本記事はSLP KBIT AdventCalendar 2022の10日目の記事になります。
記事概要
にゃんぱすー。一年前(筆者がB1のとき)のSLPサークルの活動の一部にて、人間の男女の二値分類モデルの作成に取り組んでいたのですが、当時の私は「写経」→「動いた!楽しい!」(←かわいい)というレベルで、やってることのおよそ半分も理解できていませんでした。なので今回の記事では再度勉強がてら、以前作成したモデルがうまくいかなかった原因を探って自身の成長を体感するという回です。なお、コードを載せていると冗長になるので説明したいところだけを抜粋します、ご了承ください。
旧コードの現状結果確認
まず過去に作成したコードを実行したところ以下のような結果を得られました。lossは損失関数の値、accuracyは正答率でvalはテストデータの結果を表しています。
| loss | accuracy | val_loss | val_accuracy |
|---|---|---|---|
| 0.6929 | 0.5274 | 0.6936 | 0.4859 |
accuracyが約0.5と非常に意味のないモデルになっています。モデルの構成は以下の通りです。
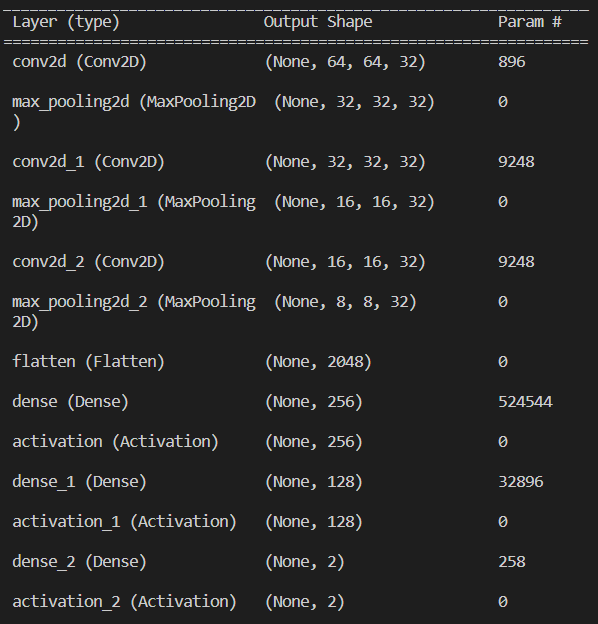
これを踏まえた上で精度の低さの原因を探る作戦を立てます。
以降では一年前に作成したコードと画像データを旧コード、旧データ、新規に作成するコードと画像データを新コード、新データと呼称します。
また、旧コード/旧データの結果を0番、次章で述べる作戦の「1. 2. ...」にあたる数字をそれぞれの結果の番号(n番)とします。
作戦
基本方針は対照比較の手法で検証していくのですが、過学習状態などの例外的な結果が得られる可能性が考えられるので、結果が微妙な場合は一般的に良いとされている方を優先的に採択していきます。(本来ならデータセットを使ってモデルの検証までしたかったけれど時間的制約の関係で今回はパス)
具体的な手順は以下です。
- 旧画像データをきれいにして0番と比較 → データの不備の有無
- 新たに画像データを用意して1番と比較 → データの不備の改善
- 新規コードを作成し新データで実行したものを2番と比較 → コードの優劣
検証
8割超えたら満点です。
1番
まず旧データから以下のような顔画像以外が切り取られたノイズ画像が多数散見されたためそれらを除去しました。

データ数は訓練データが282→280、テストデータが177→88になりました。データ数が少ないので意味はないと思いますが、検証なので一応実行したところ以下ような結果が得られました。
| loss | accuracy | val_loss | val_accuracy |
|---|---|---|---|
| 0.6963 | 0.4737 | 0.6946 | 0.4598 |
1番と比較するとaccuracyは下がっていますがこれはそもそものデータ数の不足によるものだと考えられるので、とりあえず2番を実行したいと思います。
2番
学習に用いるデータ数は多ければ多いほどいいというわけでもないと思いますが、あまりにも少なかったので訓練データを3256(1628x2)、テストデータを510(255x2)に増やしました。なお訓練データは傾斜やモザイク処理などにより500枚ほど水増ししています。
このデータを使用した旧コードの結果は以下です。
| loss | accuracy | val_loss | val_accuracy |
|---|---|---|---|
| 0.6892 | 0.5261 | 0.7858 | 0.3153 |
これもまたよくわからない結果になりました。別の条件で試してみるために3番にて新コードで実行します。
3番
モデルを構成するコードを変えて新データで実行します。新モデルの構成は以下の通りです。
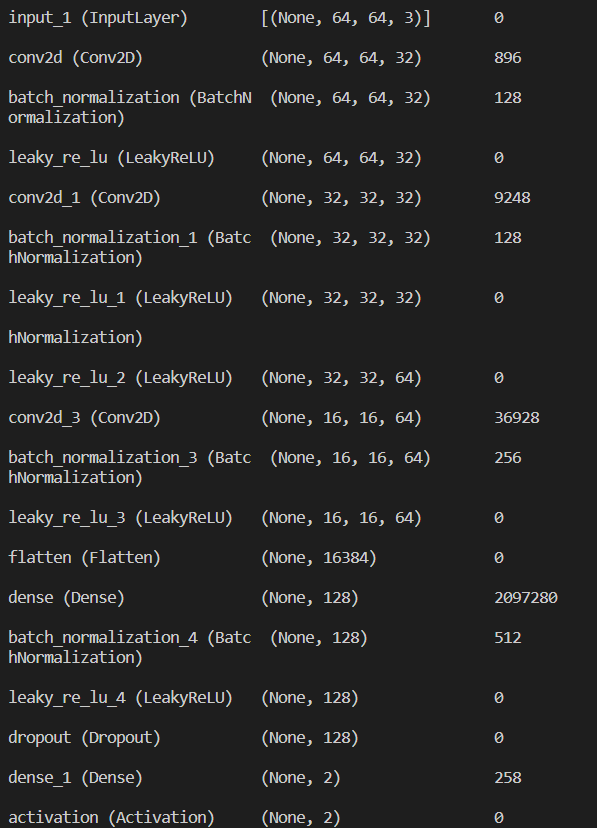
圧倒的にパラメータを増やし、dropout層などを用いることでよりパラメータが適切になるようにしました。これを利用した結果は以下の通りです。
| loss | accuracy | val_loss | val_accuracy |
|---|---|---|---|
| 0.2921 | 0.8753 | 0.5512 | 0.7843 |
一気によくなりました。定かではありませんが、学習に必要なパラメータ数が足りていなかったということが推測されます。(今回はやりませんがちゃんとしたデータセットを使用して比較してみたい)
また余談ですが旧データを新コードで実行すると以下のようになりました。
| loss | accuracy | val_loss | val_accuracy |
|---|---|---|---|
| 0.0345 | 0.9966 | 0.9815 | 0.6102 |
過学習状態になっていますね。逆に言えばきちんと過学習状態になっているということなので、旧モデルよりも正常に動作していると考えられます。
終わりに
目標としていた8割を超えることはできませんでしたが一年前よりは向上したのでよしとします。また欲を言えば、モデルを構成する手法を変えたり、ハイパーパラメータの調整やデータ数をもっと増やして実行するなどしてまともなモデルになるようにしたかったのですが、時間が足りなかったのでそれはまた別の機会に試したいと思います。
かなり自己満足の記事になりましたが、最後まで読んで下さりありがとうございました。