Selniumでなんでも自動化したい。
実装力もなく、卒論から逃げたい一心で書いた。
これを読めばみんな自動化大好き人間になってしまうだろう。
ぜひ実践しまくって堕落した人間になってほしい。
絶対に転売ヤーにはならないでほしい
1. はじめに
私もそろそろWebの挙動を何でも自動化したい年頃になったので書いた。
具体的にやってみたのは以下の通り
-
物の購入を自動化
- 画像認証を機械学習でババっと突破
- JavaScriptの実行
-
ローカル環境のファイルをWebに書き込む
単一のテキストファイルを複数の入力フォームに入力する -
Headless browserでの自動化に向いてること向いてないことの検証
今回の内容
出来たらほんのちょっとだけ嬉しいことをやった。
Webの作業で自動化する上で難しかったことや、みんながつまずきそうな所もここで解決できたらなと思う。
2. 環境
- マシン
- Mac --version 10.13.5
- ソフトウェア
- ChromeDriver --version 2.40
- Python
- Python3 --version 3.6.0
WinOSの方は各自で頑張ってください。
3.下準備
さっそくSeleniumのinstall
あぁ…難しい。
次にChromeDriverのinstall
もしくは
こちらから ( ChromeDriver - WebDriver for Chrome )
ちなみに最新版は
こちらから ( ChromeDriver - WebDriver for Chrome --ver. 2.40 )
ここまできたら進捗98%
あとの2%はPythonがやってくれる
4. まずは動かしてみる
何はともあれ動かしてみる。
まずは見たいサイトを表示してスクリーンショットを撮る。
# coding:utf-8
from time import sleep
from selenium import webdriver
# Chromeを起動
browser = webdriver.Chrome()
# 表示したいサイトを開く
browser.get("https://www.google.co.jp/")
# 表示したサイトのスクリーンショットを撮る
browser.save_screenshot('screen.png')
# 表示した瞬間消えちゃうから幅を持たせておく
sleep(5)
# ブラウザを閉じる
browser.close()
動かす
多分こんな感じのスクリーンショットが撮れてる。

もしかすると以下のようなエラーが出てしまうかもしれない。
Please see https://sites.google.com/a/chromium.org/chromedriver/home
これはchromedriverを実行するときにはパスの明示が必要だよっつってる。
そんな時は、先ほどのコードを以下のように書き換えてみよう。
browser = webdriver.Chrome()
のところを
PATH = '(ChromeDriverのあるパス)'
browser = webdriver.Chrome(executable_path=PATH)
とする。
無理だったら色々ググってみてください。
結局、
browser = webdriver.Chrome()
browser.get("https://www.google.co.jp/")
というのは、当たり前のことだけど
webdriver.Chrome.get("https://www.google.co.jp/")
これのことで、
ChromeDriverでgetの引数に入力したURLのページを表示するよってこと。
当たり前なんだけどね。
browser = webdriver.Chrome()
のbrowserはChromeDriverを意味しているということも当たり前なんだけど、そういうことです。
5. 基礎編
さっきの
browser.get("URL")
みたいなやつ、いっぱい紹介していきます。
特にこれ使ったなぁってやつ。
- find_element_by_xxxx シリーズ
- find_element_by_id
- find_element_by_name
- find_element_by_xpath
- find_element_by_link_text
- find_element_by_partial_link_text
- find_element_by_tag_name
- find_element_by_class_name
- find_element_by_css_selector
とりあえずこれ
ほぼこれ
これに尽きる
これができればもう今からSeleniumer
何をするものかというと、さっきget("URL")で表示したページの要素を取り出すのに使う。
例えば下のHTMLファイルを見てほしい。
<html>
<body>
<form id="loginForm">
<input name="username" type="text" />
<input name="password" type="password" />
<input name="continue" type="submit" value="Login" />
</form>
</body>
<html>
<!-- From
https://kurozumi.github.io/selenium-python/locating-elements.html
-->

このページから
<input name="username" type="text" />
を抜き出したいとき(=ログインフォームのusernameを入力する準備として)
browser.find_element_by_name("username")
で抜き出すことが出来る
簡単すぎる
すごい
さて、ではここに入力出来るようしていこう
以下がそのコード
# coding:utf-8
from time import sleep
from selenium import webdriver
# 入力するためのもの
from selenium.webdriver.common.keys import Keys
# Chromeを起動
browser = webdriver.Chrome()
# 表示したいサイトを開く
browser.get("https://xxxxxxx/~~~/index.html")
# ログインのユーザー名入力フォームの抜き出し
username = browser.find_element_by_name("username")
# ユーザー名入力
username.send_keys("ユーザー名はここに入る")
# 表示したサイトのスクリーンショットを撮る
browser.save_screenshot('screen.png')
# 表示した瞬間消えちゃうから幅を持たせておく
sleep(5)
# ブラウザを閉じる
browser.close()
以下のようなスクリーンショットが撮れたと思う。

同じようにしてpasswordの入力は
# ログインのパスワード入力フォームの抜き出し
password = browser.find_element_by_name("password")
# パスワード入力
password.send_keys("パスワードはここに入る")
で実現することが出来る
基礎の最後としてクリックをやってみよう
これもめちゃくちゃ簡単
先ほどのindex.htmlを用いてクリックすることを考える
ひとまずコードを記す
# ログインボタンの要素の抜き出し
login = browser.find_element_by_name("continue")
# 抜き出した要素のクリック
login.click()
これまでやったこととなんの変わりもない。
要素の抜き出し
** → 要素をどうするか( ' send_keys() ' で入力したり、 ' click() ' でクリックしたり )**
さえ徹底していれば力技でなんでも出来る。
以下のようなHTMLファイルでは "name" 要素からの抜き出しを行なった。
<input name="username" type="text" />
<input name="password" type="password" />
<input name="continue" type="submit" value="Login" />
"id" 要素も抜き出さなくてはならないこともあるが、お分かりの通り、
browser.find_element_by_id("xxxxx")
で抜き出すことが出来る。
6. 実践編
正直基礎編で大体のことをすることが出来る。
しかし、やっていくうちに要素の指定が間違っている訳でもないのに、どうしようもなく要素を抜き出せない、実行できない場合がある。
「は?」という気持ちになり、パソコンをぶっ壊したくなる。
以下がその助けになることを願う。
XPath
そういうときには " XPath " を使おう
XPathは、XML文書内のノードの位置を特定するために使用される言語です。HTMLはXML(XHTML)を実装できるため、Seleniumユーザーはこの強力な言語を活用して、Webアプリケーションの要素をターゲットにすることができます。XPathは、id属性やname属性で簡単に検索する方法を超えて(サポートするだけでなく)拡張し、ページ上の3番目のチェックボックスの位置付けなど、あらゆる可能性を開拓します。
https://kurozumi.github.io/selenium-python/locating-elements.html
ということで、id要素やname要素を抜き出すことが出来る。
使い方も
browser.find_element_by_xpath("xxxxx")
だけで良い。
xpath(上のコードの"xxxxx")をどうやって調べるのか、
chromeを使っているのであれば、以下のように要素の検証からコピーすることが出来る。
まずは抜き出したいページを表示して検証したいところにカーソルを合わせて右クリック
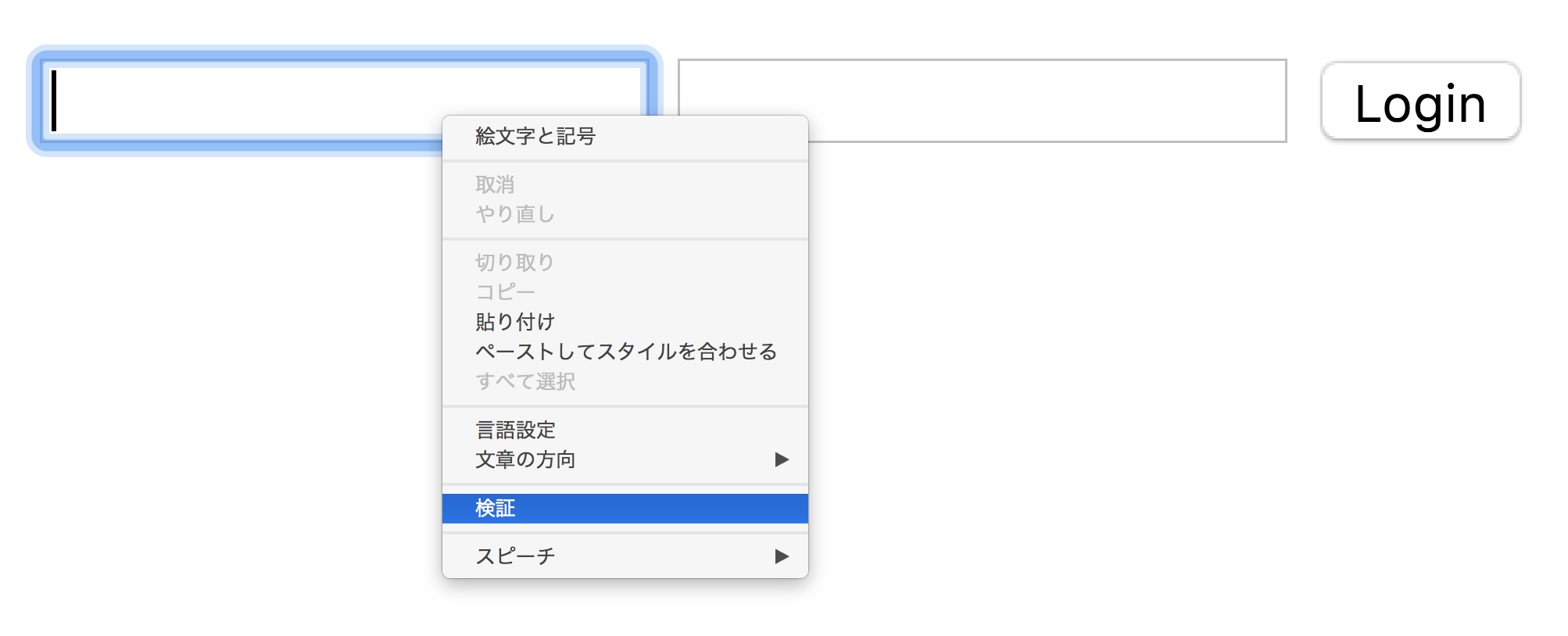
次に検証したい要素のところいカーソルを合わせて右クリックして 「Copy → Copy Xpath」 でクリップボードに保存される

では先ほどの例からログインフォームのユーザー名にxpathで抜き出して入力しよう。
# coding:utf-8
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Chrome()
browser.get("https://xxxxxxx/~~~/index.html")
# xpathで要素の抜き出し
username = browser.find_element_by_xpath('//*[@id="loginForm"]/input[1]')
## xpathで入力
username.send_keys("xpathで抜き出して入力")
browser.save_screenshot('screen.png')
browser.close()

できた。
困った時はこんな感じでxpathで対応していこう。
XPathでも対応できない場合
そういうこともある。
人生はそんなものだ。
id,name,xpathで要素の抜き出しができないと本当に心が折れる。
しかしまだ道は残されている。
<a href="hoge" onclick="fugafuga('https:hogehoge/fuga.js')">ログインページへ</a>
こんな、ログイン画面へと遷移させるようなページソースが出てきたとき、まずはid,nameの要素がないのでxpathで要素を持ってこようと思うだろう。
しかし、できない。
なぜできない。
多分外部ファイルの実行だからできないのであろうか。
僕は細かいことは分からない。
そんな時は以下を実行してみよう。
login_page = browser.find_element_by_link_text("ログインページへ")
login_page.click()
これで遷移できたりする。
難しい。
でもできたらそれで良い。
また、「ログイン ページへ」のようにスペースが入っている場合などは処理の上で正しく要素を取り出せないことがある。
こういう時は browser.find_element_by_link_text に近しいものに
browser.find_element_by_partial_link_text("ページへ")
というものがあり、これによって解決することが出来る。
これは "ログイン ページへ" のように全ての文字列を引数に渡すのではなく、
"ログイン" や "ページへ" などのように文字列の一部を引数と渡して要素を取り出すことが出来る。
例では "ページへ" を引数に渡している。
JavaScriptの実行
javascriptを実行するときには基本的にclick()がほとんどであるが、画像認証などの入力フォームではjavascriptを実行しなくては先に進めないなんていうこともある。
どうすれば良いのか。
これも答えはすでに用意されていて、
browser.execute_script("xxxxxxxxx(xxx)")
で実現することが出来る。
("xxxxxxxxx(xxx)")に関しては関数名と、必要ならば引数を入れる。
" click() " という関数を実行する場合は
browser.execute_script("click()")
とすれば良い。
その他
世界には賢い人がいっぱいいるのでぜひググって参考にしてください。
7. Headless browserについて
これまでプログラムを動かすと、勝手にブラウザが立ち上がったと思うが、Headless browserではそもそもブラウザが立ち上がらない。
どういうことかというと、chromeやfirefoxなどのソフトウェアがGUIでは立ち上がらないのである。
したがってコマンドラインだけの操作が可能なのである。
何が嬉しいかというと、GUIを持たないサーバーOSでもブラウジングすることが可能なのである。
ローカルマシンでやらなくてもサーバーで自動化できたら嬉しいよなぁという話。
ていうかそれだけ。
んで、これのデメリットがめちゃくちゃ多いと思っていて、
- javascriptがまともに動かない。(特に外部ファイル読み込みのものは動かなかった)
- サポートされているものが、ジャパニーズに優しくない。
- 動作検証はスクリーンショットでしか確かめられないので、検証段階ではヘッドレスブラウザを結局使わない。(少なくとも僕は)
普通のブラウザと同等の機能であれば、使いたいと思う。
結局、Headless browserが向いていることって、javascriptの実行を行わないくらいの単純な自動化のイメージ。
まだまだこれからイイ感じになってくるとは思うので、これからに期待したい。
もっと楽をさせてくれ。
8. 僕がやったこと
長くなってしまったので、これは次回に書く。
画像認証を突破するためにやったことや、web上にファイルをアップロードする際のファイル整形のコツなどを紹介する。