仕事でサイト横断検索機能を開発することがあったので、その構成や出来上がるまでの過程について触れていきます。
前提条件
- 自社ECサイトを複数出店している
- 各ECサイトはDBと連動した動的なものではなく、商品情報ベタ書きの静的サイト
社内からの要望
1つのサイトから別サイトの商品への誘導もスムーズに行いたいので、自社ECサイトの商品の横断的に検索できる機能が欲しい
技術選択
- CloudSearch
- 検索DBが必要
- サイト内検索機能などで調べているとCloudSearch/ElasticSearchが良さそう
- 今回はCloudSearchの機能で十分かつ使いやすかったのでこちらを採択
- Scrapy
- CloudSearchにインプットする辞書データが必要
- 静的サイトなのでWebスクレイピングで収集したものを加工すれば辞書データができそう
- WebスクレイピングにはPythonフレームワークのScrapyが便利そう
- AWS Batch
- 自動で商品情報を最新化していきたいので、日次でスクレイピングとCloudSearchへのデータ登録をしたい
- 専用サーバーにプログラムを常駐させるのは実行頻度的にコストに無駄が多い
- 一時的に実行環境リソースを作成し、その後削除してくれる/cronの指定方法でバッチ実行のできるAWS Batchを使うことにした
最終的な全体構成はこんな感じになりました。
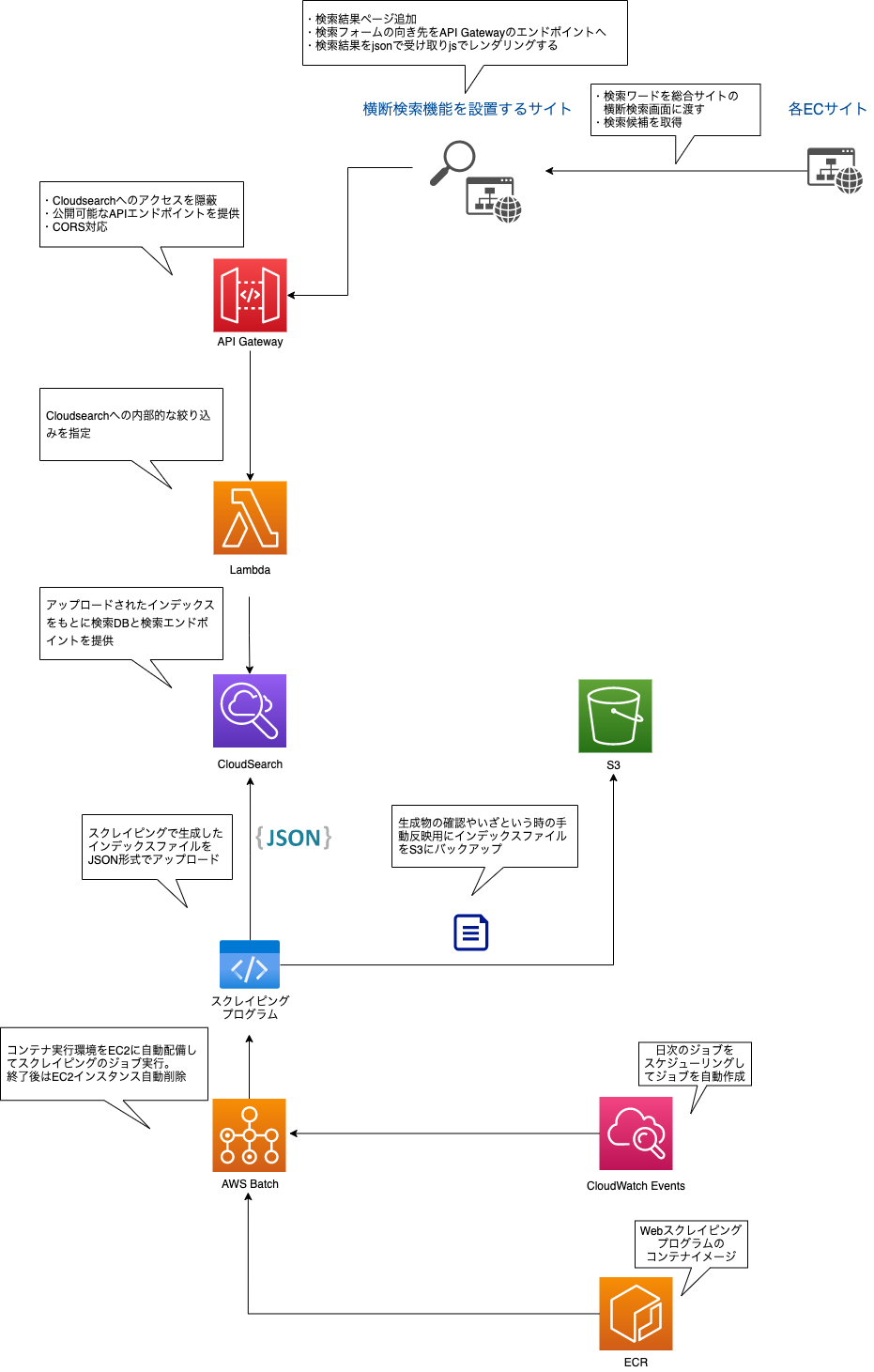
開発期間は大体1ヶ月程度でした。
それぞれの箇所について下記で触れていきます。
Webスクレイピング(Scrapy)
Scrapyは簡単に言うと、Webサイトを巡回するプログラム(Spider)を簡単に作成できるPythonフレームワークです。私はPython初心者でしたが、フレームワークがしっかりしているので割とスムーズに作成できました。Scrapyに関してはこちらの記事などを参考にさせて頂きました。
Webスクレイピングの特性上、対象ページ(html)のid/class属性の構造に依存するため、各サイトの構造に合わせてSpiderを作成することが実は一番時間がかかったと思います。
このプログラムでは以下のことをしています。
- 各サイトごとのSpiderを作成してWebスクレイピング
- スクレイピングの結果を加工して、CloudSearchに登録するための辞書データ(jsonファイル)を生成
- 生成したjsonデータをCloudSearchにアップロード
- S3にjsonをバックアップとして保存(いざと言うときに手動でCloudSearchに辞書データを登録するため)
3~4個目の機能はAWSのサービスへの操作なので、Python用のAWS SDKであるboto3をインポートして開発しています。
CloudSearchのドキュメントバッチの形式を参考に、アップロードするjsonを生成しています。CloudSearchについては後述します。
[
{"type": "add",
"id": "商品ページのURL(一意であれば何でも良いのでURLにしています)",
"fields":{
"url": "商品ページのURL",
"img_path": "商品ページのメイン画像のURL(検索結果での画像表示用)",
"title": "商品ページhtml内のtitleタグ(検索用)",
"description": "商品ページhtml内のdescriptionタグ(検索用)"
}
},
︙
]
ECR
Scrapyで作ったコードを登録しておきます。弊社ではGitlabを使っているので、pushした時にGitlab Runnerで自動ビルド→ECRにイメージ登録するようにしています。
AWS Batch
バッチの設定を行なっています。
ECRに登録したコンテナイメージを元に実行環境を自動作成し、実行後は自動でリソースを消すのでコスト効率が良いです。
CloudWatch Events
バッチの日次実行のスケジューリングを行なっています。
cron形式で指定できます。負荷の影響を抑えるため、自社ECサイトへのアクセスの少ない時間帯に実行するようにしています。
CloudSearch
AWS Batchで配備された環境から実行されたScrapyプログラムから生成したjsonの辞書データをアップロードして各項目(titleやdescriptionなど)の検索設定を行うと、検索DBを生成してくれます。提供されるエンドポイントに対しクエリパラメータで絞り込み条件などを付加できます。詳しくはこちら。
S3
スクレイピングプログラムで生成したjsonデータをバックアップとして置いておきます。
検索データに異状が起きたときに手動でリストア(CloudSearchにデータ登録)する場合などに使います。
API Gateway
検索機能を設置するWebサイトからCloudSearchのエンドポイントを直接叩くことも可能と言えば可能ですが、それだと何のサービスを使っているか丸見えなのでAPI Gatewayで隠蔽します。また、社内の事情で一部のサイトを一時的に除外してほしいなどの調整もあり得るので、Lambdaと連携させてそちらにサイトの絞り込みなどを担当させています。
Lambda
API Gatewayからhttpリクエストをルーティングして実行されます。
CloudSearchはクエリパラメータに絞り込み条件を付加できるので、ユーザーに意識させたくない内部的な絞り込みをLambda関数にさせています。