忘備録
Azureの登録等手続きは割愛します。
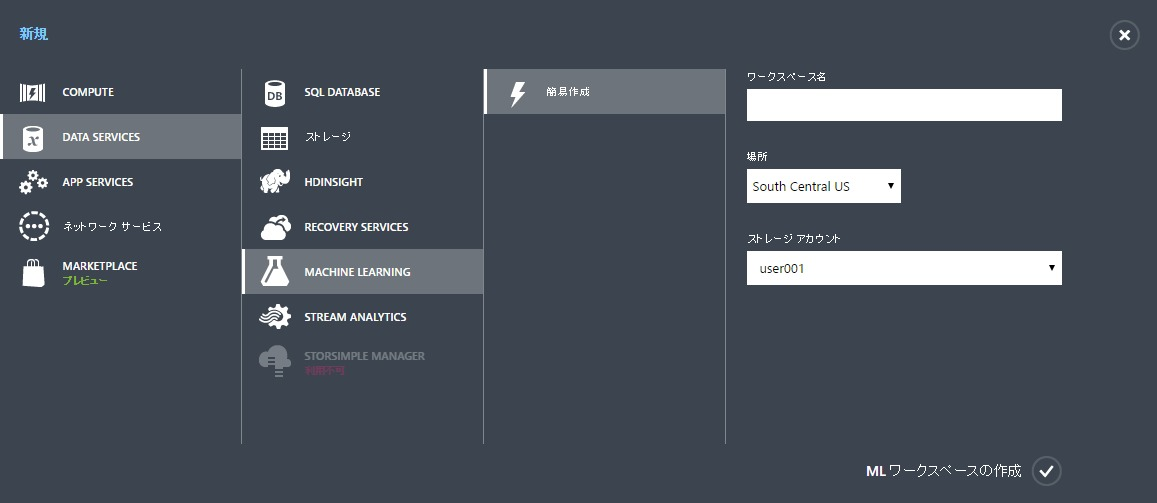
【ワークスペース作成】
Azureクラシック画面より
新規「+」をクリックし、DATA SERVICE→MIACHINE LEARNING→簡易作成を選択し
「ワークスペース名」:任意
「場所」:South Central USを選択
「ストレージアカウント」:任意
*既存で作成したストレージアカウントは使用できません。ML専用です。
入力後、「MLワークスペースの作成」をクリックして
ワークスペースの作成は完了です。
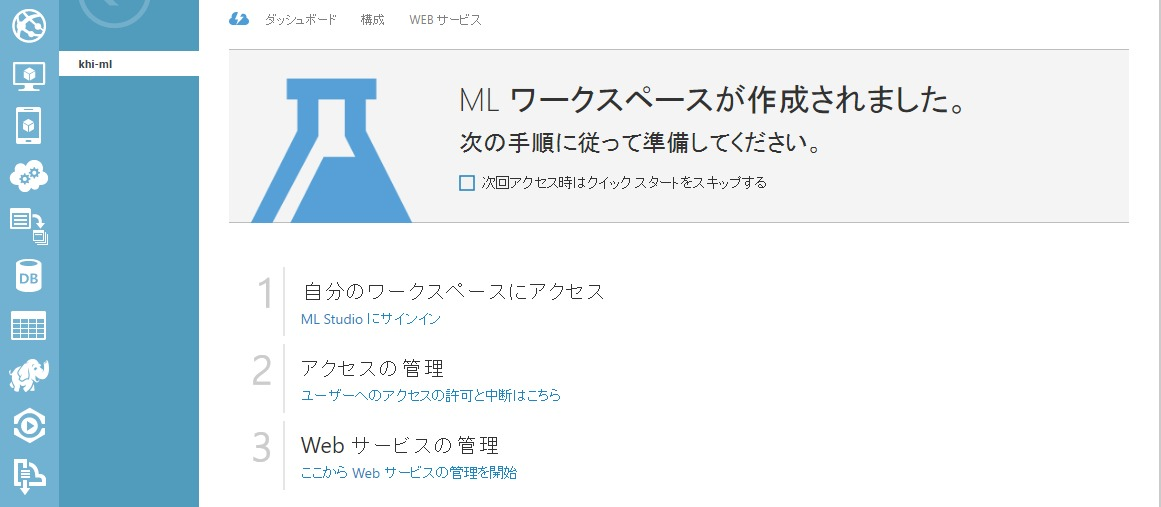
【サインイン】
作成が完了しますと、下記の画面になりますので
Azureで使用しているIDで「ML Studio」にサインインします。
サインインしますと別タブが上がり、Machine Learning Studioが起動します。英語版のみです(2016/06/14現在)
【Experiments】
実際に稼働させるMLを作成するには、Experimentsを選択し、「+NEW」をクリックします。
デフォルトのテンプレート選択画面になりますので
初期はテンプレートを選択後にカスタマイズするのが無難です。
慣れれば、Blankを選択し、一から作成するのも良いと思います。
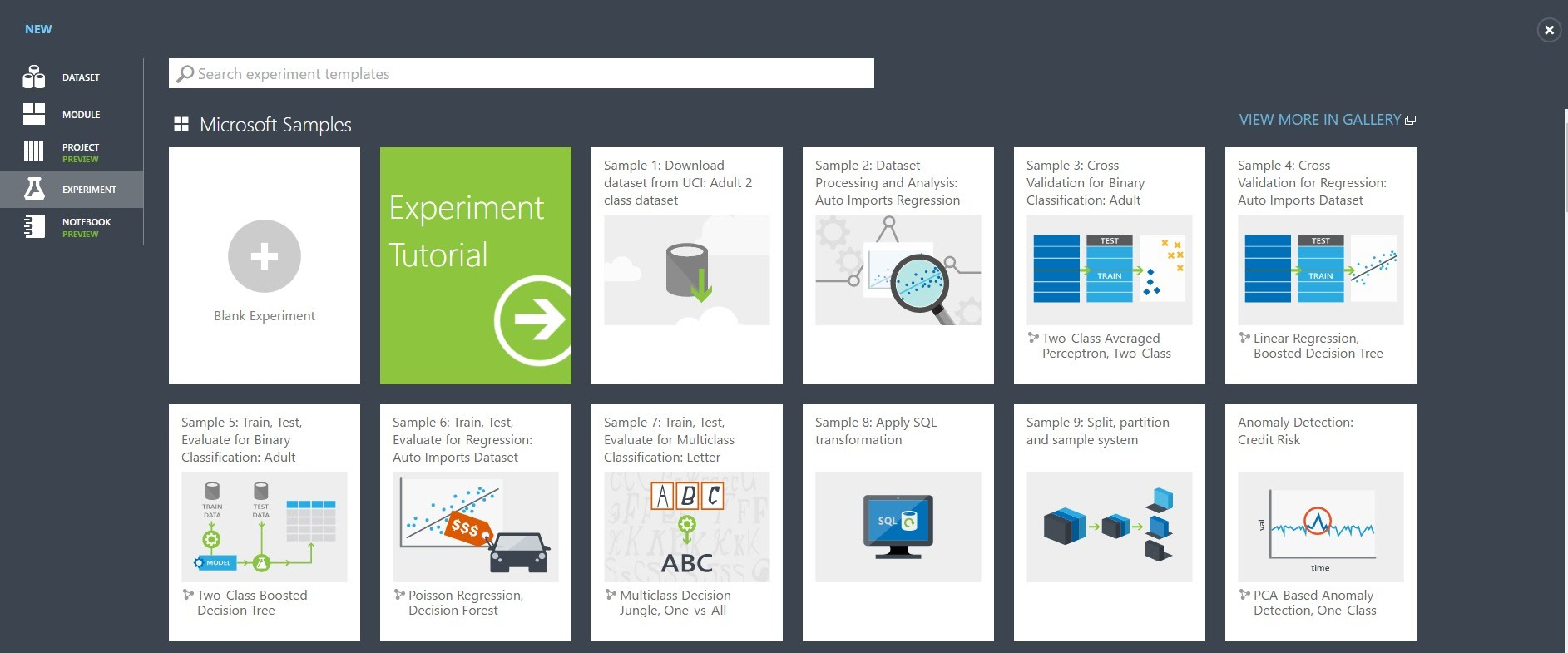
ここでは例として、Group Iris Dataを使用します。
3種類のアヤメ(iris)の、萼片(がくへん)の長さと幅、花弁の長さと幅のデータセットで
萼片・花弁の情報を元に、3種類に分類するという内容です。
UCI Machine Learning Repository で公開されているデータで、人気 No.1 の有名なデータみたいです。
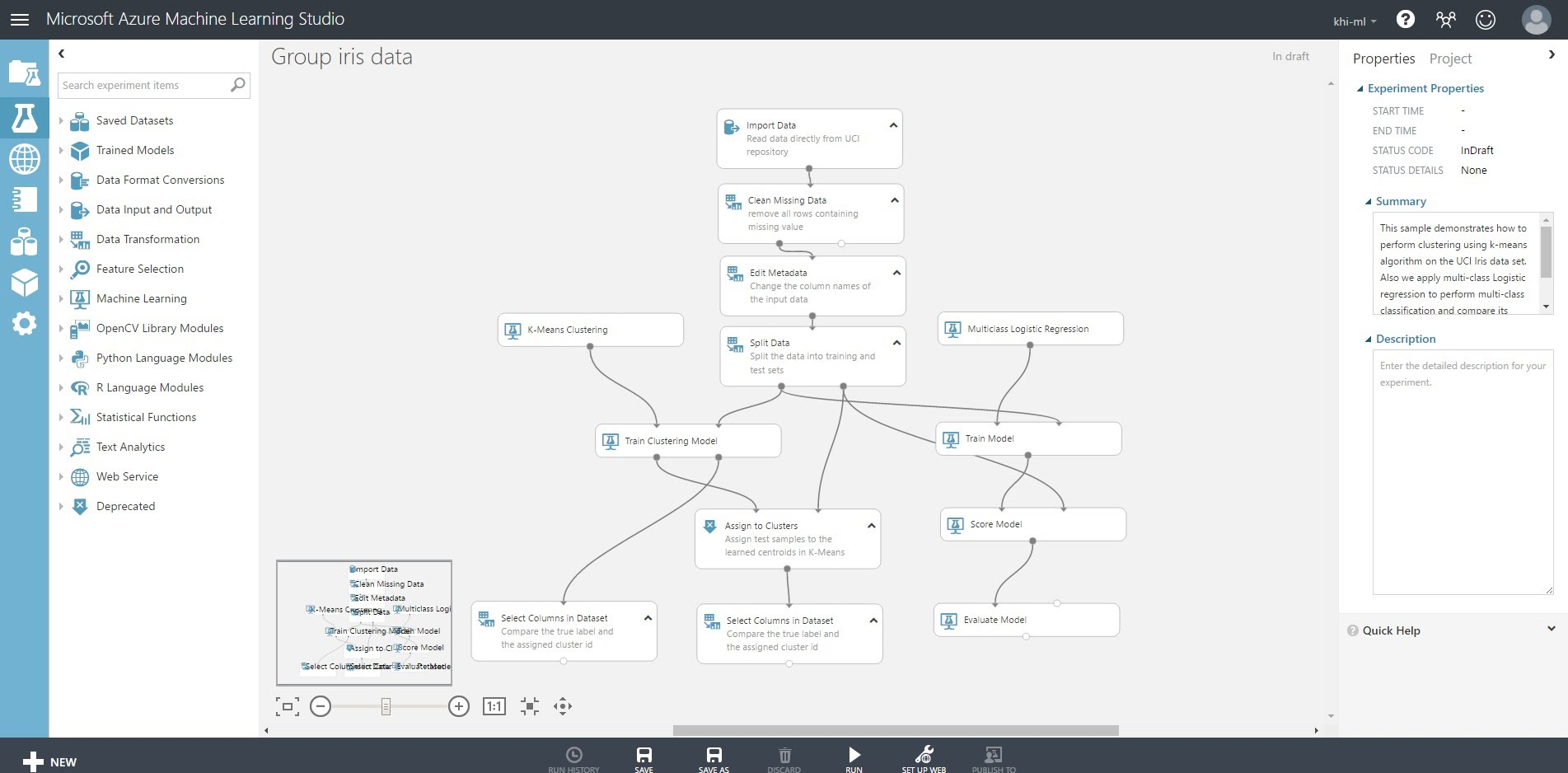
はい、完了です。何もしなくてもテンプレート側で用意されている処理やデータが作成されます。
このサンプルでは、k-means clustering(k平均法)と multiclass logistic regression(多クラスロジスティック回帰)
という手法を使って機械学習し分類しています。
「SAVE」をクリックして保存後、「RUN」をクリックしてMLを実行します。
処理が通過しデータロードが完了した部分には、✔が着きます。
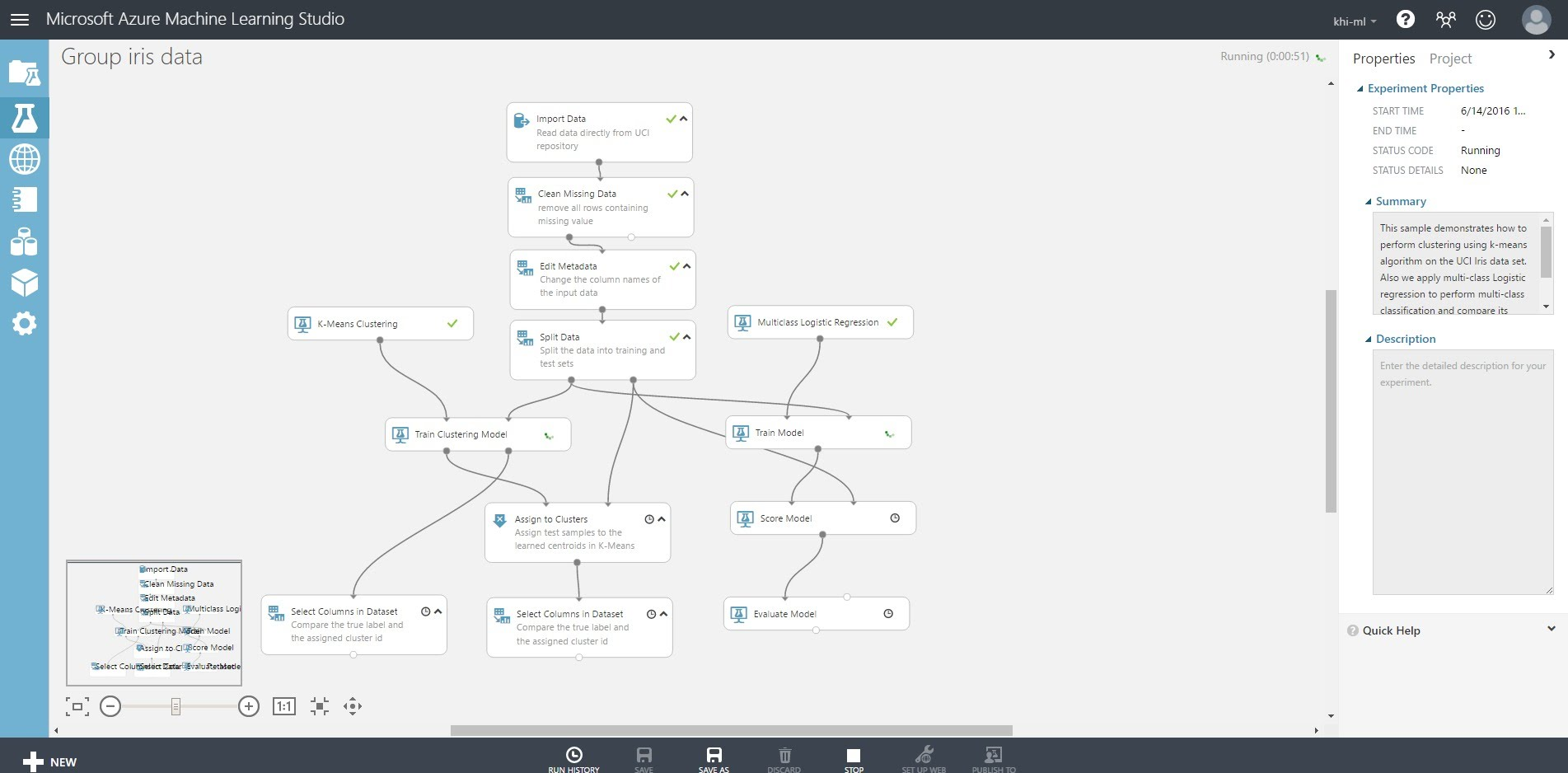
全処理が完了しましたら、実際に処理されたデータを確認します。
処理が終わったモジュールのデータを見るには、出力を表す丸部分をクリックして、Visualize を選びます。
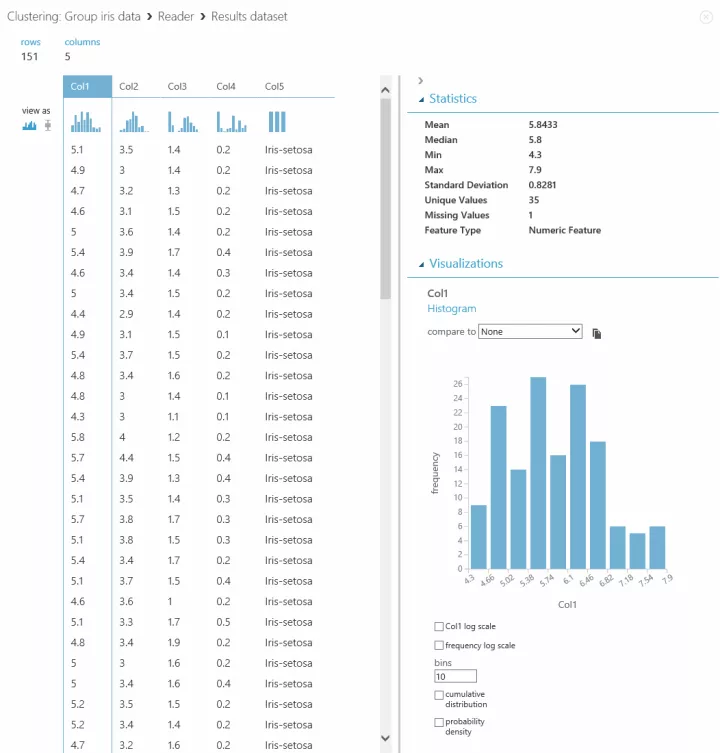
Col1~Col4 が萼片・花弁のデータ、Col5 がアヤメの種類です。列を選択すれば
右側の Statistics や Visualizations で値の範囲や分布などもわかって便利です。
次に、結果を見てみましょう。「K-Means Clustering」がつながっている
「Train Clustering Model」の先、「Project Columns」のデータを見ます。
Label 列は、入力データからのアヤメの種類。Assignments 列が
萼片・花弁の特徴量を使って、機械学習によって分類された値(0~2)です。
Assignments 列を選択して、右側の Visualizations で「compare to Label」を選びます。
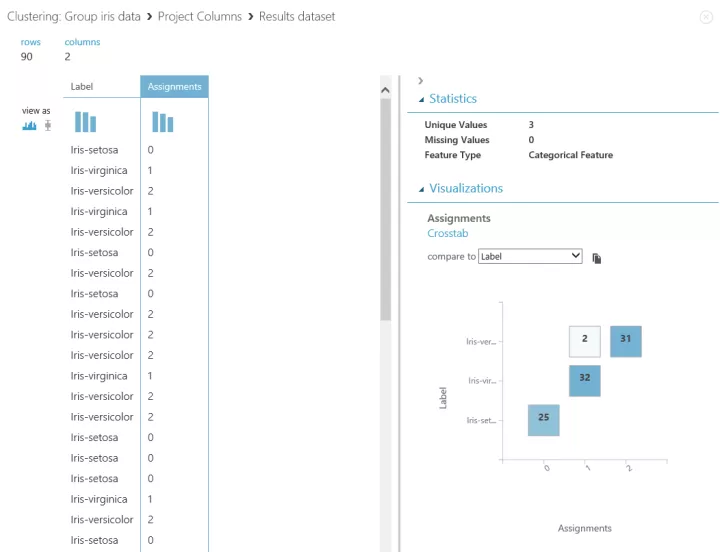
実際のアヤメの種類(Label 列)と、分類した値(Assignments)を比較できます。
Iris-versicolor という種類だけ2件、Iris-virginica という種類に分類してしまったことがわかります。
【テストデータの結果】
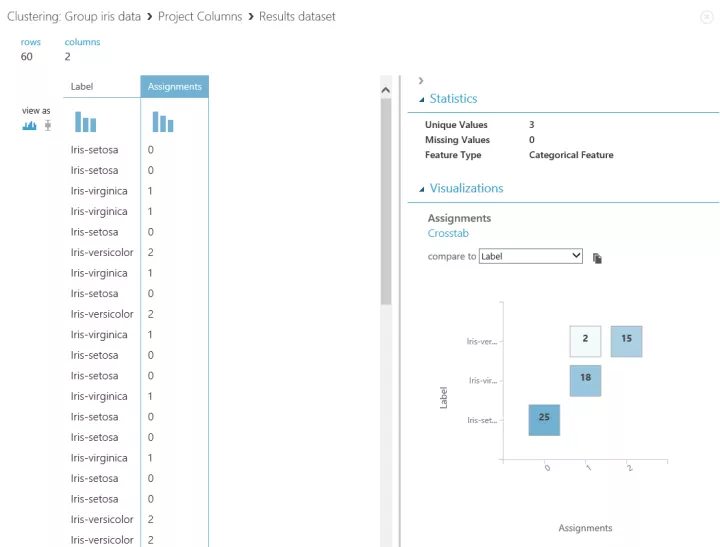
このサンプルでは、入力データを分割(Split)して、90個を機械学習に利用して
残りの60個を学習結果のモデルに入力し、テストしています。
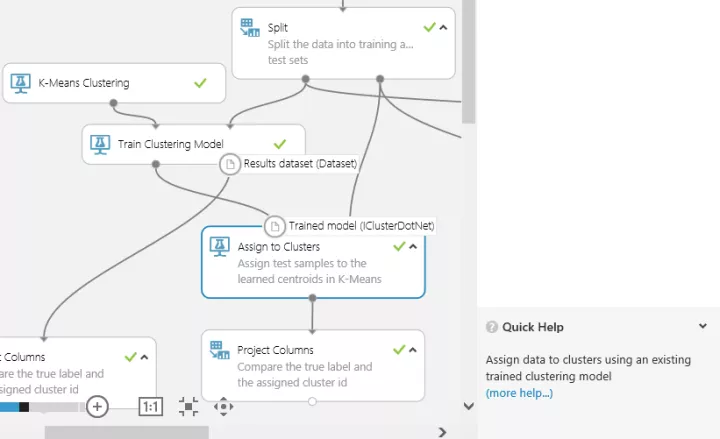
モジュールの入力と出力が何かは、接続部分にカーソルを合わせるとわかります。
また、クリックして選択した状態では、画面右下の「Quick Help」にも説明とドキュメントへのリンクがあります。
各モジュールの出力をいろいろ見てみるとデータの流れや動作がわかると思います。
「Assign to Clusters」の先の「Project Columns」の結果を見てみましょう。
学習済みモデルを使って、分類されているのがわかります。
【Multiclass Logistic Regression による結果】
Multiclass logistic regression の方は、「Score Model」に学習した結果とテストデータが入力されています。
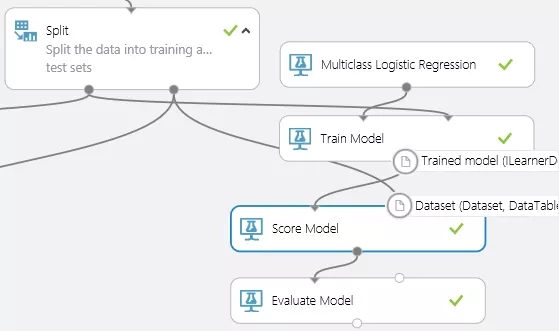
「Score Model」の出力データを見ると、k-means clustering と形式が違いますが
Scored Labels 列が、分類された結果です。Label 列と比較します。
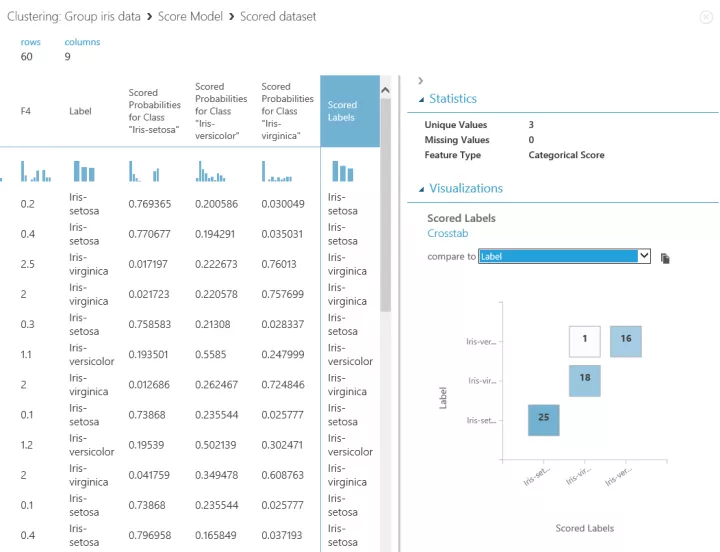
「Score Model」はさらに「Evaluate Model」につながり、分類結果の評価を見れます。
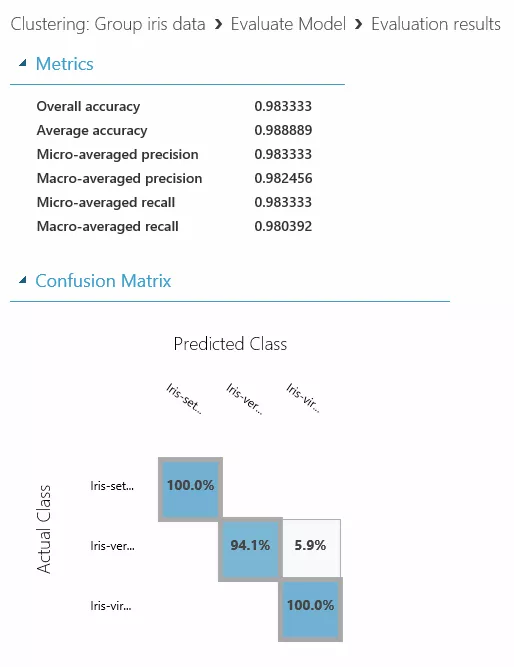
以上