今回の内容
長かったチャレンジ投稿も、今回で終了です。
いままでS3バケットに保存していたデータを、Redshiftに書き込むところまで構築します。
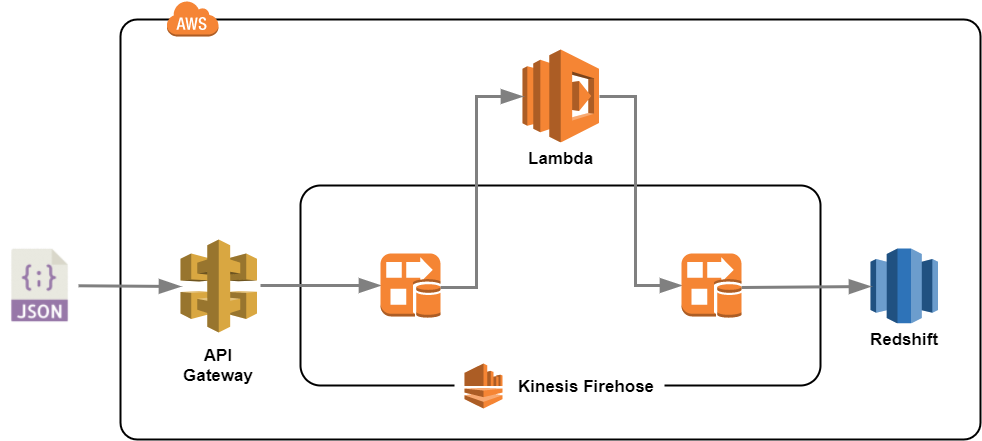
トポロジ(AWS側)
FirehoseにAmazon Lambda関数を設定することで、独自のカスタム変換を組み込むことができるようになります。
またその際のトポロジは、下図のようにFirehoseのI/O間を、Lambda関数にバイパスするようなイメージとなります。
Amazon Lambda関数の作成
FirehoseからバイパスされるAmazon Lambda関数を、予め以下の手順で作成します。
AWSマネジメントコンソールから
Lambdaを開き、関数の作成をクリック
-
Blueprints(設計図)の
kinesis-firehose-process-record-pythonをクリック
Blueprintについて
このkinesis-firehose-process-record-pythonは、Firehoseに送られたストリームデータをカスタム変換することを目的に、予め用意されているPython用のひな型となります。
デフォルトのコードは以下の内容となり、eventにセットされているPayloadをbase64デコードした後、再度base64エンコードして返しているだけなので、結果的に何も変換処理をしていません。
つまりコード内の# Do custom processing on the payload hereとコメントアウトされた部分に、payloadに対するカスタムコードを書くことによって、独自の変換処理を追加できるというわけです。lambda_function.pyfrom __future__ import print_function import base64 print('Loading function') def lambda_handler(event, context): output = [] for record in event['records']: print(record['recordId']) payload = base64.b64decode(record['data']) # Do custom processing on the payload here output_record = { 'recordId': record['recordId'], 'result': 'Ok', 'data': base64.b64encode(payload) } output.append(output_record) print('Successfully processed {} records.'.format(len(event['records']))) return {'records': output} -
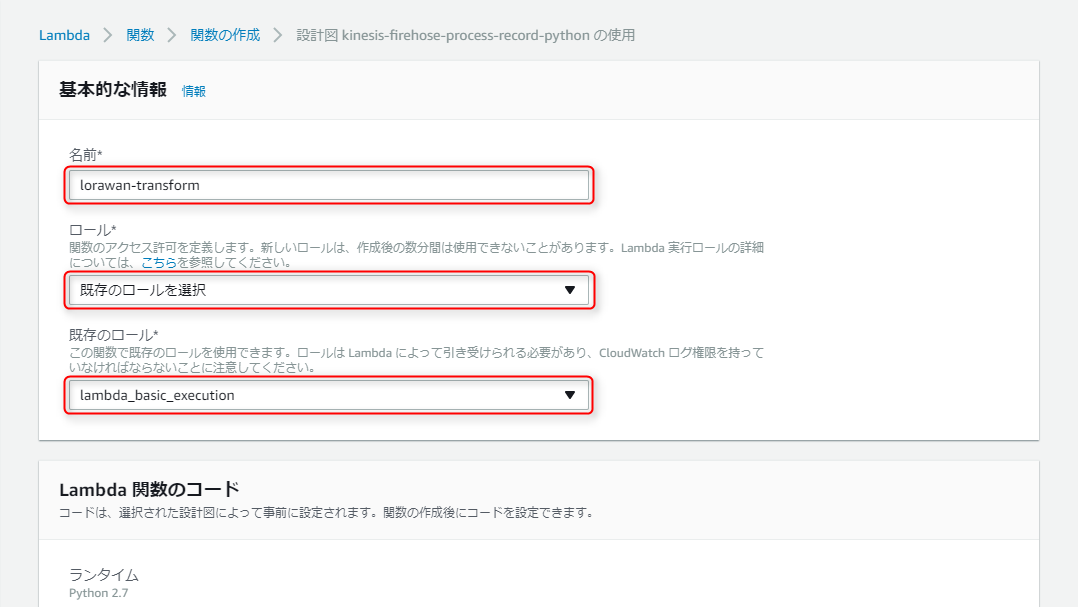
名前に任意の関数名(今回はlorawan-transform)を入力、ロールは既存のロールを選択のまま、既存のロールには任意のIAMロール(CloudWatch Logsにアクセス権限があればよい。今回はlambda_basic_execution)を選択
IAMロール
lambda_basic_executionはデフォルトで登録されていると思いますが、もし存在しなければ以下を参考にIAMロールを作成してください。信頼関係
Amazon LambdaにAssumeRoleを許可するポリシーオブジェクト{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "lambda.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }アクセス権限
CloudWatch Logsに出力を許可するインラインポリシー{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:*:*:*" } ] } ページ最下部までスクロールし、
関数の作成をクリック
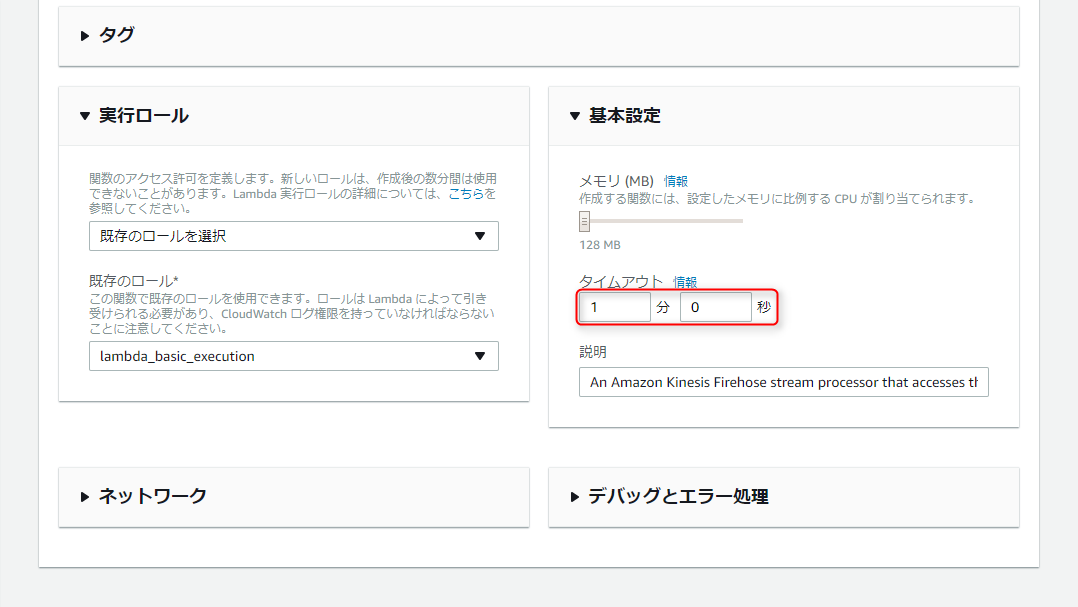
作成後、ページ下部の
基本設定にあるタイムアウト値を、1分以上に変更(Firehose側の仕様のようです)
ページ上部にある
保存をクリック
※もし保存してテストをクリックした場合、テスト結果が成功してさえいれば、この時点では問題ありません。
Kinesis Firehoseの設定変更
配信ストリーム(
lorawan_stream)を開き、Editボタンをクリック
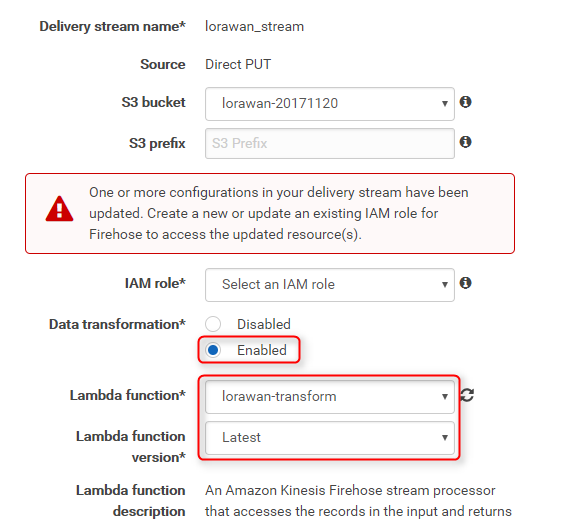
Data transformationをEnabledに変更、Lambda functionに作成した関数lorawan-transformを選択、Lambda function versionにLatestを選択
引き続き
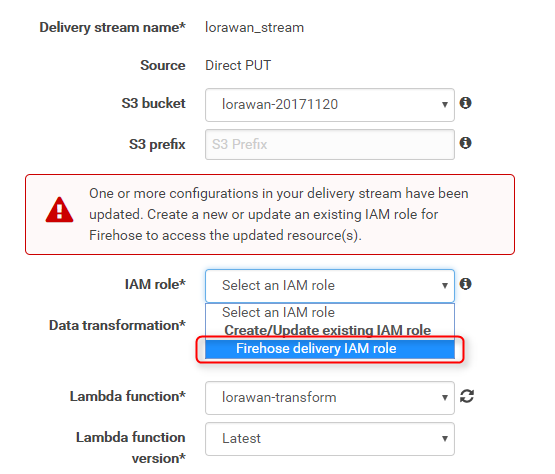
IAM roleにFirehose delivery IAM roleを選択
-
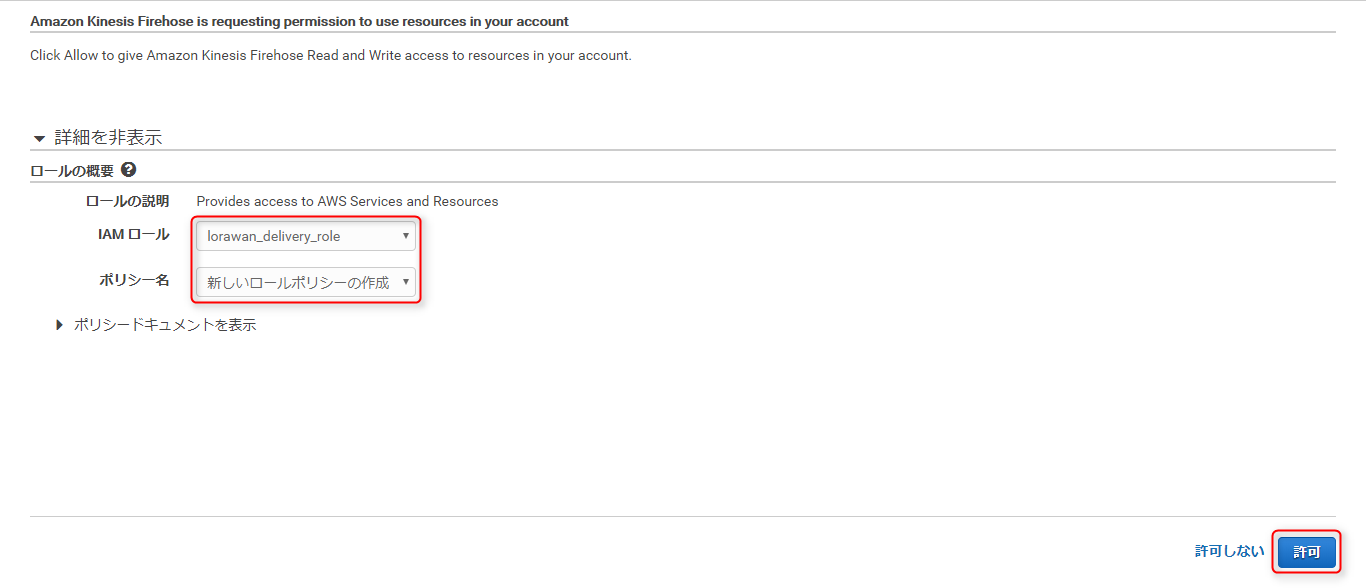
別ページが開くので、
IAMロールにlorawan_delivery_roleを選択、ポリシー名がデフォルトの新しいロールポリシーの作成のまま、許可をクリック
この設定で、以下のアクセス権限インラインポリシーが、既存のロール(lorawan_delivery_role)に追加されます。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Action": [ "s3:AbortMultipartUpload", "s3:GetBucketLocation", "s3:GetObject", "s3:ListBucket", "s3:ListBucketMultipartUploads", "s3:PutObject" ], "Resource": [ "arn:aws:s3:::lorawan-XXXXXXXX", "arn:aws:s3:::lorawan-XXXXXXXX/*", "arn:aws:s3:::%FIREHOSE_BUCKET_NAME%", "arn:aws:s3:::%FIREHOSE_BUCKET_NAME%/*" ] }, { "Sid": "", "Effect": "Allow", "Action": [ "lambda:InvokeFunction", "lambda:GetFunctionConfiguration" ], "Resource": "arn:aws:lambda:ap-northeast-1:<Account ID>:function:lorawan-transform:$LATEST" }, { "Sid": "", "Effect": "Allow", "Action": [ "logs:PutLogEvents" ], "Resource": [ "arn:aws:logs:ap-northeast-1:<Account ID>:log-group:/aws/kinesisfirehose/lorawan_stream:log-stream:*" ] }, { "Sid": "", "Effect": "Allow", "Action": [ "kinesis:DescribeStream", "kinesis:GetShardIterator", "kinesis:GetRecords" ], "Resource": "arn:aws:kinesis:ap-northeast-1:<Account ID>:stream/%FIREHOSE_STREAM_NAME%" }, { "Effect": "Allow", "Action": [ "kms:Decrypt" ], "Resource": [ "arn:aws:kms:region:accountid:key/DUMMY_KEY_ID" ], "Condition": { "StringEquals": { "kms:ViaService": "kinesis.%REGION_NAME%.amazonaws.com" }, "StringLike": { "kms:EncryptionContext:aws:kinesis:arn": "arn:aws:kinesis:%REGION_NAME%:<Account ID>:stream/%FIREHOSE_STREAM_NAME%" } } } ] } Saveボタンをクリック
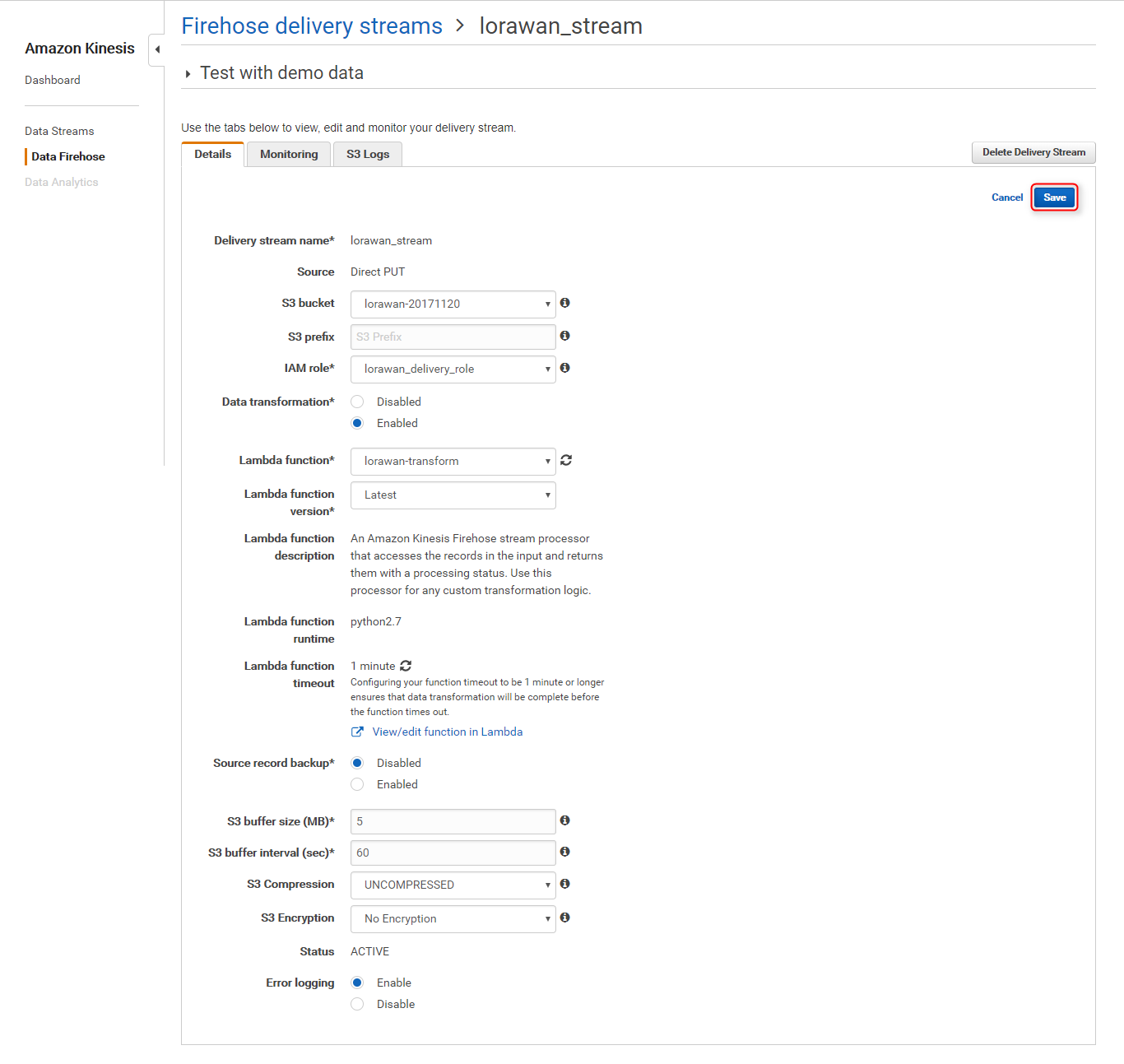
Confirm Changesダイアログが開くのでConfirmをクリック
以上でFirehoseの設定が完了です。
しばらくするとCloudWatch Logsに、Lambdaの実行結果がロギングされるようになります。
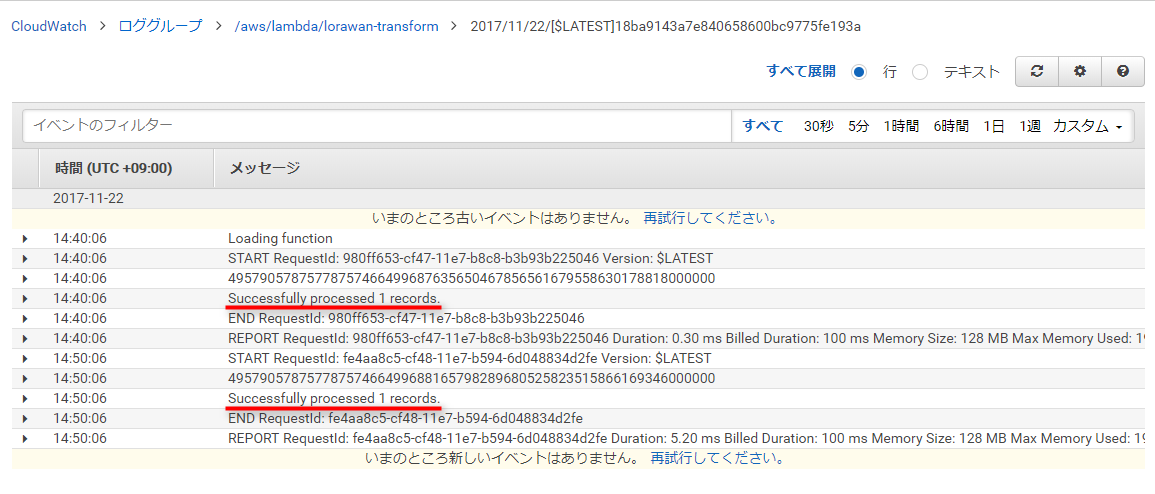
またこの時点ではAmazon Lambda関数内でデータが変換されていないので、S3バケットには前回と同様のデータが蓄積されるだけです。
カスタム変換処理の追加
作成したAmazon Lambda関数に、独自の変換処理を# Do custom processing on the payload here行以降に追加しました。
また追記に伴い必要になったモジュール(datetime、dateutil、pytz)も、新たにインポートしています。
from __future__ import print_function
import base64
import json
from datetime import datetime
import dateutil.parser
from pytz import timezone
print('Loading function')
def lambda_handler(event, context):
output = []
jst = timezone('Asia/Tokyo')
for record in event['records']:
print(record['recordId'])
payload = base64.b64decode(record['data'])
# Do custom processing on the payload here
list = []
payload_dict = json.loads(payload)
dt = dateutil.parser.parse(payload_dict['Time'])
jst_dt = dt.astimezone(jst)
list.append(payload_dict['DevAddr'])
list.append(datetime.strftime(jst_dt, '%Y-%m-%d %H:%M:%S %Z'))
list.append(payload_dict['payload_hex'].decode('hex'))
payload = ','.join([str(i) for i in list])
payload += '\n'
print(payload)
output_record = {
'recordId': record['recordId'],
'result': 'Ok',
'data': base64.b64encode(payload)
}
output.append(output_record)
print('Successfully processed {} records.'.format(len(event['records'])))
return {'records': output}
上記コードでは次の要素を変換し、カンマ区切りしたものをpayloadとして返すようにしています。
- DevAddr
- 値の変換は無し
- Time
- ISO8601フォーマット'YYYY-mm-ddTHH:MM:SS.DDD+1:00'を、'YYYY-mm-dd HH:MM:SS JST'に変換
- payload_hex
- ASCIIコードを文字列に変換
尚、追加モジュールのひとつpytzですが、Amazon Lambda実行環境にはデフォルトでインストールされていません。
pytzをインストールするには、一旦ローカル環境にlambda_function.pyを準備し、以下のコマンドでカレントディレクトリ直下にpytzをインストール、lambda_function.pyと一緒にzipにアーカイブした後、そのzipファイルをAmazon Lambdaにアップロードする必要があります。
$ pip install pytz -t .
$ zip -r upload.zip lambda_function.py pytz
以上の変換処理を追加することにより、以下のようなCSVフォーマットでS3バケット内に蓄積されるようになります。
01XXXXXX,2017-11-23 11:59:15 JST,695
Redshiftクラスタの準備
出力先となるRedshiftクラスタがVPCにある場合、そのクラスタは次の要件を満たす必要があるようなので、予め確認しておきます。
- パブリックアクセスが有効であること
Firehoseはパブリック側からRedshiftに接続してきます。 - FirehoseのパブリックIPアドレスからアクセスできること
東京リージョンにあるFirehoseのCIDRは13.113.196.224/27ということなので、グループポリシーでこのパブリックIPアドレスから5439番ポートへのアクセスを許可しておきます。
今回は既存のRedshiftクラスタを利用した為、グループポリシーへ上記CIDRを追加するだけで済みました。
これで要件を満たしたので、次のSQLを実行してテーブルlorawan.moistureを作成します。
CREATE TABLE lorawan.moisture(
devaddr VARCHAR,
timestamp TIMESTAMP,
humidity SMALLINT
);
配信ストリームの作成(for Redshift)
まず最初に知っておかなければならないことは、「Firehoseの配信ストリーム作成後は、そのストリームの出力先(Destination)を変更することが出来ない」ということです。
つまりS3に出力するよう設定されたストリームでRedshiftに対し出力するよう設定変更することができないため、新たにRedshiftへの配信ストリームを作成し、そのストリームに対してAPI Gatewayから書き込む必要があります。
以降は、ここまで設定してきた環境を残したまま、新たにRedshiftへ出力する処理を追加することにします。
Firehoseの配信ストリーム新規作成ページを開き、
Delivery stream nameに任意のストリーム名(今回はlorawan_stream_to_redshift)を入力し、ページ下部のNextをクリック
Record transformationにEnabledを選択、Lambda Functionには上記で作成したLambda関数(lorawan-transform)を選択、Lambda function versionは$LATESTを選択し、Nextをクリック
-
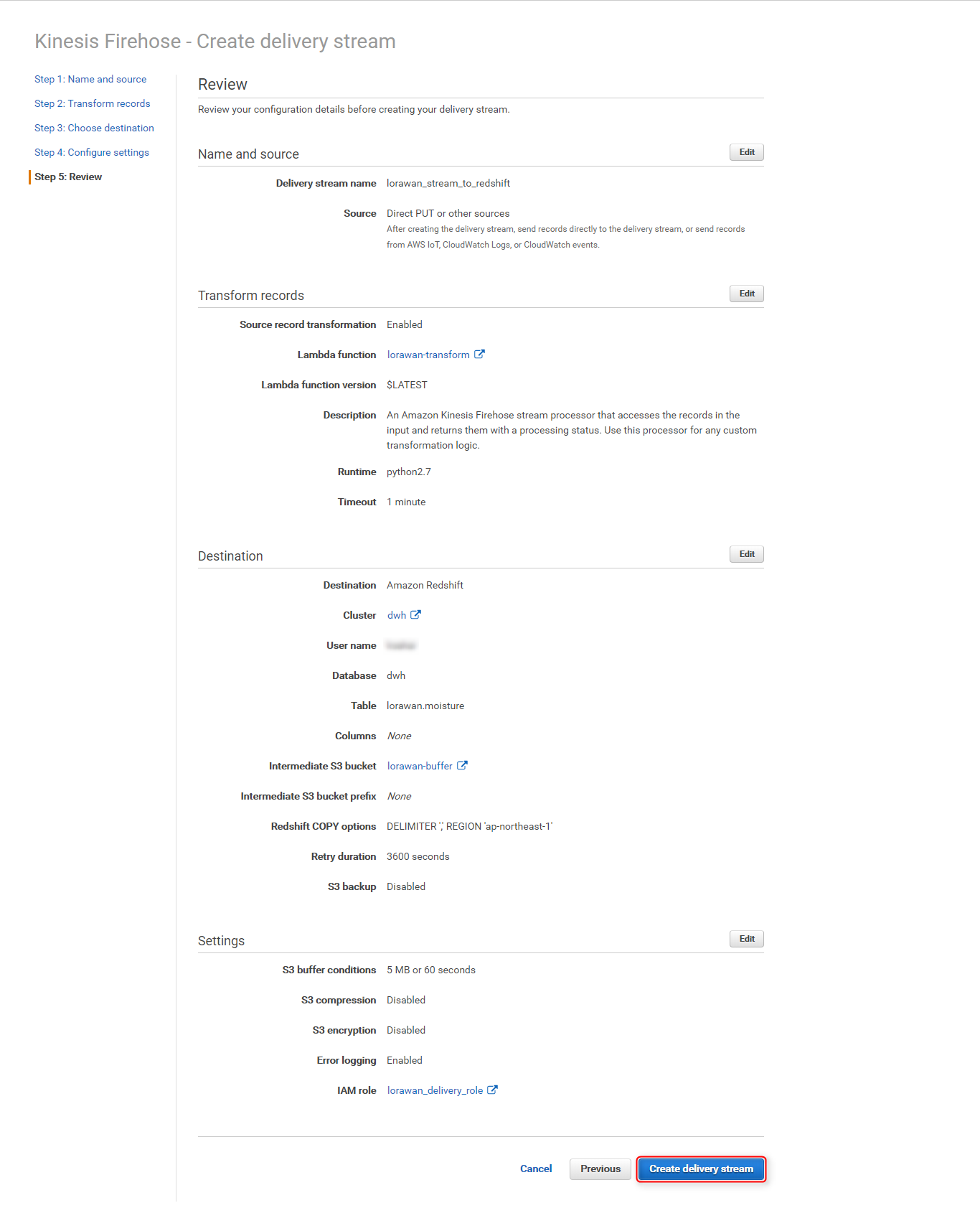
Create delivery streamページの各項目に適切な値を入力し、Nextをクリック
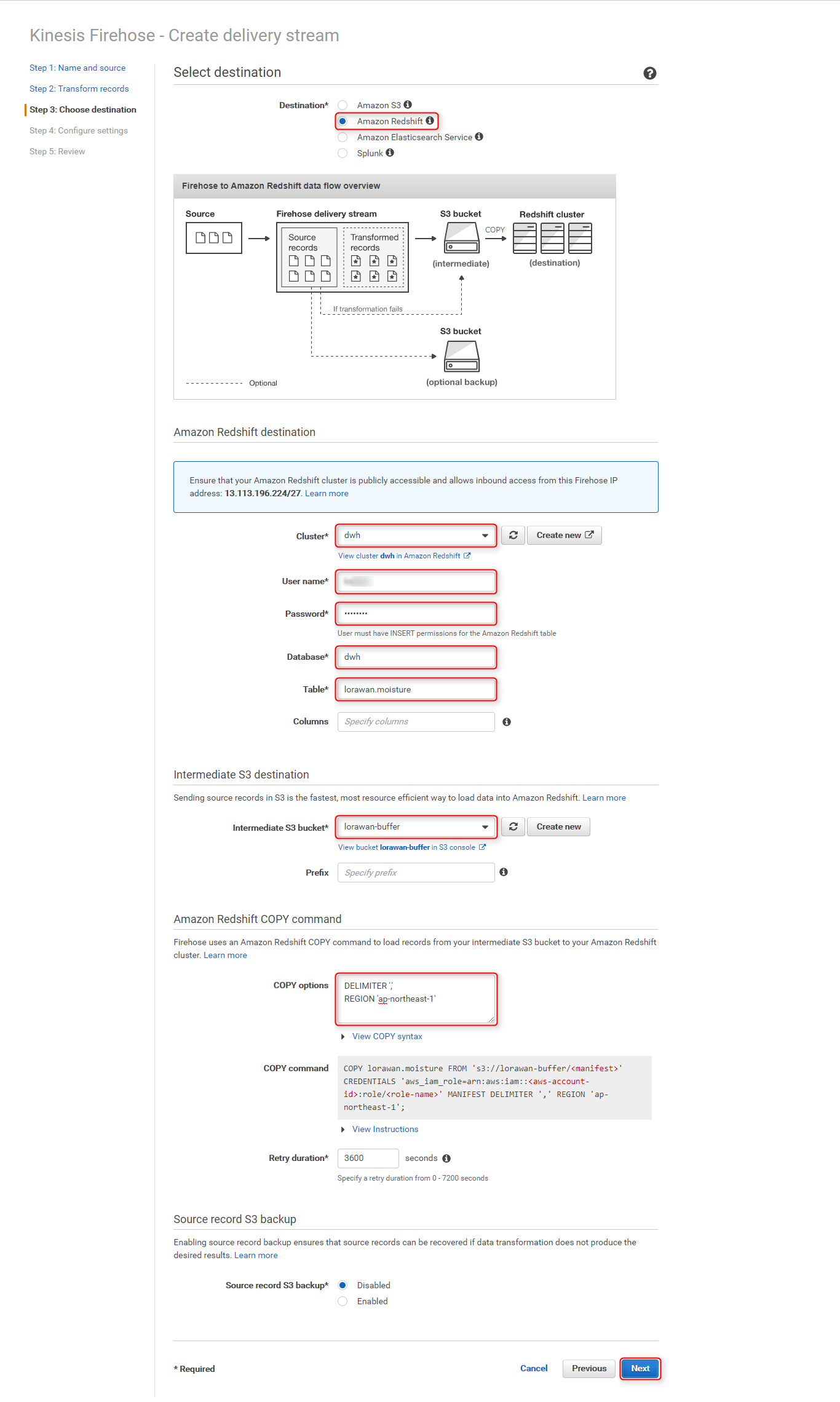
セクション 項目 設定値 Select destination Destination Amazon Redshift Amazon Redshift destination Cluster Redshiftクラスタを選択 User name クラスタへの接続ユーザー名 Password クラスタへの接続パスワード Database データベース名 Table 上記で作成した、センサーデータを保存するテーブル名 Intermediate S3 destination Intermediate S3 bucket Redshiftへデータをロードする前に、一時的に利用するS3バケット名(今回は lorawan-bufferを新規作成)Amazon Redshift COPY command COPY option DELIMITER ',' REGION 'ap-northeast-1'
Lambda関数でCSV形式に変換しているため、デリミタにカンマを指定し、更に東京リージョンを指定COPY command 実際に`Redshiftへ投入されるCOPYコマンドが確認できる Buffer intervalを60(seconds)に変更し、IAM roleのCreate new, or Chooseボタンをクリック
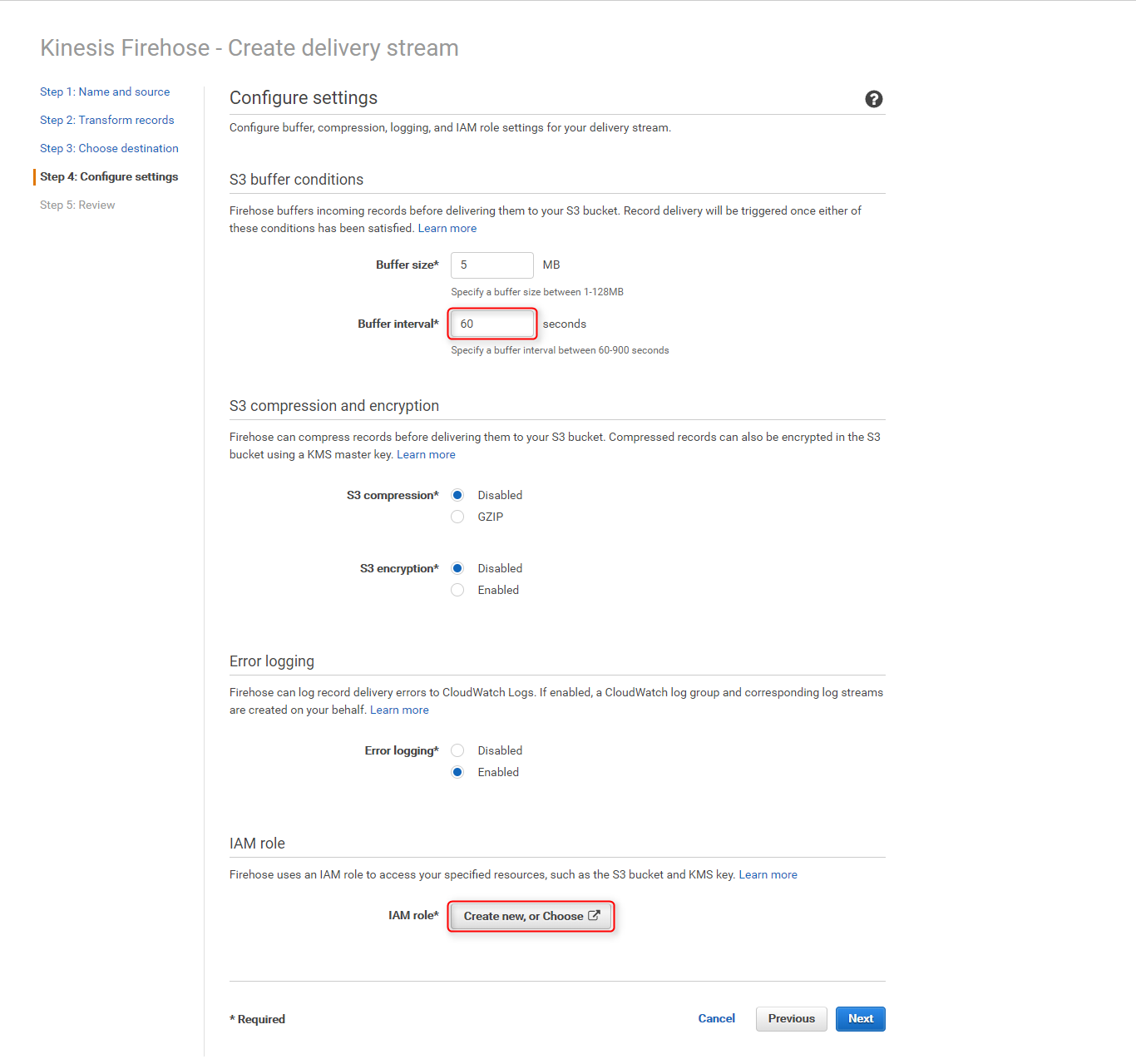
-
別ページが開くので、
IAMロールに既に作成済みのロール(lorawan_delivery_role)を選択、ポリシー名はデフォルトの新しいロールポリシーの作成のまま、許可をクリック
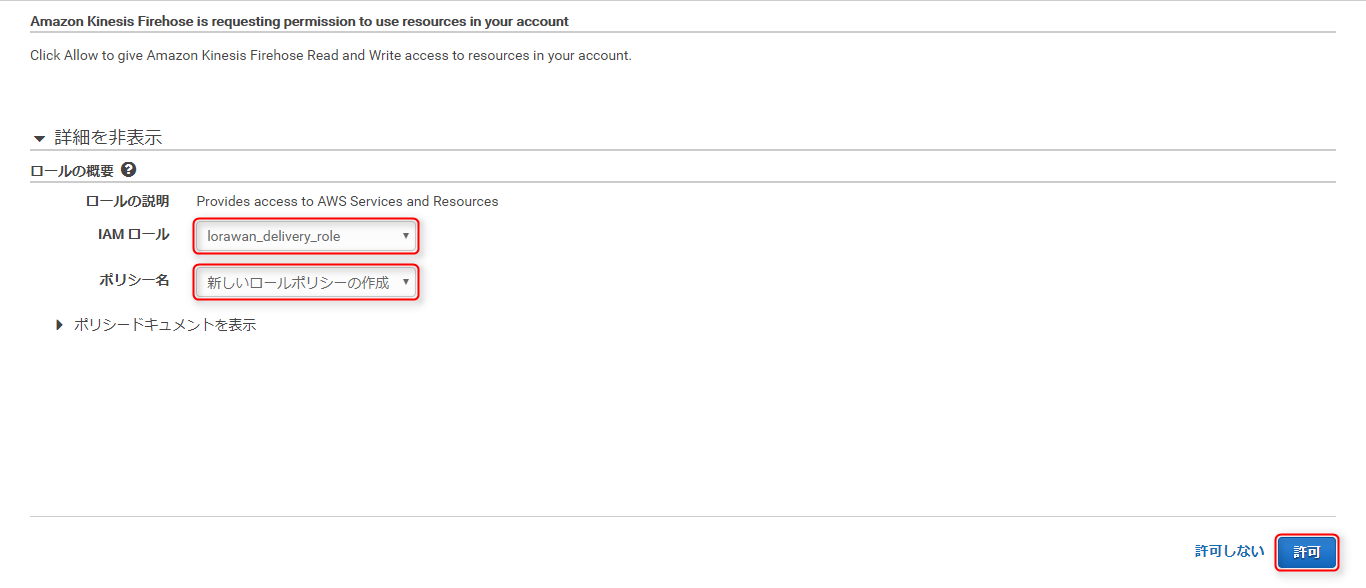
これで以下のアクセス権限インラインポリシーが、既存のロール(lorawan_delivery_role)に追加されます。{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Action": [ "s3:AbortMultipartUpload", "s3:GetBucketLocation", "s3:GetObject", "s3:ListBucket", "s3:ListBucketMultipartUploads", "s3:PutObject" ], "Resource": [ "arn:aws:s3:::lorawan-buffer", "arn:aws:s3:::lorawan-buffer/*", "arn:aws:s3:::%FIREHOSE_BUCKET_NAME%", "arn:aws:s3:::%FIREHOSE_BUCKET_NAME%/*" ] }, { "Sid": "", "Effect": "Allow", "Action": [ "lambda:InvokeFunction", "lambda:GetFunctionConfiguration" ], "Resource": "arn:aws:lambda:ap-northeast-1:<Account ID>:function:lorawan-transform:$LATEST" }, { "Sid": "", "Effect": "Allow", "Action": [ "logs:PutLogEvents" ], "Resource": [ "arn:aws:logs:ap-northeast-1:<Account ID>:log-group:/aws/kinesisfirehose/lorawan_stream_to_redshift:log-stream:*" ] }, { "Sid": "", "Effect": "Allow", "Action": [ "kinesis:DescribeStream", "kinesis:GetShardIterator", "kinesis:GetRecords" ], "Resource": "arn:aws:kinesis:ap-northeast-1:<Account ID>:stream/%FIREHOSE_STREAM_NAME%" }, { "Effect": "Allow", "Action": [ "kms:Decrypt" ], "Resource": [ "arn:aws:kms:region:accountid:key/%SSE_KEY_ARN%" ], "Condition": { "StringEquals": { "kms:ViaService": "kinesis.%REGION_NAME%.amazonaws.com" }, "StringLike": { "kms:EncryptionContext:aws:kinesis:arn": "arn:aws:kinesis:%REGION_NAME%:<Account ID>:stream/%FIREHOSE_STREAM_NAME%" } } } ] } 元のページに戻ったら
Nextをクリック
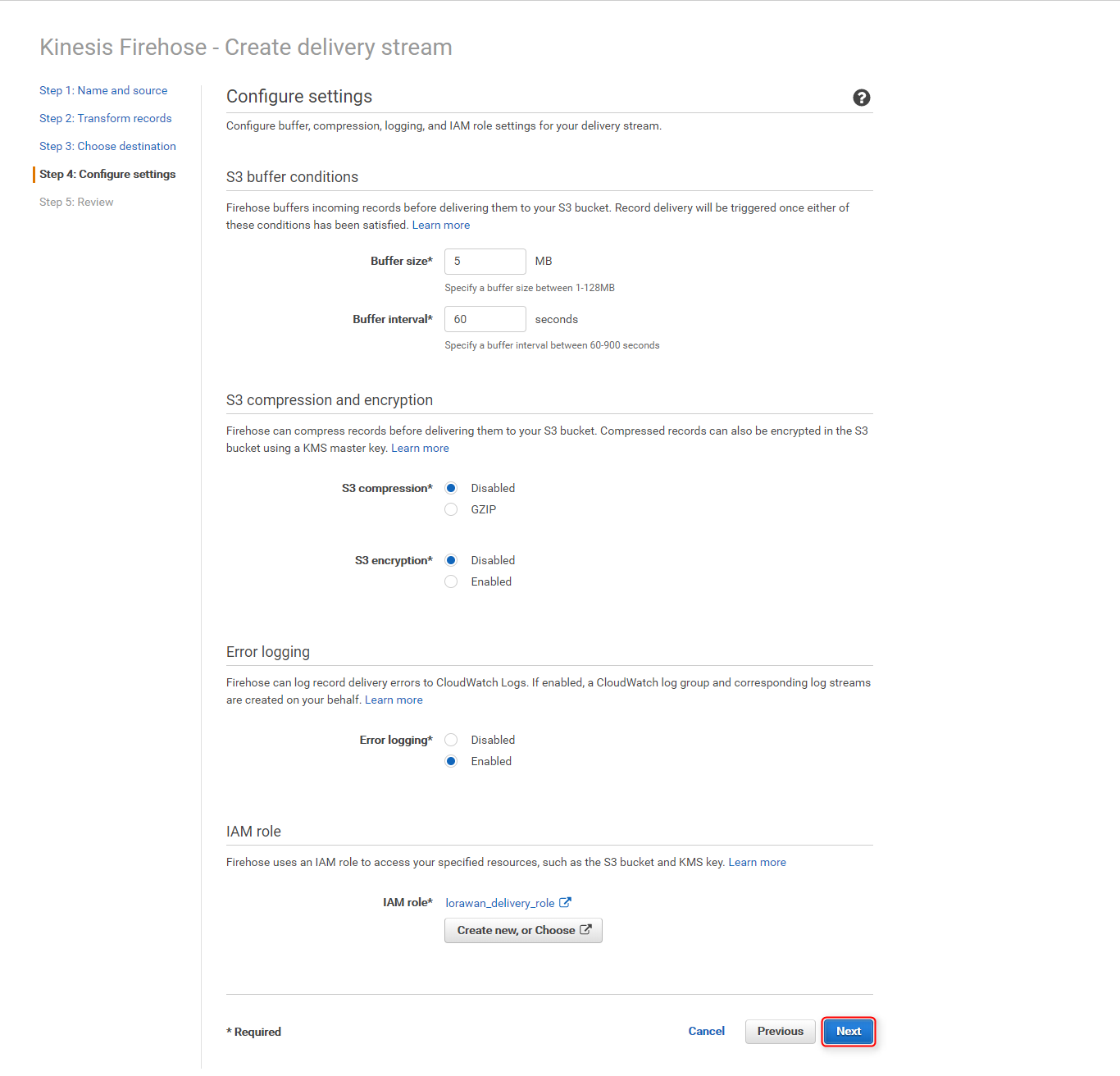
設定内容を確認し、
Create delivery streamをクリック
以上でFirehose配信ストリームの作成は完了です。
API Gatewayの設定変更
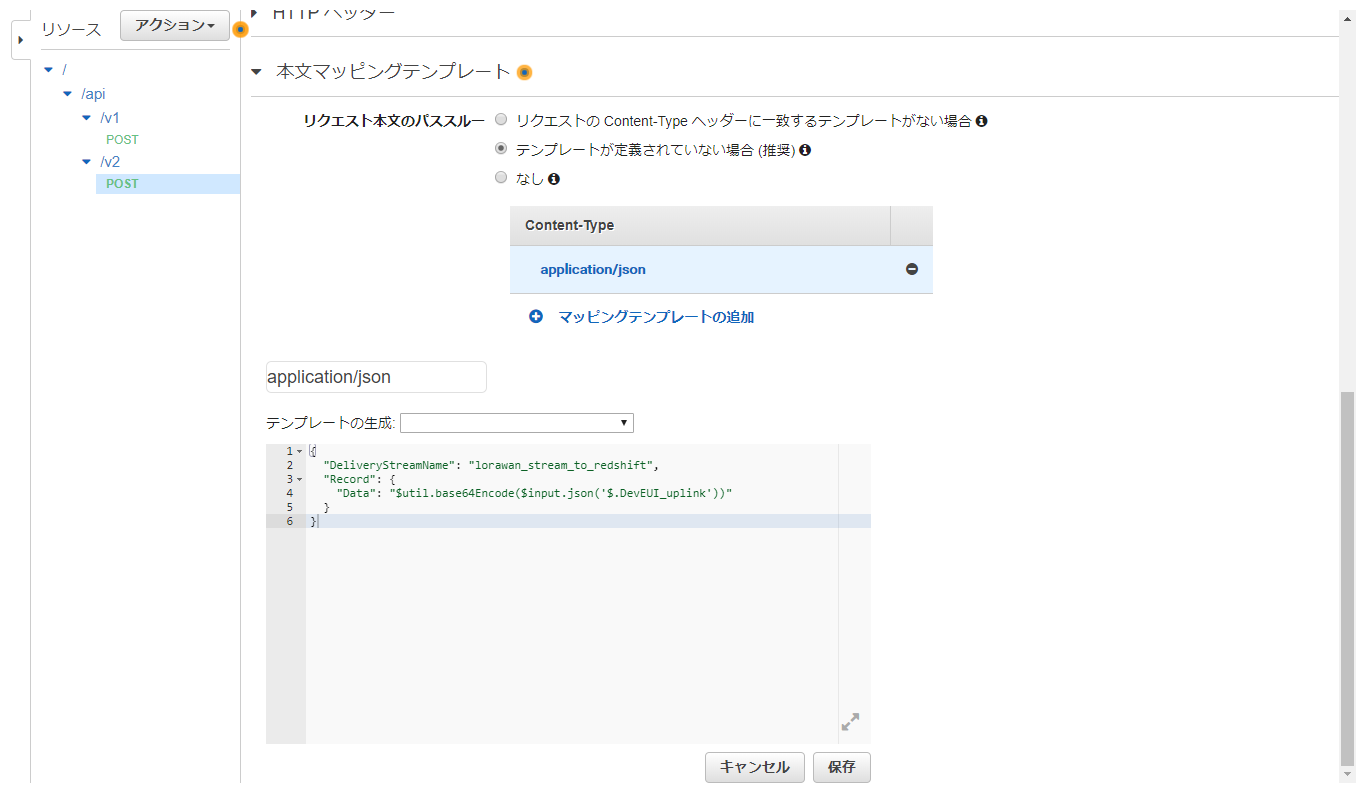
第3回のAPI Gateway作成で作成したAPILoRaWAN APIに、リソースv2と、POSTメソッドを追加で作成します。

更に追加したPOSTの統合リクエストを開き、本文マッピングテンプレートでDeliveryStreamNameの値に、上記で作成した配信ストリーム名を指定すれば設定完了です。
あとはテストをして問題がないか確認し、更にprodステージにデプロイすることも忘れないでください。
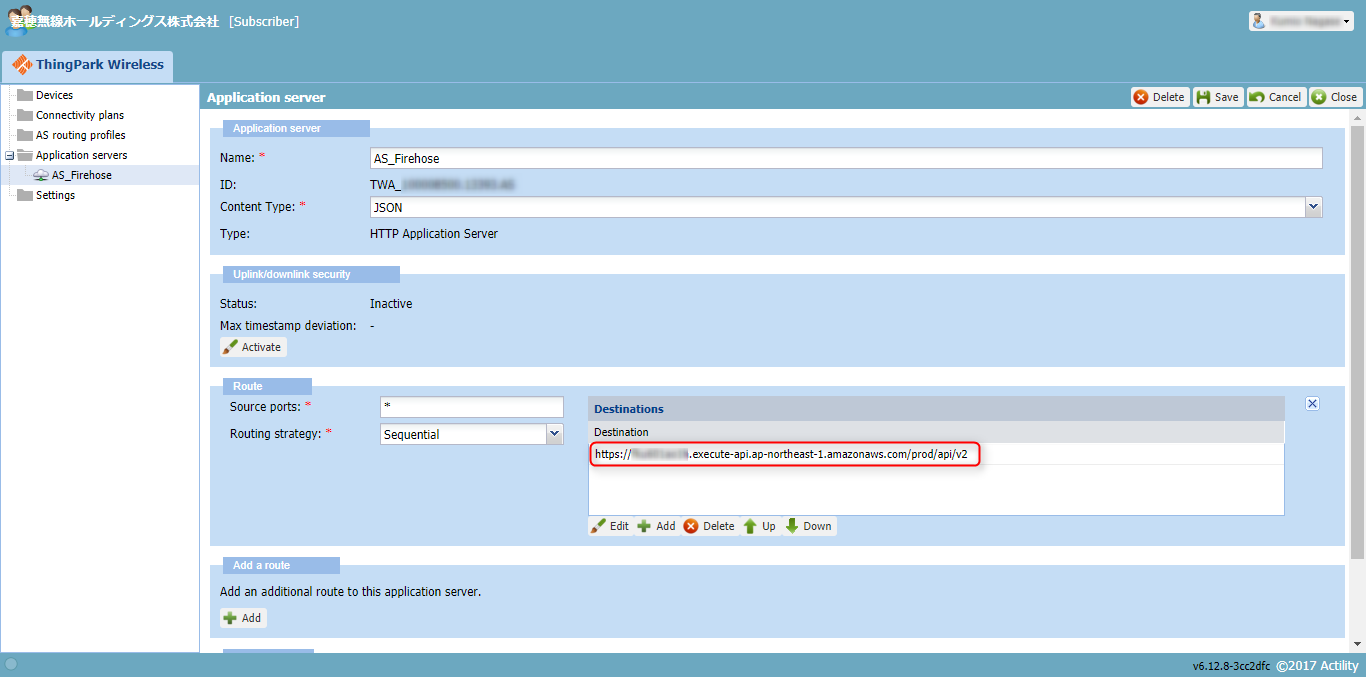
アプリケーションサーバ設定変更
第2回で登録したプラットフォーム側アプリケーションサーバのアドレスを、上記で作成したPOSTメソッドの呼出しURL(https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/prod/api/v2)に変更します。
しばらく待つとLoRaWANデバイスから送信されたセンサー値が、Redshiftに書き込まれるようになりました。
dwh=# SELECT * FROM lorawan.moisture;
devaddr | timestamp | humidity
----------+---------------------+----------
01XXXXXX | 2017-11-27 13:59:02 | 699
01XXXXXX | 2017-11-27 14:09:13 | 700
(2 行)
dwh=#
(2017/11/28 追記)
1晩経過してデータも溜まっていたので、Tableauで可視化してみました。
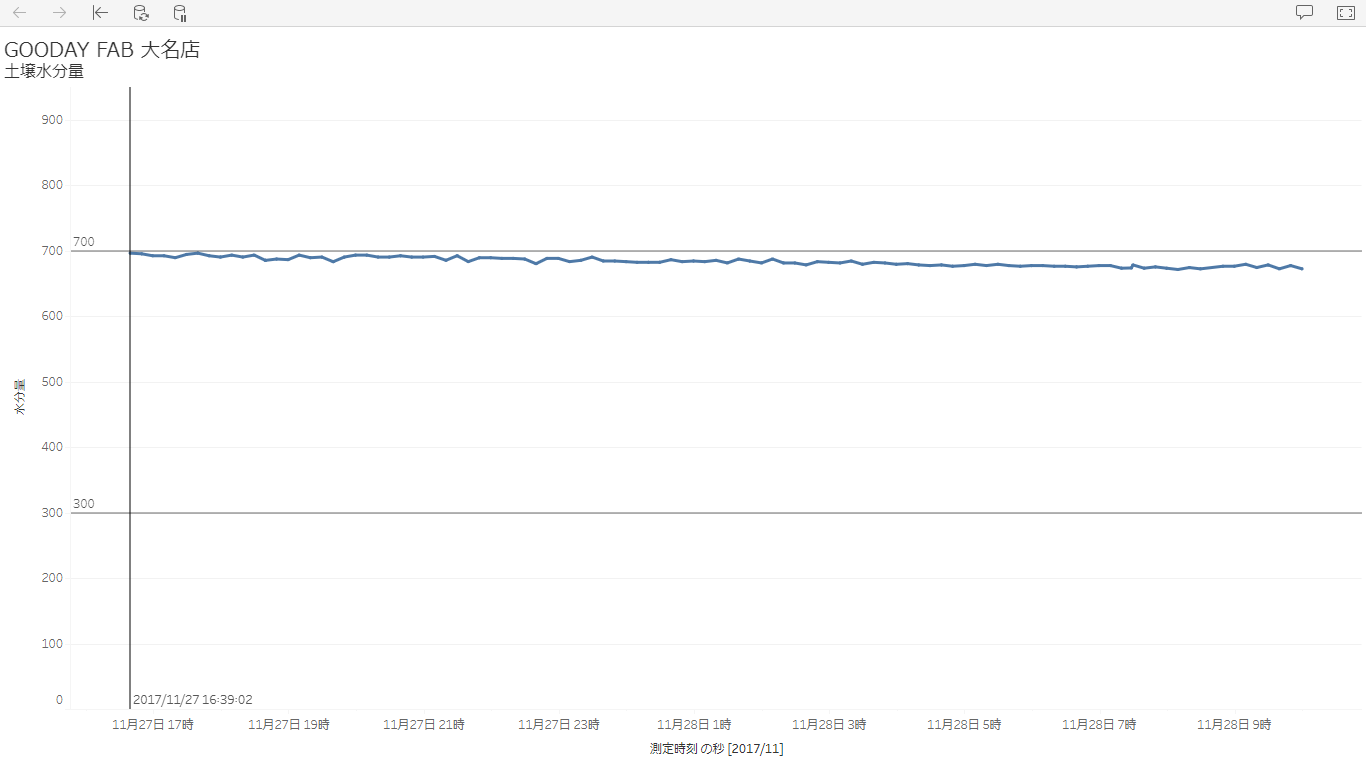
ちなみにグラフ上の定値線ですが、300を下回れば乾燥していることを表し、700を超えると水のやりすぎを表しています。
(2017/11/28 17:35追記)
調子に乗ってThingSpeakも使い、世界中にデータを公開してみました。
最後に
- 初回からいきなりシリアル通信&ATコマンドでやるハメになりましたが、モデムを設定していた懐かしい時代の経験が、非常に役に立ちました。
- 当初
LoRaWANという字面だけで身構えてた部分もありましたが、デバイスのハードウェアそのものを開発する立場でなければ、そんなにハードルは高くなかったです。 -
Kinesis Firehoseは「いままでどうして使わなかったんだろ」と思うくらい、至極簡単にストリームデータをDestinationに流せることが解りました。最近になって東京リージョンで提供されるようになったようなので、今後活用していきたいと思います。 - プラットフォームとアプリケーションサーバ間の通信に、認証機構がまだ実装されていないということなので、今後実装してもらえるんじゃないかと期待しています。