Playwright って?
ブラウザを自動で操作してくれるテスト用のフレームワークです。
https://playwright.dev/
作っているのはあのマイクロソフト! 個人的には少し驚きましたが安心感があります。
ブラウザを自動操作?
使ったことがない方はピンとこないかもしれませんが、指定したURLを開き、テキストエリアに文字を入力して送信ボタンを押す、といったようないつもは人間が手動でやっているような操作をコードを書くことで自動で行ってくれます。
Selenium などが有名かと思いますが過去に使ってみて、こういうのはもう勘弁!と思った方、私もそうだったのですがかなり使いやすくなっていたのでおすすめです!
複数言語に対応
本記事では私が Node.js 版を触ったので Node.js のみの紹介になりますが、以下の言語にも対応しているようです。
使い慣れてる言語がある方はそちらを選択するとスムーズに導入できると思います。
- Java
- Python
- .NET
お試ししてみる
ちょっと触ってみるのが一番!ということでさっそくやってきましょう。
インストール
以下のコマンドでまずはインストールしましょう。
npm i -D @playwright/test
以下のコマンドで使用するブラウザをダウンロードします。
が、今回はお試しなのでダウンロードする時間と容量を節約します。
npx playwright install
以下のように末尾にブラウザ名を指定するとそのブラウザしかダウンロードされません。
デフォルトだと3種類のブラウザがダウンロードされてしまうので複数の種類のブラウザでテストする必要がある!という環境以外ではひとつで十分だと思います。
npx playwright install chromium
簡単な操作をしてみる
以下は Wikipedia を開いてスクリーンショットを撮るコードです。
デフォルトだとヘッドレスモード(GUIが動かない)なので、動作をわかりやすくするためにあえてオフにしています。
const playwright = require('@playwright/test');
(async () => {
const browser = await playwright.chromium.launch({
headless: false // ヘッドレスモードをオフ
});
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('https://ja.wikipedia.org/');
await page.screenshot({ path: 'example.png' });
await browser.close();
})();
ブラウザが立ち上がって Wikipedia のトップページが表示され、ディレクトリ直下にexample.pngという名前でスクリーンショットが保存されたはずです。
もう少し実際に近い操作をしてみる
検索窓にテキストを入力して、ボタンをクリック、遷移先のページ内のテキストを取得してみます。
(async () => {
const browser = await playwright.chromium.launch({
headless: false // ヘッドレスモードをオフ
});
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('https://ja.wikipedia.org/');
// 検索窓に「おにぎり」と入力する
await page.fill('[placeholder="Wikipedia内を検索"]', 'おにぎり');
// 検索ボタンをクリックする
await page.click('input#searchButton')
// 概要を取得する
const text = await page.$('//*[@id="mw-content-text"]/div[1]/p[1]')
console.log(await text.innerText())
await page.screenshot({ path: `example.png` });
await browser.close();
})();
コンソールにおにぎりのページの先頭に記載してある概要が出力されたはずです。
Selenium ですとページの読み込みまでに要素を探そうとしてエラーが表示されるのでウェイトを入れて… などとやった記憶がある方もいると思いますが、そこらへんはよしなししてくれます!(正直これが一番感動しました)
以下のコードでは、プレースホルダーで検索した検索窓にテキスト入力しています。
たいていは id 属性などで検索する場合が多いかと思いますがこういう検索方法もあります。
await page.fill('[placeholder="Wikipedia内を検索"]', 'おにぎり');
ただ、検索しやすい情報がなかった場合、開発者ツールを開き要素を右クリックしてコピーすることで以下のような XPath 形式などでも取得することができます。
何も考えずに要素を選択する場合はこれが一番楽ですが、構造が変わってしまった場合などに対応できない可能性があるので id 属性などのほうが無難かもしれません。
const text = await page.$('//*[@id="mw-content-text"]/div[1]/p[1]')
Palywright では CSS やテキストなど様々な方法で要素は選択できるようなので公式ドキュメントを見てみると最適な方法が見つけられるかもしれません。
https://playwright.dev/docs/selectors
コードの自動生成
上記までの手順を見てなんかめんどくさいな~と思った方に朗報です。
なんと PlayWright にはユーザの操作をコードに出力してくれる機能があるんです…!
このコマンドでは Wikipedia を初めのページとして開き、そこからのユーザの操作をコードで出力してくれます。
npx playwright codegen wikipedia.org
ブラウザと共にもう一つウィンドウが立ち上がり、以下のように操作した内容に対応するコードが記録されていきます。
これは検索窓に Google と入力してエンターキーを押した場合の例です。
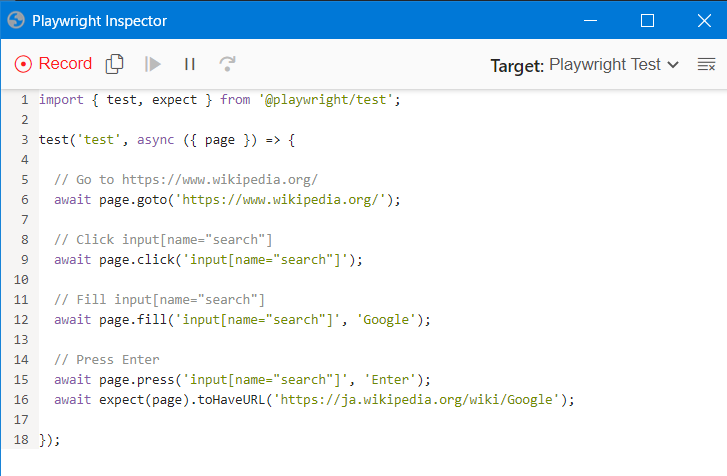
これを元にして不要な操作を削っていく方法であればかなりサクサクとコードが作れそうですね!
私も先日あるページをスクレイピングしたのですが、大本は上記で挙げた自動生成ツールを使って生成しました。
それに手を入れる形をとることで初使用にも関わらず比較的簡単にスクレイピングするスクリプトを完成することができました。
おわりに
実は半年ほど前に PlayWright を使ってスクレイピングをしたのですがそのときに見たドキュメントが現在と大幅に変わっており、アドベントカレンダーのネタにしようと思っていたのでめちゃくちゃ焦りました。
その時点では、確かアサーションメソッドなどは Getting Started には書いてなかったように思いますので短期間でテスト用のフレームワークとして押し出すべくいろいろ機能が追加されたのだと思います。
このような短期間での進化を見ると将来性という点である程度安心感があるのではないでしょうか。
今回記事には書ききれなかったのですが他にもいろいろ機能があったので、興味を持った方はぜひ公式ドキュメントを参照してみてください。