ことのはじまり
サイトのアクセス数が日に日に増えていく中で、どうも一部のアクセスが502エラーになっていると、Mackerel監視でアラートがあがってきました。
とりあえずApacheリスタートをしてみたり、リクエストを別サーバに逃がしてみたりしてみたものの、事象は改善しませんでした。
時同じくして、Mackerelを見ていたら、こんな状態に...(弊社サイトは2台のEc2で冗長構成)
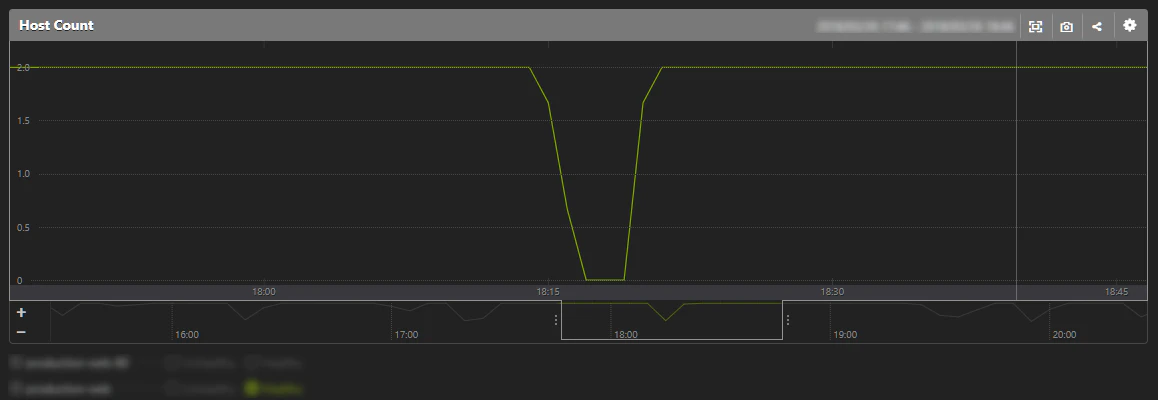
2台とも落ちてる...
すぐに画面から弊社サイトを確認してみても、ちゃんと表示できました。
なぜ、2台とも落ちてるのに、画面が表示されたのか分からなかったのですが、
調べていくうちにわかった「なるほどー」を書いておきます。
(そもそも問題を解決しないといけないので、それもあわせて書いておきます。)
何が起きていたか
アクセスが増える
↓
Apache側のプロセス生成が追いつかなくなる
↓
TLS ネゴシエーションエラーが起きる
↓
ALBのヘルスチェックが失敗する
↓
2台→1台→2台→1台・・・のループ
↓
TLS ネゴシエーションエラーがさらに起きる
↓
502エラーが返る
ということが起きていて、一度始まるとアクセスが落ち着くまでずっと不健康な状態が発生することがわかりました。
ALBの絶妙な仕様が作用していた
正常なターゲットが含まれているアベイラビリティーゾーンがない場合、ロードバランサーノードはすべてのターゲットにリクエストをルーティングします。
つまり、全滅したら、どれかにリクエストを寄せたりせず、全台にわりふるということ。
私たちの環境では、2つのターゲットグループ(1つのターゲットグループに1つのEC2)がありますので、
-
1台落ちてるとき
- HealtyなEC2:リクエスト割り振る
- UnhealthyなEC2:リクエスト割り振らない
-
2台落ちてるとき
- HealtyなEC2:リクエスト割り振る
- UnhealthyなEC2:リクエスト割り振る
という状況になるため、通常時と同じ挙動になるということがわかりました。
たまたまそんな空気を読む仕様だったので、あらかたのリクエストはちゃんと返せていたのか、と驚きとともに
使用しているAWSの仕様ももっと細かいところまで把握しないといけないなーと反省。
対処方法
さて、そもそものTLS ネゴシエーションエラーが起きないようにしなければならなかったので
その対応もついでに書いておこうと思います。
今回、TLS ネゴシエーションエラーが発生していた根本原因は、
ALBからEC2のApacheへのコネクションを十分に張れるように設定値の見直しを行いました。
実際に行った変更は下記です。
-
MaxKeepAliveRequestsを増やす
- ALB<>Apache間のコネクションを使い回す上限をあげる=connection張りっぱなし時間を伸ばす
-
MaxClientsを増やす
- 最大プロセス数の上限をあげる=捌ける窓口増やす
これで、経過観察をしてエラーが再現しなくなりましたので、晴れて解決となりました!