おまけはこちらです。
http://qiita.com/nagahisa/items/7722252eef7c446bcbdd
AGENDA
0.はじめに
- そもそも機械学習って何よぉ
- AML Studioをまっとうに触ってみる
- Pythonと連携
- 参考
0.はじめに
前回勉強会で「Azure Machine Learning(AML)で本来は何が出来るか?」に興味がある方が何名かいました。
Pythonの勉強のためだけにAML Studio使っている方が異常なので、当然といえば当然ですね![]()
せっかくなので今回もまたまた大脱線して AML Studioの初歩の初歩にトライします。
一応このシリーズは「Python勉強会」なので、最後はPython勉強に戻って、AMLでPythonコードを実行する部分にもトライします。
1. そもそも機械学習って何よぉ
僕も勉強中で、いずれ社内勉強会のLT資料にまとめてSlideshareかなんかにUPしたいと思ってますが、まだ作れるほど理解できてないので、以前参加させて頂いた外部勉強会の瀬尾さん資料で説明します。
勉強会(今回説明しない資料もあります)
http://techfair.connpass.com/event/43998/
(1)機械学習
機械学習とAzure ML Studioの基本
http://bit.ly/mlstudio20161203
以下はその勉強会参加時の個人メモの一部です。
(1)What is ML?
Using known data, develop a model to predict unknown data.
既存のデータを使って、学習モデルを作って、新しいデータを予測する
(2)教師ありとなし
あり:分類(二項/多項)・回帰(数値予測)・異常検知
なし:グループ化(=クラスタリング)
・分類:AかBか?
・回帰:どのくらいの量/数か?
・異常検出:これは異常か?
・グループ化:どのような構成か?(正解はない)
- シンプルな回帰モデルの例: y = a*x + b のa,b を求めるのが機械学習
(2)機械学習と深層学習
深層学習(Deep Learning)は、機械学習(Machine Learning)の手法の1つのようですね。
「機械学習 深層学習 違い」とかでググるといっぱい出てきますので、お好きなのをどうぞ。
僕はこの本のp86 図4.2がしっくりきました(まだ第4章までしか読めてませんが)
まぁ、深層学習とは?って偉い人に聞かれたら、
「機械学習の一手法。ニューラルネットワークという人間の神経細胞を模したモデルを何層も重ねる(深層)ことで、飛躍的にモデル精度を上げた」
という良くある言い方だけ覚えておいて、シッタカしましょう。
(そんなこと聞いてくる人は、たぶん、良く分からないまま納得すると思う![]() )
)
もちっと、ちゃんとした説明はこちらなど参照。
http://monoist.atmarkit.co.jp/mn/articles/1701/24/news048.html
ちなみに流行りの"AI"という単語の僕の好きなもともとの意味合いはこれです。
「知性のなんたるかを突き止め、それを電子的に再現する」〜この本 のp8より〜
これ思い出すと恥ずかしくってAIって単語が使えなくなります![]()
2. AML Studioをまっとうに触ってみる
まずはまっとうにAML Studioのチュートリアルをやってみましょう。
Machine Learning のチュートリアル:
Azure Machine Learning Studio で初めてのデータ サイエンス実験を作成する
https://docs.microsoft.com/ja-jp/azure/machine-learning/machine-learning-create-experiment
すごぐ分かりにくいTutorial資料です。最初にこの資料でトライすると挫けます![]()
日本マイクロソフトさんも同じ意見のようで、同じ内容で分かりやすい資料をエバンジェリストが作成されています。
今回はこのスライド資料に基づいてハンズオンを進めます。以下に実行例も載せますが、上記スライドを見た方が分かりやすいです。以下の()内のページ数は上記スライドのページ数です。
(1) AML Studioへサインイン(p24)
AML Studioには前回アカウント作成済みですので、以下リンクからサインします。
https://studio.azureml.net
Studioに移動してこんな表示になればOK。
(2)Experimentの作成(p28)
AML Studioで機械学習する単位をExperimentって言います。
今回ハンズオン用の空のExperimentを作成します。
下の方にある"+New"を押すと以下の画面になるので"Blank Experiment"をクリックします。
これが「まっとうな」AML Studio画面です![]()
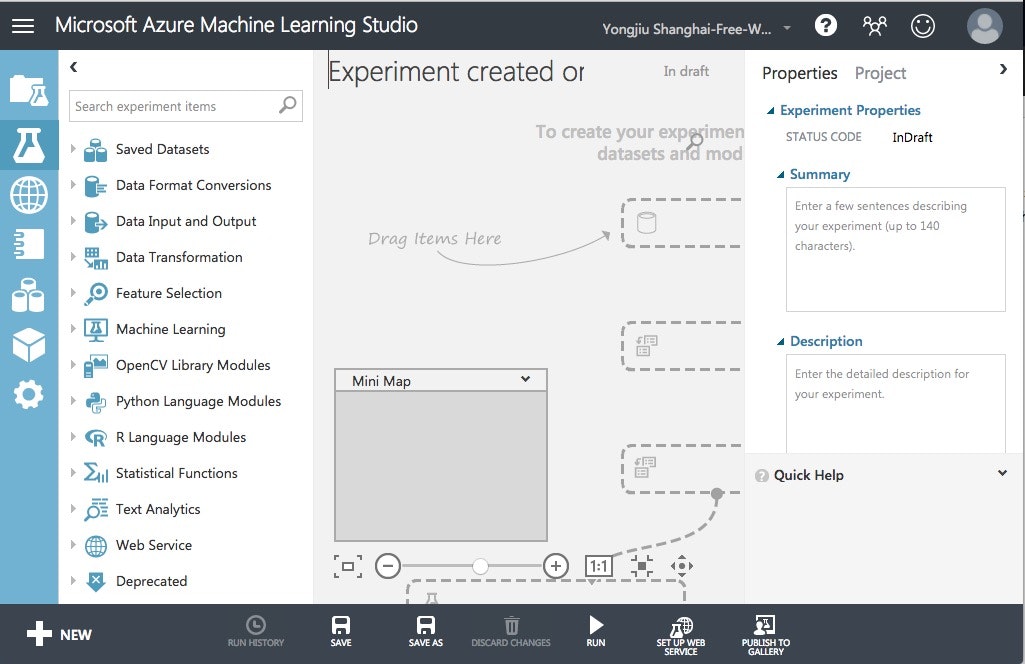
今回ハンズオン用にExperiment名を適当な名前に変更します(例では20170123_Cloud102って名前にします)。保存して一覧に戻ると、この名前のExperimentが出きているので、クリックして作業に戻ることができます。

(3)「ハンズオンの全体像(p27)・最終的なイメージ作成(p34)」の説明
ここまで来たら、このExperimentで何がやりたいか?を説明します。
やりたいのは、自動車の諸元から価格を予想するモデルを作ることです。元データとして、諸元+価格のデータが与えられています。
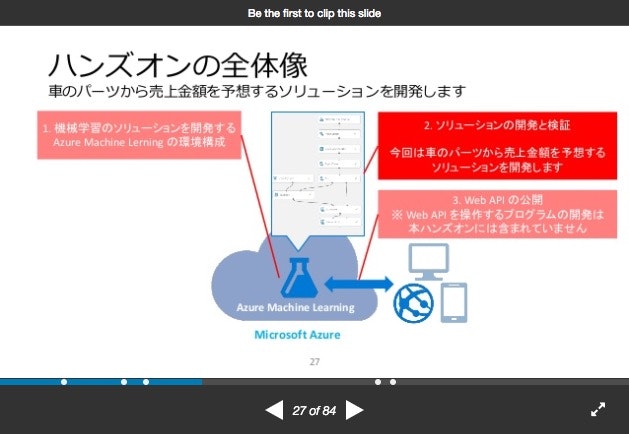
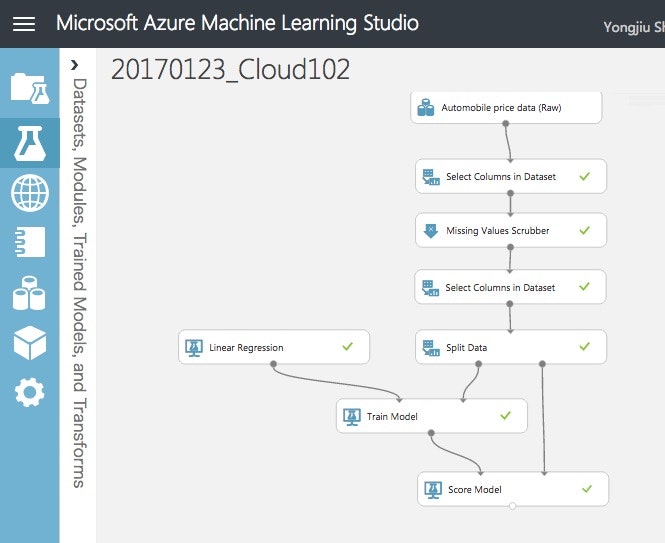
最終的にはこんな感じ(下図の左側)にフローチャーットっぽく各種Module(箱)をGUIで配置してそれらを繋げて出来上がりです。
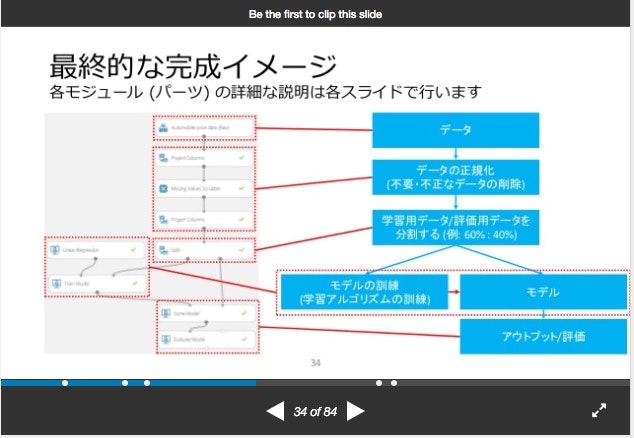
(4)サンプルデータを利用します。(p35-p39)
データは、もともとAML Studioに入っているサンプルデータを利用します。
Visualizeだけでなく、サンプルデータをダウンロードして手元のExcelで確認できます。
MacのExcel2011で開いたところ。
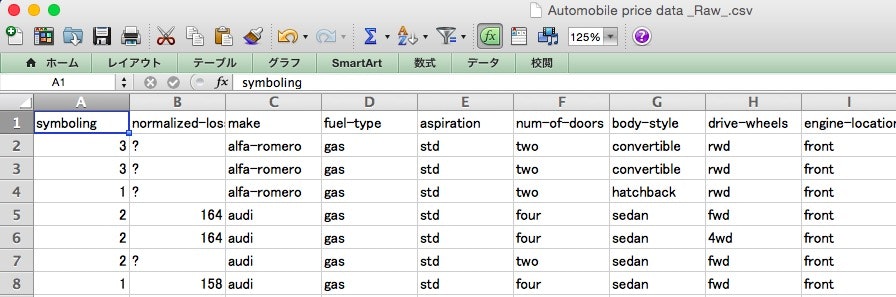
元データは、205行(rows)・26列(columns)ありますね。

(5)データの正規化1(p40-p48)
Tutorialなのでちょっと冗長ですが、3段階でデータを使いやすくしてます。
まずは不要な列(normalized-losses)の削除。
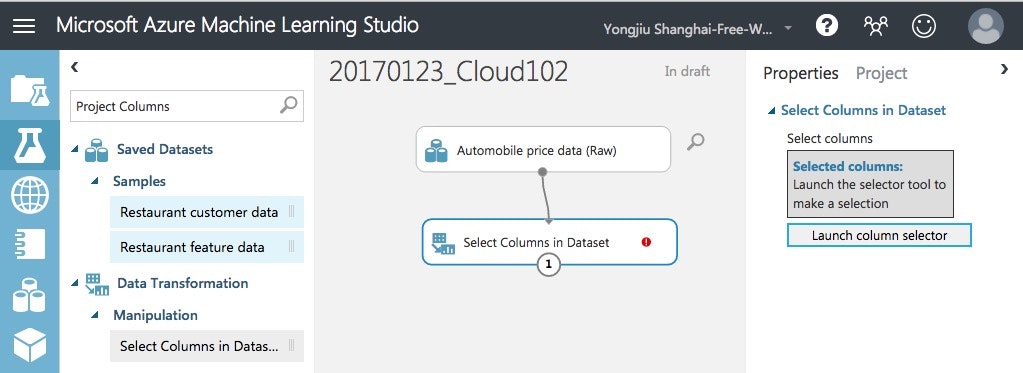
GUIで必要項目を選ぶやり方と、条件を書くやり方が左ペインで選択できて、今回は後者で指定します。
設定終わったら下の"Run"から"Run Selected"を押して実行します。モジュール毎にこれやらないと処理されないので注意してください。
処理終わると緑チェックマークが付きます。Visualizeで確認できます。
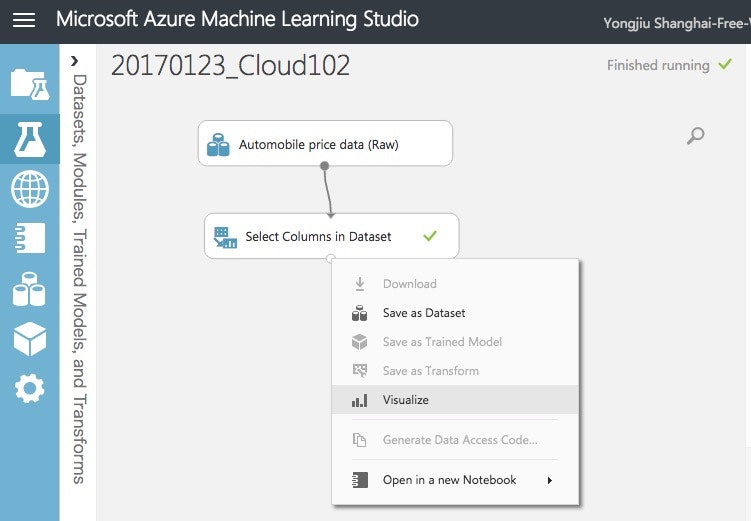
はい、列が25になりました。

(6)データの正規化2(p40-p51)
つづいて2つのデータ処理モジュールを追加します。
・Missing Value solver: 不要データをいい具合に処理します。
・Select Columns in Dataset: 正規化(1)と同じモジュールです。
2つのモジュールを追加して繋ぎます。
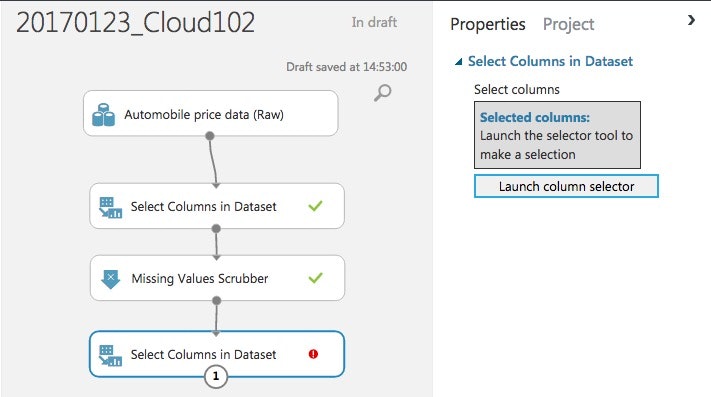
"Select Columns in Dataset"の方で必要な項目のみにします。下はGUIで必要項目選ぶ方の例です。スライドと指定の仕方が違いますが結果は一緒です。
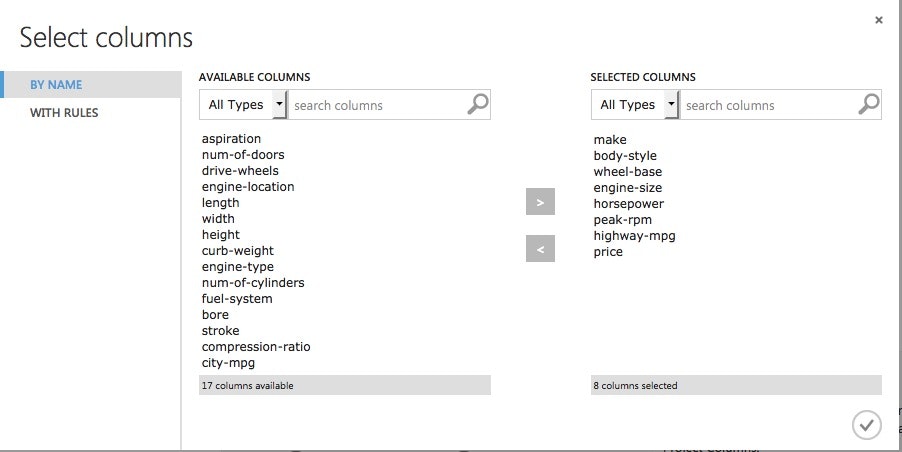
"Run Selected"して結果確認してみると、列が指定した8になっています。

(7) 学習用データ・評価データとは何か?
さてデータの前処理が終わったので、ここから本番です。
次は、前処理したデータを、学習用データと評価用データに分割するのですが、その理由を説明します。
- 機械学習はデータに基づいてモデルを作るわけですが、「汎化能力」の高いモデルを作ることが目的です。
- 「汎化能力」ってのは「知らないデータにも対応出来る能力」なので、知らない(=学習に使ってない)データでも正しく処理出来るモデルを作ることが目的です。
- 学習データだけにきちんと動くモデルを作っても、学習データ以外で動かないと意味ないわけです。
(ちなみに、学習データだけにきちんと動くように学習しちゃうことを「過学習」言うそうです。何事も「過ぎる」のは良くないッス。) - なので学習用データとは別に評価データを用意し、学習用データで作ったモデルを評価データで評価するわけです。
- 今回は元データを、学習用データ・評価データに分けます。
(8)学習用データ/評価用データの分割(p52-53)
Split Dataモジュールを追加して、学習データ側を70%(0.7)に設定します。
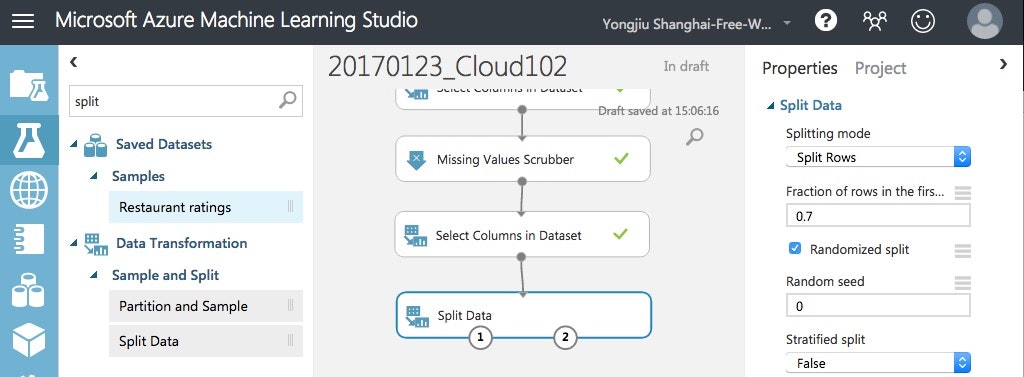
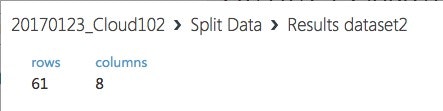
"Run Selected"してみると、学習データは、205*0.7=144行になってます。
反対の評価データは 205-144=61行です。
(9)モデルの作成(p54-58)
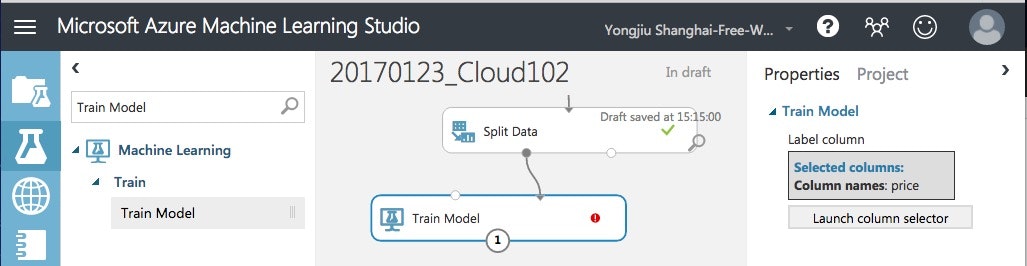
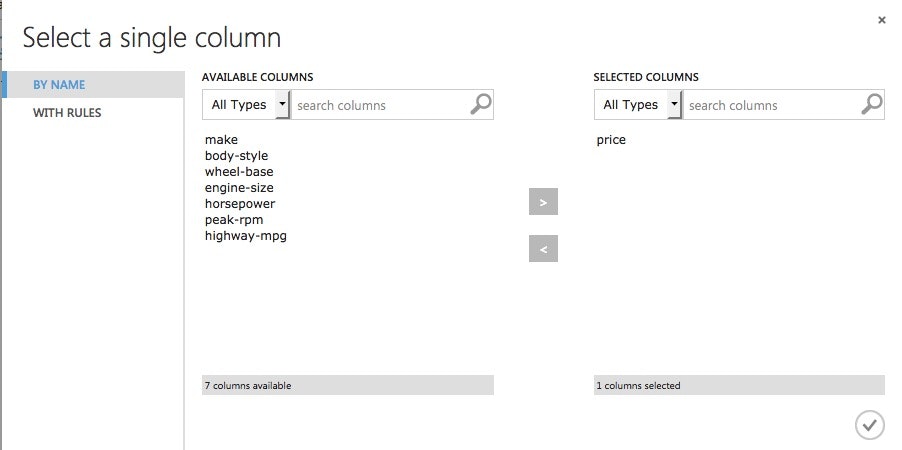
Train Modelというモジュールを追加して「目的変数」を設定します。
目的変数:求めたい結果、説明変数:目的変数に影響を与える変数です。
今回は、自動車の価格予想を行うモデルを作っているので、目的変数はPriceです。
次にアルゴリズムを追加します。今回は線形回帰(Linear Regression)を指定します。
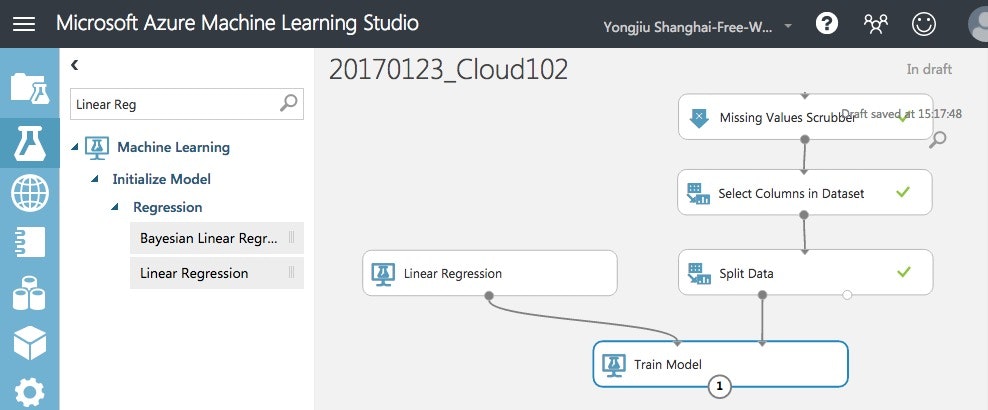
これがAML Studioのすごいとこです。アルゴリズムをTrain Moduleの入力にしているので、GUIでさくっとアルゴリズムを付け替えて、同じデータで機械学習を何度もやり直すことができます。
アルゴリズムの選択に迷ったら、色々試してみて、精度の良いモデルを採用すればいいんです。
Train Modelを実行するとモデルが作成されます。
(10)モデルの評価(p59-65)
評価データを使ってモデルでPriceを予想してみて、その結果を評価します。
以下の2つのモジュールを使います。
- Score Model: 評価データと作成したモデルでPrice予想
- Evaluate Model: Scoreデータで予想したpriceを正解と評価
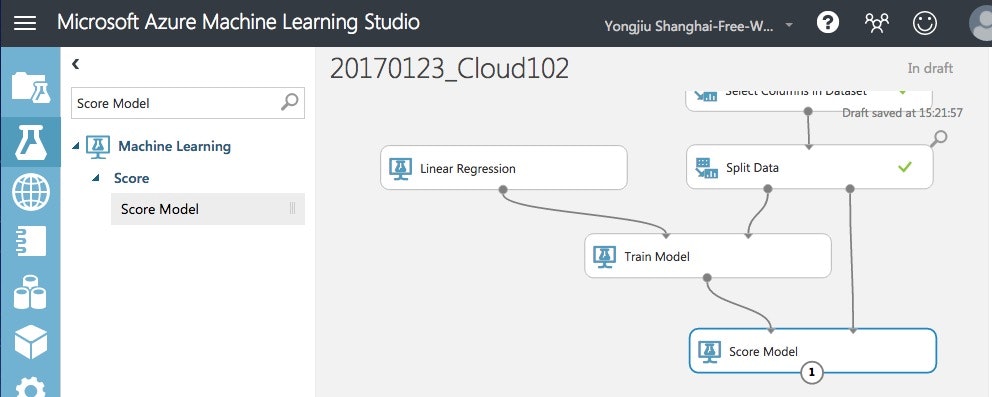
まずはScore Modelを追加して、ここで頭から一気に"Run"しちゃいましょう。
Scoreの出力は、9列になっています。

Evaluate Modelを追加して、"Run Selected"してVisualizeしてみると
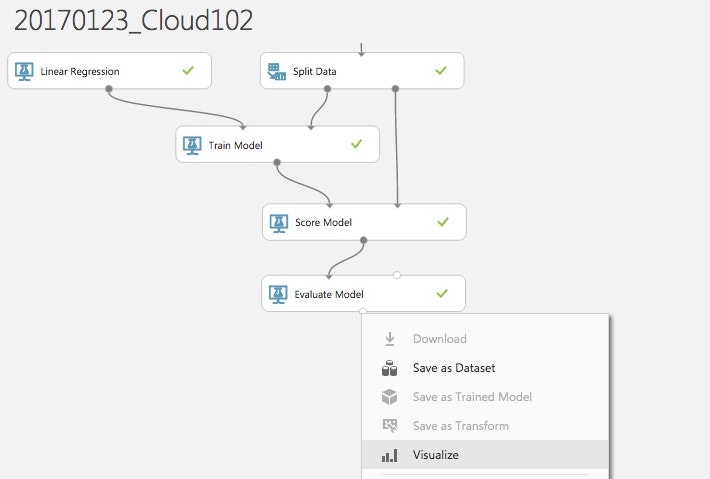
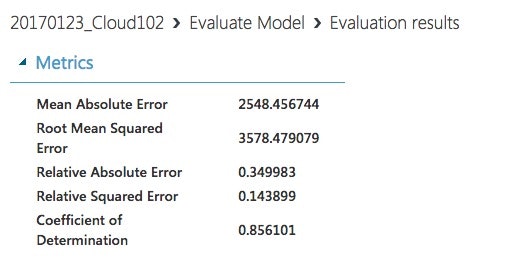
Coefficient of Determination 0.856101
これが1に近づくほど良いモデルらしいです。これがなんなのかは僕に聞かないでください![]()
(11)ちょっと横道
各々の説明変数が目的変数にどの程度関係しそうかどうかは、グラフ表示で感じがつかめます。
Split Dataの結果で、engine-sizeとPriceの散布図プロットしてみると、なんか強い正の相関関係がありそうですね。
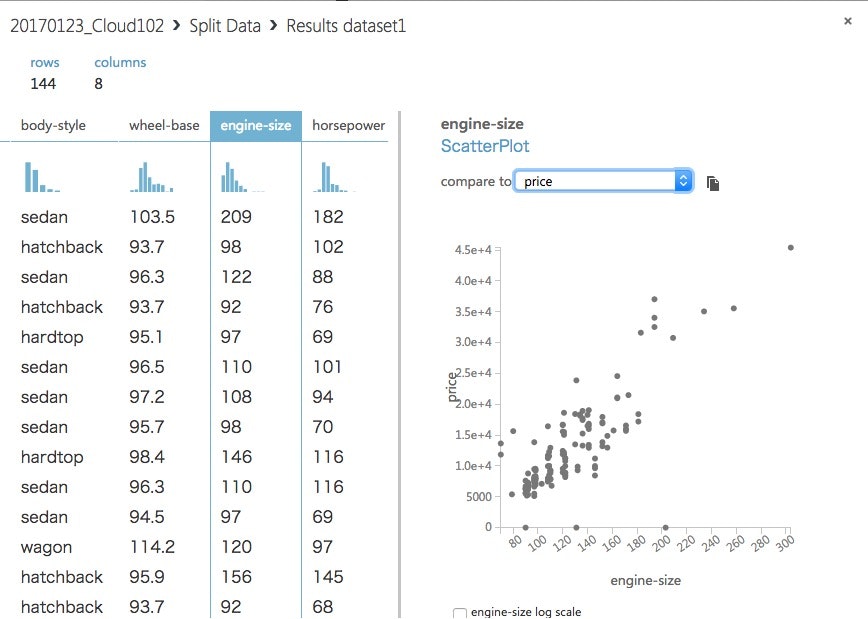
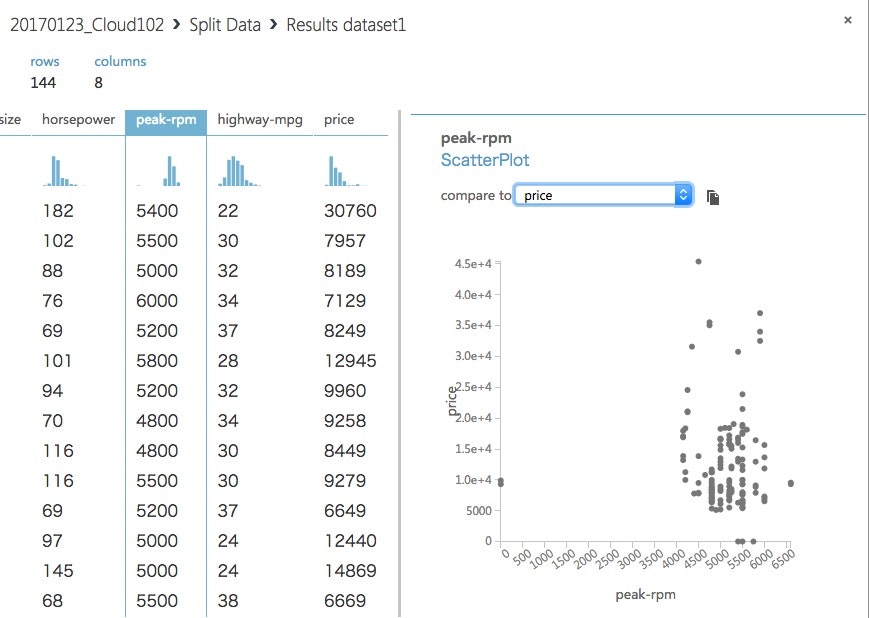
こっちのpeak-rpmはPriceにはあまり関係なさそうです。
目的変数を y, 各説明変数を x1, x2,... とすると、線形回帰は以下の計算式で目的変数を表現しようとするものです。
y = a * x1 + b * x2 + ... + C
つまり
Price = a * engine-size + b * peak-rpm + ... + C
ここでa,bは、どれだけその説明変数の影響が強いのか?を示す「重み」です。先ほど見たグラフではaは大きくてbは小さそうです。Cは数学で出てきた「切片」です。
Train Modelではこの適切な「重み」「切片」を学習データから作成しています。これが「機械学習」ですね。
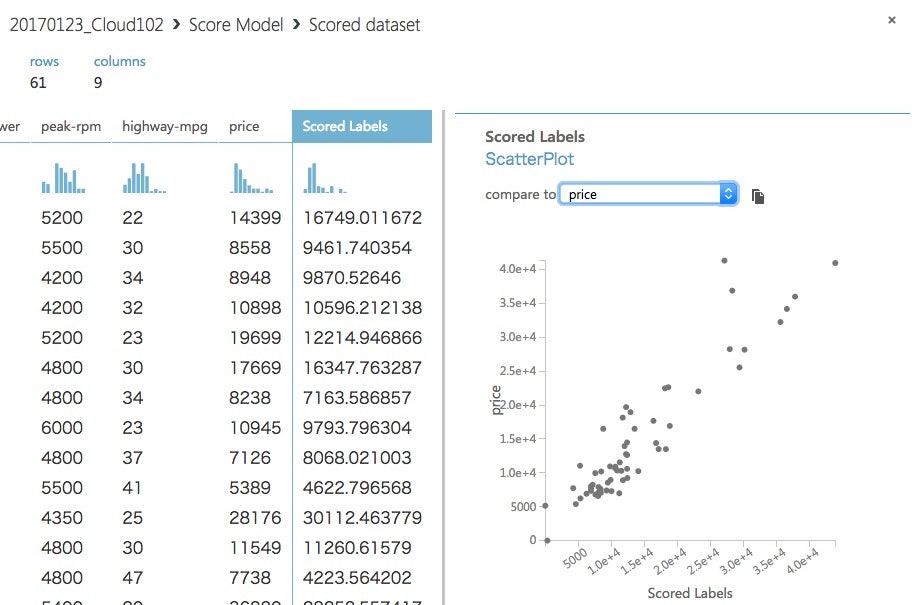
今回作ったモデルでの予測Priceと実際のPriceはこんな感じです。たぶん、これが直線になると Coefficient of Determination = 1になるんではないかと。。。
(12)このモデルをどうやって使うの?
- AML Studioでは、この作成したモデルをWeb API化して外部公開することができます。
- このWeb API(REST)を使うことで、機会学習で作成した自動車Price予想モデルを使うことができます。
(今回はやりませんが、そんなに難しくないので、希望があれば続きのWep API化ハンズオンもできます)
3. Pythonと連携
AML StudioのコンポーネントをGUIでつないでコンポーネントの属性に必要な値を設定していくやり方はとてもわかりやすくスマートですが、処理に必要なコンポーネントがないと何もできません。
全員のニーズを満たすコンポーネントを全て用意することは現実的ではないので、Execute Python Scriptのようなコンポーネントを用意し、細かい処理はPython Scriptなどに任せるアプローチをとっているようです。
まっ、そもそも AML Studio使わない人は全部Pythonなどでやるわけですが![]()
AML Studioで使えるいろんなExperimentやTutorialが「ギャラリー」に公開されています。
ここでは、ギャラリーに入っている以下TutorialのPython部分を試してみます。
(1)新Experimentの作成
新しい Experiment(この例では 20170123_ExecutePython)を作成し、"Execute Python Script"を配置します。
Pythonは2系と3系で文法が少し違うので、Python勉強会で採用している3系を選びます。
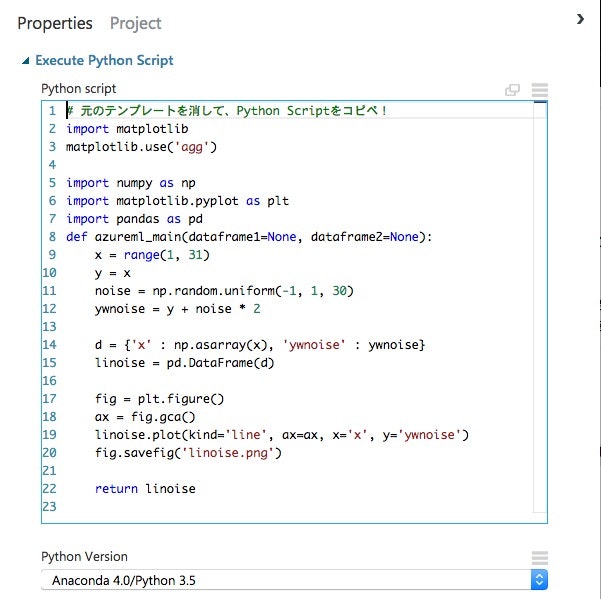
"Python Script"にはテンプレートが入っているので消します。

Tutorialにあるソースコードをコピペします。
import matplotlib
matplotlib.use('agg')
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
def azureml_main(dataframe1=None, dataframe2=None):
x = range(1, 31)
y = x
noise = np.random.uniform(-1, 1, 30)
ywnoise = y + noise * 2
d = {'x' : np.asarray(x), 'ywnoise' : ywnoise}
linoise = pd.DataFrame(d)
fig = plt.figure()
ax = fig.gca()
linoise.plot(kind='line', ax=ax, x='x', y='ywnoise')
fig.savefig('linoise.png')
return linoise
実行してみます

実行結果を見ます
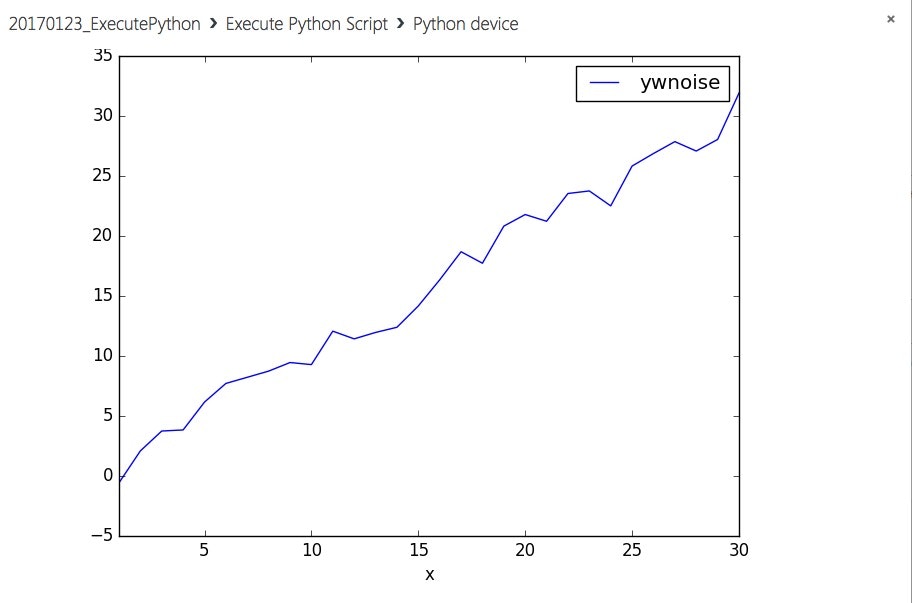
・コードは前回のグラフ表示pythonとあまり変わりませんが、2点注意が必要です。
- azureml_main()の定義:この関数がRUNから呼び出され、引数のdataset1/2でデータやりとりするようです。(今回は引数のdataset1/2は使ってません)
- matplotlib.use('agg'): グラフ表示のためのおまじない。詳しくは以下参照。
- AGGとは:
サーバサイドにおけるmatplotlibによる作図Tips
http://qiita.com/TomokIshii/items/3a26ee4453f535a69e9e
4. 参考
Azure ML を学習したい方向けのコンテンツ(2016.1時点)
http://qiita.com/OgiwaraHiroyuki/items/7953e582ca00dffc604f
この中で紹介されている「Webブラウザーでできる機械学習Azure ML入門」はちょっと古いですがとっつきやすいです。
日本マイクロソフトでハンズオンをやったり、コミュニティベース勉強会でもたまにハンズオンやってますので、興味がある方は是非どうぞ。
https://www.microsoft.com/ja-jp/mic/seminar/ml_solution.aspx
Enjoy!! ![]()