90654 |
| 1 | c77bfb0 | [d4935dc] | stash | c77bfb02b6aa0992be7d51ddc09c295a9b25d4d1 |
| 2 | d4935dc | [f294f04] | rename owner | d4935dc2157c6f968db8bae7d68868955c06f6ea |
| 3 | f294f04 | [c51257b] | stash | f294f049161ac9c8c2215f33b8d0bc25f49f88b3 |
| 4 | c51257b | [b684146] | stash | c51257b1b89ea10bd213ed5ba575033fd0514e89 |
| ... | ... | ... | ... | ... |
| 298 | e636c9f | [0f9ad8d] | [Task] Ran Prettier | e636c9ff7f9125064c2f3d367680107baebae250 |
| 299 | 0f9ad8d | [ec1c72f] | [Task] Setup Prettier | 0f9ad8d85d18010098228cabae36e674b4402686 |
| 300 | ec1c72f | [e4da3e5] | [Feat.] Can Set Initial State | ec1c72fe382a5b9dfa42a8810a740f96eb72c05c |
| 301 | e4da3e5 | [b17eb26] | Initial DTWS commit | e4da3e5ae67322feae1b93e2180b219054339182 |
| 302 | b17eb26 | [] | Initial commit from Create React App | b17eb263f8cf0adc7eb8cda7e0a0ae4aee8aff82 |
303 rows × 4 columns
Now, variables records in the code above represents all the commits on development branch since the beginning till the current moment.
Next we need to go along these commits and collect info regarding every line which appeared/disappeared in that commit. This information later will help us to determine lifetime of each line which ever appeared in our repository.
To do so, we create the variable res which is a dictionary. It's keys are tuples of the form (<line_content>,<commit>,<filename>) and its values are sets containing hashes of all the commits in which this line appeared. It is a rather big structure and computing it takes some time.
Therefore, be ready that the code below will take some time to finish (around 100 seconds on my reasonably new MacBook Pro with our repository having only ~300 commits).
I guess, there should be much more effective and elegant way to collect this data, but I have not came up with it yet. Suggestions are welcomed.
import pandas as pd
from tqdm import tqdm
def collect_filestates(end,start=None):
"""this procedure collects names of all files which changed from commit `start`
till commit `end` (these assumed to be adjacent)"""
if start is not None:
diffs = start.diff(other=end)
fns = [diff.b_path for diff in diffs]
change_types = [diff.change_type for diff in diffs]
res = [{"filename":t[0],"status":t[1]} for t in zip(fns,change_types)]
return res
else:
fns = end.stats.files.keys()
return [{"filename":f,"status":"C"} for f in fns]
def collect_lines(end,start=None):
"""collects information about all lines that changed from `start` to `end`"""
filestates = [r for r in collect_filestates(end,start) if r["status"] != "D"]
res = {}
for fs in filestates:
fn = fs["filename"]
blame = repo.blame(end,file=fn)
for k,v in blame:
for vv in v:
res[(vv,k.hexsha,fn)] = end.hexsha
return res
res = {}
for i in tqdm(range(len(records))):
_res = collect_lines(end=records[i]["commit_obj"],start=None if (i+1)==len(records) else records[i+1]["commit_obj"])
for k,v in _res.items():
if k in res:
res[k].add(v)
else:
res[k] = {v}
{k:v for k,v in list(res.items())[:5]}
100%|██████████| 303/303 [01:41<00:00, 2.99it/s]
{('*.swo',
'a73ec421cfc05cc3816cb3b2b2505d228e60c386',
'pipeline/.gitignore'): {'31ad850b08014bbf299e534e28cdfee32be90654',
'a73ec421cfc05cc3816cb3b2b2505d228e60c386'},
('*.swp',
'a73ec421cfc05cc3816cb3b2b2505d228e60c386',
'pipeline/.gitignore'): {'31ad850b08014bbf299e534e28cdfee32be90654',
'a73ec421cfc05cc3816cb3b2b2505d228e60c386'},
('.pulled_data.json',
'a73ec421cfc05cc3816cb3b2b2505d228e60c386',
'pipeline/.gitignore'): {'31ad850b08014bbf299e534e28cdfee32be90654',
'a73ec421cfc05cc3816cb3b2b2505d228e60c386'},
('.config.custom.json',
'a73ec421cfc05cc3816cb3b2b2505d228e60c386',
'pipeline/.gitignore'): {'31ad850b08014bbf299e534e28cdfee32be90654',
'a73ec421cfc05cc3816cb3b2b2505d228e60c386'},
('.stderr.txt',
'a73ec421cfc05cc3816cb3b2b2505d228e60c386',
'pipeline/.gitignore'): {'31ad850b08014bbf299e534e28cdfee32be90654',
'a73ec421cfc05cc3816cb3b2b2505d228e60c386'}}
Now, as we have our marvelous res structure, we can easily compute the lifetime of every line which ever appeared in our repository: for every key in res we simply compute the duration between oldest and newest commit in its value set.
But again, this may take some time (around 6 minutes on my machine).
from datetime import datetime
import pandas as pd
from tqdm import tqdm
_records = []
for k in tqdm(res):
dates = [datetime.fromtimestamp(repo.commit(sha).committed_date) for sha in res[k]]
_records.append(dict(line=k[0],commit=k[1],file=k[2],lifetime=max(dates)-min(dates)))
lines_df = pd.DataFrame(_records)
lines_df
100%|██████████| 1806272/1806272 [05:52<00:00, 5123.11it/s]
| line | commit | file | lifetime | |
|---|---|---|---|---|
| 0 | *.swo | a73ec421cfc05cc3816cb3b2b2505d228e60c386 | pipeline/.gitignore | 144 days 19:07:29 |
| 1 | *.swp | a73ec421cfc05cc3816cb3b2b2505d228e60c386 | pipeline/.gitignore | 144 days 19:07:29 |
| 2 | .pulled_data.json | a73ec421cfc05cc3816cb3b2b2505d228e60c386 | pipeline/.gitignore | 144 days 19:07:29 |
| 3 | .config.custom.json | a73ec421cfc05cc3816cb3b2b2505d228e60c386 | pipeline/.gitignore | 144 days 19:07:29 |
| 4 | .stderr.txt | a73ec421cfc05cc3816cb3b2b2505d228e60c386 | pipeline/.gitignore | 144 days 19:07:29 |
| ... | ... | ... | ... | ... |
| 1806267 | supports-color@^5.3.0: | b17eb263f8cf0adc7eb8cda7e0a0ae4aee8aff82 | yarn.lock | 0 days 00:00:00 |
| 1806268 | through@^2.3.6: | b17eb263f8cf0adc7eb8cda7e0a0ae4aee8aff82 | yarn.lock | 0 days 00:00:00 |
| 1806269 | typedarray@^0.0.6: | b17eb263f8cf0adc7eb8cda7e0a0ae4aee8aff82 | yarn.lock | 0 days 00:00:00 |
| 1806270 | whatwg-fetch@3.0.0: | b17eb263f8cf0adc7eb8cda7e0a0ae4aee8aff82 | yarn.lock | 0 days 00:00:00 |
| 1806271 | xtend@^4.0.0, xtend@~4.0.1: | b17eb263f8cf0adc7eb8cda7e0a0ae4aee8aff82 | yarn.lock | 0 days 00:00:00 |
1806272 rows × 4 columns
The table lines_df we assembled above contains the following columns:
-
line-- that's line's content -
commit-- that's the first commit in which this line appeared. -
file-- filename in which this line appears -
lifetime-- lifetime of a line
In the code below we add two more columns to this table:
-
author-- author of the line (to protect their privacy, I do not list real names, but rather one-letter nicknames) -
ext-- file extension offilename
from os.path import splitext, isfile
import json
if not isfile("author_masks.json"):
to_author = lambda s:s
else:
with open("author_masks.json") as f:
d = json.load(f)
to_author = lambda s:d[s]
lines_df.sort_values(by="lifetime",ascending=False)
lines_df["author"] = [to_author(str(repo.commit(sha).author)) for sha in lines_df["commit"]]
lines_df["ext"] = [splitext(fn)[1] for fn in lines_df["file"]]
lines_df
| line | commit | file | lifetime | author | ext | |
|---|---|---|---|---|---|---|
| 0 | *.swo | a73ec421cfc05cc3816cb3b2b2505d228e60c386 | pipeline/.gitignore | 144 days 19:07:29 | L | |
| 1 | *.swp | a73ec421cfc05cc3816cb3b2b2505d228e60c386 | pipeline/.gitignore | 144 days 19:07:29 | L | |
| 2 | .pulled_data.json | a73ec421cfc05cc3816cb3b2b2505d228e60c386 | pipeline/.gitignore | 144 days 19:07:29 | L | |
| 3 | .config.custom.json | a73ec421cfc05cc3816cb3b2b2505d228e60c386 | pipeline/.gitignore | 144 days 19:07:29 | L | |
| 4 | .stderr.txt | a73ec421cfc05cc3816cb3b2b2505d228e60c386 | pipeline/.gitignore | 144 days 19:07:29 | L | |
| ... | ... | ... | ... | ... | ... | ... |
| 1806267 | supports-color@^5.3.0: | b17eb263f8cf0adc7eb8cda7e0a0ae4aee8aff82 | yarn.lock | 0 days 00:00:00 | J | .lock |
| 1806268 | through@^2.3.6: | b17eb263f8cf0adc7eb8cda7e0a0ae4aee8aff82 | yarn.lock | 0 days 00:00:00 | J | .lock |
| 1806269 | typedarray@^0.0.6: | b17eb263f8cf0adc7eb8cda7e0a0ae4aee8aff82 | yarn.lock | 0 days 00:00:00 | J | .lock |
| 1806270 | whatwg-fetch@3.0.0: | b17eb263f8cf0adc7eb8cda7e0a0ae4aee8aff82 | yarn.lock | 0 days 00:00:00 | J | .lock |
| 1806271 | xtend@^4.0.0, xtend@~4.0.1: | b17eb263f8cf0adc7eb8cda7e0a0ae4aee8aff82 | yarn.lock | 0 days 00:00:00 | J | .lock |
1806272 rows × 6 columns
Analysis
Finally, having this info, we can then group, and average lifetime on various parameters.
For example, below, we see the average lifetime of every line conditional on file extension:
from datetime import timedelta
from functools import reduce
def averager(key, df=lines_df):
ltk = "lifetime (days)"
return pd.DataFrame([
{key:ext,
ltk:(reduce(lambda t1,t2:t1+t2.to_pytimedelta(),slc["lifetime"],timedelta())/len(slc)).days
}
for ext,slc
in df.groupby(key)
]).set_index(key).sort_values(by=ltk,ascending=False)
averager("ext").plot.barh(figsize=(16,10),logx=True)
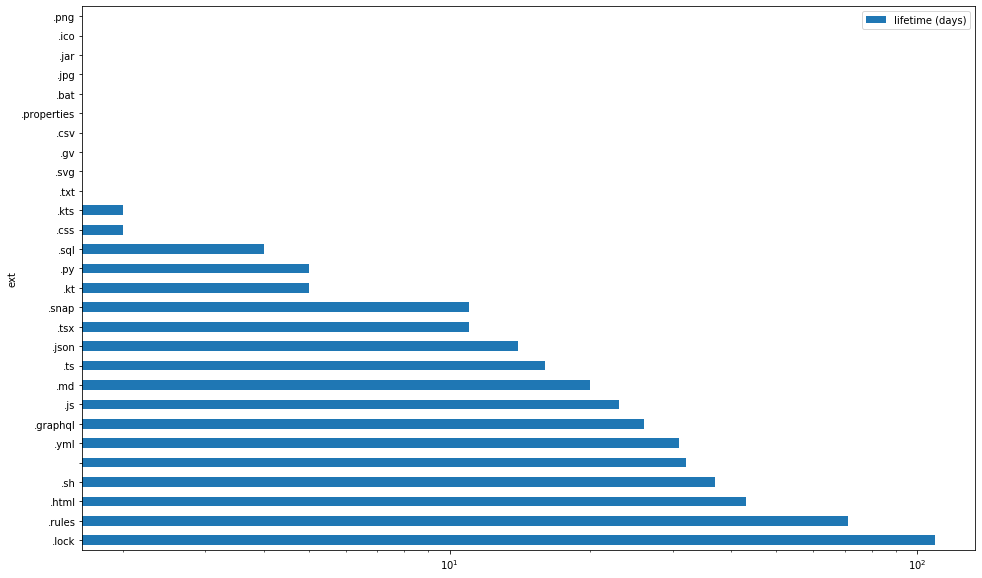
You can see that ironically, the lines that stay unchanged the longest, belong to "insignificant" files like .lock (that's various yarn.lock's), .rules (that's Firabase rules), .html (that's index.html and since our project uses React, the main index.html also receives almost no changes) and others. In particular, files with empty extension refer to .gitignore's.
And finally, we can see the average lifetime of a line of code, conditional on author.
averager("author").plot.barh(figsize=(16,10))

We can see that the colleague I mentioned in the beginning (he goes by the nickname "J" here) indeed authored the longest-surviving lines in the whole repository. Good for him.
However, let's look more closely at the secret of his success:
_df = lines_df[[ext=="J" for ext in lines_df["author"]]].loc[:,["line","file","lifetime","ext"]]
_df = averager(df=_df,key="ext")
_df[[x>0 for x in _df["lifetime (days)"]]]
| lifetime (days) | |
|---|---|
| ext | |
| .html | 181 |
| .lock | 165 |
| 154 | |
| .rules | 91 |
| .yml | 54 |
| .md | 39 |
| .ts | 38 |
| .js | 26 |
| .json | 18 |
| .snap | 11 |
| .css | 5 |
| .tsx | 4 |
Being the founder of the repository under consideration, he in particular mostly authored the aforementioned index.html, yarn.lock and *.rules files. As I explained before, these received almost no changes during the subsequent development.
Further work
Since we store the info on filenames as well, we can compute the averages conditional on folders, thus seeing, which parts of project are more "stable" than the others.